数据结构与算法(java):线性表-栈
栈
1、概念
1.1 定义
栈(Stack)是限定仅在表尾进行插入和删除操作的线性表。
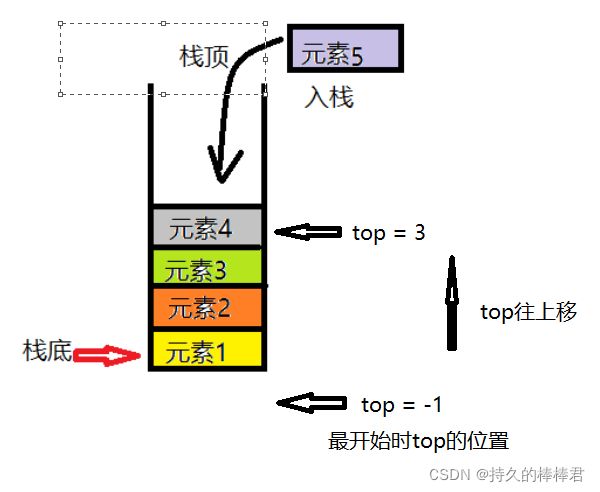
把允许插入和删除的一端称为栈顶(top),另一端称为栈底(bottom),不含任何数据元素的栈称为空栈。栈的插入(push)操作叫做压栈,也叫进栈,删除操作(pop)叫做弹栈,也叫出栈。
1.2 特点
栈是先进后出(LIFO:Last In First Out)的线性表,简称LIFO结构。
栈元素具有线性关系,即前驱后继关系。
栈的插入和删除操作始终仅在栈顶进行
2、分类
因为栈本身就是一个线性表,所以线性表的顺序存储和链式存储也是同样适用的。
顺序存储结构:顺序栈
链式存储结构:链式栈
2.1 栈的顺序存储结构及实现
2.1.1 图示

顺序栈图
可以这么理解,有个手枪子弹夹,你要往里面放入子弹,这个过程叫压栈(入栈),此时越先放入的子弹越靠近底部,当你射击的时候,越往后放入的子弹就越先发射出来,这个过程叫弹栈(出栈),这就是先进后出(后进先出)
顺序存储结构一般用数组来实现,那么用数组哪一端作为栈顶和栈底更好?
答:一般将下标为0的一端作为栈底较好,因为首元素都存在栈底,变化最小
2.1.2 思路
使用一个泛型数组来存储指定泛型类型的数据,并且使用一个头部指针top来对所存元素的位置进行指向,读取元素时想应的头指针都应变化,设置头部指针初始值为-1,当头部指针到栈顶时表示栈满了,此时top=数组长度-1.
2.1.3 代码实现
public class SequenceStack<T> implements Iterable<T>{
//数组
private T[] elements;
//栈顶指针
private int top;
//构造方法:初始化,将栈大小默认设置为10
//通过this调用构造器
public SequenceStack() {
this(10);
}
public SequenceStack(int capacity){
this.elements = (T[]) new Object[capacity];
this.top = -1; //初始化栈顶指针,默认第一个元素为0,top指向-1表示没有指向栈
}
//-------------------------------------------------------------
//判断栈是否为空
public boolean isEmpty(){
if(top == -1){
return true;
}
return false;
}
//-------------------------------------------------------------
//判断栈是否满了
public boolean isFull(){
if(top == elements.length-1){
return true;
}
return false;
}
//-------------------------------------------------------------
//返回栈的大小
public int length(){
return elements.length;
}
//-------------------------------------------------------------
//返回实际元素个数
public int size(){
return top+1;
}
//-------------------------------------------------------------
//清除栈
public void clear(){
Arrays.fill(elements,null);
}
//-------------------------------------------------------------
//查找元素第一次在栈中出现的位置,返回下标
public int indexOf(T t){
for(int i = 0; i<=top; i++){
if(elements[i].equals(t)){
return i;
}
}
return -1;
}
//-------------------------------------------------------------
//控制顺序表扩容
public void resize(int newSize){
T[] temp = elements; //定义一个新数组指向原数组
elements = (T[])new Object[newSize]; //创建新数组
for(int i = 0; i<= top; i++){
elements[i] = temp[i]; //将原数组拷贝到新数组
}
}
//-------------------------------------------------------------
//压栈
public void push(T t){
//首先判断是否需要扩容
if(isFull()){
resize(elements.length*2);
}
elements[++top] = t;
}
//-------------------------------------------------------------
//弹栈:直接删除栈顶元素,并且返回被删除的元素
public T pop(){
if(isEmpty()){
return null;
}
T oldValue = elements[top];
elements[top--] = null;
return oldValue;
}
//-------------------------------------------------------------
//返回栈顶元素,不删除栈顶元素
public T up(){
if(isEmpty()){
return null;
}
return elements[top--];
}
//-------------------------------------------------------------
//正常循环
@Override
public Iterator iterator() {
return new SIterator();
}
private class SIterator implements Iterator{
private int cursor;
public SIterator(){
this.cursor = 0;
}
@Override
public boolean hasNext() {
return cursor<=top;
}
@Override
public Object next() {
return elements[cursor++];
}
}
}
测试代码
public class SequenceStackTest {
public static void main(String[] args) {
SequenceStack<String> ss = new SequenceStack<>(2);
ss.push("alibaba");
ss.push("tencent");
ss.push("huawei");
for(String s : ss){
System.out.println(s);
}
System.out.println(ss.indexOf("alibaba"));
System.out.println(ss.indexOf("tencent"));
System.out.println(ss.indexOf("huawei"));
System.out.println("栈中元素个数");
System.out.println(ss.size());
System.out.println("栈大小");
System.out.println(ss.length());
System.out.println("出栈操作");
System.out.println( ss.pop());
System.out.println(ss.up());
ss.clear();
System.out.println(ss.up());
}
}
结果
alibaba
tencent
huawei
0
1
2
栈中元素个数
3
栈大小
4
出栈操作
huawei
tencent
null
补充
需要注意的是,顺序栈中,栈中的元素个数和栈的大小是有区别的,栈的大小值的是创建的数组的大小,是能存放元素的数量,当栈中的元素个数等于栈的最大值时,栈就满了
2.2 栈的链式存储结构及实现
2.2.1 图示
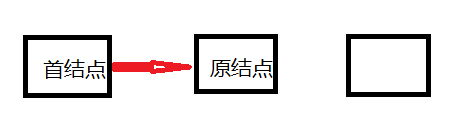
下面是压栈操作过程
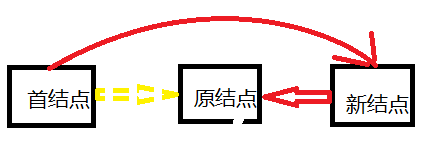
下面是弹栈操作过程

2.2.2 思路
把首结点作为栈底
1、压栈操作时,将指向原来结点的首结点指向一个新的结点,再将新的结点指向首结点之前指向的那个结点。
2、弹栈操作时,将首结点指向新结点的上一个结点。新结点的位置即为栈顶,每次弹栈操作时,先把新加入的结点弹出,越早加入的结点越靠近栈底(首结点),越往后弹出。
2.2.3 代码实现
public class LinkedListStack<T> implements Iterable<T>{
//首结点
private Node head;
//栈中元素个数
private int N;
//结点类
private class Node{
public T item; //结点中的数据
public Node next; //下一个结点
public Node(T item, Node next) {
this.item = item;
this.next = next;
}
}
//------------------------------------------------------------------
//构造方法:初始化
public LinkedListStack() {
this.head = new Node(null, null);
this.N = 0;
}
//------------------------------------------------------------------
//判断栈中元素是否为空
public boolean isEmpty(){
return N == 0;
}
//获取栈中元素个数
public int size(){
return N;
}
//------------------------------------------------------------------
//元素压栈
public void push(T t){
//找到首结点指向的第一个结点
Node oldFirst = head.next;
//创建新结点
Node newNode = new Node(t, null);
//让首结点指向新结点
head.next = newNode;
//让新结点指向原来的第一个结点
newNode.next = oldFirst;
//元素个数加1
N++;
}
//------------------------------------------------------------------
//元素弹栈
public T pop(){
//找到首结点指向的第一个结点:这个结点就是最靠近栈顶的那个元素
Node oldFirst = head.next;
//判断栈是不是空,非空则可以弹栈
if(oldFirst == null){
return null;
}
//让首结点指向原来第一个结点的下一个结点,跳过了中间那个结点
head.next = oldFirst.next;
//元素个数减1
N--;
return oldFirst.item;
}
//------------------------------------------------------------------
@Override
public Iterator<T> iterator() {
return new SIterator();
}
private class SIterator implements Iterator{
private Node n;
public SIterator() {
this.n = head;
}
@Override
public boolean hasNext() {
return n.next != null;
}
@Override
public Object next() {
n = n.next;
return n.item;
}
}
}
测试类
public class LinkedListStackTest {
public static void main(String[] args) {
LinkedListStack<String> lls = new LinkedListStack<>();
//压栈
lls.push("java");
lls.push("C");
lls.push("python");
System.out.println("迭代器遍历------");
for(String s : lls){
System.out.println(s);
}
System.out.println("栈的大小------");
System.out.println(lls.size());
System.out.println("出栈操作------");
System.out.println(lls.pop());
System.out.println(lls.pop());
System.out.println(lls.pop());
}
}
结果
迭代器遍历------
python
C
java
栈的大小------
3
出栈操作------
python
C
java
3、栈的常见应用
3.1 符号配对
问题描述
“(” 和 " )" 成对出现时字符串合法。例如" ( )", "中国(北京)”是合法的; "中国(北京))”是不合法的。判断括号是否成对出现。
主要思路
1、创建栈对象,用来存储左括号
2、从左往右遍历字符串
3、判断字符串中的字符是否为左括号,是,则加入到栈中
4、继续遍历字符串,判断字符是不是右括号,是,则从栈中弹出元素左括号,并判断弹出的结果是不是null,当不为null时,则证明有匹配的左括号
5、最后如果栈中还剩有左括号,则返回false
*/
代码实现
import org.junit.jupiter.api.Test;
public class MatchCharacter {
public static boolean isMatch(String str){
//1、创建栈对象,用来存储左括号
SequenceStack<String> stack = new SequenceStack<>();
//2、从左往右遍历字符串
for(int i = 0; i<str.length(); i++){
String currChar = str.charAt(i)+"";
//3、判断字符是不是左括号,是,则添加到栈中
if(currChar.equals("(")){
stack.push(currChar);
/* 4、
(1)判断字符是不是右括号
(2)是,则从栈中弹出元素左括号
(3)并判断弹出的结果是不是null,当不为null时,则证明有匹配的左括号
*/
}else if(currChar.equals(")")){
String pop = stack.pop();
if(pop == null){
return false;
}
}
}
//5、判断栈中是否还有剩余的左括号,有,则证明括号不匹配
return stack.size() == 0;
}
@Test
public void matchTest(){
String s = "(上海))(北京)";
boolean result = isMatch(s);
System.out.println(result);
}
}
3.2 前缀、中缀、后缀表达式
1、定义
前缀表达式
中缀表达式
就是生活中使用的表达式,例如:1+3*2,2-(1-3)等等,特点是二元运算符总是置于两个操作数中间。优点是人好理解,缺点是对于计算机来说,中缀表达式的运算顺序不具有规律性,不同运算符具有不同的优先级,如果计算机执行中缀表达式,就需要解析表达式语义,做大量优先级相关操作。
逆波兰表达式(后缀表达式)
运算符总是放在跟他相关的操作数之后。
对比如下:
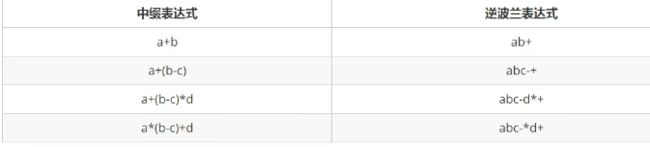
怎么一眼看出来逆波兰表达式它的中缀表达式呢
个人总结:
关键就是看操作数与符号的位置,运算符号总是写在操作数的后面
例如:
a b c - d * +
先算bc-,即b-c,假设b-c的到了一个结果N,就变成了aNd * +
再算Nd*,即N*d,假设又得到了一个结果M,就变成了aM+
即a+M
最后,将式子替代后得到:
(b-c)*d+a
2、常见问题
问题描述1 :设计一个逆波兰计算器
给定一个只包含函数加减乘除四种运算的逆波兰表达式的数组表示方式,通过设计的逆波兰计算器求出其结果。
主要思路
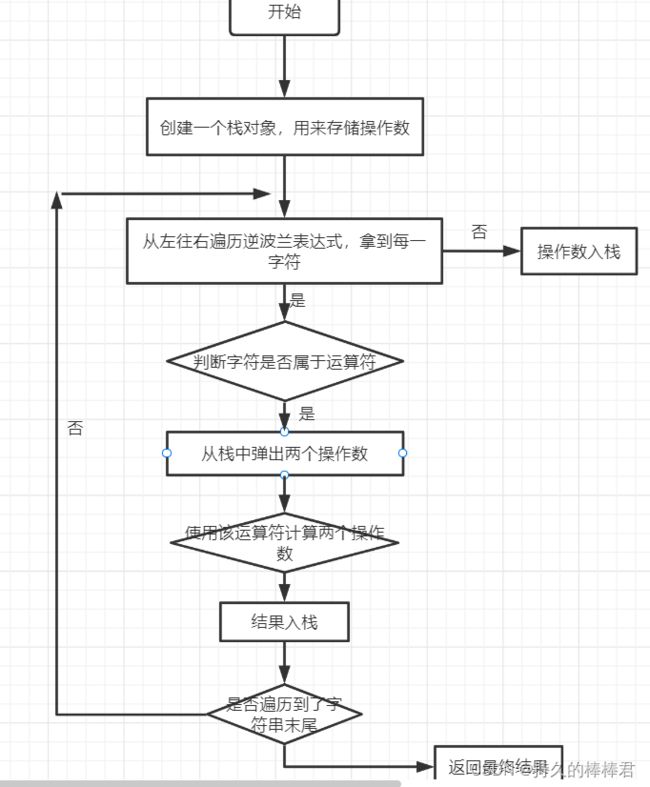
代码实现
public class ReversePolishNotationTest {
@Test
public void Test(){
//中缀表达式形式:3*(17-15)+18/6
String[] notation = {"3","17","15","-","*","18","6","/","+"};
int result = calculate(notation);
System.out.println("逆波兰表达式的结果为" + result);
}
public static int calculate(String[] notation){
//1、定义一个栈,用来存储操作数
SequenceStack<Integer> oprands = new SequenceStack<>();
//2、从左往右遍历逆波兰表达式,得到每一个元素
for(int i = 0; i<notation.length; i++){
String curr = notation[i];
//3、判断当前元素是操作数还是运算符
Integer o1;
Integer o2;
Integer result;
//通过switch来区分运算符运算
switch (curr){
//4、操作数和运算符运算后的结果压入栈中,
case "+":
o1 = oprands.pop();
o2 = oprands.pop();
result = o2+o1;
oprands.push(result);
break;
case "-":
o1 = oprands.pop();
o2 = oprands.pop();
result = o2-o1; //注意点1
oprands.push(result);
break;
case "*":
o1 = oprands.pop();
o2 = oprands.pop();
result = o2*o1;
oprands.push(result);
break;
case "/":
o1 = oprands.pop();
o2 = oprands.pop();
result = o2/o1;
oprands.push(result);
break;
default:
//5、把操作数翻入栈中
oprands.push(Integer.parseInt(curr));
break;
}
}
//6、得到栈中最后的一个元素就是结果
int result = oprands.pop();
return result;
}
}
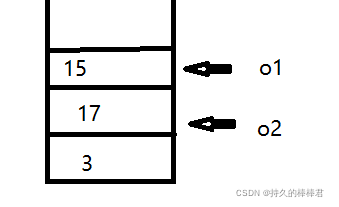
关于那个注意点1,解释如下
入栈顺序是3(栈底),17,15,此时弹栈顺序是o1,再是o2,而后缀表达式中原本计算顺序是17-15,而不是15-17,所以是o2-o1
问题描述2:将中缀表达式转后缀表达式
待补充:2022/3/6