使用cephadm部署单节点ceph集群,后期可扩容(基于官方文档,靠谱,读起来舒服)
目录
- ceph各种部署工具比较(来自官方文档的翻译,靠谱!)
- 材料准备
- cephadm使用条件
-
- 服务器有外网访问能力
- 服务器没有外网访问能力
- 安装cephadm
-
- cephadm的功能
- 两种安装方式
-
- 基于curl安装cephadm
- 各自linux发行版的特定安装方法
- 在部署ceph前先花10分钟给各位看官扫盲(原创)
-
- ceph分布式存储的整体架构
- 一些ceph的名词解释
- ceph是如何寻址的
- 部署前的架构规划
-
- 我的实际架构
- 创建一个新Ceph集群
-
- 确定主机内网ip
- 开始创建
- 我的服务器实际运行效果
- 补充知识(可不看):有关cephadm bootstrap的进一步信息
- 举例
- 安装ceph命令
- 安装OSD
-
- 查看主机目前已有的OSD
- 自动安装OSD
- 移除OSD
- 擦除机器
- 到此,ceph存储集群部署完成了!
- Ceph 存储集群介绍(包含librados)
-
- OSD后端
- GW对象存储
-
- GW与Openstack Swift集成提供对象存储服务
- RBD块存储
-
- 基本安装和基础命令
- RBD与Openstack集成,提供块存储和镜像存储
-
- 创建ceph Pool
- 初始化pool
- FS安装
- 附录一、ceph存储集群添加其他主机(RADOS扩缩容)
-
- 列出集群内的主机
- 添加主机前,检查一下是否满足条件
- 添加主机
- 移除主机
- 集群重新扫描
文章最后更新时间:2022.8.4
别问我ceph是什么,不知道的人他也不会点开这篇文章。
本文章的所有命令中 < >表示必填,[ ]表示选填,( )表示解释说明
ceph各种部署工具比较(来自官方文档的翻译,靠谱!)
- Cephadm
使用容器和systemd安装和管理Ceph集群,并与CLI和仪表板GUI紧密集成。 cephadm只支持Octopus和较新的版本。 cephadm与新的编排API完全集成,并完全支持新的CLI和仪表板特性来管理集群部署。 cephadm需要容器支持(podman或docker)和Python 3。 - Rook
部署和管理运行在Kubernetes中的Ceph集群,同时还支持通过Kubernetes API管理存储资源和供应。我们推荐Rook作为在Kubernetes中运行Ceph或将现有Ceph存储集群连接到Kubernetes的方式。 Rook只支持Nautilus及以后的Ceph的版本。 Rook是在Kubernetes上运行Ceph或将Kubernetes集群连接到现有(外部)Ceph集群的首选方法。 Rook支持新的orchestrator API。完全支持CLI和仪表板中的新管理功能。 - ceph-ansible
使用Ansible部署和管理Ceph集群。 ceph-ansible被广泛部署。 ceph-ansible没有与Nautlius和Octopus中引入的新orchestrator API集成,这意味着更新的管理特性和仪表板集成不可用。 - ceph-deploy
是一个快速部署集群的工具。注意:ceph-deploy项目不再积极维护。它没有在包括Nautilus及以后的Ceph版本上测试过。它不支持RHEL8、CentOS 8或更新的操作系统。(项目太老了,不要用) - 其他安装方式
ceph-salt使用Salt和cephadm安装Ceph。
jaas.ai/ceph-mon使用juju安装Ceph。
github.com/openstack/puppet-ceph通过puppet安装Ceph。
Ceph也可以手动安装。
Windows安装ceph, 请参考这篇文档: Windows安装指南
综上,你可以纯手动,你可以用cephadm进行纯docker化部署,或者rook进行k8s部署,其他的工具就放弃吧。
为什么我不建议你用rook将ceph部署在k8s上?
跟你讲个故事,github上曾经有个项目叫kolla-kubernetes,用于将openstack部署在k8s中,后来这个项目在2019年被废弃,原因是没有人用。我问了在九州云的培训班老师,这么好的项目干嘛废弃,多可惜啊。他说k8s太吃服务器性能了,1台1U服务器部署k8s+监控的话,1/3的性能就没了。而且你使用k8s部署云计算的初衷无非就是当容器死了,能自动杀掉然后重启一份新的。这个功能其实docker也能做到。所以没k8s有必要。这位老师想要告诉我们的是:越是底层的东西,越是要简单粗暴且高效。
部署ceph分布式存储,本身使用的服务器就是硬盘大,性能低,网络快的老旧或二手服务器,以数量取胜。老旧服务器cpu差,内存小,不适合部署k8s。如果说openstack是底层基础设施,那么ceph是底层的底层。纯手动部署,服务瘫了怎么办?部署k8s成本太大了。所以docker容器化是最好的选择。
部署ceph推荐使用cephadm,部署openstack推荐使用kolla-ansible!因为它们都是纯容器化部署。
金融企业,财大气粗不差钱,并且追求极致的稳定,“我就是要把ceph部署在k8s上”,那您随意。但是您都用上了ceph了,整了几十台服务器几百块硬盘了,还害怕一年一两次的个别硬盘损坏?
材料准备
- 主机一个,带系统盘带linux。
- 内网(如果你使用虚拟机,则需要创建一个NAT网络,如果你是用的物理主机,则需要交换机或者集线器,然后创建局域网或vlan)
- 至少3块额外硬盘。(当然你也可以准备更多硬盘。多多益善)
cephadm使用条件
ceph是分布式存储,所以横向扩容是非常容易的,加机器、减机器都是很轻松的,所以我们先用cephadm部署一台主机就行了,以后想扩容随时都可以。这也是官方文档推荐的。虽然一台节点数据安全性不是太强,但是成本低啊。而且我觉得安全性是要比raid5还要高的。记住,永远不要想着硬件容灾,那样成本太高而且没有标准,不能自动化。软件层进行容灾才是yyds,这也是分布式存储、分布式数据库、分布式账本(区块链)的意义。
打好ceph基础是你进军openstack私有云的前提。openstack社区发布数据显示,全球58%的openstack环境的底层存储用的是开源ceph。其次是LVM,占比27%,所以拿下它,精通它,涨薪3k。
以下是官方文档翻译:
Cephadm通过bootstrapping在单个主机上创建一个新的Ceph集群,扩展集群以包含任何其他主机,然后部署所需的服务。
这台主机的操作系统要求:
Python 3
Systemd(即系统可以使用systemctl管理服务,目前主流的linux都可以。比如Debian10+、Ubuntu20+、CentOS7+、RHEL7+)
有Podman或者Docker来运行容器
时间同步(比如chrony或者NTP)
LVM2作为暂存设备
由于openstack官方推荐Ubuntu Server部署云计算,ceph作为openstack的底层设施,所以本案例就使用Ubuntu Server 20.04作为操作系统。
由于Ubuntu Server20.04自带python3+systemd+lvm2,而docker不用你手动装,创建集群的时候会自动安装,所以你只要做好linux时间同步即可,命令如下。
服务器有外网访问能力
# 下载安装NTP
apt -y install ntp
# 设置时区
timedatectl set-timezone Asia/Shanghai
服务器没有外网访问能力
需要在内网中部署一个NTP服务器,这台NTP服务器需要访问公网,其他服务器通过内网连接这台NTP服务器获取原子时钟时间。
NTP服务器端设置
apt -y install ntp
# 清空配置文件
echo '' > /etc/ntp.conf
vim /etc/ntp.conf
# 文件中写入以下信息,同步阿里云时间服务器的时间。
server ntp.aliyun.com
# 重启NTP服务
systemctl restart ntp
systemctl enable ntp
# 设置时区
timedatectl set-timezone Asia/Shanghai
其他内网服务器连接NTP服务器
# 离线安装NTP。(没有外网)
# 配置文件
echo '' > /etc/ntp.conf
vim /etc/ntp.conf
# 文件中写入一下信息
server 10.0.1.15 # 这里换成你的NTP服务器内网地址
# 重启NTP服务
systemctl restart ntp
systemctl enable ntp
安装cephadm
以下内容来自官方文档。
cephadm的功能
cephadm命令可以:
- 创建新群集
- 启动一个带Ceph CLI命令行的容器化shell
- 帮助调试容器化Ceph守护进程
两种安装方式
安装cephadm有两种方法:
一种是基于curl的通用安装方法 。
另一种是各自linux发行版的特定安装方法。
任选一个进行安装,as you like.
基于curl安装cephadm
执行以下命令
# 下载二进制命令程序包,速度20kb/s。嫌慢的同志使用下一种方法
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/quincy/src/cephadm/cephadm
# 命令添加可执行权限
chmod +x cephadm
# 验证cephadm命令是否可用
./cephadm --help
# 其实到这一步,cephadm就已经能够部署集群了,但是没有安装全部功能,也没有把命令安装成操作系统命令
# 添加ceph指定版本的系统包镜像源,这里我们安装quincy版。本地apt或yum库中会多出一些镜像地址。
./cephadm add-repo --release quincy
# 开始安装cephadm命令
./cephadm install
# 验证cephadm已经成为系统命令
which cephadm
# 返回应该是这样 /usr/sbin/cephadm , 表示安装成功
各自linux发行版的特定安装方法
一些Linux发行版可能已经包含了最新的Ceph包。在这种情况下,您可以直接安装cephadm。例如:
Ubuntu:
apt install -y cephadm
CentOS Stream
dnf search release-ceph
dnf install --assumeyes centos-release-ceph-quincy
dnf install --assumeyes cephadm
Fedora:
dnf -y install cephadm
openSUSE或SLES
zypper install -y cephadm
在部署ceph前先花10分钟给各位看官扫盲(原创)
ceph分布式存储的整体架构
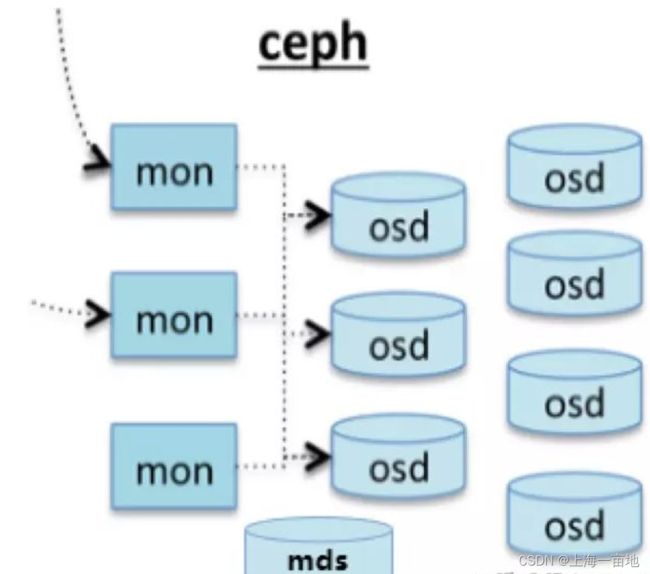
此图看不懂不要紧,花30秒看个形状就行了。当你读完我写的名词解释你就明白了

一些ceph的名词解释
当你通过ceph面板或客户端登录到ceph集群后,你们看到3个服务:RADOS GW、RBD、CEPH FS。
RADOS GW:全称是RADOS Gateway,顾名思义,是个网关。它提供对象存储服务,像华为云、腾讯云网页上你们花钱买到的对象存储服务器基本上就是它提供的。它将RADOS对象存储服务封装成了一个一个bucket,顾客能买到的就是bucket。bucket怎么用?这里不介绍了,去各家云计算官网上随便买一个玩玩你就会了。注意,GW本身没有对象存储功能,它只是基于RADOS,在RADOS基础之上提供了一个简单的命名空间隔离功能(bucket)。对象存储功能完完全全是RADOS提供的。
RBD: reliable block device。它提供块存储服务。云服务器系统盘在后台实际上是一个大文件,用过vmware的同学都清楚。当你在云计算网页上购买了一台云服务器ECS,你的系统盘放在哪里?就在RBD里,块存储相比普通硬盘的优势是,它适合存储超大文件,比如你的系统盘镜像动辄一百多GB。云服务器创建和更换操作系统速度为什么那么快?实际上在RBD里预先创建了无数个各种操作系统的云盘了,用户购买后只要云服务器只要连到RBD里就能获取系统盘了。
CEPH FS :它提供文件系统服务。说白了,通过网络连接FS就能创建文件夹、存放文件了。你可以把它理解成百度网盘。文件系统擅长处理和保存小文件。这也就是为什么百度网盘禁止没有充会员的用户上传30GB以上的文件的原因。
Ceph Storage Cluster:中文名是Ceph存储集群,前面的三大服务的安装需要基于Ceph存储集群。一个Ceph存储集群包括OSD设备、MON设备、librados接口。所以Ceph存储集群包含的守护进程有osd进程、mon进程、ceph-manager进程。
Ceph Cluster:在Ceph存储集群中,去掉所有的OSD设备,剩下的部分就是Ceph集群。Ceph集群直接由cephadm bootstrap命令创建出来。
LIBRADOS:是ceph服务中的基础接口,以上的三大服务都是基于LIBRADOS中的一堆散碎接口封装出来的。三大服务和LIBRADOS的关系就相当于系统命令和cpu指令集的关系。LIBRADOS存在的意义就是将RADOS中无数个细小的功能封装成接口,供后续三大服务和客户端的再封装和使用
RADOS:A reliable,automomous,distributed object storage.提取首字母就是RADOS。它是ceph最底层的功能模块,是一个无限可扩容的对象存储服务,能将文件拆解成无数个对象(碎片)存放在硬盘中,大大提高了数据的稳定性。一个RADOS服务由OSD和Monitor两个组件组成。OSD和Monitor都可以部署在1-n个硬盘中,这就是ceph分布式的由来,高扩展性的由来。
OSD:Object Storage Device。是分布式存储系统的基本单位,物理意义上对应一块硬盘。这个服务包含操作系统(linux)和守护进程(OSD daemon)。所以一台服务器上插了很多块硬盘,就能创建很多个OSD。我甚至见过有个哥们买了一台服务器,买了一个大硬盘架子,薅羊毛薅到极致,服务器快累死了。
Monitor: 很多博客和文档里把它简写成Mon。它的功能是提供集群运行图。用户登录ceph客户端后,首先会连接Mon获取集群运行图,知道某某文件保存在哪些OSD上,随后直接和这些OSD通信,获取文件。集群运行图中包含很多信息,包括:Monitor Map、OSD Map、PG Map、Crush算法Map、MDS Map。由于用户每次读取文件,只是从Monitor中拿一个json,所以Monitor程序的压力不是很大。ceph速度快,硬件开销小,十分优秀。
POOL:多个OSD组成的存储池。ceph管理员可以将多个OSD组成一个池子,存储池是软件层面规划出来的的,物理上不真实存在。ceph在安装的时候会自动生成一个default池。你可以根据自己的业务需求分配不同容量的存储池。你也可以把机械硬盘划到一个存储池而把所有SSD划分到另一个存储池。Pool中数据保存方式有多副本和纠删码两种形式。多副本模式下,一个块文件默认保存3分,放在不同的故障域中,可以吧多副本模式用raid1去类比。而纠删码更像是raid5,对cpu消耗稍大,但是节约磁盘空间,文件只有1份。
MDS:元数据服务器。负责提供CEPH FS文件系统的元数据。元数据记录了目录名、文件所有者、访问模式等信息。MDS设备只对Ceph FS服务。如果你不需要部署FS,则无需创建MDS。它存在的意义是保证用户读写文件时才唤醒OSD,如果用户只是ls看一下文件,则不会启动OSD,这样减轻ceph集群的压力。
心跳:OSD和OSD之间会时刻检查对方的心跳。OSD和Mon之间也会检查心跳。以保证服务正常,网络通畅。一旦任何组件心跳异常,就会从集群中摘除。由其他组件继续提供服务。ceph集群扩容后,心跳检查的范围也会扩大。我相信ceph算法不会让每个OSD去检查其他所有的OSD的,这样系统负载太高。心跳检查不重不漏即可,一定会有一个分配心跳检查任务的算法,做到负载最低。
ceph是如何寻址的
当你要存放一个文件,ceph并不是将整个文件存放在某个硬盘中,而是将文件打碎,存放在不同的OSD(硬盘)中,并且默认每个文件对象保存3个副本,当某块硬盘坏了,也没事,通过ceph内部的映射算法,从别的OSD拼出你想要的文件。提高了安全性和硬盘的寿命,而且每块硬盘的负载都是差不多的。
PG:原先ceph开发人员想把对象直接映射到OSD上,但是发现分布不太均匀,原因是hash算法的的出的数据有大有小。而且每次哈希计算的结果不唯一。为了保证均匀且唯一,ceph开发团队创新性的设计了PG层。其算法较为复杂。
Crush算法非常高级,感兴趣的朋友可以去研究源代码。Crush兼顾了硬盘负载均衡(提出虚拟节点)、数据迁移需又快又少、故障域隔离3个因素,所以此处代码编写人员都是世界级大牛。
部署前的架构规划
主机是带系统盘的,系统盘内已经安装好Ubuntu Server20.04。额外硬盘连接主机。
今后集群中的每台主机上的系统盘内运行1个Monitor进程,每块额外盘内运行一个OSD。以此看来,每台主机就运行着一个RADOS服务。多台主机的Monitor做高可用后,形成一个大的分布式存储服务。经考证,每台节点只能运行一个Monitor程序,暂时没办法让一台节点同时运行多个Mon。如果有大神知道单节点如何通过cephadm部署多个Mon,请评论区留言。
单节点唯一的不足就是MON只有一个,如果Mon程序崩溃,则ceph服务无法访问。官方文档推荐一个ceph集群至少有5台主机,多个Mon形成集群,假设某个主机A的Mon瘫痪了,这台主机的OSD可能还是正常的,用户依然可以从别的主机Mon中获取运行图,然后从主机A上拿数据,最后尝试修复或者重启主机A上的Mon。
我的实际架构
服务器为华为RH1288v3老式服务器,服务器上插了8块300GB的SSD固态硬盘。其中1号和2号槽位的SSD做了Raid1,用于安装操作系统,剩余6块单盘各自独立,每块单盘做raid0(单盘不做raid的话阵列卡是不会激活这块硬盘,将导致操作系统识别不到硬盘设备)。操作系统里部署Mon,6块盘中每块运行一个OSD。服务器内网ip是10.0.1.15
创建一个新Ceph集群
使用cephadm bootstrap命令引导出一个新的Ceph集群。
确定主机内网ip
ceph的服务器是不需要公网的,openstack通过内网访问ceph,内网每个网口都是千兆以上,速度快成本小。
官方文档翻译:
创建新Ceph集群的第一步是在Ceph集群的第一台主机上运行cephadm bootstrap命令。在Ceph集群的第一台主机上运行cephadm bootstrap命令的行为将创建Ceph集群的第一个“监视器守护进程”,该监视器守护进程需要一个IP地址。您必须将Ceph集群的第一台主机的IP地址传递给Ceph bootstrap命令,因此您需要知道该主机的IP地址。如果主机有多个网络和接口,请确保选择任何访问Ceph集群的主机都可以访问的网络和接口。
开始创建
我的服务器内网是 10.0.1.15,所以执行引导命令
# 命令格式是:cephadm bootstrap --mon-ip 此命令将:
为本地主机上的新群集创建监视器和管理器守护进程。 (此时已经有了Monitor和manager进程了!)
为Ceph集群生成一个新的SSH密钥,并将其添加到根用户的/root/.SSH/authorized_keys文件中。
将公钥的副本写到/etc/ceph/ceph.pub。
向/etc/ceph/ceph.conf编写一个最小的配置文件。需要此文件与新集群通信。
写一个client.admin administrative(特权!)的副本/etc/ceph/ceph.client.admin.keyring的密钥。
将_admin标签添加到引导主机。默认情况下,任何具有此标签的主机都将(也)获得/etc/ceph/ceph.conf和/etc/ceph/ceph.client.admin.keyring的副本。
我的服务器实际运行效果
root@ceph001:~# cephadm bootstrap --mon-ip 10.0.1.15
Creating directory /etc/ceph for ceph.conf
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit systemd-timesyncd.service is enabled and running
Repeating the final host check...
podman|docker (/usr/bin/docker) is present
systemctl is present
lvcreate is present
Unit systemd-timesyncd.service is enabled and running
Host looks OK
Cluster fsid: 02df09fe-145e-11ed-b5d6-a5a41289fd2a
Verifying IP 10.0.1.15 port 3300 ...
Verifying IP 10.0.1.15 port 6789 ...
Mon IP 10.0.1.15 is in CIDR network 10.0.0.0/19
Pulling container image quay.io/ceph/ceph:v15...
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting mon public_network...
Creating mgr...
Verifying port 9283 ...
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Wrote config to /etc/ceph/ceph.conf
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/10)...
mgr not available, waiting (2/10)...
mgr not available, waiting (3/10)...
mgr not available, waiting (4/10)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 5...
Mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to to /etc/ceph/ceph.pub
Adding key to root@localhost's authorized_keys...
Adding host ceph001...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Enabling mgr prometheus module...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 13...
Mgr epoch 13 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://ceph001:8443/
User: admin
Password: aexbgvnfsp
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 02df09fe-145e-11ed-b5d6-a5a41289fd2a -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.
bootstrap完成后服务器上会有docker,docker中有如下容器:
prometheus+grafana作为监控系统,alertmanager提供告警功能(集群有异常会发送邮件或短信),node-exporter将主机暴露给ceph集群,让别的服务器直连访问OSD。ceph-mon容器提供Monitor守护进程,为集群提供集群运行图。ceph-mgr其实是ceph manager守护进程,为集群提供librados接口。ceph-crash是Crush算法容器。
root@ceph001:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4d6ed1a0d9c0 quay.io/ceph/ceph-grafana:6.7.4 "/bin/sh -c 'grafana…" About a minute ago Up About a minute ceph-02df09fe-145e-11ed-b5d6-a5a41289fd2a-grafana.ceph001
6156a15ff897 quay.io/prometheus/alertmanager:v0.20.0 "/bin/alertmanager -…" About a minute ago Up About a minute ceph-02df09fe-145e-11ed-b5d6-a5a41289fd2a-alertmanager.ceph001
f7885969c1f2 quay.io/prometheus/prometheus:v2.18.1 "/bin/prometheus --c…" About a minute ago Up About a minute ceph-02df09fe-145e-11ed-b5d6-a5a41289fd2a-prometheus.ceph001
eed46f141dab quay.io/prometheus/node-exporter:v0.18.1 "/bin/node_exporter …" About a minute ago Up About a minute ceph-02df09fe-145e-11ed-b5d6-a5a41289fd2a-node-exporter.ceph001
e65c6f2c4ce2 quay.io/ceph/ceph:v15 "/usr/bin/ceph-crash…" 2 minutes ago Up 2 minutes ceph-02df09fe-145e-11ed-b5d6-a5a41289fd2a-crash.ceph001
c7f498df5ef0 quay.io/ceph/ceph:v15 "/usr/bin/ceph-mgr -…" 3 minutes ago Up 3 minutes ceph-02df09fe-145e-11ed-b5d6-a5a41289fd2a-mgr.ceph001.tzhkiq
52595acae9ca quay.io/ceph/ceph:v15 "/usr/bin/ceph-mon -…" 3 minutes ago Up 3 minutes ceph-02df09fe-145e-11ed-b5d6-a5a41289fd2a-mon.ceph001
到此,一个ceph集群算是创建出来了,ceph集群包括了Mon进程+librados接口。只要我们再安装OSD,一个完全的Ceph存储集群就创建好了。目前这个ceph没有存储的功能,仅仅是个管理器。
补充知识(可不看):有关cephadm bootstrap的进一步信息
上文这种默认的引导行为将适用于大多数用户。但是如果您想立即了解更多关于cephadm引导程序的信息,请阅读下面的列表。 此外,您还可以运行cephadm bootstrap-h来查看cephadm的所有可用选项。
- 日志:默认情况下,Ceph守护进程将其日志输出发送到stdout/stderr,由容器运行时(docker或podman)拾取并(在大多数系统上)发送到Journald。如果希望Ceph将传统日志文件写入/var/log/Ceph/$fsid,请在引导过程中使用–log-to-file选项。
- 子网:当(Ceph集群外部)公共网络通信量与(Ceph集群内部)集群通信量分开时,较大的Ceph集群的性能更好。内部群集通信处理OSD守护进程之间的复制、恢复和心跳。您可以通过向bootstrap子命令提供–cluster-network选项来定义集群网络。此参数必须以CIDR表示法定义子网(例如10.90.90.0/24或FE80::/64)。
- 配置文件路径:cephadm引导程序将访问新集群所需的文件写入/etc/ceph。这个中心位置使得安装在主机上的Ceph包(例如,允许访问cephadm命令行界面的包)能够查找这些文件。 但是,使用cephadm部署的守护进程容器根本不需要/etc/ceph。使用–output-dir**选项将它们放在不同的目录中(例如。)。这可能有助于避免与同一主机上现有的Ceph配置(cephadm或其他)发生冲突。
- 指定其他INI配置:您可以通过将任何初始Ceph配置选项放在标准INI样式的配置文件中,并使用–config**选项,将它们传递给新集群。例如:
cat <<EOF > initial-ceph.conf
[global]
osd crush chooseleaf type = 0
EOF
./cephadm bootstrap --config initial-ceph.conf ...
- 更换用户:使用–ssh-user选项,可以选择cephadm将使用哪个ssh用户连接到主机。关联的ssh密钥将添加到/home//.ssh/authorized_keys。使用此选项指定的用户必须具有无密码的sudo访问权限。
- 私有镜像库:如果在需要登录的经过身份验证的注册表上使用容器,则可以添加参数: --registry-json 带有登录信息的JSON文件的示例内容:
{"url":"REGISTRY_URL", "username":"REGISTRY_USERNAME", "password":"REGISTRY_PASSWORD"}
Cephadm将尝试登录到这个注册表,以便它可以拉出您的容器,然后将登录信息存储在其配置数据库中。然后,添加到集群中的其他主机也将能够使用经过身份验证的注册表。
7. 有关使用cephadm引导程序的其他示例,请参见不同的部署方案。
举例
cephadm bootstrap --mon-ip 10.0.1.15 --log-to-file
cephadm bootstrap --mon-ip 10.0.1.15 --cluster-network 10.0.0.0/19
cephadm bootstrap --mon-ip 10.0.1.15 --output-dir /ceph/
cephadm bootstrap --mon-ip 10.0.1.15 --ssh-user myceph
cephadm bootstrap --mon-ip 10.0.1.15 --registry-json {"url":"REGISTRY_URL", "username":"REGISTRY_USERNAME", "password":"REGISTRY_PASSWORD"}
安装ceph命令
由于cephadm命令无法创建和修改OSD设备,所以需要安装ceph命令。
Cephadm不需要在主机上安装任何Ceph包(所以主机上的操作系统没有ceph命令)。但是,我们建议几种方法可以轻松使用ceph命令。方法如下:
- 执行cephadm shell命令后会在所有安装了Ceph包的容器中启动一个bash shell,这样就能使用ceph命令了。默认情况下,如果在主机上的/etc/ceph中找到配置和keyring文件,就会将它们传递到容器环境中,以便这个bash shell能够完全发挥其功能。请注意,当在MON主机上执行cephadm shell命令时,将从MON容器中获得配置,而不是使用主机上的默认配置。如果在使用cephadm shell命令中给定了–mount
,那么主机上的这个path(文件或目录)将出现在容器内的/mnt下面:
# 执行这条命令后,你会发现你带着主机上的配置和key进入到容器里面了。效果类似于docker exec
cephadm shell
- 为了执行ceph命令,你也可以直接在主机上这样:
cephadm shell -- ceph -s
- 您可以安装ceph-common包,其中包含所有ceph命令,包括ceph、rbd、mount.ceph(用于挂载CephFS文件系统)等:
# 执行以下命令安装ceph-common包
cephadm add-repo --release quincy
cephadm install ceph-common
# 检验ceph命令在主机上安装成功
ceph -v
# 检验主机上的ceph命令能成功连接集群,获取集群状态
ceph status
安装OSD
主机上的每块非系统硬盘都可作为一个OSD。但是能安装OSD的硬盘必须满足以下条件:
- 硬盘设备不能有分区
- 硬盘设备不能被其他LVM占用或声明
- 硬盘设备不能已挂载
- 硬盘不能包含文件系统
- 硬盘设备不能是包含Ceph Bluestore存储引擎的OSD
- 硬盘设备不能小于5GB
查看主机目前已有的OSD
我的额外盘有6块,每块300GB的SSD。
# 查看集群目前所有的OSD设备
ceph orch device ls
-------------------------------------------------------------------------------------
Hostname Path Type Serial Size Health Ident Fault Available
ceph001 /dev/sdb hdd 6101b5442bcc70002a7e2d75a26a9cfe 298G Unknown N/A N/A Yes
ceph001 /dev/sdc hdd 6101b5442bcc70002a7e304acda0f8ed 298G Unknown N/A N/A Yes
ceph001 /dev/sdd hdd 6101b5442bcc70002a7e304acda10a7f 298G Unknown N/A N/A Yes
ceph001 /dev/sde hdd 6101b5442bcc70002a7e304acda11aed 298G Unknown N/A N/A Yes
ceph001 /dev/sdf hdd 6101b5442bcc70002a7e304acda12c7f 298G Unknown N/A N/A Yes
ceph001 /dev/sdg hdd 6101b5442bcc70002a7e304acda13dde 298G Unknown N/A N/A Yes
# 注意Available是Yes的,表示这个设备满足条件,可以安装成为OSD,如果是No表示设备已经是OSD了,或者设备无法安装OSD。
# 指定查看某一台机器的OSD
# 格式是:ceph orch device ls [--hostname=...] [--wide] [--refresh]
ceph orch device ls --hostname=10.0.1.15 --wide --refresh
自动安装OSD
# 测试一下机器上哪些硬盘是可以安装OSD的,--dry-run不会真的安装OSD的
ceph orch apply osd --all-available-devices --dry-run
# 正式开始自动安装。下方命令会自动检查本机符合上述条件的所有硬盘设备,然后每块盘安装OSD
ceph orch apply osd --all-available-devices
# 检验自动创建的结果是不是你想要的
ceph orch device ls
--------------------------------------------------------------------------------------------
Hostname Path Type Serial Size Health Ident Fault Available
ceph001 /dev/sdb hdd 6101b5442bcc70002a7e2d75a26a9cfe 298G Unknown N/A N/A No
ceph001 /dev/sdc hdd 6101b5442bcc70002a7e304acda0f8ed 298G Unknown N/A N/A No
ceph001 /dev/sdd hdd 6101b5442bcc70002a7e304acda10a7f 298G Unknown N/A N/A No
ceph001 /dev/sde hdd 6101b5442bcc70002a7e304acda11aed 298G Unknown N/A N/A No
ceph001 /dev/sdf hdd 6101b5442bcc70002a7e304acda12c7f 298G Unknown N/A N/A No
ceph001 /dev/sdg hdd 6101b5442bcc70002a7e304acda13dde 298G Unknown N/A N/A No
# Available是No就对了,表示OSD安装成功!
# 查看集群信息,显示OSD容量
ceph status
-------------------------------------------------------------------
cluster:
id: 02df09fe-145e-11ed-b5d6-a5a41289fd2a
health: HEALTH_WARN
Degraded data redundancy: 1 pg undersized
services:
mon: 1 daemons, quorum ceph001 (age 4h)
mgr: ceph001.tzhkiq(active, since 4h)
osd: 6 osds: 6 up (since 10m), 6 in (since 10m); 1 remapped pgs
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 6.0 GiB used, 1.6 TiB / 1.6 TiB avail
pgs: 1 active+undersized+remapped
progress:
Rebalancing after osd.1 marked in (10m)
[............................]
# 如果有硬盘遗漏了没有创建OSD,请先检查它是否满足上述条件,然后手动安装OSD
# 格式:ceph orch daemon add osd **:**
ceph orch daemon add osd 10.0.1.15/dev/sdc
注意,执行上面的自动安装命令会产生两个效果:
- 如果你向集群添加硬盘,新硬盘会自动创建OSD
- 如果你移除OSD并清除上面的物理卷(PV),集群就会给这个硬盘自动创建新的OSD并迁移数据到硬盘上。
如果想禁用这两个自动化效果,使用以下命令:
ceph orch apply osd --all-available-devices --unmanaged=true
移除OSD
删除命令
ceph orch osd rm <osd_id(s)> [--replace] [--force]
删除过程时间有点长,因为ceph需要先移除OSD上映射的PG。如果中途你想停止删除OSD,使用以下命令。
ceph orch osd rm stop <osd_id(s)>
擦除机器
当你想下线整台主机,则需要删除其上的所有OSD,使用以下命令:
ceph orch device zap <hostname> <path>
到此,ceph存储集群部署完成了!
我们其实已经通过cephadm命令+ceph命令完完全全安装了一个ceph存储集群。
当ceph storage cluster部署完成后,你可以随意扩容和减少主机或OSD。通过之前的名词解释您知道,
总结一下cephadm。它可以创建集群、创建ceph shell、管理守护进程。一旦集群创建成功后,它的使命就完成了,以后很少再用它了。
ceph命令才是真正用来管理集群的,命令有几百条,涵盖ceph所有的功能。
但是目前还无法使用ceph来存储文件,需要再安装三大服务(GW、RBD、FS)。三大服务才是用户真正想要的,到目前为止的劳动没有回报。革命尚未成功,同志仍需努力!
Ceph 存储集群介绍(包含librados)
官方文档:
Ceph Storage Cluster,即Ceph存储集群,是所有Ceph部署的基础。基于RADOS,Ceph存储集群由几种类型的守护进程组成:
- Ceph OSD守护进程(OSD),将数据作为对象存储在存储节点上
- Ceph监视器(MON),维护集群映射的主副本。
- Ceph Manager Manager守护进程
Ceph存储集群可能包含数千个存储节点。一个最小的系统至少有一个Ceph监视器和两个用于数据复制的Ceph OSD守护进程。 Ceph文件系统、Ceph对象存储和Ceph块设备从Ceph存储集群读取数据和向Ceph存储集群写入数据。
说人话:
Ceph存储集群=RADOS+librados,代表Ceph所有设备和守护进程。其实就是个概念,本质上还是通过ceph命令管理底层设备。
安装RADOS时,cephadm会顺带安装librados接口,所以存储集群安装工作通过cephadm已经搞定了,默认配置也足够使用了,但是如果你有些特殊场景需要定制ceph,则不得不研究它的配置。
官方文档地址:
https://docs.ceph.com/en/quincy/rados/configuration/
OSD后端
OSDs有两种方式管理它们存储的数据。在Luminous 12.2.z及以后的发行版中,默认(也是推荐的)后端是BlueStore。在Luminous发布之前,默认(也是唯一的选项)是FileStore。
Bluestore:
BlueStore是一个特殊用途的存储后端,专门为Ceph OSD工作负载管理磁盘上的数据而设计。BlueStore的设计是基于十年来支持和管理Filestore OSDS的经验。
BlueStore的主要功能包括:
- 直接管理存储设备。BlueStore使用原始块设备或分区。这样就避免了抽象层的介入(例如本地文件系统,如XFS),因为抽象层会限制性能或增加复杂性。
- 使用RocksDB进行元数据管理。RocksDB的键/值数据库是嵌入式的,以便管理内部元数据,包括将对象名称映射到磁盘上的块位置。
- 完整数据和元数据校验和。默认情况下,写入BlueStore的所有数据和元数据都受一个或多个校验和的保护。未经验证,不会从磁盘读取或返回给用户任何数据或元数据。
- 内联压缩。数据在写入磁盘之前可以选择性地进行压缩。
- 多设备元数据分层。BlueStore允许将其内部日志(预写日志)写入单独的高速设备(如SSD、NVMe或NVDIMM),以提高性能。如果有大量更快的可用存储,则可以将内部元数据存储在更快的设备上。
- 高效的写时复制。RBD和CephFS快照依赖于在BlueStore中有效实现的即写即复制克隆机制。这将为常规快照和擦除编码池(依赖克隆实现高效的两阶段提交)带来高效的I/O。
Filestore:
FileStore是在Ceph中存储对象的遗留方法。它依赖于一个标准文件系统(通常是XFS),并结合一个键/值数据库(传统上是LevelDB,现在是RocksDB),用于某些元数据。
FileStore经过了良好的测试,在生产中得到了广泛的应用。然而,由于它的总体设计和对传统文件系统的依赖,使得它在性能上存在许多不足。
尽管FileStore能够在大多数与POSIX兼容的文件系统(包括btrfs和ext4)上运行,但我们建议只将XFS文件系统与Ceph一起使用。btrfs和ext4都有已知的bug和缺陷,它们的使用可能会导致数据丢失。默认情况下,所有Ceph配置工具都使用XFS。
GW对象存储
GW与Openstack Swift集成提供对象存储服务
三大服务的配置有很多,各个公司在各个场景下的应用也不同,如果我介绍所有配置,写100篇文档都不够。本文只介绍三大服务如何与Openstack集成。
官方文档地址:https://docs.ceph.com/en/quincy/radosgw/
GW支持亚马逊S3对象存储服务和Openstack Swift组件提供的对象存储。
未完待续。
RBD块存储
官方文档地址:https://docs.ceph.com/en/quincy/rbd/
RBD基于Ceph Storage Cluster,对外部客户端提供块存储服务。
基本安装和基础命令
想要创建RBD,首先确保Ceph存储集群正常运行。然后RBD的创建分为三步走:
- 必须先创建一个存储池pool
格式: ceph osd pool create <pool-name>
# 举例:创建一个名叫volumes的存储池
ceph osd pool create volumes
- 使用rbd命令初始化这个pool,这个pool就拥有了RBD的块存储服务能力。
格式:rbd pool init <pool-name>
# 举例:初始化刚创建的存储池volumes
rbd pool init volumes
- 创建一个普通用户,使用这个普通用户来操作这个pool。ceph 存储集群在创建时会生成一个admin的默认用户,这个用户拥有主机root权限,所以不推荐使用admin用户直接操作RBD服务。常规操作是,你的RBD pool叫什么名字,就创建一个与pool同名的用户,用户的keyring和公钥保存在/etc/ceph目录中。(上文的创建Ceph集群的时候我给出了我的命令返回,其中末尾显示了admin用户和用户的密码。admin用户能管理ceph中的一切服务和设备。)
格式:ceph auth get-or-create client.{ID} mon 'profile rbd' osd 'profile {profile name} [pool={pool-name}][, profile ...]' mgr 'profile rbd [pool={pool-name}]'
# 讲解:通过这个命令,会创建一个用户,并分别指定这个用户对mon、osd、mgr的权限。如果不加pool=xxx,则这个用户能管理整个守护进程。
# mon的权限必须是mon 'profile rbd',因为Mon服务本身就是只读的,你再限制一个只读权限,脱裤子放屁。
# 假设你写了 osd 'profile rbd',则用户能管理所有pool的osd设备。
# 假设你写了osd 'profile rbd pool=xxx',则这个用户可以读写名叫xxx的pool的osd设备。
# 假设你写了osd 'profile rbd-read-only pool=xxx',则这个用户只能读取名叫xxx的pool中的osd数据,不能写入。
# mgr同理,但是最好不要写mgr 'profile rbd',否则A池的管理员能够关闭B池的librados接口,那就糟糕了。
# 举例:
# 创建一个volumes用户,该用户对volumes池拥有读写权限
ceph auth get-or-create client.volumes mon 'profile rbd' osd 'profile rbd pool=volumes' mgr 'profile rbd pool=volumes'
# 创建一个volumes用户,该用户对volumes池拥有只读权限。
ceph auth get-or-create client.volumes mon 'profile rbd' osd 'profile rbd-read-only pool=volumes' mgr 'profile rbd pool=volumes'
ceph auth get-or-create的命令行输出的内容将是指定用户的keyring,同时keyring被写入/etc/ceph/ceph.client.{ID}.keyring文件中。
RBD与Openstack集成,提供块存储和镜像存储
RBD可以和Openstack中的Glance和Cinder组件集成,形成
Openstack上的云服务器的云盘如何存储到RBD中?就涉及到RBD如何绑定Openstack。
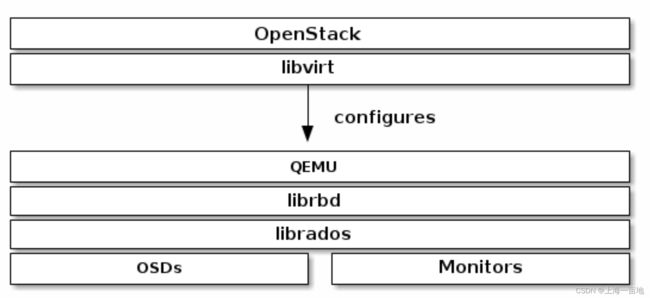
从上图我么你可以看出,在ceph这边,我们需要创建librbd服务和QEMU服务,并将QEMU的地址暴露出去,以后写入Openstack Nova组件的libvirt中,即可实现云服务器云盘的远端存储。
创建ceph Pool
默认情况下,Ceph块设备位于ceph集群的一个名叫rbd的池中。您可以通过显式指定任何合适的池来使用它。我们建议为Openstack的Glance和Cinder组件各创建一个ceph Pool。先确保Ceph集群正在运行,然后我们开始创建池。
ceph osd pool create volumes # 给cinder
ceph osd pool create images # 给glance
ceph osd pool create backups # 给cinder备份用
ceph osd pool create vms # 给nova
初始化pool
rbd pool init volumes
rbd pool init images
rbd pool init backups
rbd pool init vms
FS安装
未完待续
附录一、ceph存储集群添加其他主机(RADOS扩缩容)
使用ceph orch host命令可以管理集群内的主机。
列出集群内的主机
ceph orch host ls [--format yaml] [--host-pattern <name>] [--label <label>] [--host-status <status>]
# 其中可选参数“host-pattern”、“label”和“host-status”用于筛选。
# “host-pattern”是一个regex,它将与主机名匹配,并将只返回匹配的主机
# “label”将只返回具有给定标签的主机
# “host-status”将只返回具有给定状态(当前为“脱机”或“维护”)的主机。
# 这些过滤标志的任何组合都是有效的。您可以同时过滤名称、标签和/或状态
添加主机前,检查一下是否满足条件
这些条件在上文已经给出过,这里重申一次。任何集群内的主机都要满足以下要求。
Python 3
Systemd(即系统可以使用systemctl管理服务,目前主流的linux都可以。比如Debian10+、Ubuntu20+、CentOS7+、RHEL7+)
有Podman或者Docker来运行容器
时间同步(比如chrony或者NTP)
LVM2作为暂存设备
添加主机
将新的主机添加到ceph集群需要两步:实现主机之间的ssh免密登录。添加主机。
- 将集群的ssh公钥安装到新主机的root用户的authorized_keys文件中。
ssh-copy-id -f -i /etc/ceph/ceph.pub root@
比如
ssh-copy-id -f -i /etc/ceph/ceph.pub root@host2
ssh-copy-id -f -i /etc/ceph/ceph.pub root@host3
- 告诉ceph:新主机是集群的一部分。
ceph orch host add <newhost> [<ip>] [<label1> ...]
比如:
ceph orch host add host2 10.10.0.102
ceph orch host add host3 10.10.0.103
最好显式地提供主机IP地址。如果没有提供IP,则主机名将立即通过DNS解析,并使用该IP。
默认情况下,所有带_admin标签的主机都在各自的/etc/ceph目录下维护着一套ceph.conf文件和client.admin密钥环的副本。最初_admin标签只应用于引导主机。我们通常建议为一个或多个其他主机设置_admin标签,以便在多个主机上轻松访问Ceph CLI(例如,通过cephadm shell)。若要将_admin标签添加到其他主机,使用–label:
ceph orch host add host4 10.10.0.104 --labels _admin
你可以对一台主机设置多个label,即一行命令中可以包含多个–label。
移除主机
ceph orch host drain <host>
随后这台机器上的所有OSD将会被调度删除,你可以查看删除进程。
ceph orch osd rm status
你可以确认一下某台机器上已经没有任何ceph相关守护进程了:
ceph orch ps <host>
如果遇到机器故障、宕机或断电,导致不能像上面那样正常移除,你也可以强制移除。
ceph orch host rm <host> --offline --force
集群重新扫描
一些服务器和外部设备在设备删除或插入时没有及时向内核注册(比如机房的人热拔出硬盘,但是内核中还显示这款硬盘是存在的,ceph集群也当这块盘还存在)。在这些方案中,您需要执行主机重新扫描。重新扫描通常是非破坏性的,可以使用以下CLI命令执行:
ceph orch host rescan <hostname> [--with-summary]
–with-summary标签提供了扫描成功、失败等多个状态的数量统计。
ceph orch host rescan rh9-ceph1 --with-summary
Ok. 2 adapters detected: 2 rescanned, 0 skipped, 0 failed (0.32s)