zookeeper的安装部署
目录
简介
Zookeeper架构设计及原理
1.Zookeeper定义
2.Zookeeper的特点
3.Zookeeper的基本架构
4.Zookeeper的工作原理
5.Zookeeper的数据模型
(1)临时节点
(2)顺序节点
(3)观察机制
Zookeeper集群安装前的准备工作
1.配置Hosts文件
2.时钟同步
(1)查看时间类型
(2)修改时间类型
(3)配置NTP服务器
1)检查NTP服务是否已经安装。
2)修改配置文件ntp.conf。
3)启动NTP服务。
4)配置其他节点定时同步时间。
3.集群SSH免密登录
4.JDK安装
1)下载JDK。
2)解压JDK。
3)配置JDK环境变量。
4)检查JDK是否安装成功。
Zookeeper集群的安装部署
1)下载解压Zookeeper。
2)配置Zookeeper。
3)创建Zookeeper数据和日志目录。
4)为Zookeeper集群各个节点创建服务编号。
6)启动Zookeeper集群。
简介
编写单机版的应用比较简单,但是编写分布式应用就比较困难,主要原因在于会出现部分失败。什么是部分失败呢?当一条消息在网络中的两个节点之间传输时,如果出现网络错误,发送者无法知道接收者是否已经收到这条消息,接收者可能在出现网络错误之前就已经收到这条消息,也有可能没有收到,又或者接收者的进程已经“死掉”。发送者只能重新连接接收者并发送咨询请求才能获知之前的信息接收者是否收到。简而言之,部分失败就是不知道一个操作是否已经失败。
Zookeeper是一个分布式应用程序的协调服务,可以提供一组工具,让人们在构建分布式应用时能够对部分失败进行正确处理(部分失败是分布式系统固有的特征,使用Zookeeper并不能避免部分失败)。本节将从Zookeeper架构设计、安装部署以及shell操作等方面进行讲解,帮助读者快速掌握Zookeeper分布式协调服务。
Zookeeper架构设计及原理
Zookeeper作为一个分布式协调系统,为大数据平台其他组件提供了协调服务。要想理解Zookeeper如何对外提供服务,首先需要理解Zookeeper的架构设计和工作原理。
1.Zookeeper定义
Zookeeper是一个分布式的、开源的协调服务框架,服务于分布式应用。它是Google的Chubby组件的一个开源实现,是Hadoop和HBase的重要组件。
●它提供了一系列的原语(数据结构)操作服务,因此分布式应用能够基于这些服务,构建出更高级别的服务,比如分布式锁服务、配置管理服务、分布式消息队列、分布式通知与协调服务等。
● Zookeeper设计上易于编码,数据模型构建在树形结构目录风格的文件系统中。
● Zookeeper运行在Java环境上,同时支持Java和C语言。
2.Zookeeper的特点
Zookeeper工作在集群中,对集群提供分布式协调服务,它提供的分布式协调服务具有如下的特点。
●最终一致性:客户端不论连接到哪个Server,看到的都是同一个视图,这是Zookeeper最重要的特点。
●可靠性:Zookeeper具有简单、健壮、良好的性能。如果一条消息被一台服务器接收,那么它将被所有的服务器接收。
●实时性:Zookeeper保证客户端将在一个时间间隔范围内,获得服务器更新的信息或服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新的数据,应该在读数据之前调用sync( )接口。
●等待无关(wait-free):慢的或失效的客户端不得干预快速客户端的请求,这就使得每个客户端都能有效地等待。
● 原子性:对Zookeeper的更新操作要么成功,要么失败,没有中间状态。
●顺序性:它包括全局有序和偏序两种。全局有序是针对服务器端,例如,在一台服务器上,消息A在消息B前发布,那么所有服务器上的消息A都将在消息B前发布。偏序是针对客户端,例如,在同一个客户端消息B在消息A后发布,那么执行的顺序必将是先执行消息A然后再执行消息B。所有的更新操作都有严格的偏序关系,更新操作都是串行执行的,这是保证Zookeeper功能正确性的关键。
3.Zookeeper的基本架构
Zookeeper服务自身组成一个集群(2n+1个服务节点最多允许n个失效)。Zookeeper服务有两种角色:一种是主节点(Leader),负责投票的发起和决议,更新系统状态;另一种是从节点(Follower),用于接收客户端请求并向客户端返回结果,在选主过程(即选择主节
点的过程)中参与投票。主节点失效后,会在从节点中重新选举新的主节点。Zookeeper系统架构如图所示。

接下来对Zookeeper系统架构进行简单的解释说明。客户端(Client)可以选择连接到Zookeeper集群中的每台服务端(Server),而且每台服务端的数据完全相同。每个从节点都需要与主节点进行通信,并同步主节点上更新的数据。
对于Zookeeper集群来说,只要超过一半数量的Zookeeper服务端可用,Zookeeper整体服务就可用。
4.Zookeeper的工作原理
Zookeeper的核心是原子广播,该原子广播就是对Zookeeper集群上的所有主机发送数据包,通过这个机制保证了各个服务端之间的数据同步。实现这个机制在Zookeeper中有一个内部协议,此协议有两种模式,一种是恢复模式,一种是广播模式。当服务启动或在主节点崩溃后,此协议就进入了恢复模式,当主节点再次被选举出来,且大多数服务端完成了和主节点的状态同步后,恢复模式就结束了。状态同步保证了主节点和服务端具有相同的系统状态。一旦主节点已经和多数从节点(也就是服务端)进行了状态同步后,它就可以开始广播消息,即进入广播模式。在广播模式下,服务端会接受客户端的请求,所有的写请求都被转发给主节点,再由主节点发送广播给从节点。当半数以上的从节点完成数据的写请求之后,主节点才会提交这个更新,然后客户端才会收到一个更新成功的响应。
5.Zookeeper的数据模型
Zookeeper维护着一个树形层次结构,树中的节点被称为znode。znode可以用于存储数据,并且有一个与之相关联的访问控制列表(Access ControlList,ACL,用于控制资源的访问权限)。Zookeeper被设计用来实现协调服务(通常使用小数据文件),而不是用于存储大容量数据,因此一个znode能存储的数据被限制在1MB以内。znode的树形层次结构如下图所示。从图中可以看到,Zookeeper根节点包含两个子节点/app1和/app2。/app1节点下面又包含了3个子节点,分别为/app1/p_1、/app1/p_2和/app1/p_3。/app2节点也可以包含多个子节点,以此类推,这些节点和子节点形成了树形层次结构。

Zookeeper的数据访问具有原子性。客户端在读取一个znode的数据时,要么读到所有数据,要么读操作失败,不会存在只读到部分数据的情况。同样,写操作将替换znode存储的所有数据,Zookeeper会保证写操作不成功就失败,不会出现部分写成功之类的情况,也就是不会出现只保存客户端所写部分数据的情况。znode是客户端访问Zookeeper的主要实体,它包含了以下主要特征。
(1)临时节点
znode节点有两种:临时节点和持久节点。znode的类型在创建时即确定,之后不能修改。当创建临时节点的客户端会话结束时,Zookeeper会将该临时节点删除。而持久节点不依赖客户端会话,只有当客户端明确要删除该持久节点时才会被真正删除。临时节点不可以有子节点,即使是短暂的子节点。
(2)顺序节点
顺序节点是指名称中包含Zookeeper指定顺序号的znode。如果在创建znode时设置了顺序标识,那么该znode名称之后就会附加一个值,该值是一个单调递增的计数器添加的,由父节点维护。例如,如果一个客户端请求创建一个名为/djt/h-的顺序znode,那么所创建znode的名称可能是/djt/h-1。如果另外一个名为/djt/h-的顺序znode被创建,计数器会给出一个更大的值来保证znode名称的唯一性,znode名称可能为/djt/h-2。在一个分布式系统中,顺序号可用于为所有的事件进行全局排序,这样客户端就可以通过顺序号来推断事件的顺序。
(3)观察机制
znode以某种方式发生变化时,观察(watcher)机制(观察机制:一个watcher事件是一个一次性的触发器,当被设置了watcher的znode发生了改变时,服务器将这个改变发送给设置了watcher的客户端,以便通知它们)可以让客户端得到通知。可以针对Zookeeper服务的操作来设置观察,该服务的其他操作可以触发观察。比如,客户端可以对一个znode调用exists操作,同时在其上设定一个watcher。如果此znode不存在,则客户端所调用的exists操作将会返回false。如果另外一个客户端创建了此znode,那么设定的watcher会被触发,这时就会通知前一个客户端该znode被创建。在Zookeeper中,引入了watcher机制来实现分布式的通知功能。Zookeeper允许客户端向服务端注册一个watcher监视器,当服务端的一些特定事件触发了watcher监视器后,就会向指定客户端发送一个异步事件通知来实现分布式的通知功能。这种机制称为注册与异步通知机制。
Zookeeper集群安装前的准备工作
1.配置Hosts文件
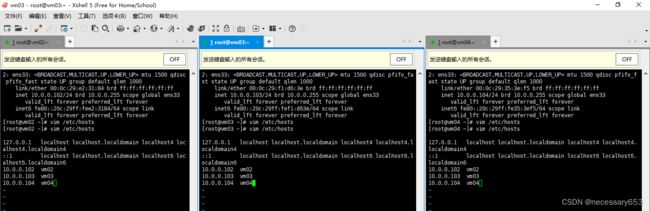
为方便集群节点之间通过hostname相互通信,在hosts文件中分别为每个节点配置hostname与IP之间的映射关系,具体操作如下所示。
[root@vm03 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.102 vm02
10.0.0.103 vm03
10.0.0.104 vm04
~ 
systemctl restart network
2.时钟同步
可以选择vm02节点作为时钟服务器。
(1)查看时间类型
在vm02节点上输入date命令,可以查看到当前系统时间,如下所示。从结果可以看出系统时间为EST(EST表示东部标准时间,即纽约时间),可以把时间改为CST(CST表示中国标准时间)。
[root@vm02 ~]# date
Tue Nov 14 23:24:35 CST 2023
(2)修改时间类型
使用shanghai时间来覆盖当前的系统默认时间,具体操作如下所示。
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
注意:上述操作在集群各个节点都要执行,保证当前系统时间标准为上海时间。
(3)配置NTP服务器
选择vm02节点来配置NTP服务器,集群其他节点定时同步vm02节点时间即可。
1)检查NTP服务是否已经安装。
输入rpm -qa|grep ntp命令查看NTP服务是否安装,操作结果如下所示。
如果NTP服务已经安装,可以直接进行下一步,否则输入yum install -y ntp命令可以在线安装NTP服务。实际上就是安装两个软件,ntpdate-4.2.6p5-12.el6.centos.2.x86_64用来与某台服务器进行同步,ntp-4.2.6p5-12.el6.centos.2.x86_64用来提供时间同步服务。
2)修改配置文件ntp.conf。
修改NTP服务配置,以下是/etc/ntp.conf 的内容片段。
#注释掉以下四行
#增加以下两行
具体操作如下所示。
[root@vm02 ~]# vim /etc/ntp.conf
# For more information about this file, see the man pages
driftfile /var/lib/ntp/drift
restrict default nomodify notrap nopeer noquery
# be tightened as well, but to do so would effect some of
# the administrative functions.
restrict 127.0.0.1
restrict ::1
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
# permit the source to query or modify the service on this system.
restrict default nomodify notrap nopeer noquery
# Permit all access over the loopback interface. This could
# be tightened as well, but to do so would effect some of
# the administrative functions.
restrict 127.0.0.1
restrict ::1
# Hosts on local network are less restricted.
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#注释掉以下四行
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
#增加以下两行
server 127.127.1.0
fudge 127.127.1.0 stratum 10
server 127.127.1.0:指定本地时钟驱动器(Local Clock Driver)作为 NTP 服务器,这个驱动器是 NTP 内建的,由本地计算机的内部时钟提供时间信息。
fudge 127.127.1.0 stratum 10:指定本地时钟驱动器的时钟层级(Stratum)为 10,这个数字越大代表层级越低,相应的准确度更低。由于本地时钟是不可信的,因此将其 stratum 设置为 10,避免与其他更准确的 NTP 服务混淆3)启动NTP服务。
执行chkconfig ntpd on命令,可以保证每次机器启动时,NTP服务都会自动启动,具体操作如下所示。
[root@vm02 ~]# chkconfig ntpd on
Note: Forwarding request to 'systemctl enable ntpd.service'.
Created symlink from /etc/systemd/system/multi-user.target.wants/ntpd.service to /usr/lib/systemd/system/ntpd.service.
4)配置其他节点定时同步时间。
vm03和vm04节点通过Linux crontab命令,可以定时同步vm02节点的系统时间,具体操作如下所示。
[root@vm03 ~]# crontab -e
#每十分钟同步一次时间
*/10 * * * * /usr/sbin/ntpdate vm02
~ 3.集群SSH免密登录
请参照上一篇blogu已做详细介绍。
4.JDK安装
1)下载JDK。
2)解压JDK。
tar -zxvf jdk-8u51-linux-x64.tar.gzln -s jdk1.8.0_51 jdk 3)配置JDK环境变量。
export JAVA_HOME=/jdk/jdk1.8.0_51/
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
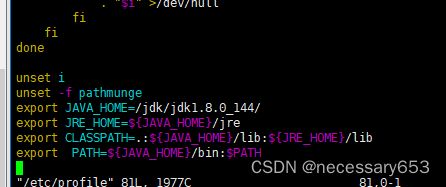
source /etc/profile4)检查JDK是否安装成功。
java -version
Zookeeper集群的安装部署
1)下载解压Zookeeper。
[hadoop@vm03 ~]$ scp apache-zookeeper-3.9.1-bin.tar.gz vm02:/home/hadoop/
apache-zookeeper-3.9.1-bin.tar.gz 100% 19MB 52.4MB/s 00:00
[hadoop@vm03 ~]$ scp apache-zookeeper-3.9.1-bin.tar.gz vm04:/home/hadoop/
apache-zookeeper-3.9.1-bin.tar.gz 100% 19MB 50.0MB/s 00:00 操作如下所示。
tar -zxvf apache-zookeeper-3.9.1-bin.tar.gz
[hadoop@vm03 ~]$ rm -rf apache-zookeeper-3.9.1-bin.tar.gz
[hadoop@vm03 ~]$
[hadoop@vm03 ~]$ ln -s apache-zookeeper-3.9.1-bin/ zookeeper
注:安装有名称有带bin 和不带bin的 选择带bin的会自带有依赖的JAR包,不选带BIN没有配置标准的JDK包 会导致ZK启动失败 Error contacting service. It is probably not running. 的报错。本文虽然配置环境变量CLASSPATH
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib避免读者在实操过程中出现问题依然使用带bin的安装进行演示,此时ZK启动会优先从自带lib查找依赖包。
2)配置Zookeeper。
在运行Zookeeper服务之前,需要新建一个配置文件。这个配置文件习惯上命名为zoo.cfg,并保存在conf子目录中,配置文件的具体内容如下所示.
[hadoop@vm03 ~]$ cd zookeeper/conf/
[hadoop@vm03 conf]$ ll
total 16
-rw-r--r--. 1 hadoop hadoop 535 Oct 4 17:50 configuration.xsl
-rw-r--r--. 1 hadoop hadoop 4559 Oct 4 17:50 logback.xml
-rw-r--r--. 1 hadoop hadoop 1183 Oct 4 17:50 zoo_sample.cfg
[hadoop@vm03 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@vm03 conf]$ vim zoo.cfg
[hadoop@vm03 conf]$ vim zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#日志目录
dataLogDir=/home/hadoop/zookeeper/zklog
#数据目录
dataDir=/home/hadoop/zookeeper/zkdata
# the port at which the clients will connect
#访问ZK的默认端口号
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
#server.节点编号=对应节点的hostname:集群通讯端口:选举端口
server.1=vm02:2888:3888
server.2=vm03:2888:3888
server.3=vm04:2888:3888
该文件中除了配置server编号外 还有几个参数,以下做解释。
·tickTime=2000:这是ZooKeeper服务器的时间单位,以毫秒为单位。此值决定了ZooKeeper服务器中的时间,以及各种超时和会话时间。默认值是2000毫秒(2秒)。
·initLimit=10:这是ZooKeeper服务器初始化时等待客户端完成连接的时间限制(以tickTime为单位)。如果在该时间内没有足够数量的客户端连接到服务器,那么服务器将关闭。默认值是10。
·syncLimit=5:这是ZooKeeper服务器同步其数据给其他服务器的时间限制(以tickTime为单位)。如果在该时间内没有完成数据同步,那么同步将被中止。默认值是5。
·dataLogDir=/home/hadoop/zookeeper/zklog:这是ZooKeeper服务器存储其数据日志的目录。数据日志包含服务器状态的持久化信息。
·dataDir=/home/hadoop/zookeeper/zkdata:这是ZooKeeper服务器存储其数据的目录。数据包含诸如配置文件、事务日志和快照等的信息。
·clientPort=2181:这是ZooKeeper服务器监听的客户端连接端口。默认情况下,ZooKeeper在端口2181上监听来自客户端的连接请求。
3)创建Zookeeper数据和日志目录。
在集群各个节点创建Zookeeper数据目录和日志目录,需要与zoo.cfg配置文件保持一致,具体操作如下所示。
mkdir -p /home/hadoop/zookeeper/zklog
mkdir -p /home/hadoop/zookeeper/zkdata
4)为Zookeeper集群各个节点创建服务编号。
分别在Zookeeper集群各个节点上,进入/home/hadoop/zookeeper/zkdata目录,创建文件myid,然后分别输入服务编号,具体操作如下所示。
[hadoop@vm03 zkdata]$ rm -rf myid
[hadoop@vm03 zkdata]$ touch myid
[hadoop@vm03 zkdata]$ echo "2">>myid
[hadoop@vm03 zkdata]$ cat myid
注意:这里的编号需要和zoo.cfg配置的服务器编号匹配
server.1=vm02:2888:3888
server.2=vm03:2888:3888
server.3=vm04:2888:3888
,且每个节点服务编号的值是一个整数且不能重复。
6)启动Zookeeper集群。
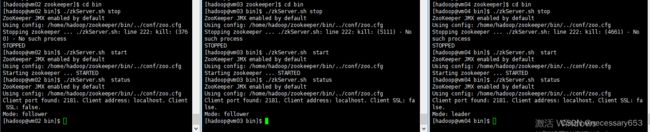
[hadoop@vm03 conf]$ cd ..
[hadoop@vm03 zookeeper]$ cd bin
[hadoop@vm03 bin]$ ./zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... ./zkServer.sh: line 222: kill: (5111) - No such process
STOPPED
[hadoop@vm03 bin]$ ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@vm03 bin]$ ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
Mode: follower 表示该节点为从节点
Mode: leader 表示该节点为主节点
也可以同JPS指令查看zk的启动状态
[hadoop@vm03 bin]$ jps
5306 Jps
5227 QuorumPeerMain
[hadoop@vm03 bin]$
![]()