PostgreSQL中的索引—7(GIN)
目录
GIN
一般概念
全文检索
查询示例
更新缓慢的问题
部分匹配的搜索
频繁词和不频繁词
限制查询结果
紧凑表示
GiST还是GIN?
数组
JSONB
内部构件
属性
其他数据类型
我们已经熟悉了PostgreSQL索引引擎和访问方法的接口,并讨论了哈希索引、B树以及GiST和SP GiST索引。本文将以GIN索引为特色。
GIN
“Gin?..Gin似乎是一种美国酒..”
“我不是酒鬼,哦,好奇的孩子!”老人又一次勃然大怒,他又一次意识到自己,又一次控制住自己。“我不是一种饮料,而是一种强大而无畏的精神,世界上没有我做不到的魔法。”
— Lazar Lagin,“老霍塔比奇”
Gin代表广义倒排索引,应该被视为精灵,而不是饮料。——README
一般概念
GIN是缩写的广义倒排索引(Generalized Inverted Index)。这就是所谓的倒排索引(倒排索引的概念可以参考这篇博文:什么是倒排索引?_starzhou的专栏-CSDN博客_什么是倒排索引)。它处理的数据类型的值不是原子的,而是由元素组成的。我们将这些类型称为复合型。这些不是索引的值,而是单个元素;每个元素都引用它出现的值。
与此方法的一个很好的类比是书末的索引,它为每个术语提供了一个出现此术语的页面列表。访问方法必须确保索引元素的快速搜索(就是能根据术语快速找到它出现的位置,而不是遍历每页的关键词,找到出现的页),就像书中的索引一样。因此,这些元素被存储为一个熟悉的B树(它使用了一个不同的、更简单的实现,但在这种情况下并不重要)。对包含元素复合值的表行的有序引用集链接到每个元素。有序性对于数据检索来说并不重要(TID的排序顺序意义不大),但对于索引的内部结构来说很重要。(后文提到了,这样后一页可以存储与前一页的差异就行)
元素永远不会从索引中删除。人们认为,包含元素的值可以消失、出现或变化,但它们所组成的元素集或多或少是稳定的。这个解决方案大大简化了多个进程并发工作的算法。
如果TID列表非常小,它可以与元素放在同一个页面中(称为“发布列表”)。但是如果列表很大,就需要一个更高效的数据结构,我们已经意识到了这一点——它又是B树。这种树位于不同的数据页上(称为“发布树”)。
因此,GIN索引由元素的B树组成,TID的B树或平面列表链接到该B树的叶行。
就像前面讨论的GiST和SP-GiST索引一样,GIN为应用程序开发人员提供了支持复合数据类型上各种操作的接口。
全文检索
GIN方法的主要应用领域是加速全文搜索,因此,在对该索引进行更详细的讨论时,可以将其用作示例。
这篇与GiST相关的文章已经对全文搜索做了一个小的介绍,所以让我们直接切入主题,不要重复。很明显,本例中的复合值是文档,而这些文档的元素是词素。
让我们将前面GIST相关文章中的例子改为GIN索引:
postgres=# create table ts(doc text, doc_tsv tsvector);
postgres=# insert into ts(doc) values
('Can a sheet slitter slit sheets?'),
('How many sheets could a sheet slitter slit?'),
('I slit a sheet, a sheet I slit.'),
('Upon a slitted sheet I sit.'),
('Whoever slit the sheets is a good sheet slitter.'),
('I am a sheet slitter.'),
('I slit sheets.'),
('I am the sleekest sheet slitter that ever slit sheets.'),
('She slits the sheet she sits on.');
postgres=# update ts set doc_tsv = to_tsvector(doc);
postgres=# create index on ts using gin(doc_tsv);该指数的可能结构如图所示:
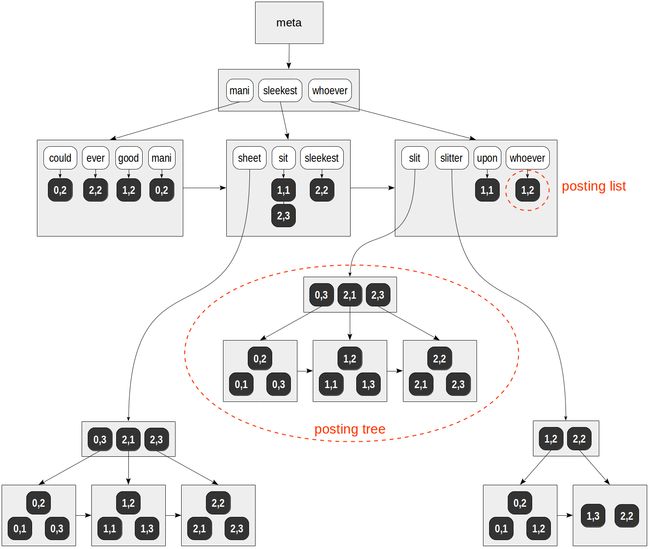
与前面的所有图不同,对表行(TID)的引用是在深色背景上用数值表示的(数值表示页码和页面上的位置),而不是用箭头。
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv
-------+----------------------+---------------------------------------------------------
(0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4
(0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7
(0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8
(1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1
(1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1
(1,3) | I am a sheet slitter | 'sheet':4 'slitter':5
(2,1) | I slit sheets. | 'sheet':3 'slit':2
(2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6
(2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2
(9 rows)在这个推测性的例子中,TID列表中的所有词素都适合常规页面,除了“sheet”、“slit”和“slitter”,这些词素出现在许多文档中,它们的TID列表被放在单个B-树中。
顺便问一下,我们如何计算出有多少文档包含指定词素?对于一个小表,下面显示的“直接”技术将起作用,但我们将进一步了解如何处理较大的表(就是后面使用ts_stat方法)。
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts
group by 1 order by 2 desc;
lexeme | count
----------+-------
sheet | 9
slit | 8
slitter | 5
sit | 2
upon | 1
mani | 1
whoever | 1
sleekest | 1
good | 1
could | 1
ever | 1
(11 rows)还要注意的是,与常规的B-树不同,GIN索引的页面是通过单向列表而不是双向列表连接的。这就足够了,因为树遍历只有一种方式。(因为不会有将包含某一词素的文档按TID存储顺序输出的需求,只会按相关性排序输出需求)
查询示例
对于我们的示例,下面的查询将如何执行?
postgres=# explain(costs off)
select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
---------------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text))
(4 rows)首先从查询中提取独立的词素(搜索键):“mani”和“slitter”。这是由一个专门的API函数完成的,该函数考虑了运算符类确定的数据类型和策略:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'tsvector_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------------+--------------
@@(tsvector,tsquery) | 1 matching search query
@@@(tsvector,tsquery) | 2 synonym for @@ (for backward compatibility)
(2 rows)在词素的B-树中,我们接下来找到两个键,并查看TID的就绪列表。我们得到:
对于“mani”-(0,2).
对于“slitter”- (0,1), (0,2), (1,2), (1,3), (2,2).
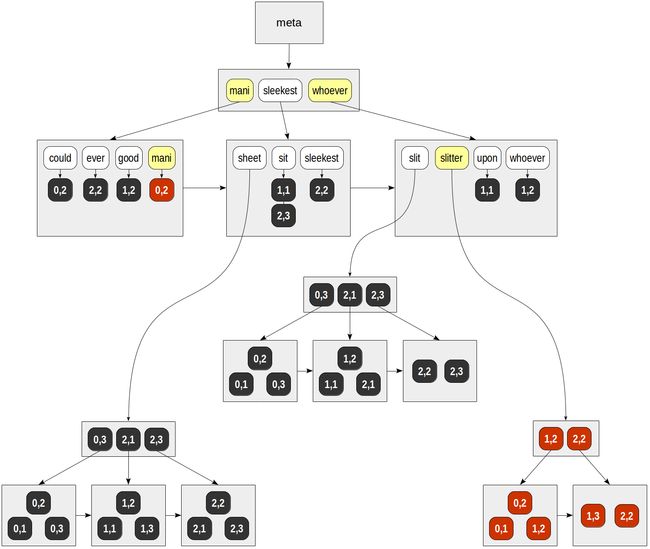
最后,对于找到的每个TID,都会调用一个API一致性函数,该函数必须确定找到的那些行与搜索查询匹配。由于查询中的词素由布尔“and”连接,因此返回的唯一一行是(0,2):
| | | consistency
| | | function
TID | mani | slitter | slit & slitter
-------+------+---------+----------------
(0,1) | f | T | f
(0,2) | T | T | T
(1,2) | f | T | f
(1,3) | f | T | f
(2,2) | f | T | f结果为:
postgres=# select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
doc
---------------------------------------------
How many sheets could a sheet slitter slit?
(1 row)如果我们将这种方法与GiST中已经讨论过的方法进行比较,GIN用于全文搜索的优势就显而易见了。但这其中还有更多东西是看不见的。
更新缓慢的问题
问题是,GIN索引中的数据插入或更新非常缓慢。每个文档通常包含许多要索引的词素。因此,当只添加或更新一个文档时,我们必须大量更新索引树。
另一方面,如果同时更新多个文档,它们的某些词素可能是相同的,并且总工作量将小于逐个更新文档时的工作量。
GIN索引有“fastupdate”存储参数,我们可以在创建索引和以后更新时指定该参数:
postgres=# create index on ts using gin(doc_tsv) with (fastupdate = true);启用此参数后,更新将累积在一个单独的无序列表中(在各个连接的页面上)。当这个列表足够大或在清空过程中,所有累积的更新都会立即对索引进行更新。列表是否足够大是由“gin_pending_list_limit”配置参数或索引的同名存储参数确定的。
但这种方法也有缺点:首先,搜索速度变慢(因为除了树之外,还需要查看无序列表),其次,如果无序列表溢出,下一次更新可能会意外地花费大量时间。
部分匹配的搜索
我们可以在全文搜索中使用部分匹配。例如,考虑下面的查询:
gin=# select doc from ts where doc_tsv @@ to_tsquery('slit:*');
doc
--------------------------------------------------------
Can a sheet slitter slit sheets?
How many sheets could a sheet slitter slit?
I slit a sheet, a sheet I slit.
Upon a slitted sheet I sit.
Whoever slit the sheets is a good sheet slitter.
I am a sheet slitter.
I slit sheets.
I am the sleekest sheet slitter that ever slit sheets.
She slits the sheet she sits on.
(9 rows)此查询将查找包含以“slit”开头的词素的文档。在这个例子中,这样的词素是“slit”和“slitter”。
不管怎样,即使没有索引,查询也肯定能工作,但GIN还允许加快以下搜索速度:
postgres=# explain (costs off)
select doc from ts where doc_tsv @@ to_tsquery('slit:*');
QUERY PLAN
-------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery('slit:*'::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery('slit:*'::text))
(4 rows)在这里,所有具有搜索查询中指定前缀的词素都会在树中查找,并通过布尔“or”连接。(而且看上面的示例图,索引中的词素在B树中,是有序的)
频繁词和不频繁词
为了观察索引如何在实时数据上工作,让我们看一下“pgsql-hacker”电子邮件的存档,我们在讨论GiST时已经使用了它。此版本的存档包含356125条消息,其中包含发送日期、主题、作者和文本。
fts=# alter table mail_messages add column tsv tsvector;
fts=# update mail_messages set tsv = to_tsvector(body_plain);
NOTICE: word is too long to be indexed
DETAIL: Words longer than 2047 characters are ignored.
...
UPDATE 356125
fts=# create index on mail_messages using gin(tsv);让我们考虑一个在许多文档中出现的词素。使用“unnest”的查询将无法处理如此大的数据量,正确的方法是使用“ts_stat”函数,该函数提供词素的信息,有该词素出现的文档数量以及出现的总数。
fts=# select word, ndoc
from ts_stat('select tsv from mail_messages')
order by ndoc desc limit 3;
word | ndoc
-------+--------
re | 322141
wrote | 231174
use | 176917
(3 rows)让我们选择“wrote”。
我们会在开发者的电子邮件中使用一些不常见的词,比如“tattoo”:
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc
--------+------
tattoo | 2
(1 row)这两个词素都出现的文件有哪些?似乎有:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count
-------
1
(1 row)一个问题是如何执行这个查询。如前所述,如果我们得到这两个词素的TID列表,搜索显然效率低下:我们将不得不遍历20多万个值(就是在出现wrote这个词的20多万封邮件中逐个与出现tatoo的文档比较TID值),只剩下其中一个。幸运的是,使用planner统计数据,该算法了解到“writed”词素经常出现,而“tatoo”很少出现。因此,执行对不常见词素的搜索,然后检查检索到的两个文档是否存在“已写”词素。从快速执行的查询中可以清楚地看到:
fts=# \timing on
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count
-------
1
(1 row)
Time: 0,959 ms而仅搜索“wrote”一项就需要相当长的时间:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
--------
231174
(1 row)
Time: 2875,543 ms (00:02,876)这种优化当然不仅适用于两个词素,也适用于更复杂的情况。
限制查询结果
GIN 访问方法的一个特点是,结果总是以位图的形式返回:该方法不能逐个TID返回结果。正因为如此,本文中的所有查询计划都使用位图扫描。
因此,使用LIMIT子句限制索引扫描结果的效率并不高。注意操作的预计成本(“Limit”节点的“cost”字段):(因为都是用的位图扫描,位图的构建时间就决定了需要花很长时间,而不是像索引扫描那样,不需要构建,匹配到一个就返回了)
fts=# explain (costs off)
select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN
-------------------------------------------------------------------------------
Limit (cost=1283.61..1285.13 rows=1)
-> Bitmap Heap Scan on mail_messages (cost=1283.61..209975.49 rows=137207)
Recheck Cond: (tsv @@ to_tsquery('wrote'::text))
-> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..1249.30 rows=137207)
Index Cond: (tsv @@ to_tsquery('wrote'::text))
(5 rows)成本估计为1285.13,略高于构建整个位图1249.30(“Bitmap Index Scan”字段)的成本。
因此,该索引使用特殊手段来限制结果数量。阈值在“gin_fuzzy_search_limit”配置参数中指定,默认情况下等于零(没有限制)。但我们可以设置阈值:
fts=# set gin_fuzzy_search_limit = 1000;
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
-------
5746
(1 row)
fts=# set gin_fuzzy_search_limit = 10000;
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
-------
14726
(1 row)如我们所见,查询返回的行数因参数值不同而不同(如果使用索引访问)。限制并不严格:可以返回比指定的行更多的行,这证明了参数名的“模糊”部分是正确的。
紧凑表示
在其他方面,GIN由于其紧凑性表现很好。首先,如果同一个词素出现在多个文档中(通常是这样),那么它只在索引中存储一次。第二,TID以有序的方式存储在索引中,这使我们能够使用简单的压缩:列表中的每个下一个TID实际上都存储为其与上一个TID的差异;这通常是一个小数字,需要的位比完整的六字节TID少得多。
为了了解(GIN、GiST与B树索引对于相同内容创建的索引)大小,让我们从(邮件的)信息文本中构建B树。但公平的比较(前提)肯定不会发生:
- GIN基于不同的数据类型(“tsvector”而非“文本”)构建,后者更小,
- 同时,B-tree的信息大小必须缩短到大约2KB。
然而,我们继续(默认使用的是B树索引):
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));我们还将建立GiST索引:
fts=# create index mail_messages_gist on mail_messages using gist(tsv);“vacuum full”时索引的大小:
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin,
pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist,
pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree
--------+--------+--------
179 MB | 125 MB | 546 MB
(1 row)由于表示的紧凑性,我们可以尝试在从Oracle迁移的过程中使用GIN索引来替代位图索引(无需详细说明,感兴趣的人可以查看Lewis的文章)。通常,位图索引用于几乎没有唯一值的字段(就是基本用于多选项的字段,比如表示性别的字段),这对于GIN也是非常好的。而且,如第一篇文章所示,PostgreSQL可以基于任何索引(包括GIN)动态构建位图。
GiST还是GIN?
对于许多数据类型,GiST和GIN都可以使用运算符类,这就提出了使用哪个索引的问题。也许,我们已经可以得出一些结论。
一般来说,GIN在准确性和搜索速度上都优于GiST。如果数据更新不频繁,需要快速搜索,那么最有可能的选择就是GIN。
另一方面,如果数据被集中更新,更新GIN的间接成本可能会显得太大。在这种情况下,我们将不得不比较这两个选项,并选择一个其特点更好地平衡。
数组
使用GIN的另一个例子是数组的索引。在这种情况下,数组元素进入索引,这允许在数组上加速许多操作:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'array_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------------+--------------
&&(anyarray,anyarray) | 1 intersection
@>(anyarray,anyarray) | 2 contains array
<@(anyarray,anyarray) | 3 contained in array
=(anyarray,anyarray) | 4 equality
(4 rows)我们的演示数据库有“航线”视图,其中包含航班信息。在其余的视图中,该视图包含“days_of_week”列,这是一个航班在工作日起飞的数组。例如,从Vnukovo飞往Gelendzhik的航班在周二、周四和周日起飞:
demo=# select departure_airport_name, arrival_airport_name, days_of_week
from routes
where flight_no = 'PG0049';
departure_airport_name | arrival_airport_name | days_of_week
------------------------+----------------------+--------------
Vnukovo | Gelendzhik | {2,4,7}
(1 row)为了构建索引,让我们将视图“具体化”到一个表中:
demo=# create table routes_t as select * from routes;
demo=# create index on routes_t using gin(days_of_week);现在,我们可以使用该索引了解周二、周四和周日起飞的所有航班:
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7];
QUERY PLAN
-----------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: (days_of_week = '{2,4,7}'::integer[])
-> Bitmap Index Scan on routes_t_days_of_week_idx
Index Cond: (days_of_week = '{2,4,7}'::integer[])
(4 rows)似乎有六种:
demo=# select flight_no, departure_airport_name, arrival_airport_name, days_of_week from routes_t where days_of_week = ARRAY[2,4,7];
flight_no | departure_airport_name | arrival_airport_name | days_of_week
-----------+------------------------+----------------------+--------------
PG0005 | Domodedovo | Pskov | {2,4,7}
PG0049 | Vnukovo | Gelendzhik | {2,4,7}
PG0113 | Naryan-Mar | Domodedovo | {2,4,7}
PG0249 | Domodedovo | Gelendzhik | {2,4,7}
PG0449 | Stavropol | Vnukovo | {2,4,7}
PG0540 | Barnaul | Vnukovo | {2,4,7}
(6 rows)这个查询是如何执行的?其实与上面的方法完全相同:
- 从在这里扮演搜索查询角色的数组{2,4,7}中,提取元素(搜索关键字)。显然,这些是“2”、“4”和“7”的值。
- 在树的元素中,会找到提取的键,并为每个键选择TID列表。
- 在找到的所有TID中,一致性函数从查询中选择与运算符匹配的TID。对于=运算符,只有三个列表中出现的那些TID与之匹配(换句话说,初始数组必须包含所有元素)。但这还不够:数组还需要不包含任何其他值,我们不能用索引检查这个条件。因此,在这种情况下,访问方法要求索引引擎重新检查随表返回的所有TID。
有趣的是,有些策略(例如,“包含在数组中”)无法检查任何内容,必须重新检查表中找到的所有TID。
但如果我们需要知道周二、周四和周日从莫斯科起飞的航班,该怎么办?索引将不支持附加条件,它将进入“过滤器”列。
demo=# explain (costs off)
select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN
-----------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: (days_of_week = '{2,4,7}'::integer[])
Filter: (departure_city = 'Moscow'::text)
-> Bitmap Index Scan on routes_t_days_of_week_idx
Index Cond: (days_of_week = '{2,4,7}'::integer[])
(5 rows)在这里这是可以的(索引无论如何只选择六行,行数很少),但是在附加条件增加选择能力的情况下,希望有这样的支持。然而,我们不能仅仅创建索引:
demo=# create index on routes_t using gin(days_of_week,departure_city);
ERROR: data type text has no default operator class for access method "gin"
HINT: You must specify an operator class for the index or define a default operator class for the data type.但“btree-gin”扩展将有所帮助,它添加了模拟常规B树工作的gin操作符类。
demo=# create extension btree_gin;
demo=# create index on routes_t using gin(days_of_week,departure_city);
demo=# explain (costs off)
select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN
---------------------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: ((days_of_week = '{2,4,7}'::integer[]) AND
(departure_city = 'Moscow'::text))
-> Bitmap Index Scan on routes_t_days_of_week_departure_city_idx
Index Cond: ((days_of_week = '{2,4,7}'::integer[]) AND
(departure_city = 'Moscow'::text))
(4 rows)JSONB
具有内置GIN支持的复合数据类型的另一个例子是JSON。为了使用JSON值,目前定义了许多运算符和函数,其中一些可以使用索引来加速:
postgres=# select opc.opcname, amop.amopopr::regoperator, amop.amopstrategy as str
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname in ('jsonb_ops','jsonb_path_ops')
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
opcname | amopopr | str
----------------+------------------+-----
jsonb_ops | ?(jsonb,text) | 9 top-level key exists
jsonb_ops | ?|(jsonb,text[]) | 10 some top-level key exists
jsonb_ops | ?&(jsonb,text[]) | 11 all top-level keys exist
jsonb_ops | @>(jsonb,jsonb) | 7 JSON value is at top level
jsonb_path_ops | @>(jsonb,jsonb) | 7
(5 rows)我们可以看到,有两个操作符类可用:“jsonb_ops”和“jsonb_path_ops”。
默认情况下使用第一个操作符类“jsonb_ops”。所有键、值和数组元素都作为初始JSON文档的元素挂载在索引上。每个元素都添加了一个属性,该属性指示该元素是否为键(区分键和值的“exists”策略需要该属性)。
例如,让我们将“routes”中的几行表示为JSON,如下所示:
demo=# create table routes_jsonb as
select to_jsonb(t) route
from (
select departure_airport_name, arrival_airport_name, days_of_week
from routes
order by flight_no limit 4
) t;
demo=# select ctid, jsonb_pretty(route) from routes_jsonb;
ctid | jsonb_pretty
-------+-------------------------------------------------
(0,1) | { +
| "days_of_week": [ +
| 1 +
| ], +
| "arrival_airport_name": "Surgut", +
| "departure_airport_name": "Ust-Ilimsk" +
| }
(0,2) | { +
| "days_of_week": [ +
| 2 +
| ], +
| "arrival_airport_name": "Ust-Ilimsk", +
| "departure_airport_name": "Surgut" +
| }
(0,3) | { +
| "days_of_week": [ +
| 1, +
| 4 +
| ], +
| "arrival_airport_name": "Sochi", +
| "departure_airport_name": "Ivanovo-Yuzhnyi"+
| }
(0,4) | { +
| "days_of_week": [ +
| 2, +
| 5 +
| ], +
| "arrival_airport_name": "Ivanovo-Yuzhnyi", +
| "departure_airport_name": "Sochi" +
| }
(4 rows)
demo=# create index on routes_jsonb using gin(route);该索引可能如下所示:
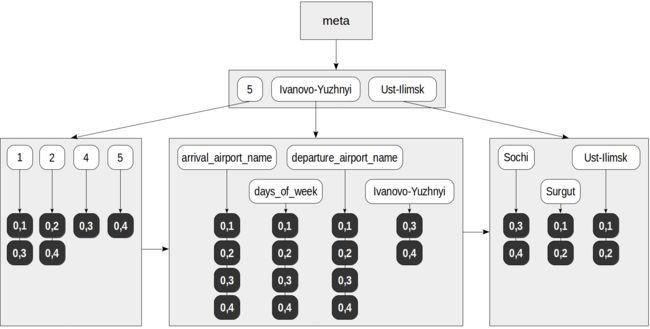
例如,现在可以使用索引执行这样的查询:
demo=# explain (costs off)
select jsonb_pretty(route)
from routes_jsonb
where route @> '{"days_of_week": [5]}';
QUERY PLAN
---------------------------------------------------------------
Bitmap Heap Scan on routes_jsonb
Recheck Cond: (route @> '{"days_of_week": [5]}'::jsonb)
-> Bitmap Index Scan on routes_jsonb_route_idx
Index Cond: (route @> '{"days_of_week": [5]}'::jsonb)
(4 rows)从JSON文档的根开始,@>操作符检查由("days_of_week": [5])指定的情况是否出现。在这里,查询将返回一行:
demo=# select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
jsonb_pretty
------------------------------------------------
{ +
"days_of_week": [ +
2, +
5 +
], +
"arrival_airport_name": "Ivanovo-Yuzhnyi",+
"departure_airport_name": "Sochi" +
}
(1 row)查询操作如下:
- 在搜索查询("days_of_week": [5])中,这些元素(搜索键)被提取:"days_of_week" 和“5”。
- 在元素树中找到提取的键,并为每个元素选择TID列表:对于“5”-(0,4),对于“days_of_week”-(0,1)、(0,2)、(0,3)、(0,4)。
- 在找到的所有TID中,一致性函数从查询中选择与运算符匹配的TID。对于@>运算符,不包含搜索查询中所有元素的文档将无法留下,因此只剩下(0,4)。但我们仍然需要重新检查表中留下的TID,因为从索引中不清楚找到的元素在JSON文档中出现的顺序(即,不知道搜索关键词在目标文档内的哪里,所以需要全文检查目标TID指向的文档,以高亮地显示关键词,下篇文章中提到的RUM索引会存储关键字在文档中的位置,就不需要重新检查了)。
要了解其他操作员的更多详细信息,可以阅读文档。
除了处理JSON的常规操作外,“jsquery”扩展长期可用,它定义了一种具有更丰富功能的查询语言(当然,还支持GIN索引)。此外,2016年发布了新的SQL标准,该标准定义了自己的一组操作和查询语言“SQL/JSON path”。该标准的实现已经完成,我们相信它将出现在PostgreSQL 11中。
【SQL/JSON path补丁最终提交给PostgreSQL 12,而其他部分仍在进行中。希望我们能在PostgreSQL 13中看到完全实现的功能。】
内部构件
我们可以使用“pageinspect”扩展来查看内部索引。
fts=# create extension pageinspect;meta页面中的信息显示了一般统计信息:
fts=# select * from gin_metapage_info(get_raw_page('mail_messages_tsv_idx',0));
-[ RECORD 1 ]----+-----------
pending_head | 4294967295
pending_tail | 4294967295
tail_free_size | 0
n_pending_pages | 0
n_pending_tuples | 0
n_total_pages | 22968
n_entry_pages | 13751
n_data_pages | 9216
n_entries | 1423598
version | 2页面结构提供了一个特殊区域,访问方法在其中存储信息;这个区域对于vacuum等普通程序来说是“不透明的”(就是vacuum可以对这部分数据进行操作的意思吧)。“gin_page_opaque_info”函数显示GIN索引的这些数据。例如,我们可以了解索引页的集合:
fts=# select flags, count(*)
from generate_series(1,22967) as g(id), -- n_total_pages
gin_page_opaque_info(get_raw_page('mail_messages_tsv_idx',g.id))
group by flags;
flags | count
------------------------+-------
{meta} | 1 meta page
{} | 133 internal page of element B-tree
{leaf} | 13618 leaf page of element B-tree
{data} | 1497 internal page of TID B-tree
{data,leaf,compressed} | 7719 leaf page of TID B-tree
(5 rows)“gin_leafpage_items”函数提供有关存储在页面上的TID的信息{data,leaf,compressed}:
fts=# select * from gin_leafpage_items(get_raw_page('mail_messages_tsv_idx',2672));
-[ RECORD 1 ]---------------------------------------------------------------------
first_tid | (239,44)
nbytes | 248
tids | {"(239,44)","(239,47)","(239,48)","(239,50)","(239,52)","(240,3)",...
-[ RECORD 2 ]---------------------------------------------------------------------
first_tid | (247,40)
nbytes | 248
tids | {"(247,40)","(247,41)","(247,44)","(247,45)","(247,46)","(248,2)",...
...请注意,TID树的叶页实际上包含指向表行的指针的小压缩列表,而不是单个指针。
属性
让我们看看GIN访问方法的属性。
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
gin | can_order | f
gin | can_unique | f
gin | can_multi_col | t
gin | can_exclude | f有趣的是,GIN支持创建多列索引。然而,与常规B-树不同的是,多列索引仍将存储单个元素,并为每个元素指示列号,而不是复合键。(上面已经有JSONB的例子了,但是也要看字段的数据类型,比如航班的数组例子中,虽然内容一样,但是飞机的起止点作为text类型存的话,就需要扩展才能建多列索引)
以下为索引层的特性:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | f
bitmap_scan | t
backward_scan | f请注意,索引扫描不支持按TID逐个返回结果,而位图扫描可以。
反向扫描也不受支持:此功能仅对索引扫描是必需的,但对位图扫描不是必需的。
以下是列层面的特性:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | f这里没有可用的特性:不能排序(这很清楚,因为检索到的文档排序没有意义),不能使用索引作为覆盖(因为文档本身不存储在索引中),没有对空值的操作(因为它对复合类型的元素没有意义,你不能去搜索一个文档是否包含NULL)。
其他数据类型
还有一些扩展可以为某些数据类型添加对GIN的支持。
- “pg_trgm”使我们能够通过比较有多少相等的三字母序列(三叉图)来确定单词的“相似性”。增加了两个操作符类,“gist_trgm_ops”和“gin_trgm_ops”,它们支持各种操作符,包括通过LIKE和正则表达式进行比较。我们可以将此扩展与全文搜索结合使用,以建议修复打字错误的单词选项。
- “hstore”实现“键值”存储。对于这种数据类型,可以使用各种访问方法的运算符类,包括GIN。然而,随着“jsonb”数据类型的引入,并没有什么特别的理由需要使用“hstore”。
- “intarray”扩展了整数数组的功能。索引支持包括GiST和GIN(“gin_int_ops”操作符类)。
以及上面已经提到了这两个扩展:
- “btree_gin”增加了对常规数据类型的gin支持,以便在多列索引中与复合类型一起使用。
- “jsquery”定义了一种用于JSON查询的语言,以及一个用于该语言索引支持的运算符类。标准PostgreSQL交付中不包括此扩展。