基础篇——强化学习之Markov决策过程建模
欢迎喜欢编程语言知识和机器学习算法等科技类文章,以及经济和历史等文史类文章的朋友们关注公众号:CodingFarmer2019,
我们一起格物致知和学史悟道,实现人生辉煌!
https://mp.weixin.qq.com/s/9IwgcpkAWHhw5vtg85E1Og
目录
一、强化学习基本概念
二、Markov决策过程
1. Markov决策过程模型
(1)用动力系统描述的环境
(2)用策略描述的智能体
(3)用价值函数描述的智能体与环境交互的奖励
2.Bellman期望方程
3.Bellman最优方程与最优策略
(1)最优策略与最优价值函数
(2)Bellman最优方程
(3)用Bellman最优方程求解最优策略
三、Markov决策过程实例和Python编程实现
1.用动力系统描述的环境
2.用策略描述的智能体
3.用价值函数描述的智能体与环境交互的奖励
4.求解Bellman期望方程得到价值函数
5.求解Bellman最优方程得到最优策略
一、强化学习基本概念
强化学习(Reinforcement Learning,又称为“增强学习”)这一名词来源于行为心理学领域,表示一定刺激下生物为了趋利避害而更倾向于频繁实施对自己有利的策略的现象。因此,强化学习就是智能体通过与环境的交互来学习和改进采取行动的策略以使其获得的最终奖励最大化。强化学习应用的场景是智能体在学习过程中每一步采取的动作往往都没有正确答案,而是通过奖励信号进行学习来最大化最终的奖励,因此它不适用于有监督学习算法擅长解决的分类和回归问题,也不适用于无监督学习算法擅长解决的聚类问题。
强化学习问题常用智能体/环境接口(Agent-Environment Interface)来研究,在此基础上将强化学习问题进一步建模为Markov决策过程。Markov决策过程有几种固定的求解方法,规模不大的问题可求得精确解,规模太大的问题往往只能采用近似算法求得近似解,而对于近似算法来说,可以和深度学习结合,得到深度强化学习算法。
强化学习需要智能体与环境交互,因此有必要安装强化学习实验环境Gym库。Python扩展库Gym在Windows、Linux 和 macOS 系统上都可以安装,在安装Gym库前先升级pip,其在命令行的升级命令为:pip install --upgrade pip。安装Gym可以选择最小安装和完整安装,最小安装的命令为:pip install gym。最小安装的Gym库只包括少量的内置环境,如算法环境、简单文字游戏环境和经典控制环境。而完整安装的Gym库还包括Atari游戏环境、二维方块环境、MuJoCo环境和机械控制环境等。Gym库的使用方法为:使用 env = gym.make('CartPole-v0') 取出环境对象,其中'CartPole-v0'只是环境ID的一个示例;然后使用 env.reset() 初始化环境返回智能体的初始观测,是 np.array 类型;接着以智能体执行的动作为输入参数,使用 env.step() 执行一步环境,并返回4个参数,分别是 np.array 类型的·观测、float 类型的奖励、bool 类型的本回合结束指示和含有一些调试信息的其他参数,这里需要注意的是每次调用 env.step() 只会让环境前进一步,所以 env.step() 往往会放在循环结构内,通过循环调用来完成整个回合;最后使用 env.render() 以图形化的方法显示当前环境,使用 env.close() 关闭环境。
二、Markov决策过程
在对强化学习有了基本认识后,接下来介绍强化学习最重要的数学模型——Markov决策过程模型。Markov决策过程模型就是在离散时间的智能体/环境接口的基础上进一步加入动作和状态具有Markov性的条件概率模型。所谓Markov性就是认为环境对智能体的奖励和下一状态的确定仅仅依赖于当前状态和智能体所当前所采取的的动作,而不依赖于更早的状态和动作。因此,Markov性可以看作是Markov决策过程模型对状态的额外约束,要求状态必须含有可能对未来产生影响的所有过去信息。
1. Markov决策过程模型
(1)用动力系统描述的环境
在离散时间的智能体/环境接口中,智能体与环境在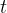 时刻交互过程中会依此发生以下事件,并形成循环直至达到终止状态为止:
时刻交互过程中会依此发生以下事件,并形成循环直至达到终止状态为止:
- 智能体观测状态为
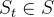 的环境,得到观测值
的环境,得到观测值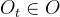 ,其中
,其中 是状态空间,
是状态空间, 是观测空间。如果智能体可以完全观测到环境的状态,则称环境是完全可观测的,也就是
是观测空间。如果智能体可以完全观测到环境的状态,则称环境是完全可观测的,也就是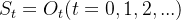 。
。 - 智能体在状态值
 下依据一定的策略做出动作
下依据一定的策略做出动作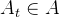 ,其中
,其中 是动作空间。
是动作空间。 - 环境根据智能体的动作
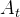 ,给予智能体奖励
,给予智能体奖励 ,并进入下一状态
,并进入下一状态 ,其中
,其中 是奖励空间,它是实数集的子集。
是奖励空间,它是实数集的子集。
因此,一个用时间离散化的智能体/环境接口表示的强化学习过程可以用这样的轨道表示:
![]()
对于回合制的强化学习任务而言,会多出一个终止状态S终止。当环境达到终止状态时,回合结束,不再有任何观测和动作,所以状态空间不应包括终止状态。但在回合制任务中,为了强调终止状态的存在,会将含有终止状态的状态空间记为。因此,回合制任务的强化学习轨道为:
![]()
式中, 是达到回合制任务终止状态的步数。
是达到回合制任务终止状态的步数。
对于完全可观测环境下的回合制的强化学习任务而言,由于不区分观测值 和状态值
和状态值![]() 的差别,其轨道可以简化为:
的差别,其轨道可以简化为:
![]()
在上述离散时间的智能体/环境接口的基础上,进一步加入动作和状态具有Markov性的条件概率模型,就得到了Markov决策过程模型,也就是定义在在时刻,从状态![]() 和动作
和动作![]() 转移到下一状态
转移到下一状态![]() 和奖励
和奖励![]() 的概率:
的概率:
![]()
值得注意的是,上述Markov决策过程模型中的概率![]() 就是在Markov决策过程中进行状态转移的动力系统,这是因为在Markov决策过程模型中用动力系统来描述环境的。
就是在Markov决策过程中进行状态转移的动力系统,这是因为在Markov决策过程模型中用动力系统来描述环境的。
因此,利用动力系统的定义可以得到状态转移概率:![p(s^ \prime| s, a) = Pr[S_{t+1}=s^ \prime| S_{t}=s, A_{t}=a]=\sum\limits_{r\in R}p(s^ \prime, r | s, a), (s, s^ \prime\in S,a\in A)](http://img.e-com-net.com/image/info8/709356ccf5094b25ad46e0dd81ec866a.png)
(2)用策略描述的智能体
我们知道,智能体依据当前状态决定其动作。在Markov决策过程中,定义策略π为在状态$s$决定执行动作$a$的概率,即:
![]()
对于动作集为连续的情况,可采用概率分布来定义策略。
(3)用价值函数描述的智能体与环境交互的奖励
对于强化学习而言,其核心概念是奖励,强化学习的最终目标就是最大化长期回报。对于回合制的强化学习任务而言,假设一个回合在第步达到终止状态,则从步骤![]() 以后的回报可以定义为未来每一步得到的奖励之和:
以后的回报可以定义为未来每一步得到的奖励之和:
![]()
上式中,是一个确定的变量,而回合的步数$T$是一个随机变量,因此在 的定义式中,不仅每一项是随机变量,而且含有的项数也是随机变量。
的定义式中,不仅每一项是随机变量,而且含有的项数也是随机变量。
对于连续性的强化学习任务而言,由于会包含时刻以后的所有奖励信息,如果像回合制任务一样对未来得到的奖励进行简单求和,那么时刻以后的回报将会是无穷大的。为了解决这一问题,引入了折扣的概念来定义连续性任务的回报:
![]()
上式中,![]() 是一个折扣因子,决定了如何在最近的奖励和未来的奖励之间进行折中。若指定
是一个折扣因子,决定了如何在最近的奖励和未来的奖励之间进行折中。若指定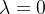 ,智能体只会考虑最近的奖励,完全无视长期回报;若指定
,智能体只会考虑最近的奖励,完全无视长期回报;若指定![]() ,智能体会认为当前的单位奖励和未来的单位奖励一样重要。对于连续性任务,一般设定
,智能体会认为当前的单位奖励和未来的单位奖励一样重要。对于连续性任务,一般设定![]() ,这样带有折扣的定义也适用于回合制任务。
,这样带有折扣的定义也适用于回合制任务。

2.Bellman期望方程
定义了策略和价值函数之后,策略评估则是试图求解给定策略的价值函数,其中最常用来进行策略评估的就是Bellman期望方程。首先,状态价值和动作价值之间可以用两种方法互相表示:
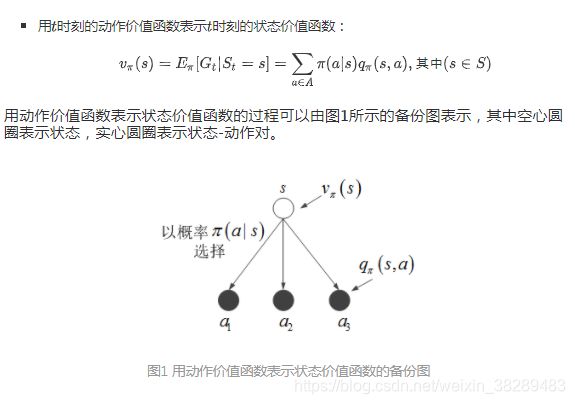

接下来,从状态价值和动作价值之间的互相表示出发,用代入法消除其中一种价值函数,就得到了Bellman期望方程,同样有以下两种形式
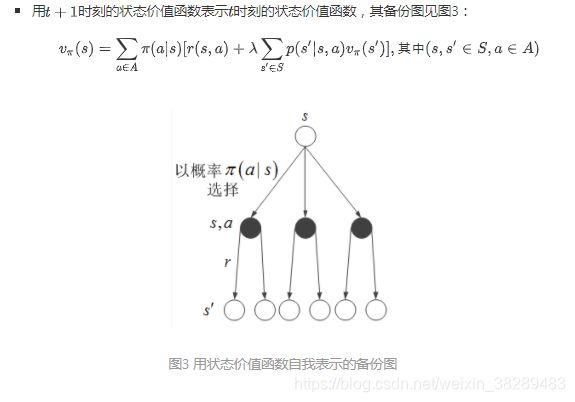
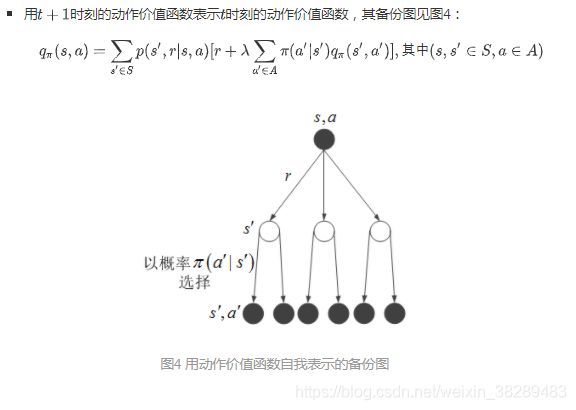
3.Bellman最优方程与最优策略
(1)最优策略与最优价值函数
在前面的内容中,我们为策略定义了价值函数,价值函数实际上能反映出多个策略之间的偏序关系。对于环境的一个动力系统而言,如果动作空间A是闭集,那么一定存在一个策略π*,使得所有策略的价值函数在任意状态下的取值都小于或等于这个策略的价值函数在相应状态下的取值,此时这个策略π* 就称为最优策略。最优策略的价值函数也称为最优价值函数,仍然包括以下两种形式:

对于环境的一个动力系统,可能存在多个最优策略,但这些最优策略总是有着相同的价值函数。因此,只要求得了最优价值函数,就可以至少得到一个最优策略。其中,最优策略的确定方法为:

(2)Bellman最优方程
最优价值函数有一个重要的性质就是Bellman最优方程。Bellman最优方程可以用来求解最优价值函数,最优价值函数求得以后就可以确定最优策略。其中,最优策略有如下性质:

最优策略的性质表明,当智能体采取的动作是使动作价值函数取最优值时的动作,则最优策略取值为1,否则最优策略取值为0。将其代入状态价值函数和动作价值函数相互表示的关系中,可以得到最优状态价值函数和最优动作价值函数之间的关系,同样包含以下两种形式:
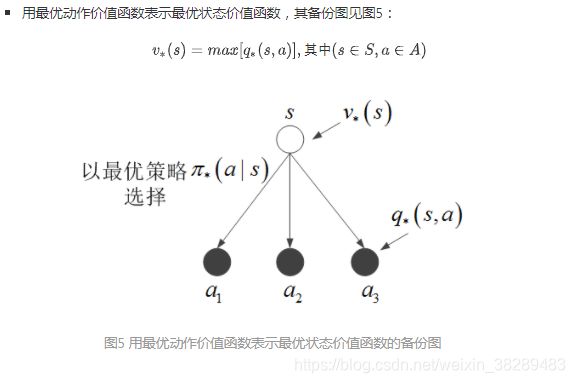

接下来,从最优状态价值和最优动作价值之间的互相表示出发,用代入法消除其中一种最优价值函数,就得到了Bellman最优方程,同样有以下两种形式:
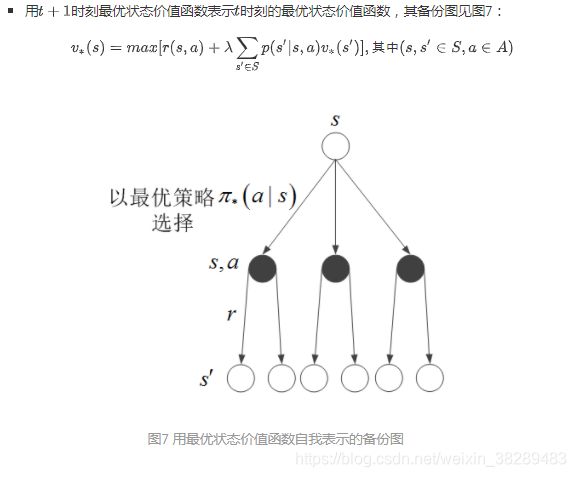
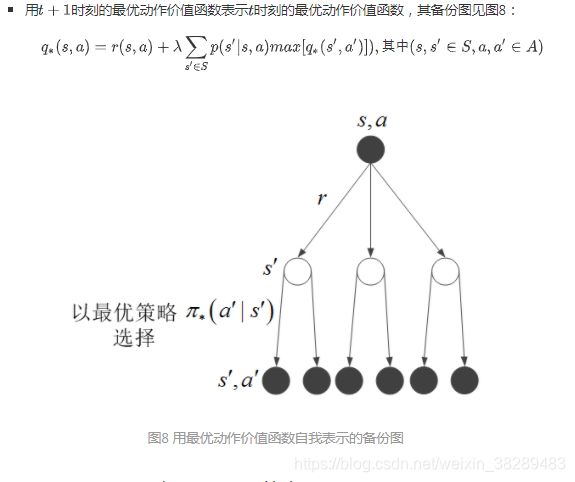
(3)用Bellman最优方程求解最优策略
理论上,通过求解Bellman最优方程可以得到最优价值函数。一旦得到最优价值函数,就能很轻易地找到一个最优策略:对于每个状态s ∈S,总是选择使q*(s,a)最大的动作a。

但是,实际使用Bellman最优方程求解最优策略可能会遇到下列困难:
- 难以给出Bellman最优方程。这是因为列出Bellman最优方程要求对环境的动力系统完全了解,并且动力系统必须要用有Markov性的Markov决策过程来建模,在实际问题中,环境往往十分复杂,很难非常周全地用概率模型来对实际问题进行完全建模。
- 难以求解Bellman最优方程。这是因为在实际问题中,状态空间和动作空间的组合往往非常巨大,在这种情况下,没有足够的计算资源来求解Bellman最优方程,所以常常会考虑采用间接的方法求解最优价值函数的值,甚至是近似值。
三、Markov决策过程实例和Python编程实现
这里以一个吃饭任务为例,进行Markov决策过程建模的演示和编程实现。
1.用动力系统描述的环境

2.用策略描述的智能体
对于这个吃饭任务的环境,某个智能体可以采用下表所示的策略,其中x,y∈ (0,1):

3.用价值函数描述的智能体与环境交互的奖励
在上述两个表格的基础上,根据前面对状态价值函数和动作价值函数的定义,可以得到用智能体/环境描述的这个吃饭任务的两类价值函数如下:

4.求解Bellman期望方程得到价值函数
接下来,将在上述给定的动力系统的基础上,为给定的策略计算状态价值函数和动作价值函数。根据前面描述的Bellman期望方程,可以得到状态价值函数和动作价值函数之间的关系如下:

通过Python语言采用sympy库的solve_linear_system()函数,求解上述标准形式的线性方程组,其核心代码如下图9所示:
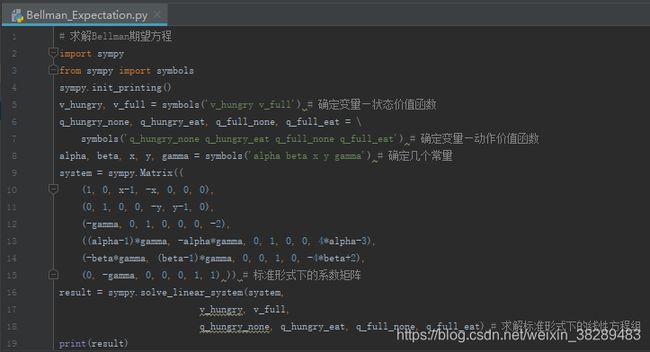
运行图9所示的代码,得到用智能体/环境描述的这个吃饭任务的状态价值函数和动作价值函数如下:
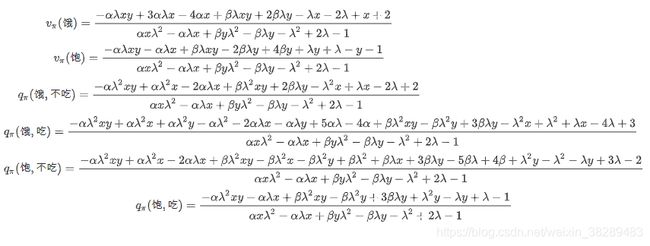
以上就是通过求解Bellman期望方程得到了给定策略的状态价值函数和动作价值函数。
5.求解Bellman最优方程得到最优策略
最后,将在上述给定的动力系统的基础上,计算最优状态价值函数和最优动作价值函数。根据前面描述的Bellman最优方程,可以得到最优状态价值函数和最优动作价值函数之间的关系如下:

这个方程组里含有max()运算,因此是一个非线性方程组。我们可以通过分类讨论的方法来化解这个max()运算,将其转化为多个线性方程组仍然采用sympy库的solve_linear_system()函数分别进行求解。根据前面描述的最优策略的性质可知,最优策略的转移概率要么取1,要么取0。具体而言,针对这个吃饭任务,最优策略的转移概率x和y分别可取0或1,因此这个非线性方程组可分为4类情况讨论,也就是x=0且y=0,x=1且y=0,x=0且y=1和x=1且y=1这4类情况。所以,通过Python语言采用sympy库的solve_linear_system()函数,采用分类讨论的方法求解上述非线性方程组,其核心代码如下图10所示:

运行图10所示的代码,得到用智能体/环境描述的这个吃饭任务分别在x=0且y=0,x=1且y=0,x=0且y=1和x=1且y=1这四种情况下的最优状态价值函数和最优动作价值函数:


比较最优策略的价值函数满足的方程组和一般策略的价值函数满足的方程组,可以看到最优价值方程组的解正是在一般策略价值方程组的解分别在$x=0$且$y=0$,$x=1$且$y=0$,$x=0$且$y=1$和$x=1$且$y=1$这四种情况下得到。所以,我们可以用一般策略价值方程组的解的形式来表示最优价值方程组的解,但是,当解的结果中概率参数确定了一个具体的数值后,最优状态价值函数和最优动作价值函数只会取到这四类情况中的某一种具体情况下的值。

综上,关于Markov决策过程模型的建立、用Bellman期望方程求解给定策略的状态价值函数和动作价值函数以及用Bellman最优方程求解最优状态价值函数和最优动作价值函数进而求得最优策略等三方面的知识介绍完毕。任何现实问题只有上升到数学的高度,才能称得上步入自然科学的殿堂,本文详细介绍了强化学习的建模方式——Markov决策过程模型的核心知识,以飨技术爱好者。