生命在于学习——Stable Diffution(Mac端)

一、前言
最近一段时间研究了一下Stable Diffution,Windows和MAC端都搭建成功了,也尝试了各种功能,后续会学习新的使用姿势,写一篇文章记录一下。
二、介绍
1、Stable Diffution是什么
Stable Diffusion,是一种AI绘画生成工具。Stability AI 于2023年6月发布新闻稿,宣布推出 SDXL 0.9 版本更新,升级了 Stable Diffusion 文本生成图片模型。(来源百度百科)
也就是说,我们可以通过自己输入文字描述,选择适合的模型,便可以生成想要的图片。
2、模型
要会使用Stable Diffution(后面简称SD),就要知道基本模型的分类。
(1)什么是模型
SD之所以能绘画,是因为收集了大量世界上已存在的图片来训练,这些图片训练得到的结果就是模型。可想而之,使用什么图片训练出来的模型,就只能画什么样的图,假设有一个只用了狗的图片训练出来的模型,那么我们使用这个模型就没法画出人的照片,因为它的训练数据中没有人的元素。
(2)模型分类
a.大模型
大模型一般都会比较大,差不多几个G,他决定了AI图片的主要风格,常见后缀:ckpt、safetensors。
b.Lora模型
比较小,一般几百MB,要结合大模型使用,使用的时候注意看介绍使用的哪个大模型,常见后缀:ckpt、safetensors、pt。
c.VAE美化模型
名字中带VAE,常见后缀:ckpt、pt。
d.Embeddings和Hypernetworks个性化模型
Embeddings也是属于微调模型,Hypernetworks比较少,常见后缀:pt。
e.其他模型
(3)模型下载
我常用两个网站下载:
https://civitai.com/
https://aituzhan.com/
三、搭建安装
1、安装Homebrew
可以使用官网的pkg,或者以下命令:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
下面是国内的gitee:
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"

2、安装Python3.10
使用brew即可安装python:
brew install cmake protobuf rust [email protected] git wget
3、克隆webui的软件包
以下是命令:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui

4、放入SD的基础模型
也可以后面直接放入下载好的模型。
对应的模型文件目录在:SD文件夹/models/下面,大模型放Stable-diffusion文件夹,lora就放lora文件夹。
以下是我的一些模型:
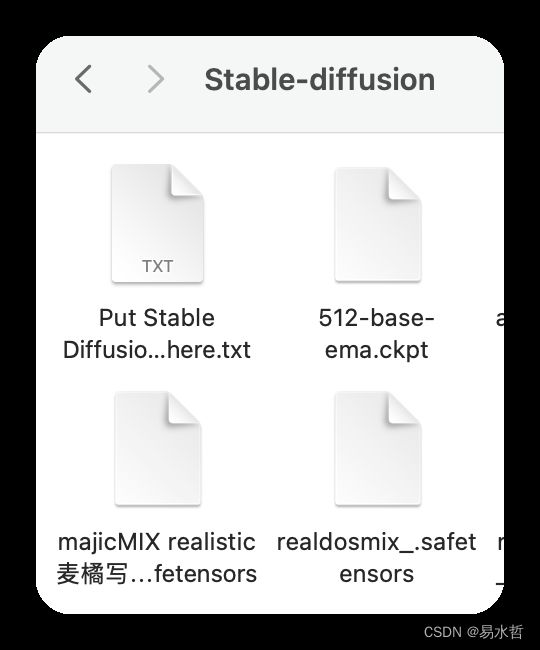
5、打开用户界面
进入SD文件夹,打开终端,输入./webui.sh回车,第一次会很慢,需要下载加载项,我记得下载的过程中会有千奇百怪的错误。
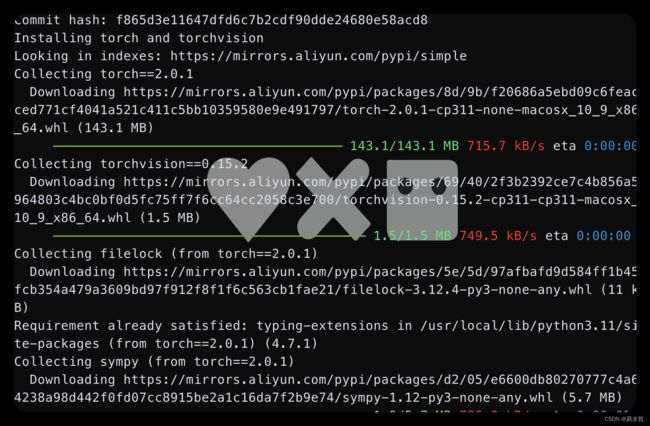
逐一解决。
(1)Installing gfpgan报错
网络错误,这里可以使用https://ghproxy.com/下载这个包,然后解压放到SD文件夹里面,改成对应的名字:
gfpgan:https://github.com/TencentARC/GFPGAN/archive/8d2447a2d918f8eba5a4a01463fd48e45126a379.zip
(2)ERROR: No matching distribution found for GitPython==3.1.30
重试一遍,发现好了。
(3)ERROR: Could not install packages due to an OSError: [Errno 13] Permission denied: ‘/usr/local/dev.txt’
继续重试一遍
(4)终端不能挂代理,这个脚本不能挂代理,否则会报错,报错内容没截到。
(5)生成的时候一直报错,没有进度条
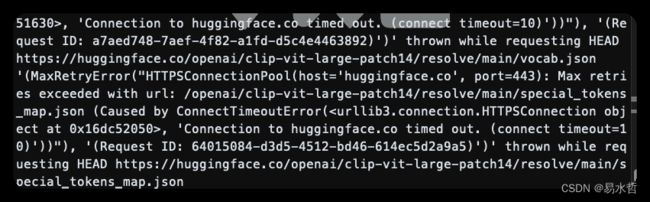
需要科学。
最后会以Running on local URL: http://127.0.0.1:7860” 结束:

然后可以在浏览器打开http://127.0.0.1:7860,就可以看到界面了:
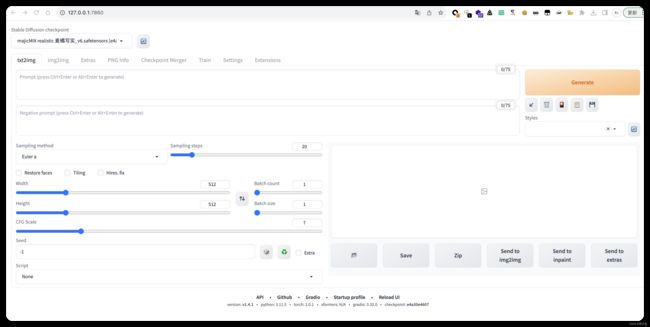
6、安装PS插件
先下载下来PS的扩展:
https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin
注意:这个插件最低支持PS24版本。
然后放入到/Applications/Adobe Photoshop (Beta)/Plug-ins文件夹下面。
7、启动的时候需要加–api参数
这次才可以连接:

四、详细使用
1、简单使用
2、文生图(txt2img)
选择一块区域,选择文生图,正向提示词一直可爱的猫,然后生成:
生成效果:
3、图生图(img2img)
图生图,可以重构该图片,但整体结构不变。
原先文生图生成的图片:

本来想生成一只白色的猫,结果给我生成一个妹子,但可以看出和原先猫的结构是不变的:
这下正常了:
4、局部重绘(inpaint)
可以用来修改小细节:
选中区域,ctrl+j,新建这个区域,使用画笔涂成白色,然后框选图片,生成,提示词不变。
原图:
重绘后的图片:
5、外绘,也可以重绘(outpaint)
选中选区,使用橡皮擦擦掉想重绘的地方,然后修改提示词,生成。
原图:
生成后:
五、总结
本篇为简单安装和基本使用,后续会有进阶使用。