微服务架构学习与思考
参考:微服务架构学习与思考(01):什么是微服务?微服务的优势和劣势 - 九卷 - 博客园 (cnblogs.com)
一、单体应用
在软件开发早期阶段,大家都在一个应用系统上开发。各个业务模块之间耦合也比较紧密。软件发布也是整体发布,或者对软件进行打包发布和部署,比如java可以打包成war部署。测试也很容易,因为代码都在一起,基本不需要引用外部的关联服务。
此时可能出现的问题:
- 打包编译会耗时很久,导致发布也很耗时。
- 代码可维护性变差,因为代码量大,逻辑复杂,只有少数老员工能全部理解。代码腐化严重。
- 修改bug和增加新功能会变得困难,可能牵一发而动全身。
- 由于上面的原因,软件扩展变得困难
- 软件可用性风险增加。可能一个bug导致整个软件不可用。
二、应用拆分#
第一步可能想到的就是拆分应用。
业务规模进一步发展,你可能把上面的应用做进一步拆分,变成更小的应用,以服务的形式对外提供应用服务。应用慢慢的拆分为了比较小的服务 - 微服务。
三、微服务思考
什么是微服务
微服务 (Microservices) 是一种软件架构风格,它是以专注于单一责任与功能的小型功能区块 (Small Building Blocks) 为基础,利用模块化的方式组合出复杂的大型应用程序,各功能区块使用与语言无关 (Language-Independent/Language agnostic) 的 API 集相互通信。
- 优势:
- 应用小,可快速编译部署
- 单个微服务维护性变高,修改容易,因为每个团队独立负责一块功能。新功能交付变快,可以快速开发交付
- 扩展性变高,根据业务规模可以随时缩减/增加服务器规模
- 可靠性变强,可以部署很多独立的服务
- 业务解耦,按照业务边界拆分为多个独立的服务模块
- 提升研发效率,业务拆分后,服务模块变小,在一个团队内就可以独立编写、测试、发布,加快研发效率。
拆分后,单个微服务比较小,它只专注于做好一件事情。
拆分的指导原则:高内聚,低耦合。
单一微服务有点像软件设计中的单一职责原则:
Martin 对单一职责有一个论述:
把因相同原因而变化的东西聚合到一起,而把因不同原因而变化的东西分离开来。
- 劣势(问题):
- 整体复杂度变高,从哪些方面来管理这种复杂度?
- 运维变得复杂:微服务变多,怎么监控所有微服务,保证服务稳定?出了问题,怎么定位问题?
- 服务管理:微服务变多,管理复杂度变高,治理变得复杂
- 测试方面的挑战:你需要结合其他的微服务来进行集成测试
- 分布式问题:分布式数据一致性、分布式事务
- 服务可用性保障:一个服务出了问题,如何才能不影响其他服务?
从单体架构升级到微服务架构,肯定希望提高研发效率,缩短工期,加快产品交付速度。
在复杂度较小时,单体应用的生产率更高,微服务架构反而降低了生产率。但是,当复杂度到了一定规模,无论采用单体应用还是微服务架构,都会降低系统的生产率。区别是:单体应用生产率开始急剧下降,而微服务架构则能缓解生产率下降的程度。
微服务架构特点:每个微服务是独立的,团队可以独立开发,独立测试,独立部署,服务是自治的。相应的团队组成人员也有产品,技术,测试,团队成员在自己内部就可以完整的进行微服务各种功能开发。
这就要打破原先传统的那种按职能划分的组织团队形式,而要把不同职能的人组织在一个团队内,组成一个跨职能的产品组织架构。这样才能把一个微服务功能架构、设计、开发、测试、部署、上线运行,在一个组织内部完成,从而形成完整的业务、开发、交付闭环。
基础设施建设
这里的基础设施建设,指的是以 CI/CD 为基础的自动化交付流水线,到最后建设成从开发、测试、预发布、上线、运维等整个研发流程自动化的 DevOps 为目标。
因为随着微服务的逐步建设,服务数量增多,上线服务次数必然增多,交付频繁会带来故障次数增多,所以我们必须建设自动化的工具链,来帮助我们快速无误的交付服务,实施好微服务项目。
五、怎么构建第一个微服务项目
-
第一种:有新项目,可以从0开始设计微服务架构。
-
第二种:改造旧有的老项目 这种也可以划分2类:
-
从项目小范围开始试水,进行改造。
-
完全重构项目 - 一般不推荐这种方式。因为不仅老项目需要维护,而且来了新需求咋办?是老项目停止需求开发,还是新旧一起加,一起加又浪费人力,不加技术跟不上业务发展。这些风险都是需要思考衡量。
-
-
第三种:从边缘不重要的小项目开始。
这种项目需求开发一般不紧迫,项目又小,相对独立,与现有系统耦合较小,可以完全重构。从这种小项目开始实施微服务,一步一步来构建,降低风险。
经验丰富后,在逐步将其他项目进行改造。 这种是折中的办法,不是那种“休克疗法”。
一:进行服务分层#
分层:是一种很常见的架构方法。比如我们常见的网络协议TCP/IP的分层。分层之后,各层各司其职,相互隔离开来。
最简单的服务分层:

二:微服务总体架构图
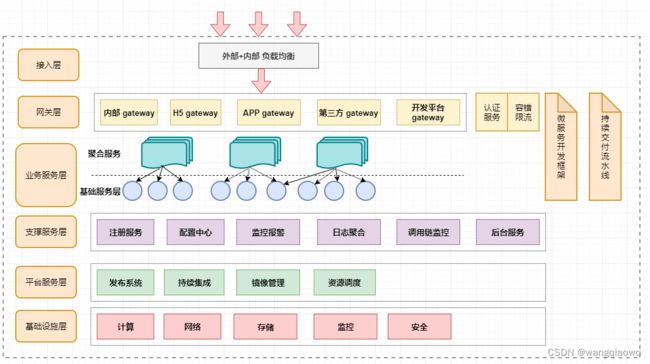
- 1.接入层
也可以叫负载均衡层,把外部的流量引入到系统中来。一般负载均衡软件有nginx,lvs,还有各大云服务厂商自己的负载均衡服务。
-
2.网关层
内部接口的一些认证、安全、鉴权、过滤、限流等服务,一般处于这一层。这一层把内部的服务接口做一层安全隔离,保护内部服务,同时也可以实现一些其他需求,比如前面讲的鉴权、黑名单过滤等等需求。所以这一层在微服务架构中是很重要的一层。 -
3.业务服务层
基础服务和聚合服务
-
基础服务:根据业务特点又可以分为核心基础服务、公共服务、中间层服务等。
-
聚合服务:把下面细粒度的基础服务再进一步封装、关联,组合成新的服务,供上层调用。这一层可以实现多变的需求。
上面的这种划分是根据逻辑来划分,各个公司可以根据自己实际的业务需求来进行划分。 -
4.支撑服务层
微服务能够成功实施落地,这一层与下一层CI/CD的配套设施是非常重要。微服务不是把上面的业务服务写完就完事了,在服务治理的过程中需要很多配套设置支持。
这一层包括注册服务中心,配置中心,监控报警服务,日志聚合服务,调用链监控几大服务,后台服务涉及的服务有消息队列,定时任务,数据访问等内容。
- 5.平台服务层
这一层是实施业务弹性治理的关键。集群的资源调度:扩展和减少。业务量上来时,可以弹性增加资源。
镜像管理和发布系统配合使用可以应对出现的这种情况。所以很多团队后面会引入docker+k8s,容器,镜像管理,容器服务编排。此外,基于CI/CD的DevOps也是构建在这一层能力。
- 6.基础设施层
这个是最底层的基础设施,网络,存储,硬盘,IDC的部分。
laas 这个概念就是针对这一层。
微服务技术体系

Golang微服务技术栈

java微服务技术栈
用java技术开发微服务,比较主流的选择有:Spring Cloud 和 Dubbo。
Spring Cloud也是一个全家桶,它由很多技术框架组合而成:
-
服务治理
- 服务注册和发现:Netflix Eureka
当然我们也有其他的选择,比如consul,etcd,zookeeper等 - 断路器:Hystrix
- 调用端负载均衡:Ribbon
- REST客户端:Feign
- 服务注册和发现:Netflix Eureka
-
网关
API 网关:Zuul
当然我们也可以选择其他的,比如Spring Cloud Gateway,kong,nginx+lua,apisix等 -
分布式链路监控
- Spring Cloud Sleuth:埋点和发送数据
当然还有其他的比如zipkin,pinpoint,skywalking,jaeger等
- Spring Cloud Sleuth:埋点和发送数据
-
消息组件
- Spring Cloud Stream
- Spirng Cloud Bus
消息中间件的其他软件:RocketMQ,Kafka,RabbitMQ
-
配置中心
- Spring Cloud Config
配置中心可以有其他的替代,比如Apollo,Nacos等
- Spring Cloud Config
-
安全控制
- Spring Cloud Security
Spring Cloud 这个地址列出了springcloud各种框架,就是它的文档地址。
阿里巴巴的SpringCloud#
阿里巴巴在SpringCloud之上,开发了自己的微服务框架spring-cloud-alibaba 。
- spring-cloud-alibaba wiki
主要功能
- 服务限流降级:默认支持 WebServlet、WebFlux, OpenFeign、RestTemplate、Spring Cloud Gateway, Zuul, Dubbo 和 RocketMQ 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控。
- 服务注册与发现:适配 Spring Cloud 服务注册与发现标准,默认集成了 Ribbon 的支持。
- 分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新。消息驱动能力:基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。
- 分布式事务:使用 @GlobalTransactional 注解, 高效并且对业务零侵入地解决分布式事务问题。
- 阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
- 分布式任务调度:提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker(schedulerx-client)上执行。
- 阿里云短信服务:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
组件
Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
Dubbo:Apache Dubbo™ 是一款高性能 Java RPC 框架。
Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
Alibaba Cloud ACM:一款在分布式架构环境中对应用配置进行集中管理和推送的应用配置中心产品。
Alibaba Cloud OSS: 阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
Alibaba Cloud SchedulerX: 阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。
Alibaba Cloud SMS: 覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
Dubbo和Spring Cloud对比

java微服务框架总结#
就微服务体系来说,Dubbo只是整个微服务的一部分。Spring Cloud是一整套微服务体系,它是一个完整的解决方案。Spring Cloud社区强大,也很活跃。
参考#
- Spring Cloud
- Spring Cloud · GitHub
- https://github.com/spring-projects/spring-cloud
- https://github.com/alibaba/spring-cloud-alibaba/blob/master/README-zh.md
- 网易考拉海购Dubbok框架优化详解-CSDN博客 网易考拉海购Dubbok框架优化详解
- spring cloud 和 dubbo 各自的优缺点是什么? - 知乎 spring cloud 和 dubbo 各自的优缺点是什么?
- https://www.cnblogs.com/xishuai/p/dubbo-and-spring-cloud.html Java微服务框架选型(Dubbo 和 Spring Cloud?)
-------------------------------------------------------------------------------------------------------------
参考:微服务2.0技术栈选型手册 (qq.com)
微服务2.0技术栈的核心模块


服务框架是一个比较成熟的领域,有太多可选项。Spring Boot/Cloud[附录12.1]由于Spring社区的影响力和Netflix的背书,目前可以认为是构建Java微服务的一个社区标准,Spring Boot目前在github上有超过20k星。基于Spring的框架本质上可以认为是一种RESTful框架(不是RPC框架),序列化协议主要采用基于文本的JSON,通讯协议一般基于HTTP。RESTful框架天然支持跨语言,任何语言只要有HTTP客户端都可以接入调用,但是客户端一般需要自己解析payload。目前Spring框架也支持Swagger契约编程模型,能够基于契约生成各种语言的强类型客户端,极大方便不同语言栈的应用接入,但是因为RESTful框架和Swagger规范的弱契约特性,生成的各种语言客户端的互操作性还是有不少坑的。
Dubbo[附录12.2]是阿里多年构建生产级分布式微服务的技术结晶,服务治理能力非常丰富,在国内技术社区具有很大影响力,目前github上有超过16k星。Dubbo本质上是一套基于Java的RPC框架,当当Dubbox扩展了Dubbo支持RESTful接口暴露能力。Dubbo主要面向Java 技术栈,跨语言支持不足是它的一个弱项,另外因为治理能力太丰富,以至于这个框架比较重,完全用好这个框架的门槛比较高,但是如果你的企业基本上投资在Java技术栈上,选Dubbo可以让你在服务框架一块站在较高的起点上,不管是性能还是企业级的服务治理能力,Dubbo都做的很出色。新浪微博开源的Motan(github 4k stars)也不错,功能和Dubbo类似,可以认为是一个轻量裁剪版的Dubbo。
gRPC[附录12.3]是谷歌近年新推的一套RPC框架,基于protobuf的强契约编程模型,能自动生成各种语言客户端,且保证互操作。支持HTTP2是gRPC的一大亮点,通讯层性能比HTTP有很大改进。Protobuf是在社区具有悠久历史和良好口碑的高性能序列化协议,加上Google公司的背书和社区影响力,目前gRPC也比较火,github上有超过13.4k星。目前看gRPC更适合内部服务相互调用场景,对外暴露HTTP RESTful接口可以实现,但是比较麻烦(需要gRPC Gateway配合),所以对于对外暴露API场景可能还需要引入第二套HTTP RESTful框架作为补充。总体上gRPC这个东西还比较新,社区对于HTTP2带来的好处还未形成一致认同,建议谨慎投入,可以做一些试点。
五、运行时支撑服务选型
运行时支撑服务主要包括服务注册中心,服务路由网关和集中式配置中心三个产品。
服务注册中心,如果采用Spring Cloud体系,则选择Eureka[附录12.4]是最佳搭配,Eureka在Netflix经过大规模生产验证,支持跨数据中心,客户端配合Ribbon可以实现灵活的客户端软负载,Eureka目前在github上有超过4.7k星;Consul[附录12.5]也是不错选择,天然支持跨数据中心,还支持KV模型存储和灵活健康检查能力,目前在github上有超过11k星。
服务网关也是一个比较成熟的领域,有很多可选项。如果采用Spring Cloud体系,则选择Zuul[附录12.6]是最佳搭配,Zuul在Netflix经过大规模生产验证,支持灵活的动态过滤器脚本机制,异步性能不足(基于Netty的异步Zuul迟迟未能推出正式版)。Zuul网关目前在github上有超过3.7k星。基于Nginx/OpenResty的API网关Kong[附录12.7]目前在github上比较火,有超过14.1k星。因为采用Nginx内核,Kong的异步性能较强,另外基于lua的插件机制比较灵活,社区插件也比较丰富,从安全到限流熔断都有,还有不少开源的管理界面,能够集中管理Kong集群。
配置中心,Spring Cloud自带Spring Cloud Config[附录12.8](github 0.75k stars),个人认为算不上生产级,很多治理能力缺失,小规模场景可以试用。个人比较推荐携程的Apollo[附录12.9]配置中心,在携程经过生产级验证,具备高可用,配置实时生效(推拉结合),配置审计和版本化,多环境多集群支持等生产级特性,建议中大规模需要对配置集中进行治理的企业采用。Apollo目前在github上有超过3.4k星。
六、服务监控选型
主要包括日志监控,调用链监控,Metrics监控,健康检查和告警通知等产品。
ELK目前可以认为是日志监控的标配,功能完善开箱即用,Elasticsearch[附录12.10]目前在github上有超过28.4k星。Elastalert[附录12.11] (github 4k stars)是Yelp开源的针对ELK的告警通知模块。
调用链监控目前社区主流是点评CAT[附录12.12](github 4.3k stars),Twitter之前开源现在由OpenZipkin社区维护的Zipkin[附录12.13](github 7.5k stars)和Naver开源的Pinpoint[附录12.14](github 5.3k stars)。个人比较推荐点评开源的CAT,在点评和国内多家互联网公司有落地案例,生产级特性和治理能力较完善,另外CAT自带告警模块。下面是我之前对三款产品的评估表,供参考。
七、服务容错选型
针对Java技术栈,Netflix的Hystrix[附录12.24](github 12.4k stars)把熔断、隔离、限流和降级等能力封装成组件,任何依赖调用(数据库,服务,缓存)都可以封装在Hystrix Command之内,封装后自动具备容错能力。Hystrix起源于Netflix的弹性工程项目,经过Netflix大规模生产验证,目前是容错组件的社区标准,github上有超12k星。其它语言栈也有类似Hystrix的简化版本组件。
Hystrix一般需要在应用端或者框架内埋点,有一定的使用门槛。对于采用集中式反向代理(边界和内部)做服务路由的公司,则可以集中在反向代理上做熔断限流,例如采用nginx[附录12.25](github 5.1k stars)或者Kong[附录12.7](github 11.4k stars)这类反向代理,它们都有插件支持灵活的限流容错配置。Zuul网关也可以集成Hystrix实现网关层集中式限流容错。集中式反向代理需要有一定的研发和运维能力,但是可以对限流容错进行集中治理,可以简化客户端。
八、后台服务选型
后台服务主要包括消息系统,分布式缓存,分布式数据访问层和任务调度系统。后台服务是一个相对比较成熟的领域,很多开源产品基本可以开箱即用。
消息系统,对于日志等可靠性要求不高的场景,则Apache顶级项目Kafka[附录12.26](github 7.2k stars)是社区标配。对于可靠性要求较高的业务场景,kafka其实也是可以胜任,但企业需要根据具体场景,对 Kafka的监控和治理能力进行适当定制完善,Allegro公司开源的hermes[附录12.27](github 0.3k stars)是一个可参考项目,它在Kafka基础上封装了适合业务场景的企业级治理能力。阿里开源的RocketMQ[附录12.28](github 3.5k星)也是一个不错选择,具备更多适用于业务场景的特性,目前也是Apache顶级项目。RabbitMQ[附录12.29](github 3.6k星)是老牌经典的MQ,队列特性和文档都很丰富,性能和分布式能力稍弱,中小规模场景可选。
对于缓存治理,如果倾向于采用客户端直连模式(个人认为缓存直连更简单轻量),则SohuTv开源的cachecloud[附录12.30](github 2.5k stars)是一款不错的Redis缓存治理平台,提供诸如监控统计,一键开启,自动故障转移,在线伸缩,自动化运维等生产级治理能力,另外其文档也比较丰富。如果倾向采用中间层Proxy模式,则Twitter开源的twemproxy[附录12.31](github 7.5k stars)和CodisLab开源的codis[附录12.32](github 6.9k stars)是社区比较热的选项。
对于分布式数据访问层,如果采用Java技术栈,则当当开源的shardingjdbc[附录12.33](github 3.5k stars)是一个不错的选项,分库分表逻辑做在客户端jdbc driver中,客户端直连数据库比较简单轻量,建议中小规模场景采用。如果倾向采用数据库访问中间层proxy模式,则从阿里Cobar演化出来的社区开源分库分表中间件MyCAT[附录12.34](github 3.6k stars)是一个不错选择 。proxy模式运维成本较高,建议中大规模场景,有一定框架自研和运维能力的团队采用。
任务调度系统,个人推荐徐雪里开源的xxl-job[附录12.35](github 3.4k stars),部署简单轻量,大部分场景够用。当当开源的elastic-job[附录12.36](github 3.2k stars)也是一个不错选择,相比xxl-job功能更强一些也更复杂。