内容安全综合实践-数字水印
DCT实现数字水印功能模块
1.整体效果
- 功能:添加和提取字符水印,添加和提取图片水印
- 整体效果

2.数字水印的基本特点
(1) 不可见性。在宿主数字媒体中嵌入一定数量的附加信息后,不能引起明显的将质现象,隐藏的数据不易觉察,即无法人为的看见或听见。
(2) 稳健性。数字水印必须对施加于宿主媒体的变化或操作具有一定的免疫力,不能因为某种变换操作导致水印信息的丢失,即水印被迫坏,从而失去商用价值。常用的变换操作有:信道噪声、滤波、有损压缩、重采样等。
(3) 安全性。数字水印应该能够抵抗各种蓄意的攻击,同时应很难被他人复制和伪造。
(4) 有效性。水印提取算法应高效,提取出的水印应能唯一标识版权所有者。
(5)抗窜改性。 与抗毁坏的鲁棒性不同,抗窜改性是指水印一旦嵌入到载体中,攻击者就很难改变或伪造。鲁棒性要求高的应用,通常也需要很强的抗窜改性,在版权保护中,要达到好的抗窜改性是比较困难的。
3.实现关键技术
(一)数字水印嵌入过程
频域法加入数字水印的原理是首先将原始信号(语音一维信号、图像二维信号)变换到频域,常用的变换一般有DWT、DCT、DFT、WP和分形。然后,对加入了水印信息的信号进行频域反变换(IDWT、IDCT、DFT、WP),得到含有水印信息的信号。
(二)DCT算法
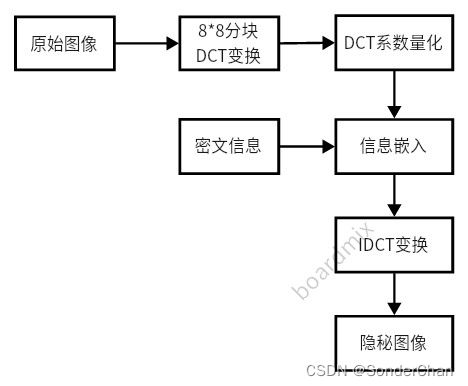
离散余弦变换(DCT)数字水印算法是首先把图像分成8×8的不重叠像素块,在经过分块DCT变换后,即得到由DCT系数组成的频率块,然后随机选取一些频率块,将水印信号嵌入到由密钥控制选择的一些DCT系数中。该算法是通过对选定的DCT系数进行微小变换以满足特定的关系,以此来表示一个比特的信息。
(三)DCT变换水印的实现
数字图像水印算法选择二值化灰度图像作为水印信息,根据水印图像的二值性选择不同的嵌入系数,并将载体图像进行8×8的分块,将数字水印的灰度值直接植入到载体灰度图像的DCT变换域中,实现水印的嵌入。
1.将原始图像进行8×8分块
2.对每个分块进行DCT变换
3.加载水印对每一个DCT变换后的分块
4.对每一个加载水印后的分块进行逆dct变换,完成从频域到空域的变换,合并为一个整图
水印嵌入算法流程:
水印提取算法流程:

(四)文字水印嵌入
主要思路是我们知道图像是由一个一个的像素点构成的,而每个像素点是由rgb三原色组成,也就是说每个点可以表示为(0-255,0-255,0-255)的一个tuple。由于人眼识别的能力有限,修改最后一位是无法用肉眼发现差异的,如果我们能够将这些数据的最后一位提取出来作为信息位存储信息,那么便能够向图片中嵌入信息了。
4.代码实现
word_watermark.py
from PIL import Image
import numpy as np
import functools
#文字嵌入
#由于人眼识别的能力有限,修改最后一位是无法用肉眼发现差异的,
# 如果我们能够将这些数据的最后一位提取出来作为信息位存储信息,那么便能够向图片中嵌入信息
#信息嵌入函数
def embedding_info(picname, savename, text):
text += '#%#' # 作为结束标记
im = np.array(Image.open(picname))
rows, columns, colors = im.shape
embed = []
for c in text:
#由于我们需要支持中文信息的嵌入,我们这里使用16的bit位来存储信息,
# 因此我们使用 '(bin(ord(c))[2:]).zfill(16)' 来将字符转换成二进制编码并在高位补0至16位。
bin_sign = (bin(ord(c))[2:]).zfill(16)
for i in range(16):
embed.append(int(bin_sign[i]))
#将处理后的比特流逐位替换掉原图像中的RGB值的最后一位
count = 0
for row in range(rows):
for col in range(columns):
for color in range(colors):
if count < len(embed):
im[row][col][color] = im[row][col][color] // 2 * 2 + embed[count]
count += 1
Image.fromarray(im).save(savename)
def extract_info(picname):
im = np.array(Image.open(picname))
rows, columns, colors = im.shape
text = ""
extract = np.array([], dtype=int)
count = 0
for row in range(rows):
for col in range(columns):
for color in range(colors):
extract = np.append(extract, im[row][col][color] % 2)
count += 1
if count % 16 == 0:
bcode = functools.reduce(lambda x, y: str(x) + str(y), extract)
cur_char = chr(int(bcode, 2))
text += cur_char
if cur_char == '#' and text[-3:] == '#%#':
return text[:-3]
extract = np.array([], dtype=int)
#图片的格式最好为PNG格式,其他形如jpg,jpeg格式的图像文件在处理的过程中由于会对原图进行压缩,
# 可能导致信息位被破坏而失去嵌入其中的信息
# text = "Hello, world!"
# embedding_info('1.png', 'After.png', text)
# a=extract_info('After.png')
# print(a)
dct_watermark.py
import cv2
import numpy as np
import matplotlib.pyplot as plt
from word_watermark import *
import sys
from PyQt5 import QtWidgets, QtCore, QtGui
from PyQt5.QtGui import *
from PyQt5.QtWidgets import * #导入 PyQt5.QtWidgets 中的所有部件
from PyQt5.QtCore import *
from PyQt5.QtWidgets import QWidget, QPushButton, QApplication, QMainWindow
# 主要参考https://blog.csdn.net/WilsonSong1024/article/details/80318006、https://github.com/lfreya/Watermark-embed-and-extract进行实现
class DCT_Embed(object):
# 定义参数背景图,水印图片,块数,水印强度
def __init__(self, background, watermark, block_size=8, alpha=30):
b_h, b_w = background.shape[:2] # 获取背景图的高和宽
w_h, w_w = watermark.shape[:2] # 获取水印图片的高和宽
assert w_h <= b_h / block_size and w_w <= b_w / block_size, \
"\r\n请确保您的的水印图像尺寸 不大于 背景图像尺寸的1/{:}\r\nbackground尺寸{:}\r\nwatermark尺寸{:}".format(
block_size, background.shape, watermark.shape )# 判断水印图片的高和宽是否小于等于原始图的1/8倍
# 保存参数
self.block_size = block_size
# 水印强度控制
self.alpha = alpha
# 随机的序列
self.k1 = np.random.randn(block_size)
self.k2 = np.random.randn(block_size)
# 对图片进行分块,分成8*8个方块,对每个方块进行DCT变换
def dct_blkproc(self, background):
"""
对background进行分块,然后进行dct变换,得到dct变换后的矩阵
:param image: 输入图像
:param split_w: 分割的每个patch的w
:param split_h: 分割的每个patch的h
:return: 经dct变换的分块矩阵、原始的分块矩阵
"""
background_dct_blocks_h = background.shape[0] // self.block_size # 每个方块的高度 取整
background_dct_blocks_w = background.shape[1] // self.block_size # 每个方块的宽度
background_dct_blocks = np.zeros(shape=(
(background_dct_blocks_h, background_dct_blocks_w, self.block_size, self.block_size)
)) # 前2个维度用来遍历所有block,后2个维度用来存储每个block的DCT变换的值
# 返回来一个给定形状和类型的用0填充的数组
# 实现参照https://www.cnblogs.com/gxgl314/p/9287628.html
h_data = np.vsplit(background, background_dct_blocks_h) # 垂直方向分成background_dct_blocks_h个块
for h in range(background_dct_blocks_h):
block_data = np.hsplit(h_data[h], background_dct_blocks_w) # 水平方向分成background_dct_blocks_w个块
for w in range(background_dct_blocks_w):
a_block = block_data[w]
background_dct_blocks[h, w, ...] = cv2.dct(a_block.astype(np.float64)) # dct变换
return background_dct_blocks
# 加载水印
def dct_embed(self, dct_data, watermark):
"""
将水印嵌入到载体的dct系数中
:param dct_data: 背景图像(载体)的DCT系数
:param watermark: 归一化二值图像0-1 (uint8类型)
:return: 空域图像
"""
temp = watermark.flatten() # 返回一个一维数组
assert temp.max() == 1 and temp.min() == 0, "为方便处理,请保证输入的watermark是被二值归一化的"
result = dct_data.copy()
for h in range(watermark.shape[0]):
for w in range(watermark.shape[1]):
k = self.k1 if watermark[h, w] == 1 else self.k2
# 查询块(h,w)并遍历对应块的中频系数(主对角线),进行修改
for i in range(self.block_size):
result[h, w, i, self.block_size - 1] = dct_data[h, w, i, self.block_size - 1] + self.alpha * k[i]
return result
# 对dct矩阵进行idct变换,完成从频域到空域的变换
def idct_embed(self, dct_data):
"""
进行对dct矩阵进行idct变换,完成从频域到空域的变换
:param dct_data: 频域数据
:return: 空域数据
"""
row = None
result = None
h, w = dct_data.shape[0], dct_data.shape[1]
for i in range(h):
for j in range(w):
block = cv2.idct(dct_data[i, j, ...])
row = block if j == 0 else np.hstack((row, block))
result = row if i == 0 else np.vstack((result, row))
return result.astype(np.uint8)
# 提取水印
def dct_extract(self, synthesis, watermark_size):
"""
从嵌入水印的图像中提取水印
:param synthesis: 嵌入水印的空域图像
:param watermark_size: 水印大小
:return: 提取的空域水印
"""
w_h, w_w = watermark_size
recover_watermark = np.zeros(shape=watermark_size)
synthesis_dct_blocks = self.dct_blkproc(background=synthesis) # 讲嵌入水印的图片分成8*8个方块
p = np.zeros(8)
# 对每一个方块进行二维DFT变换:DBD=DCT(BD)
for h in range(w_h):
for w in range(w_w):
for k in range(self.block_size):
p[k] = synthesis_dct_blocks[h, w, k, self.block_size - 1]
if corr2(p, self.k1) > corr2(p, self.k2):
recover_watermark[h, w] = 1
else:
recover_watermark[h, w] = 0
return recover_watermark
# https://www.cnpython.com/qa/183113
def mean2(x):
y = np.sum(x) / np.size(x);
return y
def corr2(a, b):
"""
相关性判断
"""
a = a - mean2(a)
b = b - mean2(b)
r = (a * b).sum() / np.sqrt((a * a).sum() * (b * b).sum())
return r
def openimage():
imgName, imgType = QFileDialog.getOpenFileName()
jpg = QtGui.QPixmap(imgName).scaled(label1.width(), label1.height())#待嵌入的图片
label1.setPixmap(jpg)
#def openimage2():
imgName2, imgType2 = QFileDialog.getOpenFileName()
jpg = QtGui.QPixmap(imgName2).scaled(label2.width(), label2.height())#待嵌入的图片
label2.setPixmap(jpg)
main(imgName,imgName2)
print(imgName)
#if __name__ == '__main__':
def main(watermark_name,background_name):
root = ".."
# 0. 超参数设置
alpha = 100 # 尺度控制因子,控制水印添加强度,决定频域系数被修改的幅度
blocksize = 8 # 分块大小
# 1. 数据读取
# watermak
watermark = cv2.imread(watermark_name, cv2.IMREAD_GRAYSCALE)
watermark = np.where(watermark < np.mean(watermark), 0, 1) # watermark进行(归一化的)二值化
background = cv2.imread(background_name)
background = cv2.cvtColor(background, cv2.COLOR_BGR2RGB)
background_backup = background.copy()
yuv_background = cv2.cvtColor(background, cv2.COLOR_RGB2YUV) # 将RBG格式的背景转为YUV格式,Y为灰度层,U\V为色彩层,此处选择U层进行嵌入
Y, U, V = yuv_background[..., 0], yuv_background[..., 1], yuv_background[..., 2]
bk = U # 嵌入对象为bk
# 2. 初始化DCT算法
dct_emb = DCT_Embed(background=bk, watermark=watermark, block_size=blocksize, alpha=alpha)
# 3. 进行分块与DCT变换
background_dct_blocks = dct_emb.dct_blkproc(background=bk) # 得到分块的DCTblocks
# 4. 嵌入水印图像
embed_watermak_blocks = dct_emb.dct_embed(dct_data=background_dct_blocks, watermark=watermark) # 在dct块中嵌入水印图像
# 5. 将图像转换为空域形式
synthesis = dct_emb.idct_embed(dct_data=embed_watermak_blocks) # idct变换得到空域图像
yuv_background[..., 1] = synthesis
rbg_synthesis = cv2.cvtColor(yuv_background, cv2.COLOR_YUV2RGB)
# 6. 提取水印
extract_watermark = dct_emb.dct_extract(synthesis=synthesis, watermark_size=watermark.shape) * 255
#extract_watermark.astype(np.uint8)
#c=plt.imshow(rbg_synthesis)
#
# plt.imshow(rbg_synthesis,cmap=plt.cm.gray)
# plt.savefig('5.png')
# jpg = QtGui.QPixmap('5.png').scaled(label3.width(), label3.height())
#plt.show()
#print(type(rbg_synthesis))
#label3.setPixmap(jpg)
# image = rbg_synthesis.fromarray(np.uint8.convert('RGB') # 从numpy转成PIL格式
# image = image.resize((pri_image.shape[1], pri_image.shape[0]), resample=Image.BILINEAR) # 图片格式
# # 保存到本地
# image.save(save_dir)
plt.imshow(rbg_synthesis)
plt.axis("off")
plt.savefig('5.png',bbox_inches='tight',pad_inches=0)
jpg = QtGui.QPixmap('5.png').scaled(label2.width(), label2.height())
label4.setPixmap(jpg)
plt.imshow(extract_watermark,cmap=plt.cm.gray)
plt.axis("off")
#plt.show()
plt.savefig('6.png', bbox_inches='tight', pad_inches=0)
jpg = QtGui.QPixmap('6.png').scaled(label1.width(), label1.height())
label3.setPixmap(jpg)
#7. 可视化处理
images = [background_backup, watermark, rbg_synthesis, extract_watermark]
titles = ["background", "watermark", "systhesis", "extract"]
for i in range(4):
plt.subplot(2, 2, i + 1)
if i%2:
plt.imshow(images[i],cmap=plt.cm.gray)
else:
plt.imshow(images[i])
plt.savefig('6.png')
#plt.title(titles[i])
plt.axis("off")
plt.show()
def run():
get_text = le.text()
imgName, imgType = QFileDialog.getOpenFileName()
jpg = QtGui.QPixmap(imgName).scaled(label1.width(), label1.height()) # 待嵌入的图片
label6.setPixmap(jpg)
# def openimage2():
embedding_info(imgName, 'After.png', get_text)
a=extract_info('After.png')
label22.setText(a)
print(a)
app = QApplication(sys.argv)
#app = QApplication([])
window = QMainWindow()
window.resize(1500, 700)
window.move(300, 310)
window.setWindowTitle('数字水印嵌入和提取')
label11 =QLabel(window)
label11.move(300,20)
label11.resize(150,50)
label11.setText('嵌入水印')
label1 = QLabel(window)
label1.move(200,60)
label1.resize(250,250)
label1.setScaledContents(True)
label11 =QLabel(window)
label11.move(300,350)
label11.resize(150,50)
label11.setText('原始图片')
label2 = QLabel(window)
label2.move(200,390)
label2.resize(250,250)
label11 =QLabel(window)
label11.move(700,20)
label11.resize(150,50)
label11.setText('提取水印')
label3 = QLabel(window)
label3.move(600,60)
label3.resize(250,250)
label11 =QLabel(window)
label11.move(700,350)
label11.resize(150,50)
label11.setText('带水印图片')
label4 = QLabel(window)
label4.move(600,390)
label4.resize(250,250)
button1 = QPushButton('选择水印和原图', window)
button1.move(30,20)
button1.resize(150,50)
button1.clicked.connect(openimage)
button2 = QPushButton('选择图片文本嵌入', window)
button2.move(30,90)
button2.resize(150,50)
button2.clicked.connect(run)
# button2 = QPushButton('选择图片', window)
# button2.move(300,250)
# button2.clicked.connect(openimage)
label5 = QLabel(window)
label5.move(1000,20)
label5.resize(150,50)
label5.setText('输入带嵌入信息:')
label5 = QLabel(window)
label5.move(1000,400)
label5.resize(150,50)
label5.setText('提取文本水印:')
le = QLineEdit(window)
le.move(1150,20)
le.resize(200,50)
label22 =QLabel(window)
label22.move(1150,400)
label22.resize(200,50)
label22.setStyleSheet('background-color:#838383;color:white;font:bold 17px;')
label6 = QLabel(window)
label6.move(1100,100)
label6.resize(250,250)
#label11.setText('带水印图片')
window.show()
sys.exit(app.exec_())
字符水印嵌入提取的代码来源文章
https://blog.csdn.net/Empire_03/article/details/82262680?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168813317516800215023869%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=168813317516800215023869&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allbaidu_landing_v2~default-1-82262680-null-null.142v88insert_down28v1,239v2insert_chatgpt&utm_term=%E6%96%87%E5%AD%97%E6%B0%B4%E5%8D%B0%E5%B5%8C%E5%85%A5&spm=1018.2226.3001.4187
数字图像DCT算法代码文章