4hadoopHDFS集群搭建-伪分布式模式
hadoop旧版网址:http://hadoop.apache.org/old/
2.6.5 版本
ssh协议在免密登陆其他机器的时候,不会加载其他机器的环境变量。就是不会加载/etc/profile文件
在免密登陆别的机器时,如果需要环境变量可以先加载环境变量,然后在执行命令。
例如:ssh [email protected] ’ source /etc/profile ; echo $PATH’即可
伪分布式模式:单节点,所有的角色NN,DN在一台机器上
完全分布式模式:多节点,NN和DN不在一台机器上
思路:
基础设施
部署配置
初始化运行
命令行使用
实操:
基础设施:操作系统、环境、网络,必须软件
1.设置IP及主机名
设置ip前面教程由 vi /etc/sysconfig/network-scruots/ifcfg-eth0
设置主机名 vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node1
2.关闭防火墙和selinux
service iptables stop
chkconfig iptables off 开机不启动
vi /etc/selinux/config
如下修改;
#SELINUX=enforcing
SELINUX=disabled
3.设置hosts映射
配置hosts
vi /etc/hosts
192.168.111.3 node01
4.时间同步
所有机器的时间要同步
需要安装ntp 命令: yum install ntp -y
vi /etc/ntp.conf
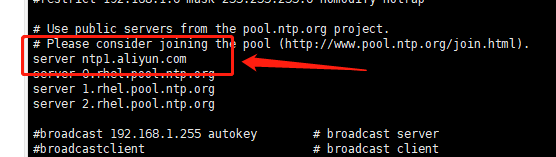
加入这个,这个是阿里互联网的时间同步服务器
机器就会跟这个服务器同步时间
启动命令 service ntpd start
chkconfig ntpd on
5.安装jdk
yum install lrzsz -y 安装rz sz命令
rz上传
sz 下载
yum install wget 安装wget命令
安装jdk命令
rpm -i jdk-8u212-linux-x64.rpm
注意写软件不认JAVAHOME 而是在/usr/java/default找jdk 所以如果用压缩包按转发的话 要注意是否会有这个目录
配置环境变量:
vi /etc/profile
在文件最后两行追加如下:
export JAVA_HOME=/usr/java/default
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
source /etc/profile 让profile文件立即生效
6.设置SSH免密钥
ssh免密验证:ssh localhost
执行这个命令验证是否可以免密登陆 同时生成了/root/.ssh 文件
ssh-keygen 创建公钥秘钥的命令 注意没有空格
-t dsa dsa是加密算法
-P ‘’ 设置空密码(此处不要写密码否则会有问题)(如果弄错了就把生成的id_dsa和id_dsa.pub两个文件删除,重新生成即可)
-f 给出存放公钥秘钥的路径 一般是在/root/.ssh/id_dsa 目录下
ssh-keygen -t dsa -P ‘’ -f /root/.ssh/id_dsa
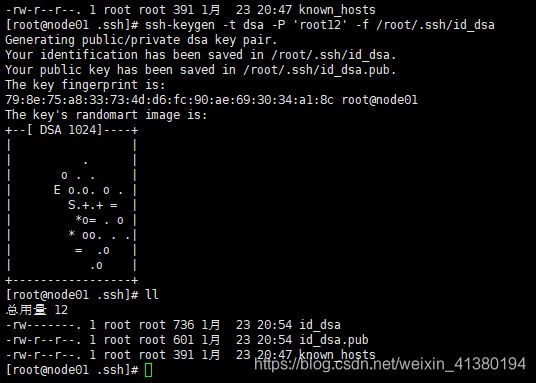
会生成两个文件 id_dsa是秘钥 id_dsa.pub是公钥
想要免密登陆到别的机器上去的话,将自己的公钥放到别人的/root/.ssh/authorized_keys的目录中
cat id_dsa.pub >> /root/.ssh/authorized_keys
然后用ssh localhost去验证即可。
2.Hadoop应用部署
伪分布式:(单一节点) 就是在一台机器上要有NN SNN DN 就是伪分布式啦。
1.部署路径
2.配置文件
hadoop-env.sh
core-site.xml
hdfs-site.xml
slaves
1.在opt目录下建立大数据的专属目录
下载hadoop2.6.5压缩包
然后上传并且解压。
解压命令:tar xf hadoop-2.6.5.tar.gz
会生成hadoop-2.6.5目录。
规划路径:
mkdir /opt/bigdata
tar xf hadoop-2.6.5.tar.gz 生成hadoop-2.6.5
将此目录移动至bigdata目录下
进入hadoop-2.6.5目录中:bin中放着hadoop自己模块的命令 sbin目录中就是命令对应的可执行文件
配置环境变量:
export HADOOP_HOME=/opt/bigdata/hadoop-2.6.5
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin: H A D O O P H O M E / b i n : HADOOP_HOME/bin: HADOOPHOME/bin:HADOOP_HOME/sbin
source /etc/profile
cd $HADOOP_HOME 就会切换到该环境变量对应的目录下
修改hadoop中的etc的hadoop中的配置文件:
vi hadoop-env.sh
原本的值:
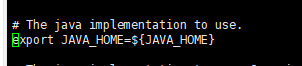
这种配置方式在免密登陆的时候,应为不执行source profile命令,所以不会加载环境变量,所以这里就取不到值。
所以要把这里换为java的绝对路径JAVA_HOME=/usr/java/default
然后修改:vi core-site.xml 这个是核心配置 当启动时读取到这个文件就会知道从hdfs:/localhost:9000这个服务器的端口启动NameNode
如果是DataNode读取这个文件,就会知道自己要跟那个机器的那个端口的NameNode通信
如果是客户端读取这个文件,就通过这个机器的这个端的NameNode知道了DataNode的信息
这个文件就是定义NameNode在哪里启动
原本就是空的
现在改为:
fs.defaultFS
hdfs://node01:9000 //记得配置hosts文件
然后修改:
vi hdfs-site.xml
原本为空
现在改为:
修改slaves文件:文件是空的 改为node01 表示在哪个机器启动dataNode
hdfs-default.xml文件中(这个文件是官网的,也不知道具体在哪个目录)的下面配置
dfs.namenode.name.dir file:// h a d o o p . t m p . d i r / d f s / n a m e 引 用 了 c o r e − d e f a u l t . x m l 文 件 中 的 h a d o o p . t m p . d i r / t m p / h a d o o p − {hadoop.tmp.dir}/dfs/name 引用了core-default.xml文件中的hadoop.tmp.dir /tmp/hadoop- hadoop.tmp.dir/dfs/name引用了core−default.xml文件中的hadoop.tmp.dir/tmp/hadoop−{user.name}配置
发现使用了/tmp目录 这是linux的临时目录,如果满了会自动删除的,尼玛 巨坑啊
所以要将这个隐藏很深的巨无霸处理掉
如何处理:在hdfs_site.xml文件中加入配置:如下:
4yy 复制4行 p粘贴
dfs.replication
1
dfs.namenode.name.dir
/var/bigdata/hadoop/local/dfs/name
dfs.datanode.data.dir
/var/bigdata/hadoop/local/dfs/data
3.初始化和启动
第一步先要格式化:只格式化namenode
hdfs namenode -format
执行成功后进入到我们配置的目录中,会有current文件夹,进入
/var/bigdata/hadoop/local/dfs/name/current
查看VERSION文件:
namespaceID=1277576943
clusterID=CID-b5bed8b3-e15f-47f4-bd92-8aff5540042e //集群id 假如一个公司有1000台机器,每500台搭建一个hadoop集群这个时候,会有两个集群ID,这个就不会有两个集群就不会有交集,不会错乱。 集群id就是为了防止多个hadoop集群的错乱 错乱是说集群a的datanode去给集群b的nameNode回报信息。
cTime=0
storageType=NAME_NODE
blockpoolID=BP-644009053-192.168.3.23-1611411176532
layoutVersion=-60
格式化的目的就是创建目录以及生成集群id。
格式化一次就好了,不要重复格式化。如果集群id和datanode同步了 再次格式化 会出大问题的。datanode就不会跟namenode通信了
进入:/opt/bigdata/hadoop-2.6.5/sbin目录
vi start-dfs.sh

这个脚本会启动nameNode secondary Namemode datanode. 还有守护进程
看守护进程
vi hadoop-daemons.sh

会执行slaves脚本:
查看这个脚本:
vi slaves.sh
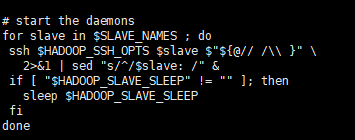
这里就是循环免密登陆所有datanode节点启动datanode的节点,这时候不会加载环境变量,所以datanode节点的java配置必须是绝对路径。
启动hdfs:
在任何目录下执行这个start-dfs.sh都行。
执行后它会读取我们上面修改过的文件
糟糕,没有配置namenode在哪里启动,默认会在当前机器启动:

然后 jps验证
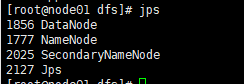
补充secondarynamenode的配置:

startup progress 描述的是hadoop启动的时候在安全模式下,使用的那个edits文件以及fsimage文件进行和合并的。
SNN 只需要从NN拷贝最后时点的FSimage和增量的Editlog
utilties 模块可以看hdfs文件系统目前有哪些文件以及数量。
简单使用: hdfs dfs 会出现帮助文档。
hdfs dfs -mkdir /bigdata
这个命令会在hdfs文件系统中的根目录创建bigdata目录
一般会创建这么个目录 创建用户当前的家目录
hdfs dfs -mkdir -p /usr/root 递归创建
hdfs dfs -put jdk-8u212-linux-x64.rpm /usr/root将这个文件推送到hdfs系统中的指定目录上
在上传的过程中会先jdk-8u212-linux-x64.rpm_COPYING使用这个名字占用,当上传完成后,将去掉COPYING.
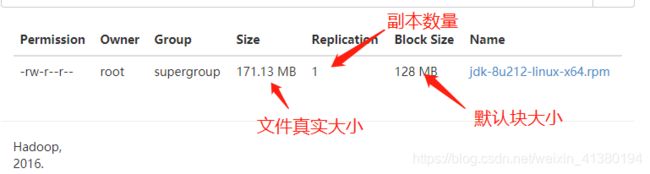
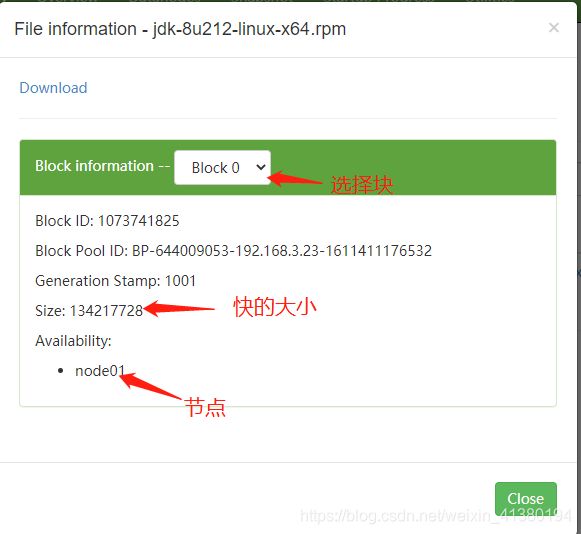
点击文件名会展示文件有几个块,将每个块的大小以及位置
看看datanode的数据目录:
cd /var/bigdata/hadoop/local/dfs/data/current/BP-644009053-192.168.3.23-1611411176532/current/finalized/subdir0/subdir0/
上传了一个文件,文件大小大于128MB,所以会有两个块。此目录下会有4个文件

验证-----是否线性切割--------:
执行这个命令:遍历100000,每行输出hello hadoop i
for i in seq 100000;do echo “hello hadoop $i” >> data.txt; done
得到data.txt
ls -l -h h表示可读的单位

如果现在以1MB块大小上传这个文件,也会有两个块。
以指定块大小来上传data.txt文件到指定目录.
hdfs dfs -D dfs.blocksize=1048576 -put data.txt /usr/root
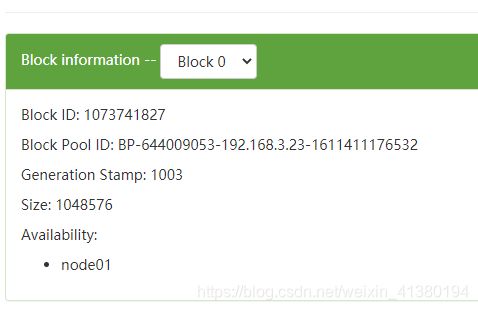
所以文件按照字节线性切割。
进入下面目录:
/var/bigdata/hadoop/local/dfs/data/current/BP-644009053-192.168.3.23-1611411176532/current/finalized/subdir0/subdir0
vi blk_1073741827查看刚才上传文件的第一个块的最后一行
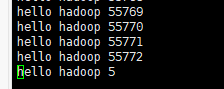
我草 文件切坏了。
第二个块:
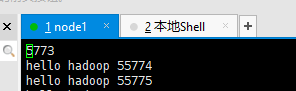
两个刚好可以拼接上