python数据分析——数据分析的统计推断
数据分析的统计推断
- 前言
- 一、提出问题
- 二、统计归纳方法
- 三、统计推断
- 四、统计推断步骤
-
- 1.点估计
- 2.区间估计
- 3. 假设检验
- 4. 假设检验的假设
- 5.显著性水平
- 五、检验统计量
- 六、检验方法
- 七、拒绝域
- 八、假设检验步骤
- 九、重要假设检验方法
-
- 1. z检验
- 2. t检验
- 3. F检验
- 4 .卡方检验
前言
认识过程是从个别到一般,又由一般再到个别的过程。通过个别认识一般的主要思维方法是归纳,是从个别或特殊事物概括出一般原理的逻辑思维方法,在逻辑上叫做归纳推理。
不完全归纳推理是统计推理归纳中比较常用的一种方法。不完全统计仅仅从集合中抽取少量或具有代表性的元素进行归纳,所以不完全归纳是统计归纳常用的数学工具之一。
一、提出问题
为了对首都经济贸易大学本科一年级2500学生的微积分成绩进行考察,准备随机抽取10名学生来研究所有学生微积分的平均成绩,也就是用不完全归纳推理来获得平均成绩。我们有如下信息:
总体:2500名学生。
总体服从正态分布,均值和方差都是未知。
待估计总体参数:平均成绩。
样本容量:10名学生。
抽样方式:随机抽样。
抽样值: 85, 78, 90, 81, 83, 89, 77, 85, 72, 80。
统计量:样本均值。
目标一:通过统计归纳推理获得总体参数, 2500名学生微积分的平均成绩的估计。
目标二:在95%是置信度,及著性水平为5%的情况下,计算2500名学生的平均成绩
进行区间估计
目标三:对微积分的平均成绩进行假设检验。
二、统计归纳方法
统计归纳是根据样本具有的一些属性推出总体具有这些属性的归纳推理方法。所谓样本就是从总体中抽选出来的那一部分对象。使用这种方法时,首先要选好样本,处理好样本的代表性与样本数量之间的关系。样本的数量越大,样本的代表性就越大。
总的来说,统计归纳推理是由部分推出全部的归纳推理,我们不知道总体是什么样的,但是我们已经知道我拿在手里的样本是什么样的,我们想依靠我们掌握的样本的属性去推断总体属性是什么。
统计归纳的结论不可能百分之百正确,也就是说结论是或然的。利用概率论,我们可以研究通过样本推测总体的时候所犯得错误是多少。比如说,在随机抽取的100万选民中, 60%支持现任总统,因此在总统竞选中现任总统会得到60%选民的支持。
三、统计推断
统计推断包括:对总体的未知参数进行估计,对关于参数的假设进行检查和验证,对总体进行预测。科学的统计推断所使用的样本,通常通过随机抽样方法得到。
统计推断的理论和方法论的基础是来自于概率论和数理统计学。统计推断的一个基本特点是其所依据的条件中包含有带随机性的观测数据。
如何理解带随机性的观测数据?我们手里有的就是样本信息,比如,我们从2500名学生中抽取10个学生样本。在这里要注意样本的两重性,样本既可看成具体的数,又可以看成随机变量。在完成抽样后,它是具体的数,在实施抽样之前,它被看成随机变量。因为在实施具体抽样之前无法预料抽样的结果,只能预料它可能取值的范围,所以可把它看成一个随机变量,因此才有概率分布可言。
四、统计推断步骤
那么我们如何进行统计推断?当我们获得有效样本数据后,统计推断问题可以按照如下的步骤进行:
- 步骤1:确定用于统计推断的合适统计量。
- 步骤2:寻找统计量的精确分布。如果出现统计量的精确分布难以求出的情况下,可考虑利用中心极限定理或其它极限定理找出统计量的极限分布。
- 步骤3:基于该统计量的精确分布或极限分布,求出统计推断问题的精确解或近似解。
- 步骤4:根据统计推断结果对问题作出解释。
统计推断的基本问题可以分为两大类:
- 一类是参数估计问题,包括点估计和区间估计;
- 另一类是假设检验问题。我们将分别进行介绍。
1.点估计
点估计是以抽样得到的样本统计量作为总体参数的估计量,并以样本统计量的实际值直接作为总体未知参数的估计值的一种推理方法。
常见点估计方法有矩估计,最小二乘估计,极大似然估计,贝叶斯估计,在本节中,我们讨论矩估计的基本概念。
矩估计法的理论依据是大数定理,是基于一种简单的“替换”思想,即用样本矩估计总体矩。其特点是简单易行,并不需要事先知道总体是什么分布。最常见的矩估计是利用均值或方差来计算总体未知参数。
矩估计就是用样本的矩函数作为统计量,其原理就是构造样本矩和总体矩,然后用样本矩去估计总体矩。
设有样本:X1,X2,…,X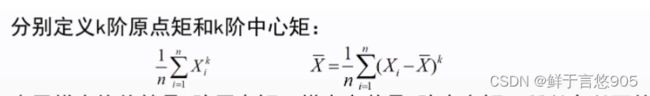
由于样本均值就是1阶原点矩,样本方差是2阶中心矩,所以在以下的关于矩估计的讨论主要集中数学期望和方差的估计。
由于矩估计不考虑抽样误差,直接用样本矩估计总体参数的一种推断方法。因为个别样本的抽样统计值不等于总体的参数,所以,用样本矩直接估计总体的参数,不可避免的会有误差。
点估计具有的标准特点为无偏性和有效性。从数学上不难证明,样本均值(一阶原点矩)是关于总体数学期望的一个无偏估计。但是,样本的方差(二阶中心矩)并非总体的方差的无偏估计。在实际应用中,我们通常用样本均值估计总体均值,用样本方差估计总体方差,用样本标准差估计总体标准差。
我们继续讨论关于学生微积分成绩的例子。我们将通过统计归纳推理获得2500名学生的平均成绩。由于抽样数据为: 85, 78, 90, 81, 83, 89, 77, 85,72, 80,我们可以计算出样本均值为82,我们就可以认为总体均值,即2500名学生微积分的平均成绩为82分。
2.区间估计
区间估计是在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常由样本统计量加减估计误差得到。与点估计不同,进行区间估计时,根据样本统计量的抽样分布可以对样本统计量与总体参数的接近程度给出一个概率意义上的度量。
为了理解区间估计,我们来讨论关于置信度,置信区间,和显著性水平的相关概念。置信区间是根据样本信息推导出来的可能包含总体参数的数值区间,置信度表示置信区间的可信度。置信度一般用百分数来表示,表示成(1-a) 100%,其中a指的是显著性水平,表示总体参数不落在置信区间的可能性。
比如,一个学校学生的平均身高的区间估计情况,有95%的置信度可以认为该校学生的平均身高为1.4米到1.5米之间,那么[1.4,1.5]是置信区间, 95%是置信度,著性水平为5%。如果抽样100次,有信心认为这个区间大约有95次包含该校学生的平均身高。有5次不包括。
置信度越大,置信区间包含总体参数真值的概率就越大,同时区间的长度就越大,对未知参数估计的精度就越差。计算置信区间的基本思想为在点估计的基础上,构造合适的函数,并针对给定的置信度计算出置信区间。
我们来讨论关于总体均值的区间估计问题,假设容量为n的样本,是从正态分布总体中随机抽取。为了计算总体均值的区间估计,我们需要考虑二种情况,一是正态总体的标准差已知,二是标准差未知。
- 总体方差已知
在大样本情况下,总体服从正态分布,总体方差已知,总体均值在置信水平(1-a)下的置信区间为:
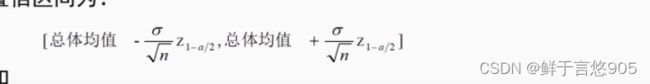
2总体方差未知
当正态总体的方差未知,且为小样本条件下,总体均值在置信水平(1-a)下的置信区间为:
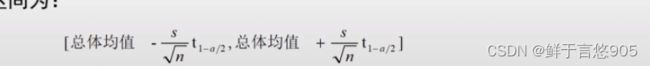
我们继续讨论关于学生微积分成绩的例子。我们将计算2500名学生的平均成绩估计值的置信区间。由于总体方差是未知,我们将利用样本方差和t分布来计算置信度为95%的置信区间。由于样本方差标准差s=5.49, n=10, t1-a/2 =2.26 我们有: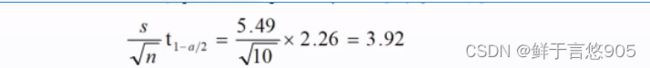
所以, 2500名学生微积分的平均成绩82分的置信区间为: [82-3.92,82+3.92]
3. 假设检验
假设检验是用来判断样本与样本,样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。显著性检验是假设检验中最常用的一种方法,也是一种最基本的统计推断形式,其基本原理是先对总体的特征做出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受做出推断。
假设检验这种统计推断方法是带有概率性质的反证法,是利用“小概率事件”的原理。所谓小概率思想是指小概率事件在一次试验中基本上不会发生。反证法思想是先对总体参数提出一个假设值,再用样本信息和适当的统计方法,利用小概率原理,确定假设是否成立。如果样本观察值导致了“小概率事件”发生,就应拒绝提出的假设,否则应接受假设。
在实践中,常用的假设检验方法有基于正态分布的Z检验,t分布的t检验,卡方分布的卡方检验,F分布的F检验。
4. 假设检验的假设
由定义可知,我们需要对结果进行假设,然后拿样本数据去验证这个假设。所以做假设检验时会设置两个假设,一种叫原假设,通常用HO表示。原假设一般是设计者想要拒绝的假设。原假设的设置条件一般有:等于(=),大于等于(>=) ,和小于等于(<=)。
另外一种叫备择假设,一般用H1表示。备则假设是设计者想要接受的假设。
备择假设的设置一般为不等于(丰),大于(>),小于(<)的形式。为什么设计者想要拒绝的假设放在原假设呢?如果原假设备被拒绝,结果是错误的话,只能犯第1类错误,而犯第1类错误的概率已经被规定的显著性水平所控制。
我们通过样本数据来判断总体参数的假设是否成立,但样本是随机抽取的,因而有可能出现小概率的错误。
这种错误分两种,
- 一种是弃真错误,也称为第一类错误,
- 另一种是取伪错误,也称为第二类错误。
弃真错误是指原假设实际上是真的,但通过样本估计总体后,拒绝了原假设。明显这是错误的,我们拒绝了真实的原假设,所以叫弃真错误,这个错误的概率记为a。这个值也是显著性水平,在假设检验之前会规定这个概率的大小。
取伪错误它是指原假设实际上假的,但通过样本估计总体后,接受了原假设。显然是错误的,我们接受的原假设实际上是假的,所以叫取伪错误,这个错误的概率记为β。
这就是为什么原假设一般都是想要拒绝的假设了么?如果原假设备被拒绝,如果出错的话,只能犯弃真错误,而犯弃真错误的概率已经被规定的显著性水平所控制了。这样对设计者来说更容易控制,将错误影响降到最小。
5.显著性水平
单理解就是犯弃真错误的概率。这个值是我们做假设检验之前数据分析人员根据业务情况事先确定好的。
显著性水平是指当原假设实际上正确时,检验统计量落在拒绝域的概率,简我们通常把假设检验中的显著性水平显著性水平用a表示,也就是决策中所面临的风险。a越小,犯第一类错误的概率也就越小。
五、检验统计量
假设检验需要借助样本统计量进行统计推断,我们也称这样的通缉令为检验统计量。不同的假设检验问题需要选择不同的检验统计量。
检验统计量是用于假设检验计算的统计量,是根据对原假设和备择假设作出决策的某个样本统计量。
检验统计量是用于进行假设检验的计算量,通常根据样本数据计算得出,用于衡量样本数据与假设之间的差异。
常见的检验统计量包括:
- t值:用于检验样本均值与总体均值之间是否有显著差异,适用于小样本情形。
- F值:用于检验多个总体方差是否相等,适用于方差分析。
- 卡方值:用于检验观测值和期望值的偏差程度,适用于卡方检验。
- Z值:用于检验样本比例与总体比例之间是否有显著差异,适用于大样本情形。
以上检验统计量都有其特定的计算公式和应用范围,具体使用时需要根据问题类型和数据情况进行选择。
六、检验方法
假设检验方法有两种,双侧检验和单侧检验。单侧检验又可分为左侧检验和右侧检验。
如果检验的目的是检验抽样的样本统计量与假设参数的差是否过大(无论正方向,还是负方向) ,我们都会把风险分摊到左右两侧。比如显著性水平为5%,则概率曲线的左右两侧各占2.5%,也就是95%的置信区间。
双侧检验的备择假设没有特定的方向性,通常的形式为“丰”,这种检验假设被称为双侧检验。
如果检验的目的只是注重验证是否偏高,或者偏低,也就是说只注重验证单一方向,我们就检验单侧。比如显著性水平为5%,概率曲线只需要关注某一侧占5%即可,即90%的置信区间。
单侧检验的备择假设带有特定的方向性,通常的形式为">“或”<“的假设检验,一般来说单侧检验”<“被称为左侧检验,而单侧检验”>"被称为右侧检验。
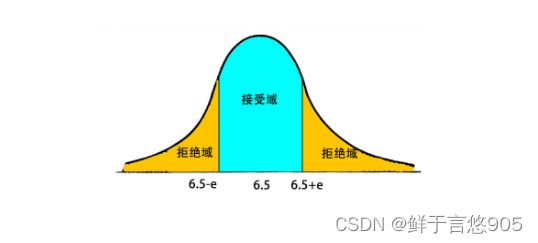
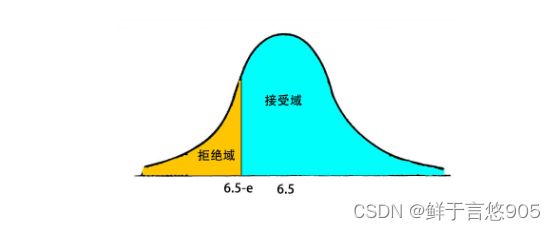
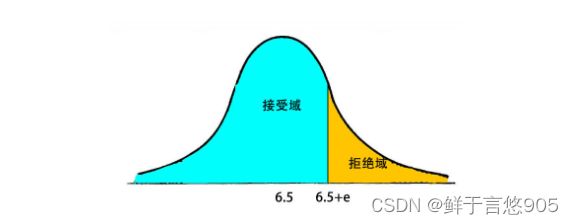
在实践中,我们会根据问题的性质来决定使用双侧检验和单侧检验。比如,为了检验中学生男女生身高是否有性别差异。如果问题是在中学生中,男女生的身高是否存在性别差异,这个时候我们需要用双侧检验,因为实际的差异可能是男生平均身高比女生高,也可能是男生平均比女生矮。这两种情况都属于存在性别差异。
而如果问题变为在中学生中,男生的身高是否比女生高,这个时候我们只需要检验单侧即可。
七、拒绝域
在假设检验中,用来拒绝原假设的统计量的取值范围,拒绝域是由显著性水平围成的区域。拒绝域的功能主要用来判断假设检验是否拒绝原假设的。如果通过样本数据计算出来的检验统计量的具体数值落在拒绝域内,就拒绝原假设,否则不拒绝原假设。给定显著性水平a后,查表就可以得到具体临界值,将检验统计量与临界值进行比较,判断是否拒绝原假设。
八、假设检验步骤
假设检验首先需要对问题做出假设,对照样本数据进行检验,主要分为以下基本步骤。
- 步骤一:提出原假设(HO)与备择假设(H1)
- 步骤二:从总体中出抽取一个随机样本
- 步骤三:构造检验统计量
- 步骤四:根据显著性水平确定拒绝域临界值
- 步骤五:计算检验统计量与临界值进行比较
九、重要假设检验方法
1. z检验
z检验是有关总体平均值参数的假设检验,检验是一般用于大样本,即样本容量大于30,总体的方差已知的方法。它是用标准正态分布的理论来推断差异发生的概率,从而比较样本平均数和总体均值的差异是否显著。
z检验首先比较根据样本计算所得z值与理论z值之间关系,推断发生的概率,依据z值与差异显著性关系表作出判断。比如,在显著性水平a=0.05的情况下,通过查表获得理论z值=1.96,如果计算所得z值大于1.96,则拒绝原假设。
例:一种零配件,要求使用寿命不低于1000小时,现从一批这种零配件中抽
取25件,测得其使用寿命的平均值为950小时,已知该零配件服从标准差S=100小时的正态分布,在显著性水平a=0.05下确定这批零配件是否合格。
解:使用寿命小于1000小时即为不合格,我们可以使用左单侧检验,这时我们有:
原假设HO:μ>1000;备选假设:H1<1000
计算统计量:

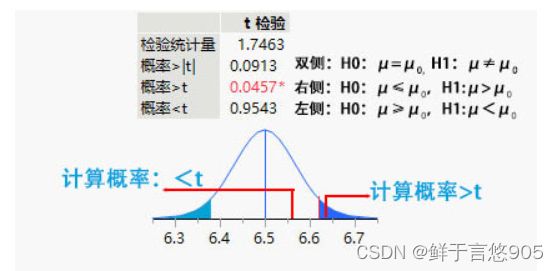
而在显著性水平a=0.05下的真值为Z=-1.65,由于z=-2.5 t检验是在总体方差未知的情况下有关总体均值参数的假设检验,主要用于样本含量较小(n<30),总体标准差σ未知的正态分布。目的是用来比较样本均值所代表的未知总体均值和已知总体均数。 F检验是对两个正态分布的方差齐性检验,简单来说,就是检验两个分布的方 根据卡方统计量的定义,卡方值描述两个事件的独立性或者描述实际观察值与期望值的偏离程度。卡方值越大,表名实际观察值与期望值偏离越大,也说明两个事件的相互独立性越弱。卡方检验属于非参数检验,主要是比较两个变量的关联性分析。根本思想在于比较观测值和理论值的拟合程度。原假设认为观测值与理论值的差异是由于随机误差所致。2. t检验
我们可以将原假设假设为样本均值与总体均值之间没有显著差异。然后,在给定理论值差异的显著水平下,比如选择 a=0.05,根据自由度n-1,查T值表,找出对应的T理论值。
根据样本数据计算t统计量的t值,比较计算得到的t值和理论T值,推断发生的概率,如果t值大于T值,作出原假设不成立的判断。3. F检验
差是否相等接下来我们讨论F检验,最典型的F检验是用于分析一系列服从正态分布总体的样本是否都有相同的标准差。具体来说,对于正态总体,两个总体的方差比较可以用F-分布来检验。

检验结果说明甲乙两人检测结果差别不显著。4 .卡方检验
确定数据间的实际差异,即求出卡方值,如卡方值大于某特定显著性标准,则拒绝原假设,认为实测值与理论值的差异在该显著水平下是显著的。
利用卡方分布进行假设检验的基本步骤。