下一个 OpenAI?大模型在这一方面做到了世界第一
来源:机器之心
虽然我们不知道谁是下一个 OpenAI,但是似乎找到了另一个 Anthropic。
最近,大模型创投领域又发生了一件大事:大模型初创公司 Anthropic 获得了亚马逊 40 亿美元的融资。该笔融资几天后,又有消息传出,谷歌等也要向这家公司再投 20 亿美元。听到这些消息,不少人可能会问,这家公司有何过人之处?别急,我们来问一下新必应。
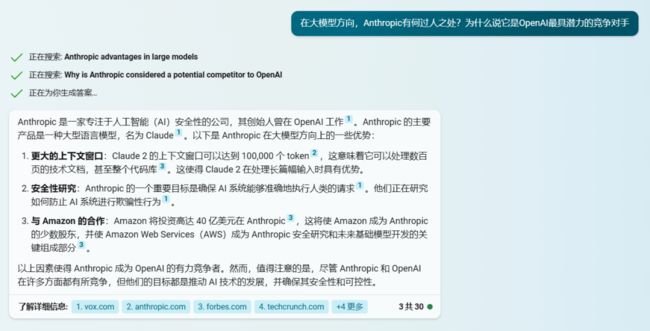
新必应的答案显示,在大模型方向上,除了一支优秀的团队,Anthropic 在技术上也非常领先,尤其在大模型支持的上下文窗口方面。
上下文窗口有多重要?回想一下使用 ChatGPT 处理长文的经历,你是不是也经常收到「文本过长」的提示?这是因为 ChatGPT 至多只支持 32k tokens(约 2.5 万汉字)的上下文。这一限制让很多行业的从业人员都很头疼,尤其是律师、分析师、咨询师、prompt 工程师等需要分析、处理较长文本的工作。

此外, token 数量的限制还会导致模型「忘记」之前对话的重要信息,或者加重模型「幻觉」,就像 Character.AI 等聊天 AI 产品的用户所抱怨的那样。

为了解决这些问题,Anthropic 在其产品 Claude 2.0 中提供了 100k tokens(实测约 8 万汉字)的上下文窗口,大大扩展了其产品的应用空间。
那么,如果这个窗口再大一点呢?
这是国内大模型初创公司 Moonshot AI 推出的大模型智能助手 Kimi Chat,拥有超长的上下文窗口。在动图展示的例子中,Kimi Chat 接收到的上下文达到了 15 万字,而实测中我们发现,它甚至能一次处理 20 万字,大约是 Claude 2.0 中文上下文窗口的 2.5 倍,是全球市场上能够产品化使用的大模型服务中所能支持的最长上下文输入长度。GPT-4 等英文为基础的模型产品需要做到接近 250k tokens 才能获得与 Kimi Chat 同等的汉字上下文窗口。
那么,这么大的上下文窗口用起来是一种怎样的体验?Moonshot AI 是怎么做到这一点的?在该功能开放内测之际,机器之心在第一时间拿到了内测资格并进行了测评,同时也和 Moonshot AI 的技术团队聊了一些技术细节以及他们对该技术的思考,希望能给国内关注大模型技术与应用的读者一些启发。
原来,不用担心文本过长是这种感觉
打开「KIMI」的测试页面,我们可以看到,它有一个简单的对话框,对话框的右侧有几个按钮,分别是网络开关和文件上传按钮。这意味着,KIMI 不仅能分析我们提供的资料,还能在必要时自己上网查找,看起来非常靠谱。

既然 KIMI 的强项是处理长文本,那我们就选一些长文本的场景来测试一下。第一份材料是《中华人民共和国刑事诉讼法》和《最高法关于适用〈中华人民共和国刑事诉讼法〉的解释》组合起来的一份 word 材料,篇幅超过 12 万字,一般的大语言模型都无法处理。在询问了几个比较具体的问题后,我们发现,KIMI 能够根据材料回答大部分问题,并给出答案依据:
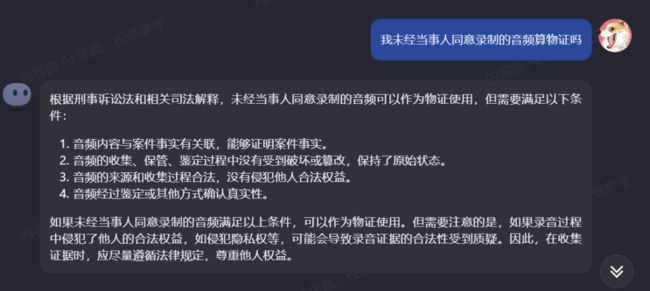
如果问题超出了材料所给的范围,它会自己上网检索相关内容,并归纳出答案,这是一种跨文档的文本处理能力。

值得注意的是,KIMI 在回答一些比较综合的问题时会结合多个法条,并在消化了这些条款内容的前提下,用自己的语言重新组织逻辑清晰的答案。

这种贯穿全文的强大理解能力在小说的测试中表现得更为明显。这里我们选取的是科幻小说《三体 1》,虽然小说有 20 万字,但 KIMI 能把它全部读下来,并梳理人物故事线等信息:

当我们问及小说后半部分的内容以及需要结合上下文理解的某些概念的引申含义时,KIMI 回答起来也毫无压力:


既然 KIMI 展现出了如此强大的上下文记忆能力,那多轮对话想必也能轻松应对。于是,在另一项测试中,我们选取了《原神》人物胡桃的百科信息,让 KIMI 在掌握胡桃全部信息的基础上模仿后者与我们对话,就像科幻作品里的「数字生命」一样。当前大多数角色扮演类 AI 是消化不了这么多角色背景信息的,因此聊天过程中很容易让人丧失沉浸感。
基于大模型设计的文字游戏玩家抱怨角色设定信息少,输出缺乏逻辑性。
同样的,我们也用《三体》试了一下,让 KIMI 模仿大史说话,效果也非常不错:

重要的是,这种基于长文本的多轮对话能力在科研、教育等场景中也非常实用,比如它可以解读最近很火的微软 GPT-4V 使用体验论文:
几轮体验下来,可以明显感觉到,当上下文窗口扩展到 20 万字,我们能用大模型做的事情突然就多了很多。由于大部分文本材料都不会超过这个数字,我们终于不用再去一个一个检查字数,也不用担心和模型聊多了话题戛然而止。这是一种非常流畅的体验,也让人有信心去探索更多使用场景。
超长上下文窗口,实现起来有多难?
既然扩大上下文窗口如此有效,那为什么市面上现有的各路大模型大多还局限在 32k 或以下的 token 长度呢?这是因为,实现模型对超长上下文的处理在训练算法和工程实现上都面临着艰巨的挑战。
首先,从训练层面来看,想得到一个支持足够长上下文长度的模型,不可避免地要面对如下困难:
如何让模型能在数十万 tokens 的上下文窗口中,准确地关注到所需要的内容?
如何让模型在适应长文本工作方式时,不降低其原有的基础能力?
由超长上下文窗口带来的更高的算力需求和极严重的显存压力,如何在传统的 3D 并行方案之外寻找到更多的并行空间?
缺乏充足的高质量长序列数据,如何提供更多的有效数据给模型训练?
从推理层面来看,在获得了支持超长上下文的模型后,如何让模型能服务众多用户,同样要面临一番挑战:
一是 Transformer 模型中自注意力机制的计算量会随着上下文长度的增加呈平方级增长,比如上下文增加 32 倍时,计算量实际会增长 1000 倍,这会导致用户需要等待极长的时间才能获得反馈;
二是长下上文推理需要的显存容量巨大:以 1750 亿参数的 GPT-3 为例(GPT-4、Claude 等模型参数量未知,故无法估算),目前最高单机配置 (80 GiB * 8) 最多只能支持 64k 上下文长度的推理,超长文本对显存的要求可见一斑;
三是目前的显存带宽无法满足需求:英伟达 A800 或 H800 的显存带宽高达 2-3 TiB/s,但面对如此长的上下文,若只通过一些朴素的基本处理方法,生成速度只能达到 2~5 token/s,使用的体验极其卡顿。

当然,上述问题的解决存在一些「捷径」,但这些捷径往往都是以牺牲模型性能为代价的,导致模型的应用价值大打折扣, 典型的做法包括:
首先,最容易想到的就是把模型做小,通过把参数减少到百亿来提升上下文长度。但模型小了之后,能力也会显著下降,大量任务都无法胜任,就像未发育完全的蝌蚪。
其次,你可以让模型「问哪儿看哪儿」,就像只能在特定花蕊上采蜜的蜜蜂,无法关注到整体信息。这通常是通过对上下文的降采样或者 RAG(检索增强生成)方法来实现的,让模型只关注和问题直接相关的部分,减少计算量。但如此一来,模型就无法回答那些需要基于全文理解来回答的问题(例如从 50 个简历中对候选人的画像进行归纳和总结),能力大打折扣。
最后,你还可以让模型「边看边忘」,只让它记住最新的输入,就像只有 7 秒钟记忆的金鱼一样。但很明显,这种方法也做不到理解全文,尤其是跨文档的长文本的综合理解(比如从一篇 10 万字的用户访谈录音转写中提取最有价值的 10 个观点)。
总之,这些所谓的捷径都无法达到理想的产品化效果。为了让模型真正解决问题,从好技术变成好产品,Moonshot AI 选择直面挑战,从多个角度去解决长上下文窗口的技术难题。
在模型训练方面,业界已经有不少通过相对位置编码外推来低成本地实现超长上下文的模型,在各项 benchmark 中分数也非常高,但 Moonshot AI 发现,这类模型在实际的工作场景中并不能达到预期的效果。因此 Moonshot AI 选择直面困难,逐一解决上述问题。
总体来看,他们从如下几个大方向入手来改善训练中遇到的问题:
在传统的 Tensor 并行、Data 并行、Pipeline 并行基础上,增加了多项基于 Seqence 维度的并行策略,提升了并行效率;
利用定制版的 Flash Attention、Fuse Cross Entropy、CPU offload 等技术大幅度降低了显存压力;
使用了创新的训练方法,针对性地调配了多阶段式训练方法,让模型保留基础能力的前提下,逐步激活长上下文的能力。
当然,模型训练是一项外科手术般精密的工作,每一个细节都不能出差错。因此,除了上述几个大方向外,Moonshot AI 还在算法稳定性、显存占用、数据分布等方面进行了上百项优化。在强大的工程和算法能力加持下,他们最终让直接训练超长上下文模型成为可能。
模型有了,接下来还要优化推理成本,以保证大量用户都能高效、低成本地使用模型。为此,Moonshot AI 探索了诸多方案,比如:
用 GQA 替换 MHA:让 KVCache 所占用的显存大小大幅度缩小
Paged attention:保证显存的充分利用;
低比特量化:通过 W8A8,至多可以把推理速度在上述基础上再提升一倍;
MoE & KVCache 裁减:让显存占用在上述基础上再下降一倍;
此外,Moonshot AI 通过极高的工程代码质量,将所有的 overhead 降到最低,使得代码性能不断逼近理论上限,从而构筑了高效推理的基础。
通过组合这些关键技术,Moonshot AI 在超长文本下依然可以让大量用户同时获得良好的使用体验,并且拥有了在文本长度和推理速度间灵活权衡的空间,其极限可处理的上下文长度上限更是可以达到 150 万字以上,相当于可以一次让模型处理《三国演义》加《西游记》两本名著。
大模型能力的二元性:为什么要死磕「长上下文窗口」?
今年年初,在 GPT-4 问世之前,一个号称「GPT-4 有 100 万亿个参数」的谣言引发了不少关注。在无数次被转发后,很多人信以为真,导致 OpenAI 首席执行官 Sam Altman 不得不亲自出来辟谣。这也在一定程度上反映了大模型领域对于参数量的一种「崇拜」。
诚然,参数量对于大模型的能力高低十分重要,是大模型出现「涌现」现象的一道门槛。但除此之外呢?还有哪些方向没有得到足够的重视?在 Moonshot AI 看来,长上下文窗口就是其中之一。
我们知道,在传统计算中有两个核心原则:计算是按照顺序逐步进行的;每一步都有有限的复杂度容量。大型语言模型可以被看作是进化了的计算实体,所以 Moonshot AI 认为大模型能够达到的最高水平由两个因素决定:单步骤的容量(即模型在每一步中可以处理的信息量,对应参数量)和执行的步骤数(即模型能够处理的上下文长度)。
目前,大部分大模型研究都集中在增加模型参数量的大小,即增强「单步骤容量」。但 Moonshot AI 认为,在保持一定参数量的同时放大另一个维度,即「步骤数」或上下文长度也同样重要。就像我们在实测中所看到的,上下文窗口就像大模型应用的新「内存」,窗口越大,用户能用它做的事情就越广泛;同时,窗口所能容纳的信息越多,模型在生成下一个 token 时可以参考的信息就越多,「幻觉」发生的可能性就越小,生成的信息就越准确。这是大模型技术落地的必要条件。
不过,更为重要的是,Moonshot AI 已经看到,超长上下文窗口其实是大模型技术未来发展的必由之路。
如今,以 OpenAI 为代表,几乎所有的头部大模型企业都会走多模态技术道路,因为人类文明的总和不止以文字的形式存在硬盘上,还隐藏于海量的语音、图像、视频等数据形态中。Moonshot AI 创始人杨植麟曾提到,他们相信对海量数据的无损压缩可以实现高程度的智能。而无损压缩等同于对数据联合概率分布的预测,这就找到了与多模态数据生成的契合点,多模态数据的生成本质上也是在做数据的联合概率分布预测,所以超长上下文窗口技术对实现多模态至关重要,是一个必须解决的技术问题。
大模型「登月计划」第一步:欢迎来到 Long LLM 时代
能选出一个有前景的方向是一回事,能不能做成又是另外一回事,毕竟超长上下文窗口打造起来并非易事,需要非常强的算法和工程能力。对此,杨植麟采取了和 Anthropic 类似的策略:提高人才密度。
目前,Moonshot AI 的整个团队人数超过了 60 人,这些人绝大部分都是拥有世界级影响力工作的大模型专家,比如杨植麟本人提出的 Transformer-XL 是历史上第一个在词级别和字级别都全面超越 RNN 的注意力语言模型,解决了语言建模上下文长度的关键问题,定义了语言建模的新标准;两位联合创始人 —— 周昕宇和吴育昕 —— 有着五位数的 Google Scholar 引用,在大模型方面有非常丰富的工程和算法经验。还有一些核心成员参与了 Google Gemini、Bard、盘古、悟道等多个大模型的开发。在这些人的共同努力下,Moonshot AI 仅用半年时间就打造出了一款世界领先的产品。
这款产品的诞生是有标志性意义的,20 万字以及更长的上下文窗口足以把使用大模型工作的你我从 LLM 时代带入 L(Long)LLM 时代。在这个时代,我们可以拥有一个能记住与你所有交互细节的虚拟伴侣;可以将日常工作中的冗长文件(如合同、研报、财务报告等)都丢给大模型来处理;还可以针对某个科学问题, 将跨领域的相关学术论文作为上下文,利用大模型寻求解决问题的新思路…… 可以说,上下文窗口越大,大模型留给用户的创新空间就越大。
至少日常处理发票这种工作就不会浪费时间了
此外,Moonshot AI 表示,本次推出的超长上下文产品对于他们来说仅仅是一个起点。随着对应用场景挖掘的逐渐深入以及相应技术的优化,他们很快就会开放支持更长上下文以及拥有其他能力的模型。
如果你也想体验 Kimi Chat 的长文本能力,可以点击以下链接,申请加入内测计划:https://www.moonshot.cn/
推荐阅读
西电IEEE Fellow团队出品!最新《Transformer视觉表征学习全面综述》
润了!大龄码农从北京到荷兰的躺平生活(文末有福利哟!)
如何做好科研?这份《科研阅读、写作与报告》PPT,手把手教你做科研
奖金675万!3位科学家,斩获“中国诺贝尔奖”!
又一名视觉大牛从大厂离开!阿里达摩院 XR 实验室负责人谭平离职
最新 2022「深度学习视觉注意力 」研究概述,包括50种注意力机制和方法!
【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载!
2021李宏毅老师最新40节机器学习课程!附课件+视频资料
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

长按识别,邀请您进群!