Ray 分布式简单教程(1)
1.概览
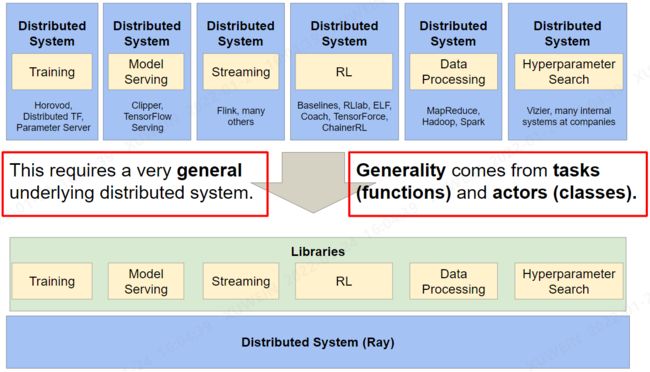
Ray为构建分布式应用程序提供了一个简单、通用的API。
Ray主要作用就是提供一个调度平台,能够将各个分布式集群以及远程云端的服务器资源调度管理,只需稍加改动,就能将单机运行的代码部署到大规模集群上。
在Ray Core上有几个库,用于解决机器学习中的问题:
Tune:可伸缩的超参数调优RLlib:工业级强化学习Ray Train:分布式深度学习Datasets:分布式数据加载和计算(beta)
以及用于将 ML 和分布式应用程序投入生产的库:Serve:可扩展和可编程的服务Workflows:快速、持久的应用程序流程(alpha)
还有许多与 Ray 的社区集成,包括 Dask、MARS、Modin、Horovod、Hugging Face、Scikit-learn 等。
2.社区集成
此页面列出了与 Ray 集成以进行分布式执行的库。
2.1 Airflow
Airflow 是一个由社区创建的平台,用于以编程方式创作、安排和监控工作流程。 Airflow/Ray 集成允许 Airflow 用户将所有 Ray 代码保留在 Python 函数中,并通过 Python 函数移动数据来定义任务依赖关系。
2.2 ClassyVision
Classy Vision 是一个新的端到端、基于 PyTorch 的框架,用于对最先进的图像和视频分类模型进行大规模训练。该库采用模块化、灵活的设计,允许任何人在 PyTorch 之上使用非常简单的抽象训练机器学习模型。
2.3 Dask
Dask为分析提供了高级的并行性,为您喜欢的工具提供了大规模的性能。Dask使用现有的Python api和数据结构,使得它可以很容易地在Numpy、Pandas、Scikit-learn和它们的基于Dask的等价对象之间切换。
2.4 Flambe
Flambe 的主要目标是为原型模型、运行包含复杂管道的实验、实时监控这些实验、报告结果以及部署最终模型进行推理提供统一的接口。
2.5 Horovod
Horovod 是一个用于 TensorFlow、Keras、PyTorch 和 Apache MXNet 的分布式深度学习训练框架。 Horovod 的目标是让分布式深度学习变得快速且易于使用。
2.6 Hugging Face Transformers
适用于 Pytorch 和 TensorFlow 2.0 的最先进的自然语言处理。 它与 Ray 集成,用于Transformers模型的分布式超参数调整以及用于检索增强生成模型的分布式文档检索。
2.7 Intel Analytics Zoo
Analytics Zoo 将 TensorFlow、Keras 和 PyTorch 无缝扩展到分布式大数据(使用 Spark、Flink 和 Ray)。
2.8 John Snow Labs’ NLU
1 行 Python 代码就可获得46 种语言的 350 多个预训练 NLP 模型、100 多个词嵌入、50 多个句子嵌入和 50 多个分类器的强大功能。
2.9 Ludwig AI
Ludwig 是一个工具箱,允许用户在无需编写代码的情况下训练和测试深度学习模型。使用 Ludwig,您可以在零行代码中在 Ray 上训练深度学习模型,自动利用 Dask on Ray 进行数据预处理,利用 Horovod on Ray 进行分布式训练,以及 Ray Tune 进行超参数优化。
2.10 MARS
Mars 是一个基于张量的统一框架,用于大规模数据计算,可扩展 Numpy、Pandas 和 Scikit-learn。 Mars 可以扩展到单台机器,也可以扩展到拥有数千台机器的集群。
2.11 Modin
通过更改一行代码来扩展您的 pandas 工作流程。Modin透明地分发数据和计算,所以你所需要做的就是继续使用pandas API,就像你在安装Modin之前一样。
2.12 PyCaret
PyCaret 是 Python 中的一个开源低代码机器学习库,旨在减少假设以洞察机器学习实验中的周期时间。它使数据科学家能够快速有效地执行端到端实验。
2.13 PyTorch Lightning
PyTorch Lightning 是一个流行的开源库,为 PyTorch 提供高级接口。 PyTorch Lightning 的目标是构建您的 PyTorch 代码以抽象训练的细节,使 AI 研究具有可扩展性和快速迭代。
2.14 RayDP
RayDP(“Spark on Ray”)使您能够在 Ray 程序中轻松使用 Spark。您可以使用 Spark 读取输入数据,使用 SQL、Spark DataFrame 或 Pandas(通过 Koalas)API 处理数据,使用 Spark MLLib 提取和转换特征,以及使用 RayDP Estimator API 对预处理数据集进行分布式训练。
2.15 Scikit Learn
Scikit-learn 是 Python 编程语言的免费软件机器学习库。它具有各种分类、回归和聚类算法,包括支持向量机、随机森林、梯度提升、k-means 和 DBSCAN,旨在与 Python 数值和科学库 NumPy 和 SciPy 互操作。
2.16 Seldon Alibi
Alibi 是一个开源 Python 库,旨在机器学习模型检查和解释。该库的重点是为分类和回归模型提供黑盒、白盒、局部和全局解释方法的高质量实现。
2.17 Spacy
spaCy 是 Python 和 Cython 中用于高级自然语言处理的库。它建立在最新研究的基础上,从一开始就设计用于实际产品。
2.18 XGBoost
XGBoost 是一个流行的梯度提升库,用于分类和回归。它是数据科学中最受欢迎的工具之一,也是许多性能最佳的 Kaggle 内核的主力。
2.19LightGBM
LightGBM 是一个用于分类和回归的高性能梯度提升库。它被设计为分布式和高效的。
参考目录
https://docs.ray.io/en/latest/index.html