MySQL 查询分析和调优利器Optimizer Trace
庖丁解牛-图解查询分析和调优利器Optimizer Trace
查询分析和调优背景
在数据库的使用过程,我们经常会碰到SQL突然变慢,是由于下面导致的问题:
- 选择错误的索引
- 选择错误的连接顺序
- 范围查询使用了不同的快速优化策略
- 子查询选择的执行方式变化
- 半连接选择的策略方式变化
如何使用分析工具OPTIMIZER TRACE来理解优化过程和原理来深度分析和调优慢SQL就成为高级DBA的利器。
我们先来了解下查询优化整体的过程:

该过程主要考虑的因素是访问方式、连接顺序和方法已经半连接、子查询的执行策略,主要步骤就是:
- 计算和设置各个算子的代价
- 计算和设置部分或者可代替的执行计划的代价
- 找到最低代价的执行计划
EXPLAIN工具
先来介绍下常用的explain工具。EXPLAIN是用来查询最终执行计划以及可以通过EXPLAIN format=json看到具体的一些cost信息,如对于TPCH Q8的EXPLAIN的展示:
+----+-------------+----------+------------+--------+------------------------------------------------------------------+---------------+---------+-----------------------------+---------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+--------+------------------------------------------------------------------+---------------+---------+-----------------------------+---------+----------+----------------------------------------------------+
| 1 | SIMPLE | region | NULL | ALL | PRIMARY | NULL | NULL | NULL | 5 | 20.00 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | n1 | NULL | ref | PRIMARY,i_n_regionkey | i_n_regionkey | 5 | tpch_1.region.r_regionkey | 5 | 100.00 | Using index |
| 1 | SIMPLE | orders | NULL | ALL | PRIMARY,i_o_custkey,i_o_orderdate | NULL | NULL | NULL | 1488146 | 50.00 | Using where; Using join buffer (Block Nested Loop) |
| 1 | SIMPLE | customer | NULL | eq_ref | PRIMARY,i_c_nationkey | PRIMARY | 4 | tpch_1.orders.o_custkey | 1 | 5.00 | Using where |
| 1 | SIMPLE | lineitem | NULL | ref | PRIMARY,i_l_orderkey,i_l_partkey,i_l_suppkey,i_l_partkey_suppkey | PRIMARY | 4 | tpch_1.orders.o_orderkey | 4 | 100.00 | Using where |
| 1 | SIMPLE | supplier | NULL | eq_ref | PRIMARY,i_s_nationkey | PRIMARY | 4 | tpch_1.lineitem.l_suppkey | 1 | 100.00 | Using where |
| 1 | SIMPLE | n2 | NULL | eq_ref | PRIMARY | PRIMARY | 4 | tpch_1.supplier.s_nationkey | 1 | 100.00 | NULL |
| 1 | SIMPLE | part | NULL | eq_ref | PRIMARY | PRIMARY | 4 | tpch_1.lineitem.l_partkey | 1 | 10.00 | Using where |
+----+-------------+----------+------------+--------+------------------------------------------------------------------+---------------+---------+-----------------------------+---------+----------+----------------------------------------------------+EXPLAIN format=json片段展示:
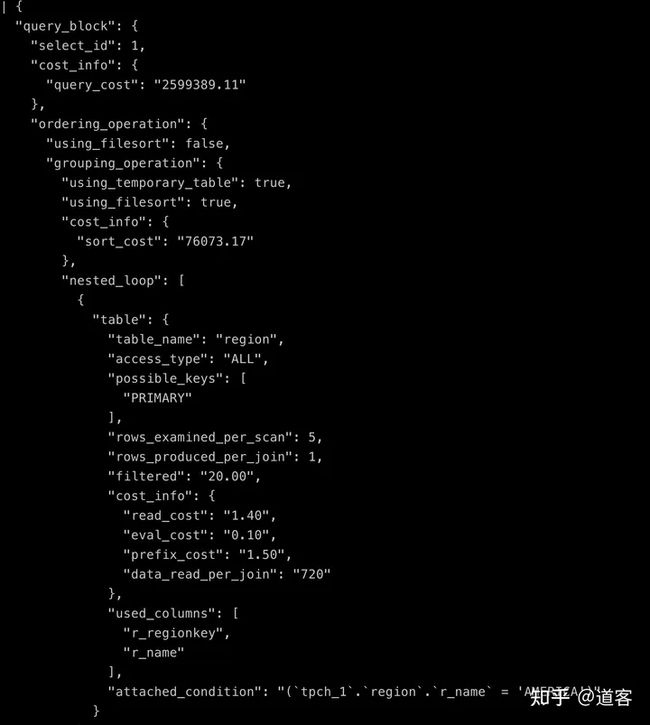
在看EXPLAIN的时候,主要关心的几个字段:
- id是query block的序号,相同的数字代表,table字段的表是在同级query block当中
- select_type通常会指EXPLAIN_PRIMARY、EXPLAIN_SIMPLE、EXPLAIN_DERIVED、EXPLAIN_SUBQUERY、UNION、UNION_RESULT、MATERIALIZED,代表该query block的类型
- table是对应执行计划中的表,也可以是
:对应的派生表,其中N就是select id,可以从explain中找到对应的行 :对应的物化子查询,N是select id
- partitions是支持经过剪枝后的分区列表
- type是指访问的方式,其中包含以下内容值,性能的好坏依次为system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
- system:表仅有一行(=系统表)。这个一般是一个变量值,是const连接类型的一个特例。
- const:表最多的一个匹配行,它将查询开始被读取。因为仅有一行,在这行的列值可被优化器的剩余部分认为是常数。const用于用常数值比较primary key或unique索引的所有部分时。
- eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。eq_ref可以用于使用= 操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。
- ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref。如果使用的键仅仅匹配少量行,该联接类型是不错的。ref可以用于使用=或<=>操作符的带索引的列。
- ref_or_null:该联接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。在解决子查询中经常使用该联接类型的优化。
- index_merge:该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
- unique_subquery:该类型替换了下面形式的IN子查询的ref:value IN (SELECT primary_key FROMsingle_table WHERE some_expr);unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
- index_subquery:该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引:value IN SELECT key_column FROM single_table WHERE some_expr)
- range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range
- index:该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。
- all:对于每个来自于先前的表的行组合,进行完整的表扫描。如果表是第一个没标记const的表,这通常不好,并且通常在它情况下很差。通常可以增加更多的索引而不要使用ALL,使得行能基于前面的表中的常数值或列值被检索出。
- extra字段内容更多,包括是否使用临时表(Using temporary)、是否使用文件排序(Using filesort)、是否使用WHERE过滤(Using where)还是索引条件下推(Using index condition)、是否使用连接缓冲区(Using join buffer),是否告知没有符合条件的行(Impossible where)、或者使用索引覆盖(Using index)等,因为本文重点在optimizer trace上,这里就不再一一详细解释了。
最新的8.0.18版本中,又增加了format=tree,更好的看到新的iterator的执行过程,如下:
| -> Sort: all_nations.o_year -> Table scan on
-> Aggregate using temporary table
-> Nested loop inner join (cost=9.91 rows=1)
-> Nested loop inner join (cost=8.81 rows=1)
-> Nested loop inner join (cost=7.71 rows=1)
-> Nested loop inner join (cost=6.61 rows=1)
-> Nested loop inner join (cost=5.51 rows=1)
-> Nested loop inner join (cost=4.41 rows=1)
-> Nested loop inner join (cost=3.31 rows=1)
-> Filter: (orders.o_custkey is not null) (cost=2.21 rows=1)
-> Index range scan on orders using i_o_orderdate, with index condition: (orders.o_orderDATE between DATE'1995-01-01' and DATE'1996-12-31') (cost=2.21 rows=1)
-> Filter: (customer.c_nationkey is not null) (cost=1.10 rows=1)
-> Single-row index lookup on customer using PRIMARY (c_custkey=orders.o_custkey) (cost=1.10 rows=1)
-> Filter: (n1.n_regionkey is not null) (cost=1.10 rows=1)
-> Single-row index lookup on n1 using PRIMARY (n_nationkey=customer.c_nationkey) (cost=1.10 rows=1)
-> Filter: (region.r_name = 'AMERICA') (cost=1.10 rows=1)
-> Single-row index lookup on region using PRIMARY (r_regionkey=n1.n_regionkey) (cost=1.10 rows=1)
-> Filter: ((lineitem.l_suppkey is not null) and (lineitem.l_partkey is not null)) (cost=1.10 rows=1)
-> Index lookup on lineitem using PRIMARY (l_orderkey=orders.o_orderkey) (cost=1.10 rows=1)
-> Filter: (supplier.s_nationkey is not null) (cost=1.10 rows=1)
-> Single-row index lookup on supplier using PRIMARY (s_suppkey=lineitem.l_suppkey) (cost=1.10 rows=1)
-> Single-row index lookup on n2 using PRIMARY (n_nationkey=supplier.s_nationkey) (cost=1.10 rows=1)
-> Filter: (part.p_type = 'ECONOMY ANODIZED STEEL') (cost=1.10 rows=1)
-> Single-row index lookup on part using PRIMARY (p_partkey=lineitem.l_partkey) (cost=1.10 rows=1)
| EXPLAIN展示的是最终执行计划是什么样子,使用它可以分析出是否需要创建新的索引,或者对比之前的执行计划来确定是否有变化导致的性能问题,但无法更深入的知道优化器是怎么从众多的可以使用的方法中选取的最终计划。
OPTIMIZER TRACE
EXPLAIN展示了选择的结果,那么对于非常想知道为什么这样执行的DBA来说,OPTIMIZER TRACE就是为了来展示为什么这个执行计划被访问了
如何生成OPTIMIZER TRACE
SET optimizer_trace = "enabled=on";
SET optimizer_trace_max_mem_size=655350;
SELECT trace FROM information_schema.optimizer_trace
INTO OUTFILE LINES TERMINATED BY '';
# 或者
SELECT trace FROM information_schema.optimizer_trace \G
SET optimizer_trace ="enabled=off"; 举例说明:
test:tpch_1> SELECT * FROM information_schema.`OPTIMIZER_TRACE`\G
*************************** 1. row ***************************
QUERY: select o_year, sum(case when nation = 'BRAZIL' then volume else 0 end) / sum(volume) as mkt_share from
( select extract(year from o_orderdate) as o_year, l_extendedprice * (1 - l_discount) as volume, n2.n_
name as nation from part, supplier, lineitem, orders, custom
er, nation n1, nation n2, region where p_partkey = l_partkey
and s_suppkey = l_suppkey and l_orderkey = o_orderkey and o_custkey = c_custkey and c_nationkey = n1.n_nationkey
and n1.n_regionkey = r_regionkey and r_name = 'AMERICA' and s_nationkey = n2.n_nationkey and o_orderdate betwe
en date '1995-01-01' and date '1996-12-31' and p_type = 'ECONOMY ANODIZED STEEL' ) as all_nations group by o_year order by o_year
TRACE: {
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"join_preparation": {
"select#": 2,
"steps": [
{
"expanded_query": "/* select#2 */ select extract(year from `orders`.`o_orderDATE`) AS `o_year`,(`lineitem`.`l_extendedprice` * (1 - `lineitem`.`l_discount`)) AS `volume`,`n2`.`n_
name` AS `nation` from `part` join `supplier` join `lineitem` join `orders` join `customer` join `nation` `n1` join `nation` `n2` join `region` where ((`part`.`p_partkey` = `lineitem`.`l_partkey`)
and (`supplier`.`s_suppkey` = `lineitem`.`l_suppkey`) and (`lineitem`.`l_orderkey` = `orders`.`o_orderkey`) and (`orders`.`o_custkey` = `customer`.`c_custkey`) and (`customer`.`c_nationkey` = `n1
`.`n_nationkey`) and (`n1`.`n_regionkey` = `region`.`r_regionkey`) and (`region`.`r_name` = 'AMERICA') and (`supplier`.`s_nationkey` = `n2`.`n_nationkey`) and (`orders`.`o_orderDATE` between DATE'
1995-01-01' and DATE'1996-12-31') and (`part`.`p_type` = 'ECONOMY ANODIZED STEEL'))"
}
]
}
},
{
"derived": {
"table": "``.`` `all_nations`",
"select#": 2,
"merged": true
}
},
......
MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 801464
INSUFFICIENT_PRIVILEGES: 0
1 row in set (0.10 sec)由于优化过程可能会输出很多,如果超过某个限制时,多余的文本将不会被显示,这个字段展示了被忽略的文本字节数,MISSING_BYTES_BEYOND_MAX_MEM_SIZE不为0意味着,说明Trace被截断了,需要重新设置更大的值,optimizer_trace_max_mem_size,比如1000000>801464。
也可以用JSON浏览器插件展示Trace,更为直观

OPTIMIZER TRACE的结构分为三类:

OPTIMIZER TRACE分析
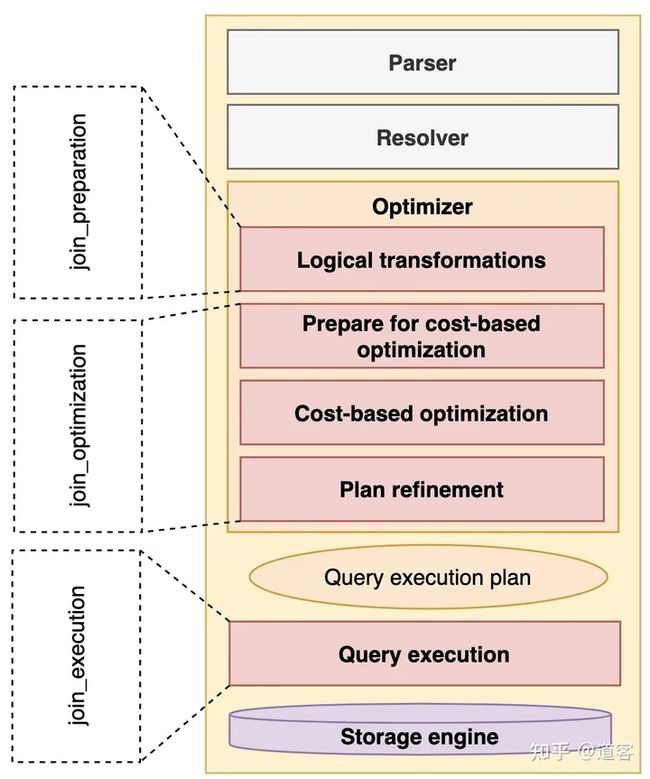
Optimizer trace是跟踪优化器和执行器的整体过程的,如图所示为优化器整体的流程图和trace采集的范围
join_preparation阶段展示
我们可以知道在SQL的preparation阶段,主要是做语义解析、语法检测、永久性的基于规则的转换包括转换外连接成内连接、合并视图或者派生表和一些子查询转换,详细可以查看《庖丁解牛-图解MySQL 8.0优化器查询解析篇》和《庖丁解牛-图解MySQL 8.0优化器查询转换篇》。下面我们就来观察下几个典型的转换过程在trace中的体现。
Derived Merge规则转换
{
"derived": {
"table": "``.`` `all_nations`",
"select#": 2,
"merged": true
}
},转换外连接变成内连接规则集合outer_join_to_inner_join、JOIN_condition_to_WHERE和parenthesis_removal
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `orders`.`o_orderkey` AS `o_orderkey` from (`orders` left join `lineitem` on((`order
s`.`o_orderkey` = `lineitem`.`l_orderkey`))) where (`lineitem`.`l_discount` > 0.10)"
},
{
"transformations_to_nested_joins": {
"transformations": [
"outer_join_to_inner_join",
"JOIN_condition_to_WHERE",
"parenthesis_removal"
],
"expanded_query": "/* select#1 */ select `orders`.`o_orderkey` AS `o_orderkey` from `orders` join `lineitem` where ((`linei
tem`.`l_discount` > 0.10) and (`orders`.`o_orderkey` = `lineitem`.`l_orderkey`))"
}
}
]
}在8.0.16中,转换EXISTS子查询到IN子查询规则:
SELECT o_orderpriority, COUNT(*) AS order_count FROM orders WHERE EXISTS (SELECT * FROM lineitem WHERE l_orderkey =
o_orderkey AND l_commitdate < l_receiptdate) GROUP BY o_orderpriority ORDER BY o_orderpriority;
{ [642/44613]
"transformation": {
"select#": 2,
"from": "IN (SELECT)",
"to": "semijoin",
"chosen": true,
"transformation_to_semi_join": {
"subquery_predicate": "exists(/* select#2 */ select 1 from `lineitem` where ((`lineitem`.`l_orderkey` = `orders`.`o_order
key`) and (`lineitem`.`l_commitDATE` < `lineitem`.`l_receiptDATE`)))",
"embedded in": "WHERE",
"evaluating_constant_semijoin_conditions": [
],
"semi-join condition": "((`lineitem`.`l_commitDATE` < `lineitem`.`l_receiptDATE`) and (`orders`.`o_orderkey` = `lineitem`
.`l_orderkey`))",
"decorrelated_predicates": [
{
"outer": "`orders`.`o_orderkey`",
"inner": "`lineitem`.`l_orderkey`"
}
]
}
}
},
{
"transformations_to_nested_joins": {
"transformations": [
"semijoin"
],
"expanded_query": "/* select#1 */ select `orders`.`o_orderpriority` AS `o_orderpriority`,count(0) AS `order_count` from `o
rders` semi join (`lineitem`) where ((`lineitem`.`l_commitDATE` < `lineitem`.`l_receiptDATE`) and (`orders`.`o_orderkey` = `lineitem`.`l_orderkey`)) group by `orders`.`o_orderpriority` order by `orders`.`o_orderpriority`" }
}join_optimization展示
该阶段除了做一些prepare后续的逻辑转换之外,主要展示了优化器基于cost的优化过程,包括访问方式、连接方法和顺序,以及一些针对执行计划的特定优化。不过也会解决一些遗留的一些逻辑转换规则,如NOT消除、等值传递、常量计算和条件移除。

可以看到trace如下:
{ [174/44947]
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "((`t1`.`a` = `t2`.`a`) and (`t2`.`a` = 9) and (((`t1`.`a` <= 10) and (`t2`.`b` <= 3)) or ((`t1`.`b`
= (`t2`.`b` + 7)) and (`t2`.`b` = 5))))",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "((((9 <= 10) and (`t2`.`b` <= 3)) or ((`t1`.`b` = (5 + 7)) and multiple equal(5, `t2`.`b`))) a
nd multiple equal(9, `t1`.`a`, `t2`.`a`))"
},
{
"transformation": "constant_propagation",
"resulting_condition": "((((9 <= 10) and (`t2`.`b` <= 3)) or ((`t1`.`b` = 12) and multiple equal(5, `t2`.`b`))) and mu
ltiple equal(9, `t1`.`a`, `t2`.`a`))"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(((`t2`.`b` <= 3) or ((`t1`.`b` = 12) and multiple equal(5, `t2`.`b`))) and multiple equal(9,
`t1`.`a`, `t2`.`a`))"
}
]
}
},下面我们来用trace解开基于代价访问的神秘面纱,也就是访问方式、连接方法和顺序、是否使用连接缓冲区和子查询策略等等。
表访问方式选择
首先进行表访问方式的代价估算,主要分为Table Scan(全表扫描)、Index Look Up (ref访问)方式、Index Scan(索引扫描),Range Index Scan(索引范围查询)和一些替代的Quick Range Scan(快速范围访问方式)。每一种分类是可以独立计算选出最佳方案,最终在所有类型的最佳方案中选择代价最低的访问方式。
- 分析表之间的依赖关系
- table:涉及的表名,如果有别名,也会展示出来
- row_may_be_null:行是否可能为NULL,这里是指JOIN操作之后,这张表里的数据是不是可能为NULL。如果语句中使用了LEFT JOIN,则后一张表的row_may_be_null会显示为true
- map_bit:表的映射编号,从0开始递增
- depends_on_map_bits:依赖的映射表。主要是当使用STRAIGHT_JOIN强行控制连接顺序或者LEFT JOIN/RIGHT JOIN有顺序差别时,会在depends_on_map_bits中展示前置表的map_bit值。
{
"table_dependencies": [
{
"table": "`part`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": []
},
{
"table": "`supplier`",
"row_may_be_null": false,
"map_bit": 1,
"depends_on_map_bits": []
},
......
]
},- 列出所有可用的ref类型的索引
优化器先通过ref_optimizer_key_uses步骤查看SQL中每个表可以使用的ref索引,用于后续计算访问和连接代价。ref是必须为等值比较的方式,通常在单表条件和多表连接的条件中。
{
"ref_optimizer_key_uses": [
{
"table": "`part`",
"field": "p_partkey",
"equals": "`lineitem`.`l_partkey`",
"null_rejecting": true
},
{
"table": "`supplier`",
"field": "s_suppkey",
"equals": "`lineitem`.`l_suppkey`",
"null_rejecting": true
},
......
{
"table": "`region`",
"field": "r_regionkey",
"equals": "`n1`.`n_regionkey`",
"null_rejecting": true
}
]
},接下来遍历每个表进行访问方式代价评估
- 全表扫描的代价评估

{
"table": "`orders`",
"range_analysis": {
"table_scan": {
"rows": 1488146,
"cost": 151868,
"in_memory": 1
},
......in_memory是xxx版本新增的参数,用来计算访问的数据page不在内存而在磁盘,由于IO访问造成的代价,1指的是数据都在内存中。
- 覆盖索引扫描估算
best_covering_index_scan:如果有覆盖索引,列出覆盖索引情况
select max(l_shipdate), sum(l_shipdate) from lineitem where l_shipdate <= date '1998-12-01' - interval '90' day;
"range_analysis": {
"table_scan": {
"rows": 1497730,
"cost": 150488
},
......
"best_covering_index_scan": {
"index": "i_l_shipdate",
"cost": 151967,
"chosen": false,
"cause": "cost"
},可以清晰看出来及时有覆盖索引,由于过滤性不强导致全表扫描方式代价和覆盖索引代价相近,而选择全表扫描。
- 范围索引扫描和快速索引扫描方式的评估和选优
可以很清楚的看到首先先列出该表可以使用RANGE扫描的key索引列表(potential_range_indexes),这里直接会判定是否所以可以被考虑,"usable"代表是否可能被用到,"cause"代表被拒绝的原因。
接下来就开始查看是否有快速范围查找的方式(Quick Range Scan),如group_index_range和skip_scan_range等,"chosen"代表是否该快速访问方式被使用,"cause"是被拒绝的原因。这里看到举例的SQL,都是因为不是单表(not_single_table)而被拒绝使用该规则。如果可以使用,还有被拒绝的原因是cost代价原因。
SELECT a, b FROM t1 GROUP BY a, b;
SELECT DISTINCT a, b FROM t1;
SELECT a, MIN(b) FROM t1 GROUP BY a;
这时候我们已经根据cost选出了一个最佳的访问方式(Table Scan vs Quick Range Scan),接下来我们就看继续单独查看范围索引(Index Range Scan)是否有最有的方案,这些可能的选择都放在range_scan_alternatives中,我们可以看到具体使用的索引、索引估算代价的来源(dive、statistics、histogram等)是否使用一些特殊的优化模式(rowid_ordered、using_mrr、index_only),已经该索引内存占用的比例。"chosen"代表是否该快速访问方式被使用,"cause"是被拒绝的原因,我们通常都会看到由于cost被剪枝掉。

之前我们都是针对一个索引去估算表访问的代价,那其实还有一种快速的访问方式是基于多个索引共同方式,也就是通过row ids排序后进行交集和并集的访问方式,会放在analyzing_roworder_intersect中。"usable"代表是否可能被用到,"cause"代表被拒绝的原因。通常我们会得到too_few_roworder_scans的原因。
"analyzing_index_merge_union": [
{
"indexes_to_merge": [
{
"range_scan_alternatives": [
{
"index": "ind1",
"ranges": [
"2 <= key1_part1 <= 2"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": true,
"rows": 1,
"cost": 0.36,
"chosen": true
}
],
"index_to_merge": "ind1",
"cumulated_cost": 0.36
},
{
"range_scan_alternatives": [
{
"index": "ind2",
"ranges": [
"4 <= key2_part1 <= 4"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": true,
"rows": 1,
"cost": 0.36,
"chosen": true
}
],
"index_to_merge": "ind2",
"cumulated_cost": 0.72
}
],
"cost_of_reading_ranges": 0.72,
"cost_sort_rowid_and_read_disk": 0.4375,
"cost_duplicate_removal": 0.254503,
"total_cost": 1.412
},
"chosen_range_access_summary": {
"range_access_plan": {
"type": "index_merge",
"index_merge_of": [
{
"type": "range_scan",
"index": "ind1",
"rows": 1,
"ranges": [
"2 <= key1_part1 <= 2"
]
},
{
"type": "range_scan",
"index": "ind2",
"rows": 1,
"ranges": [
"4 <= key2_part1 <= 4"
]
}
]
},
"rows_for_plan": 2,
"cost_for_plan": 1.412,
"chosen": true
}
如果整个Range分析过程中,有被选中的range扫描方式被选中,可以看到chosen_range_access_summary属性,否则没有。
- rows_for_plan:该执行计划的扫描行数
- cost_for_plan:该执行计划的执行代价
- chosen:是否选择该执行计划
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "i_l_shipdate",
"rows": 1,
"ranges": [
"NULL < l_shipDATE <= 0x229d0f"
]
},
"rows_for_plan": 1,
"cost_for_plan": 0.61,
"chosen": true
}- 选择最优执行计划(considered_execution_plans)
下面就来到了考虑最终执行计划的阶段,负责对比各可行计划的开销,并选择相对最优的执行计划。单表场景只会考虑Range和Ref的访问方式(Ref access vs. table/index scan)。
"considered_execution_plans": [ [52/47176]
{ [58/47542]
"plan_prefix": [
],
"table": "`lineitem`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "i_l_partkey",
"rows": 1,
"cost": 0.35,
"chosen": true
},
{
"access_type": "ref",
"index": "i_l_partkey_suppkey",
"rows": 1,
"cost": 0.35,
"chosen": false
},
{
"access_type": "range",
"range_details": {
"used_index": "i_l_partkey"
},
"chosen": false,
"cause": "heuristic_index_cheaper"
}
]
},如果多表还要进行贪婪算法,选出最有的连接顺序和方法,其中比较重要的属性是:
- plan_prefix:当前计划的前置执行计划。
- table:涉及的表名,如果有别名,也会展示出来
- best_access_path:本层table访问代价
- condition_filtering_pct:类似于filtered列,是一个估算值
- rows_for_plan:执行计划最终的扫描行数,由considered_access_paths.rows X condition_filtering_pct计算获得。
- cost_for_plan:执行计划的代价,由considered_access_paths.cost相加获得
- chosen:是否选择了该执行计划

我们通过tree来完整看下,橘红色为最终选择的JOIN的顺序,customer、orders、lineitem:

- 访问和连接的其他因素的考虑
- Join buffering (BNL/BKA/HASH JOIN)
"rest_of_plan": [
{
"plan_prefix": [
"`t1`"
],
"table": "`t2`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 5,
"filtering_effect": [
],
"final_filtering_effect": 0.3333,
"access_type": "scan",
"using_join_cache": true,
"buffers_needed": 1,
"resulting_rows": 1.6665,
"cost": 0.75002,
"chosen": true
}
]
},
"condition_filtering_pct": 60.006,
"rows_for_plan": 1,
"cost_for_plan": 1.30002,
"chosen": true
}
]- Filtering effects of conditions
如果有条件过滤中的where条件不在索引条件中,并且有表连接的场景,还可以关注filtering_effect的值,通过set optimizer_switch="condition_fanout_filter=on";可以关闭该优化。
"table": "`employee`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 10,
"filtering_effect": [
],
"final_filtering_effect": 0.1,
"access_type": "scan",
"resulting_rows": 1,
"cost": 1.75,
"chosen": true
}
]
},通过在驱动表上做额外的where条件过滤(Condition Filtering),能够将驱动表限制在一个更小的范围,以便优化器能够做出更优的执行计划。
root:test> set optimizer_switch="condition_fanout_filter=on";
Query OK, 0 rows affected (0.00 sec)
root:test> explain SELECT * FROM employee JOIN department ON employee.dept_id = department.DNO WHERE employee.emp_name = 'John' AND employee.hire_date BETWEEN '2018-01-01' AND '2018-06-01';
+----+-------------+------------+----------------------+--------+---------------+---------+---------+-----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+----------------------+--------+---------------+---------+---------+-----------------------+------+----------+-------------+
| 1 | SIMPLE | employee | p_1000,p_2000,p_3000 | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where |
| 1 | SIMPLE | department | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test.employee.dept_id | 1 | 100.00 | Using where |
+----+-------------+------------+----------------------+--------+---------------+---------+---------+-----------------------+------+----------+-------------+
2 rows in set, 1 warning (0.01 sec)
root:test> set optimizer_switch="condition_fanout_filter=off";
Query OK, 0 rows affected (0.00 sec)
root:test> explain SELECT * FROM employee JOIN department ON employee.dept_id = department.DNO WHERE employee.emp_name = 'John' AND employee.hire_date BETWEEN '2018-01-01' AND '2018-06-01';
+----+-------------+------------+----------------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+----------------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| 1 | SIMPLE | employee | p_1000,p_2000,p_3000 | ALL | NULL | NULL | NULL | NULL | 10 | 100.00 | Using where |
| 1 | SIMPLE | department | NULL | ALL | PRIMARY | NULL | NULL | NULL | 5 | 75.00 | Using where; Using join buffer (hash join) |
+----+-------------+------------+----------------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
2 rows in set, 1 warning (0.00 sec)- Semi-join策略的选择
我们知道一般有五种策略分别是FirstMatch、LooseScan、MaterializeLookup、MaterializeScan、DuplicatesWeedout。由于不同策略的执行方式不同,因此也是可以通过trace来判断最终的选择。也可以通过set @@optimizer_switch='materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on';来强制关闭某种策略,来查看效果。
"considered_execution_plans": [
{
"semijoin_strategy_choice": [
{
"strategy": "FirstMatch",
"recalculate_access_paths_and_cost": {
"tables": [
]
},
"cost": 0.7,
"rows": 1,
"chosen": true
},
{
"strategy": "MaterializeLookup",
"cost": 1.9,
"rows": 1,
"duplicate_tables_left": false,
"chosen": false
},
{
"strategy": "DuplicatesWeedout",
"cost": 1.9,
"rows": 1,
"duplicate_tables_left": false,
"chosen": false
}
]
......
{
"final_semijoin_strategy": "FirstMatch",
"recalculate_access_paths_and_cost": {
"tables": [
]
}
}
}
...
]表条件优化attaching_conditions_to_tables和finalizing_table_conditions
基于considered_execution_plans中选择的执行计划,改造原有where条件,并针对表增加适当的附加条件,以便于单表数据的筛选。
{
"attaching_conditions_to_tables": {
"original_condition": "(`lineitem`.`l_partkey` = 12)",
"attached_conditions_computation": [
],
"attached_conditions_summary": [
{
"table": "`lineitem`",
"attached": "(`lineitem`.`l_partkey` = 12)"
}
]
}
},最终的、经过优化后的表条件。
{
"finalizing_table_conditions": [
{
"table": "`lineitem`",
"original_table_condition": "(`lineitem`.`l_shipDATE` <= (DATE'1998-12-01' - interval '90' day))",
"final_table_condition ": "(`lineitem`.`l_shipDATE` <= ((DATE'1998-12-01' - interval '90' day)))"
}
]
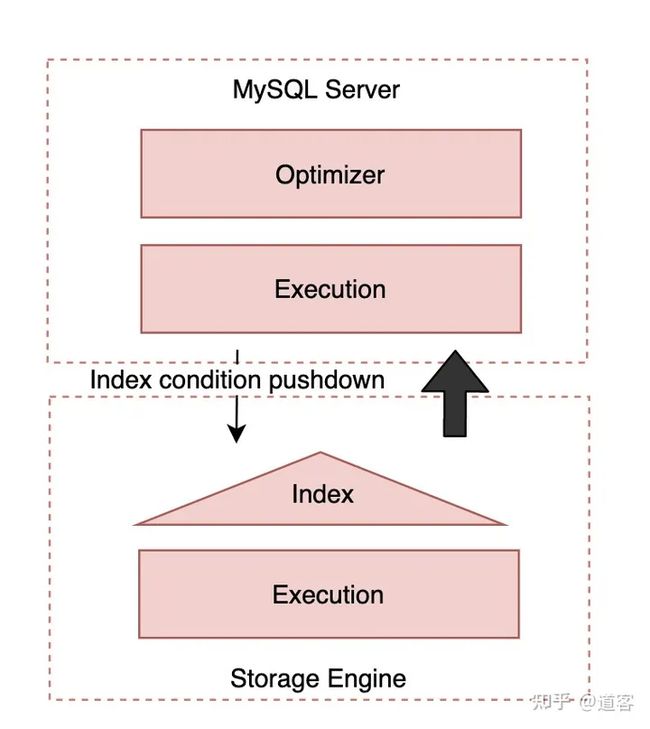
}, - 提炼计划(refine plan)
该阶段主要是直接展示执行计划中各个表的概要信息(包含index condition pushdown信息)。
{
"refine_plan": [
{
"table": "`t3`",
"pushed_index_condition": "(`t3`.`name` = 'acb')",
"table_condition_attached": null
}
]
}join_execution
该阶段主要展示的是执行过程中的下列信息:
- 临时表信息
这里展示了执行计划中临时表的基本信息,重要的信息包括了location:disk (InnoDB)、
{
"creating_tmp_table": {
"tmp_table_info": {
"table": "intermediate_tmp_table",
"in_plan_at_position": 8,
"columns": 3,
"row_length": 47,
"key_length": 5,
"unique_constraint": false,
"makes_grouped_rows": true,
"cannot_insert_duplicates": false,
"location": "TempTable"
}
}
},- 排序信息
这里包含了排序的基本信息filesort_information;是否用到优先级队列堆排序的优化filesort_priority_queue_optimization,通常LIMIT会用到该优化;排序用到的内存情况和大小filesort_summary
{
"sorting_table_in_plan_at_position": 8,
"filesort_information": [
{
"direction": "asc",
"table": "intermediate_tmp_table",
"field": "o_year"
}
],
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
},
"filesort_execution": [],
"filesort_summary": {
"memory_available": 262144,
"key_size": 13,
"row_size": 13,
"max_rows_per_buffer": 15,
"num_rows_estimate": 15,
"num_rows_found": 2,
"num_initial_chunks_spilled_to_disk": 0,
"peak_memory_used": 32784,
"sort_algorithm": "std::sort",
"unpacked_addon_fields": "using_heap_table",
"sort_mode": ""
}
} 总结
本文重点介绍了Optimizer trace的详细内容,只有深入了解这个工具本身的内容,才能真正具体分析优化器究竟做了哪些事情,根据哪些已有的索引、代价和优化方法进行了选择,基于什么原因做的选择。虽然JSON结果看起来复杂,但是仍然可以辅助DBA去发现性能问题,验证一些优化方法,希望这篇文章对大家有所帮助。