Linux三剑客:grep的基本使用
目录
grep介绍
什么是grep和egrep
使用grep
命令格式
命令功能
命令参数
grep配合正则表达式使用
认识正则
基本正则表达式
匹配字符
配置次数
位置锚定:定位出现的位置
分组和后向引用
作为学习一名计算机专业的学生,我想Linux应该需要了解吧,作为以后想要从事网络安全或者运维工作的小伙伴们,Linux那就要更加的熟练使用吧,学习Linux我们不可避免的需要接触到shell,那么Linux三剑客你就不得不学习,我就是一个梦想从事网络安全工作的大学生,所以从本篇开始会依次介绍Linux三剑客的基本使用与一些简单的练习,那么现在,开始!
grep介绍
什么是grep和egrep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来(匹配到的标红)。
grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep的工作方式是这样的:它在一个或多个文件中搜索字符串模板,如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。
我们利用这些返回值就可进行一些自动化的文本处理工作。
注:
egrep = grep -E:扩展的正则表达式 (除了< , > , \b 使用其他正则都可以去掉\)
正是因为shell中使用正则表达式需要使用-E,所以后面的示例中有很多的正则表达式前面加一个\
都是为了表示这是一个匹配字符
使用grep
命令格式
grep` `[option] pattern ``file命令功能
用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
命令参数
常用参数已加粗
-
-A<显示行数>:除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-
-B<显示行数>:除了显示符合样式的那一行之外,并显示该行之前的内容。
-
-C<显示行数>:除了显示符合样式的那一行之外,并显示该行之前后的内容。
-
-c:统计匹配的行数
-
-e :实现多个选项间的逻辑or 关系
-
-E:扩展的正则表达式
-
-f FILE:从FILE获取PATTERN匹配
-
-F :相当于fgrep
-
-i --ignore-case #忽略字符大小写的差别。
-
-n:显示匹配的行号
-
-o:仅显示匹配到的字符串
-
-q: 静默模式,不输出任何信息
-
-s:不显示错误信息。
-
-v:显示不被pattern 匹配到的行,相当于[^] 反向匹配
-
-w :匹配 整个单词
示例:
首先创建一个用于测试的文本文件
内容为:
yyy
pp
sss
ypsyps
yyppsss


grep配合正则表达式使用
认识正则
(1)介绍
正则表达式应用广泛,在绝大多数的编程语言都可以完美应用,在Linux中,也有着极大的用处。
使用正则表达式,可以有效的筛选出需要的文本,然后结合相应的支持的工具或语言,完成任务需求。
在本篇博客中,我们使用grep/egrep来完成对正则表达式的调用
(2)正则表达式类型
正则表达式可以使用正则表达式引擎实现,正则表达式引擎是解释正则表达式模式并使用这些模式匹配文本的基础软件。
在Linux中,常用的正则表达式有:
-
POSIX 基本正则表达式(BRE)引擎
-
POSIX 扩展正则表达式(BRE)引擎
基本正则表达式
匹配字符
(1)格式
-
. 匹配任意单个字符,不能匹配空行
-
[] 匹配指定范围内的任意单个字符
-
[^] 取反
-
[:alnum:] 或 [0-9a-zA-Z]
-
[:alpha:] 或 [a-zA-Z]
-
[:upper:] 或 [A-Z]
-
[:lower:] 或 [a-z]
-
[:blank:] 空白字符(空格和制表符)
-
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
-
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
-
[:digit:] 十进制数字 或[0-9]
-
[:xdigit:]十六进制数字
-
[:graph:] 可打印的非空白字符
-
[:print:] 可打印字符
-
[:punct:] 标点符号
(2)示例
还是一样,首先编辑一个用于测试的文件
内容:
abc
123
//[
注:这里面的空行是有用的,不要删除
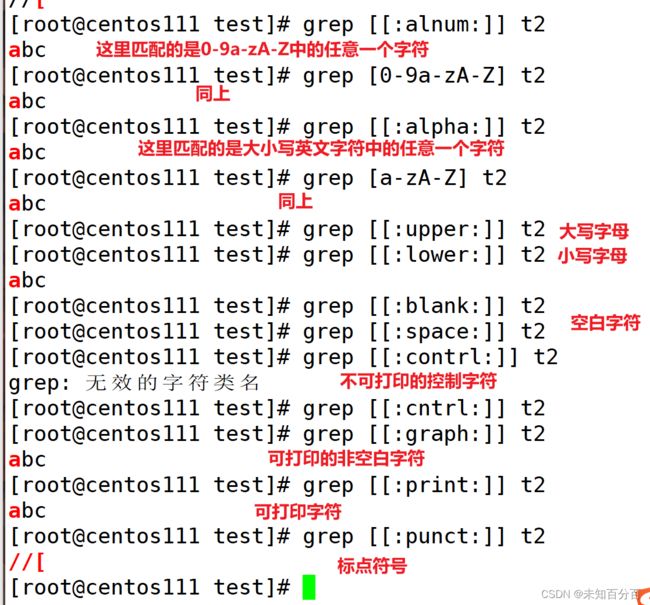
注:以上所有的匹配都是匹配单个字符,并且是非贪婪匹配,即匹配到一个就不再匹配了
配置次数
(1)格式
-
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
-
.* 任意前面长度的任意字符,不包括0次
-
\? 匹配其前面的字符0 或 1次
-
+ 匹配其前面的字符至少1次
-
{n} 匹配前面的字符n次
-
{m,n} 匹配前面的字符至少m 次,至多n次
-
{,n} 匹配前面的字符至多n次
-
{n,} 匹配前面的字符至少n次
(2)示例
首先还是一样新建一个测试文件
内容:
ggle
gogle
google
gooooooooooooooooogle
gagle


位置锚定:定位出现的位置
(1)格式
-
^ 行首锚定,用于模式的最左侧
-
$ 行尾锚定,用于模式的最右侧
-
^PATTERN$,用于模式匹配整行
-
^$ 空行
-
^[[:space:]].*$ 空白行
-
< 或 \b 词首锚定,用于单词模式的左侧
-
> 或 \b 词尾锚定;用于单词模式的右侧
-
(2)示例
文件内容:
aaaa
bbbb
qweqadadqqq
分组和后向引用
(1)格式
① 分组:() 将一个或多个字符捆绑在一起,当作一个整体进行处理
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, ...
② 后向引用
引用前面的分组括号中的模式所匹配字符,而非模式本身
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
\2 表示从左侧起第2个左括号以及与之匹配右括号之间的模式所匹配到的字符,以此类推
& 表示前面的分组中所有字符
③ 流程分析如下:
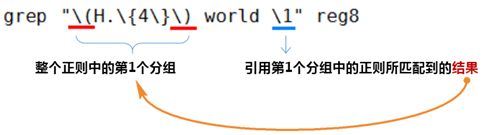
示例:
文件内容:
