搜狐视频的屌丝男士第二季大结局了,惊现波多野老师,怀揣着无比鸡冻的心情啊,可惜随着剧情的推进发展,并没有出现期待中的屌丝奇遇,大鹏还是没敢冲破尺度的界线。想百度些种子吧,又不想让电脑留下污点证据,要知道大洋彼岸有个棱镜计划,只好作罢。不如看看书吧,书中自有颜如玉。
开始本次读书笔记前,先扯两个哲学观点,提高下境界。第一个就是《Data-Intensive Text Processing with mapReduce》读书笔记前言中谈到的,大数据产生了大价值,对应的思想很简单:量变导致了质变。第二个就要引出本节读书笔记的一种思想:分而治之。后者,大家都会用的,特别你是管理者的话,会把一个很大的问题,分成几个独立的部分,然后分给几个下属去完成,最后你再把结果给简单汇总,当然了苦逼的是下属。
《Data-Intensive Text Processing with mapReduce》读书笔记之二:mapreduce编程、框架及运行
Mapreduce处理数据的思想正是分而治之。其最大的优势就是提过了Mapper和Reducer两个抽象的上层模型,统一了构架,为程序开发者隐含了很多底层分治的细节,比如:
1).如何划分任务;
2).如何实现同步;
3).如何共享中间结果;
4).如何处理错误
这些在传统的并行计算中,都是需要开发者自己设计考虑的。此外,Mapreduce将数据分散到节点上,并在节点上计算处理,效率极高。下面将详细探讨mapreduce的编程、执行过程以及优化处理。
1.Mapper与Reducer
首先Mapreduce中最基本的数据结构就是key-value对,两者可以是基本数据类型,也可自定义(当然自定义也不简单,要继承hadoop api中的相关类,覆盖重新那些比较、hash方法之类的,在此还特别说明下,hadoop开源是java实现的,详细请看《hadoop权威指南》)。借鉴于经典的函数式程序设计语言Lisp中的思想,在Mapper和Reducer对象里分别定义了Map和reduce两个抽象的操作函数:
map: (k1; v1) [(k2; v2)]
reduce: (k2; [v2]) [(k3; v3)] (本书用[...]表示列表,集合)
图1:简化的mapreduce计算
有两个特点:描述了对一组数据处理的两个阶段的抽象操作,仅仅描述了需要做什么,不需要关注怎么做。上图表示的Mapreduce计算的简化版。其执行过程可描述为:
1) 数据输入到Mapper中,生成Key-value对的列表(中间数据);
2) 将中间结果清洗、默认按Key来排序(此过程为隐含操作);
3) 每组对应一个reduce,进行并行计算并输出处理
以mapreduce中的“Hello word”,即单词个数统计为例,其算法描述如下:

图2:单词统计的伪代码
在算法中,Key-value对是(docid,doc),即(文档的编号id,文档的内容),mapper将doc中的单词逐个抽取,然后对每个单词产生(key,value)对(可重复),其中key就是单词本身,value就是1,故为(word,1)的形式;而后(word,1)被分组、划分(partitioner完成,将在后面谈及,默认是隐含操作),改过程保证了所有具有相同key的key-value对(这里指的是经过mapper处理得到的中间结果,即指具有相同word的(word,1)对)都能够被分配到同一个reduce中;紧接着reduce将具有相同word的计数累加,并将结果排序输出。
2.执行框架
再次强调:MapReduce最伟大的地方在于它分离了编写并行算法的what和how。其执行框架对次体现尤为明显:在几乎封装了底层实现的同时,还具有节点从几个到上千个的良好扩展性。这些隐含的执行,具体有:
1) 调度
主要是指任务的调度,每个mapreduce工作任务被分解为多个小的任务tasks。Map任务负责处理输入的键值对,reduce任务需要处理中间结果的键值对;任务的等待分配是常有的事情,特别对于大规模的计算来说,等待分配的任务比并行计算的节点多的时候,调度的重要性就体现出来了。对单个任务,分配的任务要适当,太多时需要维护队列,保证顺序执行;对于多个工作,要保证共享性、可靠稳定性。
预测执行是任务调度中的优化措施,不管是在map还是reduce阶段,总有某个任务的最慢的,通常把最慢者称为“掉对者”。因为有可能是任务划分不均匀,硬件故障等导致任务执行缓慢,而预测执行解决该问题的方法是在另一台机器上执行一个相同任务的拷贝,当这两个任务有一个完成时,即认为任务已完成。
数据/代码 本地化
这是与传统并行计算的区别,就是把代码的执行运算放到存放所需数据的节点上,利用数据2)的局部性,降低数据网络传输及延迟。通常,数据中心的数据量最大,单机的最少;但宽度或者延迟则相反。
3)同步
首先来看mapreduce中中间数据的产生到处理是如何执行的:
@ map的产生的中间结果,全部经分组排序后,reduce才开始启动;
@r从输入map产生的m个中间结果,经分组排序到分配到n个reduce,需m*n个传输操作;
Reduce的启动需要等待中间数据处理完事无法避免的事实,但是可以实现将处理好的中间数据传输给reduce,既可以等map产生玩数据后对中间结果的异步传输,也可以边产生map,边将数据传输至reduce,这都是根据实际问题进行高效的处理。
1) 错误和故障处理
由于数据存储在普通pc机上,单点硬件故障是常见的,主节点会周期性地给工作节点发送检测命令,如果工作节点没有回应,这认为该工作节点失效,主节点将终止该工作节点的任务并把失效的任务重新调度到其它工作节点上重新执行(这种机制通常称为心跳机制)。(此外,主节点中会周期性地设置检查点(checkpoint),检查整个计算作业的执行情况,一旦某个任务失效,可以从最近有效的检查点开始重新执行,避免从头开始计算的时间浪费)。可见,mapreduce的有很强容错性。
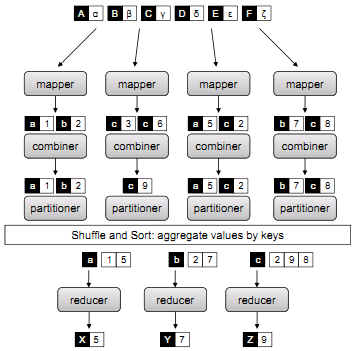
图3:完整的mapreduce过程
5)Partitioner 与 Combiner(划分与合并)图3
Partitionner:划分的主要任务是将mapper后的中间数据key-value对进行划分,每个划分对应分配到同一个reducer。默认的做法就是按着key的hash值对个数取模,相同模对应同一个reducer。但该方法不能保证key-value对分布的均匀,因为只按key进行划分,对有些key对应的value的个数相差太大,就会导致虽然分配到reducer的key种类数均匀但key-value对的个数不均匀。用户如果了解key-value对的特点,可以自定制划分方法,保证划分均匀,有利于提高reducer并行计算的速度。
Combiner:在mapper产生的中间数据还未被混洗划分前的一个局部合并,在某个mapper产生的数据后合并,相当于对每个mapper进行了一次“迷你的reducer操作”,即可以使得每个Mapper 的map 方法产生的结果本地聚集,它能有效减少map和reduce之间的数据传输量,是一种网络传输优化手段。
湖南省内10县市突破38℃高温,衡山、永兴、衡南达39.6℃;省气象台预计,受台风“苏力”影响,今晚到明天,湘东半部有中等阵雨或雷阵雨。