ElasticSearch 自定义分词器Analyzer示例
一、前提概述
接下来定义一个index,并在该index中使用自定义分词器。
假设在ES中有这么一个index,用来存储用户在什么时间调用了哪个接口,调用的入参是什么的这么一个信息(即服务网关日志),要存储的数据示例如下所示(已脱敏):
[
{
"authSignId" : "75",
"interfaceName" : "/vehicle/interface1",
"requestData" : """{"head":{"sign":"86006c91a07f88aaaaaaaaaaaa","systemSign":"dkgc","timeStamp":"1646848500981","version":"20191213"},"body":{"endTime":1646848500795,"page":-1,"pageSize":-1,"radius":0,"startTime":1646805300795,"tplType":-1,"vehiclePlateNoAndColor":"鲁Q050EV@黄色"}}""",
"log_time" : "2022-03-10 01:55:00"
},
{
"authSignId" : "5",
"interfaceName" : "/vehicle/interface2",
"requestData" : """{"head":{"sign":"6d1bee5f0971bbbbbbbbbbbbbb","systemSign":"kfpt","timeStamp":"1646848500232","version":"20181023"},"body":{"endTime":-1,"page":-1,"pageSize":-1,"radius":0,"startTime":-1,"tplType":-1,"vehiclePlateNoAndColorList":["津C28933@黄色"]}}""",
"log_time" : "2022-03-10 01:55:00"
},
{
"authSignId" : "5",
"interfaceName" : "/vehicle/interface3",
"requestData" : """{"head":{"sign":"6f0514f860cccccccccccccccc","systemSign":"kfpt","timeStamp":"1646848499342","version":"20181023"},"body":{"endTime":-1,"maxOfflineTime":"172800000","page":-1,"pageSize":-1,"radius":0,"startTime":-1,"tplType":-1,"vehiclePlateNoAndColorList":["冀A96243@黄色"]}}""",
"log_time" : "2022-03-10 01:54:59.562"
},
{
"authSignId" : "14",
"interfaceName" : "/vehicle/interface4",
"requestData" : """{"head":{"sign":"069d352985e2dddddddddddddd","systemSign":"clwsjzx","timeStamp":"1646848502122","version":"20190109"},"body":{"vid":"3367053073233333","startTime":1646845465000,"endTime":1646849065000}}""",
"log_time" : "2022-03-10 01:55:02.335"
},
{
"authSignId" : "85",
"interfaceName" : "/vehicle/interface5",
"requestData" : """{"head":{"sign":"1a0a24e62ac506eeeeeeeeeeee","systemSign":"yljj","timeStamp":"1646848499744","version":"20200420"},"body":{"vehiclePlateNoAndColor":"陕KD5260@黄色","tplId":"2168053781999934883","message":"{\"城市区域名称\":\"榆林\",\"危险路段描述\":\"道路弯急\"}"}}""",
"log_time" : "2022-03-10 01:54:59.989"
}
]
在本例子中,我们只关心requestData字段,将该字段的内容格式化一下方便看清它的内容:
{
"head": {
"sign": "1da02bc2e0945187bbbbbbbbbbbbbb",
"systemSign": "kfpt",
"timeStamp": "1646830874618",
"version": "20181023"
},
"body": {
"endTime": 1646830771000,
"page": -1,
"pageSize": -1,
"radius": 0,
"startTime": 1646830721000,
"tplType": -1,
"vehiclePlateNoAndColor": "车牌号在末尾津B2M937@黄绿色"
}
}
结合示例数据,以及该字段格式化之后的格式,不难看出该字段的值其实就是调用一个POST接口时的body入参。
二、分词器的选择
此时就需要使用一个合适的分词器,来对该字段进行分词处理。
先说一下处理的相关要求:
1)首先,我们是不关心json串中的key值的
2)其次,也不关心json串中的head部分,而只关心body中的中文的部分
基于以上要求,首先ES的内置的分词器肯定是不满足需求了,然后也无法直接使用IK分词器,因为直接使用IK分词器对requestData字段进行分词之后,key的值依然存在,如下图:
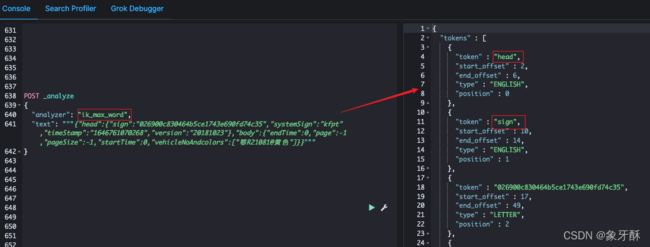
这就使得:
1)类似head、sign这样的毫无业务意义的key也被切分为了token,从而放入到倒排索引中,凭白占用了ES空间;
2)由于类似head、sign这样的key也被放入到了倒排索引中,就会使得通过这些key来进行检索时,也同样能够查询到数据,这就不符合我们的查询时候的期望值了(这里我们假设用户想查询的是value值中,包含了某些关键词的数据)。
基于上述需求,这里将自定义两个分词器,名字分别是dmp_custom_json_ik_analyzer和custom_car_number_analyzer。
其中:
- dmp_custom_json_ik_analyzer
功能是先剔除掉json串中的key值,接着再对value值使用IK分词器进行切分 - custom_car_number_analyzer
功能是将json串中的车牌号提取出来。之所以要自定义这个分词器,是因为最开始只定义了上面那个分词器时,用户在使用车牌号去进行查询时,根本查询不到数据,详情可查看该博客《全文检索问题:根据车牌号查询,检索结果跟预期不一致的问题的排查与解决方法》。
因此,在这里需要再定义这个分词器。并且在本例中,也是着重对这个分词器进行的解释。
三、自定义分词器的使用
定义一个索引,并在索引中引用我们自定义分词器
# 为防止index已存在,可先进行删除
DELETE idx-susu-test-car-number
# 设置index的settings和mappings配置
PUT idx-susu-test-car-number
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis" : {
"char_filter" : {
"del_header_char_filter" : {
"type" : "pattern_replace",
"pattern" : """("head":)(.*)(,"body":)""",
"replacement" : ""
},
"del_digit_char_filter" : {
"type" : "pattern_replace",
"pattern" : """(:(-)?\d+,)""",
"replacement" : " "
},
"json_key_char_filter" : {
"type" : "pattern_replace",
"pattern" : """("\w*")(\s*)(:)""",
"replacement" : "$3"
},
"symbol_char_filter" : {
"type" : "pattern_replace",
"pattern" : """\{|\}|,""",
"replacement" : " "
},
"not_car_number_char_filter" : {
"type" : "pattern_replace",
"pattern" : """([^(([京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[警京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼]{0,1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1})(@(白|蓝|黄|黑|绿|黄绿|渐变绿)色)?)]+)""",
"replacement" : " "
}
},
"filter" : {
"car_number" : {
"type" : "pattern_capture",
"preserve_original" : true,
"patterns" : [
"([京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[警京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼]{0,1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1})",
"(白色|蓝色|黄色|黑色|绿色|黄绿色|渐变绿色)"
]
}
},
"analyzer" : {
"dmp_custom_json_ik_analyzer": {
"char_filter": [
"json_key_char_filter"
],
"tokenizer": "ik_max_word"
},
"custom_car_number_analyzer" : {
"char_filter" : [
"del_header_char_filter",
"json_key_char_filter",
"del_digit_char_filter",
"symbol_char_filter",
"not_car_number_char_filter"
],
"tokenizer" : "whitespace",
"filter": ["car_number"]
}
}
}
},
"mappings": {
"properties": {
"requestData": {
"analyzer": "dmp_custom_json_ik_analyzer",
"type": "text",
"fields": {
"carNumber": {
"analyzer": "custom_car_number_analyzer",
"type": "text"
}
}
}
}
}
}
注:
在requestData字段上,使用的是dmp_custom_json_ik_analyzer分词器,同时给这个字段添加了一个名为carNumber的子字段,并将子字段设置的分词器是custom_car_number_analyzer。
接着往索引中插入数据:
PUT idx-susu-test-car-number/_bulk?refresh=true
{ "index": { "_id": "1" }}
{ "requestData": """{"head":{"sign":"0b02feea339667e96c649dc7a9063d75","systemSign":"dkgc","timeStamp":"1646780548613","version":"20191213"},"body":{"queryDate":"20220307","vehiclePlateNoAndColorList":["津C36267@白色","津C36285@黑色","津C36580@蓝色","津C36605@黄绿色","津C36633@黄色","津C37178@渐变绿色]}}"""}
{ "index": { "_id": "2" }}
{ "requestData": """{"head":{"sign":"1da02bc2e0945187612b3268437b9901","systemSign":"kfpt","timeStamp":"1646830874618","version":"20181023"},"body":{"endTime":1646830771000,"page":-1,"pageSize":-1,"radius":0,"startTime":1646830721000,"tplType":-1,"vehiclePlateNoAndColor":"津B2M936"}}"""}
{ "index": { "_id": "3" }}
{ "requestData": """{"head":{"sign":"1da02bc2e0945187612b3268437b9901","systemSign":"kfpt","timeStamp":"1646830874618","version":"20181023"},"body":{"endTime":1646830771000,"page":-1,"pageSize":-1,"radius":0,"startTime":1646830721000,"tplType":-1,"vehiclePlateNoAndColor":"车牌号在末尾津B2M937@黄绿色"}}"""}
{ "index": { "_id": "4" }}
{ "requestData": """{"head":{"sign":"1da02bc2e0945187612b3268437b9901","systemSign":"kfpt","timeStamp":"1646830874618","version":"20181023"},"body":{"endTime":1646830771000,"page":-1,"pageSize":-1,"radius":0,"startTime":1646830721000,"tplType":-1,"vehiclePlateNoAndColor":"津B2M938车牌号在开头"}}"""}
{ "index": { "_id": "5" }}
{ "requestData": """{"head":{"sign":"1da02bc2e0945187612b3268437b9901","systemSign":"kfpt","timeStamp":"1646830874618","version":"20181023"},"body":{"endTime":1646830771000,"page":-1,"pageSize":-1,"radius":0,"startTime":1646830721000,"tplType":-1,"vehiclePlateNoAndColor":"车牌号在中间津B2M938@蓝色车牌号在中间"}}"""}
{ "index": { "_id": "6" }}
{ "requestData": """{"head":{"sign":"026900c830464b5ce1743e690fd74c35","systemSign":"kfpt","timeStamp":"1646761070268","version":"20181023"},"body":{"endTime":0,"page":-1,"pageSize":-1,"startTime":0,"vehicleNoAndcolors":["鄂R21081@黄色"]}}"""}
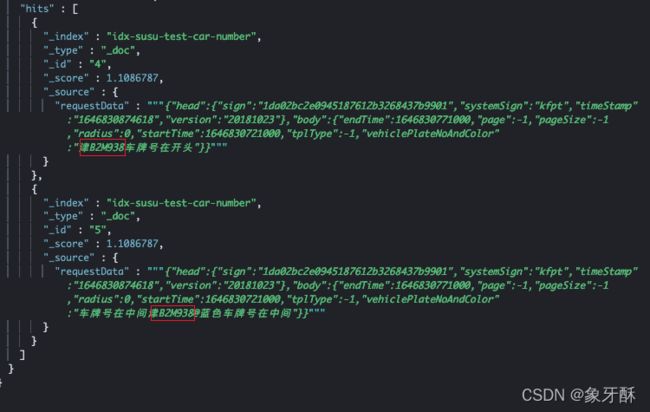
然后在requestData.carNumber字段上,对指定车牌号进行查询
# 在requestData.carNumber字段上查询关键字“津B2M938”
GET idx-susu-test-car-number/_search
{
"query": {
"match": {
"requestData.carNumber": {
"query": "津B2M938"
}
}
}
}
查询结果如下,可以看到,已经能正确的根据车牌号查询出来结果
四、自定义分词器详解
接下来对自定义的分词器进行详解
观察该分词器的组成:
"custom_car_number_analyzer" : {
"char_filter" : [
"del_header_char_filter",
"json_key_char_filter",
"del_digit_char_filter",
"symbol_char_filter",
"not_car_number_char_filter"
],
"tokenizer" : "whitespace",
"filter": ["car_number"]
}
组成如下:
1)5个自定义的character filter
2)1一个ES内置的名为whitespace的tokenizer
3)1个自定义的token filter
一个analyzer中不同角色的应用顺序

1.character filter
1)del_header_char_filter
基于pattern_replace规则自定义的character filter,功能是将requestData字段输入的json串中的head部分给剔除掉。定义如下:
"del_header_char_filter" : {
"type" : "pattern_replace",
"pattern" : """("head":)(.*)(,"body":)""",
"replacement" : ""
}
假设数据的requestData内容:
{
"head": {
"sign": "1da02bc2e0945187612b3268437b9901",
"systemSign": "kfpt",
"timeStamp": "1646830874618",
"version": "20181023"
},
"body": {
"endTime": 1646830771000,
"page": -1,
"pageSize": -1,
"radius": 0,
"startTime": 1646830721000,
"tplType": -1,
"vehiclePlateNoAndColor": "津B2M937中间内容津B2M938@蓝色车牌号"
}
}
则在经过该character filter处理之后,得到的结果如下,可以看到,head部分已经被剔除掉了
{ {
"endTime": 1646830771000,
"page": -1,
"pageSize": -1,
"radius": 0,
"startTime": 1646830721000,
"tplType": -1,
"vehiclePlateNoAndColor": "津B2M937中间内容津B2M938@蓝色车牌号"
}
}
2)json_key_char_filter
基于pattern_replace规则自定义的character filter,功能是将输入的json串中的key剔除出去。定义如下
"json_key_char_filter" : {
"type" : "pattern_replace",
"pattern" : """("\w*")(\s*)(:)""",
"replacement" : "$3"
}
那么上一步的结果,在经过当前的character filter 处理之后,输出如下:
{ {
: 1646830771000,
: -1,
: -1,
: 0,
: 1646830721000,
: -1,
: "津B2M937中间内容津B2M938@蓝色车牌号"
}
}
3) del_digit_char_filter
这同样是基于pattern_replace规则自定义的character filter,功能是将内容是纯数值的value值给剔除掉。定义如下
"del_digit_char_filter" : {
"type" : "pattern_replace",
"pattern" : """(:(-)?\d+,)""",
"replacement" : " "
}
上一步的结果,在经过当前character filter处理之后,得到的结果如下:
{ {
: "津B2M937中间内容津B2M938@蓝色车牌号"
}
}
4)symbol_char_filter
基于pattern_replace规则自定义的character filter,功能是将输入中的大括号和逗号,给替换为空格" "。定义如下:
"symbol_char_filter" : {
"type" : "pattern_replace",
"pattern" : """\{|\}|,""",
"replacement" : " "
}
上一步的结果,在经过当前character filter处理之后,得到的结果如下:
"津B2M937中间内容津B2M938@蓝色车牌号"
5) not_car_number_char_filter
这是最核心的一个character filter,它同样基于pattern_replace规则进行构建。主要功能是将不是车牌号的内容,替换成空格。定义如下:
"not_car_number_char_filter" : {
"type" : "pattern_replace",
"pattern" : """([^(([京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[警京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼]{0,1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1})(@(白|蓝|黄|黑|绿|黄绿|渐变绿)色)?)]+)""",
"replacement" : " "
}
上一步的结果,在经过当前character filter处理之后,得到的结果如下:
津B2M937 津B2M938@蓝色
综上,这5个character filter结合起来,完成的功能是,将输入中除了车牌号(或车牌号@颜色)的部分都剔除掉,只留下车牌号(或车牌号@颜色)
2.tokenizer
这里使用的tokenizer是ES内置的whitespace。由于前面的几个character filter已经将输出处理的只剩下车牌号了(并且若有多个车牌号,则多个车牌号之间是空格作为分隔符),因此这里使用whitespace这个tokenizer来进行切分。
依旧使用上面的示例,则经过切分之后,将得到如下的2个token:
["津B2M937", "津B2M938@蓝色"]
3.token filter
这里使用的是一个名为car_number的自定义的token filter,它是基于pattern_capture的token filter规则来构建的,该规则的更多详情可参考ES官网。
自定义的car_number 的token filter 具体定义如下:
"car_number" : {
"type" : "pattern_capture",
"preserve_original" : true,
"patterns" : [
"([京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[警京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼]{0,1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1})",
"(白色|蓝色|黄色|黑色|绿色|黄绿色|渐变绿色)"
]
}
该token filter的功能是,对于从tokenizer接收过来的类似津B2M938@蓝色这样的token,再次进行处理,将其切分如下:
["津B2M938", "蓝色", "津B2M938@蓝色"]
最后看下该分词器的分词效果:

五、参考
- 自定义analyzer:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-custom-analyzer.html#_configuration
- 自定义character filter:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html
- 自定义tokenizer:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html
- 自定义token filter:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html