论文阅读(1) —— Character Region Awareness for Text Detection
论文地址:https://arxiv.org/abs/1904.01941
Pytorch代码实现 https://github.com/clovaai/CRAFT-pytorch
自制PPT下载地址:https://download.csdn.net/download/weixin_43575791/12322592
Introduction
(这部分可忽略,暂时为保留完整性写下来。)
深度学习出现之前,场景文本检测是采用自底而上的方法,大多使用人工特征,比如MSER or SWT 作为基本成分。
而基于深度学习的文本检测提出采用目标检测或实例分割的方法,比如SSD,Faster R-CNN,FCN
基于回归的文本检测:
和一般物体不同,文本形状不规则,长宽比不同
为了解决这个问题,TextBoxes改变卷积核和锚点边框以便有效的捕捉不同的文本形状。
DMPNet尝试合并四边形滑窗。
Rotation-Sensitive Regression Detector (RSDD):充分使用旋转不变性,将卷积核旋转。但是使用这种方法对捕捉所有可能的形状存在结构制约
基于分割的文本检测:
分割的方法致力于寻找像素级别的文本区域。
这些想通过估计词的边界区域来检测文本的方法也使用分割作为基础
SSTD试图从回归和分割两种方法中受益,它使用了一种注意机制,通过减少特征层上的背景干扰来增强文本相关区域。
TextSnake通过预测文本区域和中心线以及几何属性来检测文本实例。
端到端的文本检测:
端到端的方法将检测和识别一起训练,以利用识别结果来提高检测准确性
FOTS and EAA 连接了最受欢迎的检测和识别方法,并以端到端的方式训练
Mask TextSpotter利用统一模型来把识别任务作为一个语义分割问题处理
很明显,使用识别模块进行训练有助于文本检测器对类似文本的背景杂波具有更强的鲁棒性。
大多数方法以检测单词作为单元,但是检测字母的边界也很重要。因为 划分单词的标准很多,比如空格、颜色,意思。
CRAFT
CRAFT全称:Character Region Awareness for Text Detection,是一种文字检测方法。
公开数据集一般都是单词级标注,合成的图像有字符级标注,本文利用单词级标注的真实图片和字符级标注的合成图片训练craft模型。craft可以定位字符区域,并且把检测到的字符连成文字实例。craft使用弱监督框架,在现有的单词级数据集基础上估计字符级真值。
craft很灵活,可检测长的、弯曲的、任意形状的文本
其效果图下图

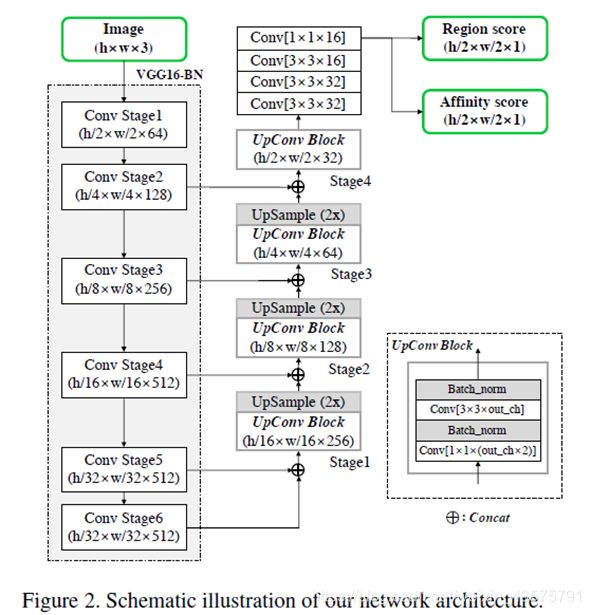
Architecture
backbone为带BN层的VGG16
上采样部分采用和U-net类似的跳跃连接,可以聚合低层次的特征图
输出为两个通道,区域分数以及关联分数
其中,区域分数代表给定像素是字符中心的概率,用来定位单个字符;
关联分数代表相邻字符间距中心的概率,用来把每个字符组合成实例。
网络结构如下图:
Training
训练过程如下图:
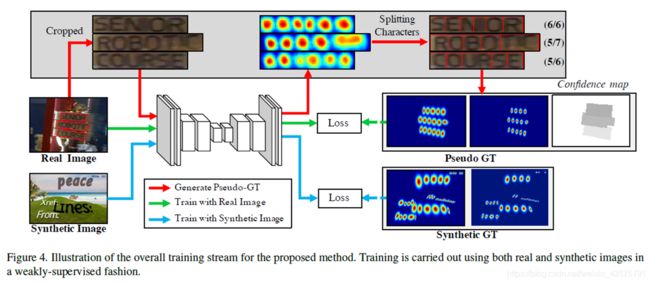
首先,用来训练的图片分为两类。
一是只有单词级标注的真实图片
二是人工合成的图片,人工合成的图片有字符级标注
网路训练过程整体上为,将图片输入网络,输出预测的the region score and the affinity score,然后有每个字符有pseudo-ground truth,通过使得损失函数最小不断调整网络中的权重及偏置项,得到训练好的模型。
但是,这里有两个问题是
一、和预测的the region score and the affinity score相对应的Ground Truth Label如何产生
二、真实图片是没有字符级标注的,如何产生字符级标注(解决了第一个问题,且有了字符级标注后,真实图片也按照同样的方法生成Ground Truth Label)
对于第一个问题,如何产生Ground Truth Label,作者解决办法如下:
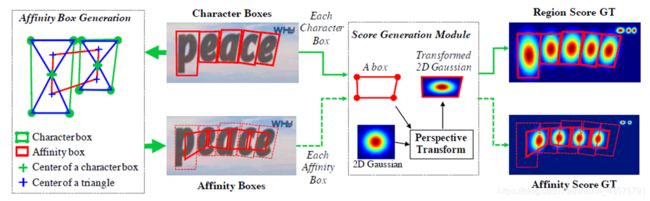
首先这个办法的前提是有字符级标注。
生成办法如下:
1、affinity box生成过程:
1) 连接每个字符边框对角,产生两个三角形,分别为上、下字符三角形
2) 对每一对相邻字符框,上下字符三角形的中心作为角,就产生affinity box
2、分数生成过程:
1)准备2维等向高斯热图
2)在高斯热图区域和每一个字符边框之间计算透视变换
3)变换高斯热图到字符边框区域
也就是,原本字符级标注就是有字符边框的,有了字符边框,自己设置高斯热图(也就是字符中心概率分布设为二维高斯分布),经过透视变换,就产生了 region score GT。affinity box生成过程帮我们产生了关联边框,有了边框就可以用同样的方法产生affinity score GT 了。
到现在为止,只要有字符级标注,就可以产生对应的分数标签,the region score and the affinity score。
这只解决了上述的第一个问题:Ground Truth Label如何产生,还有第二个问题:真实图片没有字符级标注怎么办?
解决办法如下:
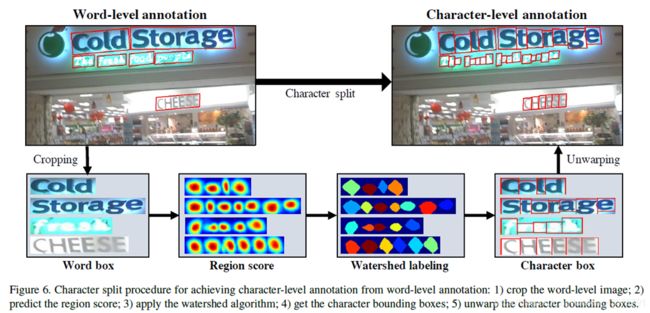
总之是要想办法把字符分开。
文章采用分水岭算法(watershed algorithm)分开字符,具体如下:
把图片中单词级标注的区域裁剪下来,用本文之前介绍的以VGG16为backbone并能产生region score and affinity score的网络预测出region score,然后应用分水岭算法,产生字符边框,并还原到原图片上。
关于分水岭算法如何产生边框的,不做过多描述,可参考其他博客。这里简述如下:
任何一副灰度图像都可以被看成拓扑平面,灰度值高的区域可以被看成是山峰,灰度值低的区域可以被看成是山谷。我们向每一个山谷中灌不同颜色的水。随着水的位的升高,不同山谷的水就会相遇汇合,为了防止不同山谷的水汇合,我们需要在水汇合的地方构建起堤坝。不停的灌水,不停的构建堤坝知道所有的山峰都被水淹没。我们构建好的堤坝就是对图像的分割。
下附分水岭算法示意图
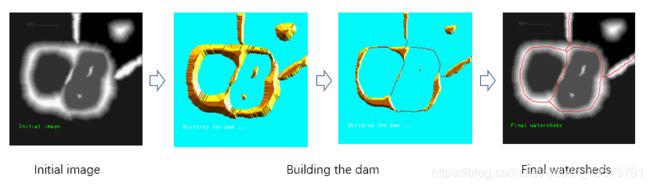
上述这种利用真实图片的单词级标注来产生字符级标注,进而用来训练模型的方式,称为弱监督学习方式,也是本文的一大特色。
现在,两个问题都解决了
下面定义损失函数:
首先,说明数学符号的含义:

然后:
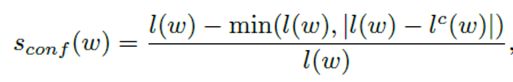
当一个单词级标注的样本,经过上面说过的字符级标注过程,产生字符级标注的时候,会预测出lc(w)个字符,实际上的真实字符数是l(w),前面我们都没有讲过,如何评定产生的字符标注的准确性,这个公式可以代表一个置信分数,观察这个公式可以发现,预测的字符数和真实字符数越接近,即lc(w)和l(w)越接近,置信分数越大,可信度越高,当两者相等时,Sconf(w)=1。
下面一个公式:
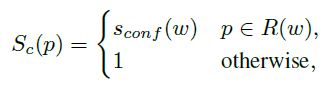
这个公式是在定义每个像素的的置信度,当像素p属于样本w的区域时,像素p的置信度为样本w的置信分数,其他区域设为1。这里可以理解为,其他区域确定不是字符所在区域,所以概率为1。同时,对于合成图像来说,由于其字符级标注不是预测的,所以所有像素的置信度都设为1,即 Sc(p) =1
最后一个公式,也就是最重要的损失函数:
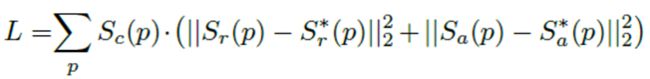
可以看到,最小化损失函数,也就是在不断调整网络权重,使网络预测的the region score and the affinity score更接近pseudo-ground truth,这里可以认为Sc(p)是权重。
Inference
对于任意形状文本,可以产生多边形
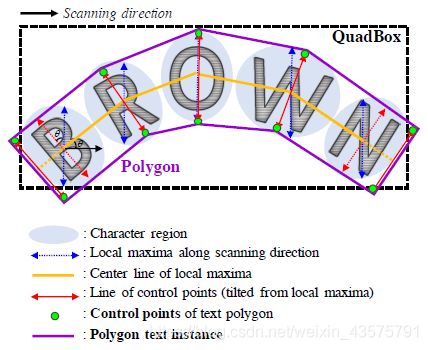
具体来说,可以先产生一个矩形框QuadBox,步骤如下:
1)先生成一个二值图M,初始化为0
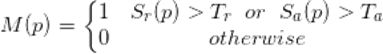
Tr:区域分数 (the region score) 阈值
Ta:关联分数 (the affinity score) 阈值
对于每个像素,分数超过相应的阈值,则设为1,其他设为0
2)Connected Component Labeling (CCL)
进行区域连通标记。
3)找到最小面积外接矩形
关于区域连通标记:
区域连通标记指的是,找出图像中连通区域并且标记,处理对象一般为二值化图像
而连通区域一般有4 - 邻域连通和8 - 邻域连通,如下图:

除了可以生成矩形框,也可以为任意文本形状生成多边形边框,做法如下:
1)沿着扫描的方向,找到每个字符局部极大值线。
将局部极大值线的长度相等地设置为其中的最大长度,以防止最终的多边形变得不均匀,即图中蓝色线
2)连接每个局部极大值线的中心,即图中黄色线
3)将蓝色线旋转到与黄色线垂直来反映倾斜角,旋转后的线即图中红色线
4)局部极大值线的端点即是多边形的控制点,即图中绿色圆圈
5)将两边的极大直线向外移动,即得最外面的控制点,以覆盖文字区域,即图中两端最外面的红色线,即其绿色端点
Experiment
关于试验部分,简单介绍如下:
评价指标:recall, precision and H-mean
Datasets: IC13、IC15、IC17、TD500、TotalText、CTW
Training strategy
first use the SynthText dataset to train the network for 50k iterations,
then each benchmark dataset is adopted to fine-tune the model.
优化:ADAM optimizer
GPU:多GPU,训练和监督GPU分离,产生的pseudo-GTs保存在内存中
fine-tuning:SynthText dataset 使用比例1:5确保字符分开
On-line Hard Negative Mining:使用,1:3
Data augmentation techniques:crops, rotations, and/or color variations
Datasets
总结了一下文中用的数据集信息:
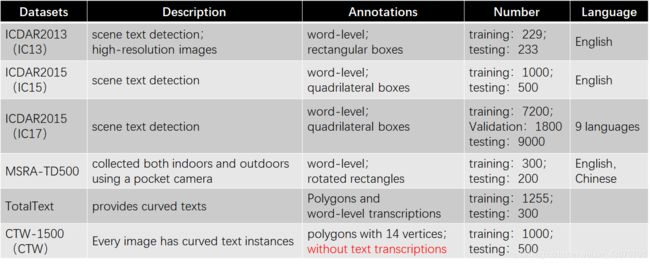
CTW-1500数据集只含有多边形标注但是没有文本转录,且只有行级标注,不提供空格作为分隔符,这和我们所假设的 字符中间有空格的affinity score得分为零相去甚远。
因此为了得到单一多边形(即一行文字用一个多边形框出来),使用了一个浅层网络进行连接细化,如下图:
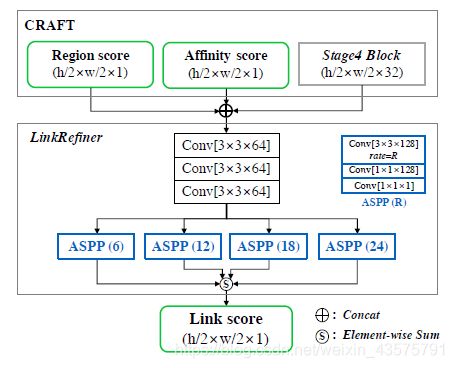
这个网络是将CRAFT产生的the region score and the affinity score以及stage4产生的特征作为输入,ASPP确保大的感受野,将距离远的字符和单词组合到同一文本行上,输出Link score ,并用Link score 替换 affinity score
这里,CRAFT的作用是定位单个字符,LinkRefiner的作用是结合字符以及由空格分开的单词。
效果如图:

Discussions & Conclusion
Robustness to Scale Variance: 相对小的感受野足以覆盖大图像中的单个字符,在检测尺度不同的文本时具有鲁棒性
Multi-language issue:孟加拉文字和阿拉伯文字比较潦草,且合成数据集里面没有,故不能很好分开这两种字符
Generalization ability:泛化能力很好
CRAFT通过the character region score and the character affinity score的结合,检测各种形状的文本;弱监督的学习方式解决了真实数据集字符级标注少的问题
搜了两张孟加拉文字和阿拉伯文字的图片,如下:


模型测试效果如下:
