停止使用C#异步流保存到磁盘
目录
这些是什么?
晦涩的语言功能:认识真实世界
将内容捕获为流?
异步消费
异步限制
又一陷阱
结论
我用一个新的语言特性解决一个困难的性能问题的旅程:异步流。解释什么是异步流,并展示了它们可以解决的现实世界问题。
最近我遇到了一个有趣的性能挑战,最终将3小时的工作减少到1.5小时,这要归功于最近的C#语言增强功能:异步流。哇,所以2019年我听到你说。我敢肯定您已经阅读了一些标题并浏览了一些博客文章,但是您真的了解这项技术及其含义吗?我没有。在这篇文章中,我将快速解释什么是异步流,描述它们帮助我解决了哪些现实世界的问题,并展示了一些常见的陷阱,以防您遇到类似的情况。
这些是什么?
简而言之,异步流是C# 8中引入的一种语言功能,它允许您以异步方式处理数据流。对,很明显。一个例子会有所帮助。
IAsyncEnumerable numbers = Producer.GetNumbersAsync();
await foreach (var number in numbers)
{
if (number > 10) break;
} 上面我们检索了一组IAsyncEnumerable类型的数字(C# 8中引入的接口),并使用await foreach(C# 8中也引入的新语言功能)迭代其中的前10个。
这里的奇特之处在于,循环的每次迭代都有一个隐藏的等待,它创建一个延续并将控制权返回给调用者,直到数据提供者有一个新的数字要提供。将控制权返回给调用者通常是C# 5中引入的await所做的。它释放了主机来刷新移动应用程序的UI或响应HTTP请求。IAsyncEnumerable的新功能是当谈到可枚举时, await现在是一等公民。
如果您在ILSpy中打开前面示例中的代码,您可以看到它是如何工作的。如果您反编译并将其视为C# 8之前的版本(ILSpy在这种情况下非常棒)。
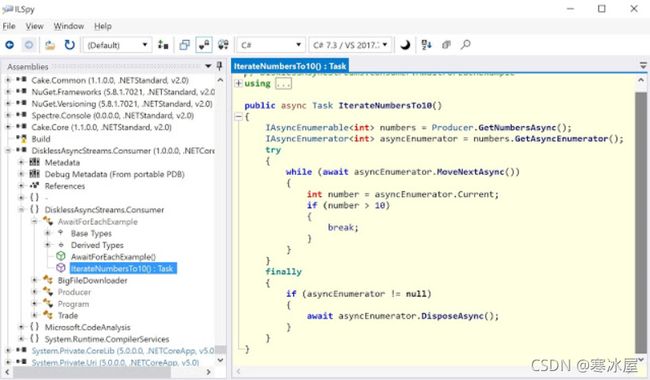
然后你最终得到这个:
IAsyncEnumerable numbers = Producer.GetNumbersAsync();
IAsyncEnumerator asyncEnumerator = numbers.GetAsyncEnumerator();
try
{
while (await asyncEnumerator.MoveNextAsync())
{
int number = asyncEnumerator.Current;
if (number > 10)
{
break;
}
}
}
finally
{
if (asyncEnumerator != null)
{
await asyncEnumerator.DisposeAsync();
}
} 现在您可以清楚地看到IAsyncEnumerable的工作原理几乎与IEnumerable对它的.MoveNext和.Current方法所做的完全一样。除了三件事:
- 方法名称后缀为Async
- 一切都是基于任务的
- 正在进行一些额外的清理工作
有趣,但如何有用还有待观察。
晦涩的语言功能:认识真实世界
在我的项目中,我们需要每天下载和处理大文件。想想60 Gig CSV文件。从技术上讲,它们是60 Gig BSON文件。如果它们是CSV,它们会更大。无论如何,关键是我们需要读取和处理大量数据,而且速度很慢。这需要几个小时。这是一个问题,因为数据需要在一天中的某个时间准备好,如果出现问题,我们必须重新开始。所以我们只得到了几个镜头,更糟糕的是:未来这个客户的数据会变得更大。我们需要找到性能优化。
现在,从历史上看,我们分几个步骤处理这个过程,例如:
- 下载文件
- 读取和处理文件(使用Task Parallel Library中的DataFlow,如果你不熟悉它,你应该放下一切去学习)
- 将结果(仅约90兆)插入数据库
这很简单,但总的来说这三个步骤花了2个多小时。下载:~40分钟。阅读和处理:~1.5小时。插入:~10分钟。
该团队花了很多时间集思广益地解决性能问题。但是有一件事情让我对这个过程感到不安。也许重新阅读要点,看看是否有任何内容站得住脚。
答:为什么我们要保存到磁盘并从磁盘读取?!理论上这就是流存在的原因。我们应该能够下载数据并将其处理成90兆,并且根本不会命中磁盘。对?!
此外,该IO听起来很慢,但这是另一回事。
将内容捕获为流?
但是我不知道异步流是否可以应用于通过HTTP下载大文件。首先,团队一直在下载BSON中的zip文件。我需要将数据作为流消耗,所以压缩是正确的。最终证明将BSON作为流使用是可行的,但后来才出现,超出了本文的范围。因此,第一遍解压缩了CSV。
幸运的是,有一种方法可以在数据提供者的API中指定我们想要解压缩的CSV内容。这会增加下载时间,但我打赌我们会在处理过程中弥补它,因为磁盘似乎是一个瓶颈。
接下来我很好奇TCP数据包是否根据请求立即启动并在换行边界处中断。重要的?不确定,虽然它确实为博客文章制作了一张好照片。
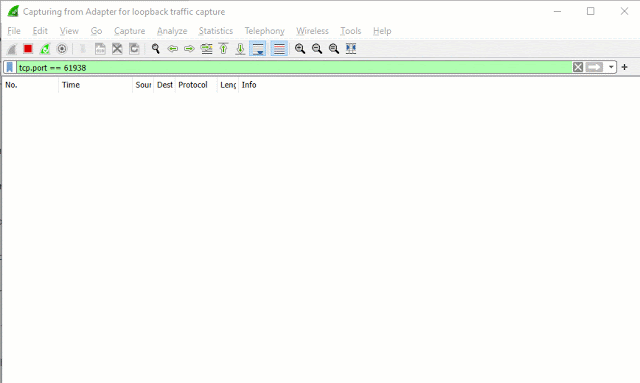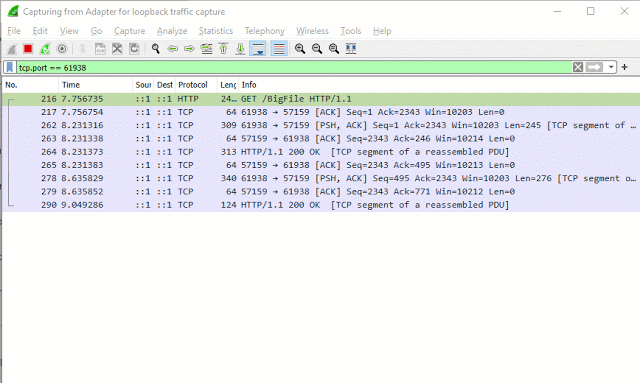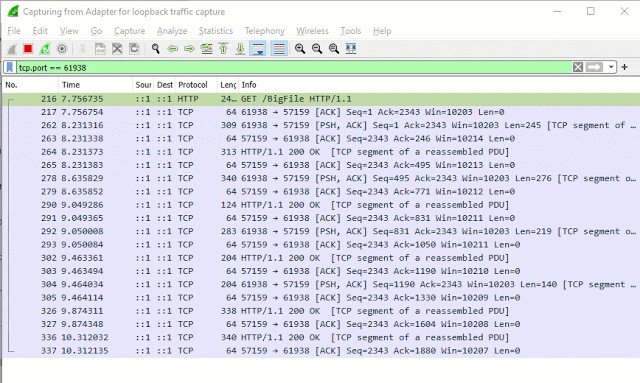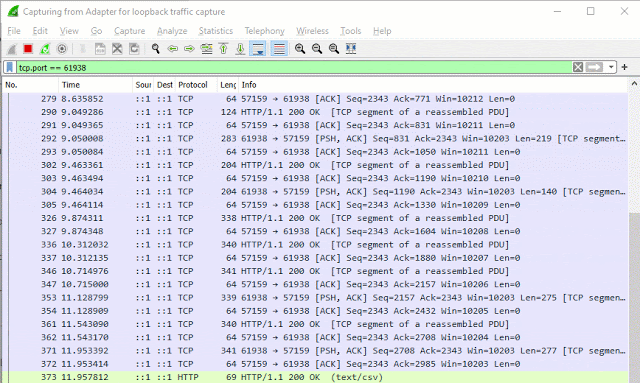
Wireshark数据包如下所示:

换句话说,这是一个数据包:
`U0(ñòßGAäwÆMP'Û10d
2021-06-26T23:24:45,10.79
2021-06-26T23:24:53,97.83
2021-06-26T23:25:01,86.53
2021-06-26T23:25:09,3.83
2021-06-26T23:25:17,39.38
2021-06-26T23:25:25,37.94
2021-06-26T23:25:33,31.59
2021-06-26T23:25:41,12.55
2021-06-26T23:25:49,74.67
2021-06-26T23:25:57,95.25顶部有一些随机元数据,但以换行符结尾。
顺便说一下,这实际上是我构建的一个应用程序的结果,该应用程序是为了这篇博文的目的来模拟我们的实际数据提供者。它被称为DisklessAsynchronousStreams(也许不要试图说快10倍)。如果您想更详细地探索这篇文章的代码,它是开源的。
异步消费
再回到这一点,我很快就学会了拉异步数据没有写入到磁盘中的重要法宝是在HttpClient上调用GetAsync()或SendAsync()时设置HttpCompletionOption.ResponseHeadersRead标志。这告诉编译器只在收到头文件之前阻塞,然后继续执行。然后可以在数据仍在下载时调用ReadLineAsync()。进一步来说:
using var response = await httpClient.GetAsync(
uri, HttpCompletionOption.ResponseHeadersRead);
response.EnsureSuccessStatusCode();
await using var stream = await response.Content.ReadAsStreamAsync();
using var streamReader = new StreamReader(stream, Encoding.UTF8);
while (!streamReader.EndOfStream)
{
var line = await streamReader.ReadLineAsync();
var trade = GetTradeFromLine(rowNum, line);
yield return trade;
}上面的代码有效,但只是因为C# 8。在C# 8之前,返回类型需要是async Task
The return type of an async method must be void, Task, Task
使用C# 8和IAsyncEnumerable的简单解决方案是返回IAsyncEnumerable,然后可以使用async foreach使用它。
private async IAsyncEnumerable StreamReadLines()
{
...
} ps 如果你对yield的工作原理不满意,请查看System.Linq.Where()的真正工作原理
异步限制
这是一个有趣的错误,猜猜它是什么意思:
类型:System.IO.IOException
消息:无法从传输连接读取数据:远程主机强行关闭了现有连接。
内部异常:
类型:System.Net.Sockets.SocketError
SocketErrorCode : 连接重置
消息:现有连接被远程主机强行关闭。
堆栈跟踪:
...
在System.IO.StreamReader.d__67.MoveNext()
System.IO.StreamReader.d__59.MoveNext
如果您说远程主机关闭了我们的连接,恭喜您可以阅读,但遗憾的是,事实并非如此。实际问题是消费者超出了缓冲区(这发生在我们中最好的人身上),然后.NET欺骗了我们,这让我们感到难过。
当消费者从生产者读取数据太慢时就会出现问题。基本上,如果数据进入的速度比我们处理它的速度快,那么有人需要将该数据保存在特定大小的内存插槽中,最终数据将超过插槽的大小。
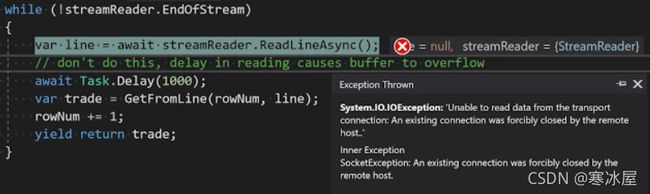
有趣的是,您可以通过在HttpClient上设置较小的MaxResponseContentBufferSizeon值使其更快发生。不幸的是,您不能设置MaxResponseContentBufferSize超过2 Gig的默认大小。因此,请确保在主消息处理循环中不要做任何缓慢的事情。
又一陷阱
不要指望消费者在Fiddler打开的情况下成功地异步传输读取数据。Fiddler非常适合观察常规的HTTP流量,但它在转发之前将整个请求分批处理,接下来你知道你浪费了30分钟试图弄清楚为什么你不能在一个重复的项目上复制你的生产环境,同时写一篇博客文章。注意我的警告:不要成为那个人。
结论
太好了,所以我停止将数据保存到磁盘,但大大增加了我的下载大小。它值得吗?幸运的是,我很高兴地发现批处理时间减少了50%。此外,它消耗更少的内存和CPU以及电力和冷却成本。您的结果可能会有所不同。
说起来:这段代码更难维护,所以要谨慎使用。但是无磁盘异步流是一项很好的技术,您可以了解是否找到了正确的问题。
https://www.codeproject.com/Articles/5307011/Stop-Saving-to-Disk-with-Csharp-Asynchronous-Strea