【JVM】Java虚拟机
本文主要介绍了JVM的内存区域划分,类加载机制以及垃圾回收机制.
其实JVM的初心,就是让java程序员不需要去了解JVM的细节,它把很多工作内部封装好了.但是学习JVM的内部原理有利于我们深入理解学习Java.
1.JVM的内存区域划分
JVM其实是一个java进程 ; 每个java进程,就是一个jvm的实例
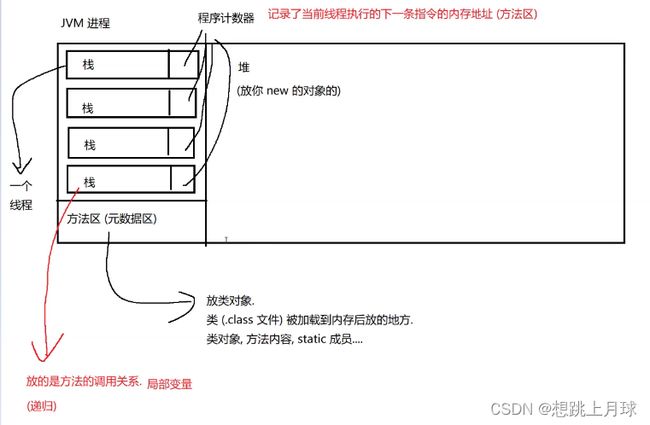
JVM的内存区域划分
| 堆 |
放new的对象 |
| 方法区(元数据区) |
放类对象,类(.class文件),方法内容,static成员 |
| 栈 |
放方法的调用关系 , 局部变量 |
注意:
栈空间和程序计数器,是每个线程有一份.(每个线程都有一个独立的执行逻辑)
面试题:给一段代码,问某个变量在哪个内存区域中

2.JVM类加载机制
类加载:Java程序最开始写的是一个.java文件,编程成.class文件.运行java程序的时候,JVM会读取.class文件,把文件的内容放到内存中,并且构造成.class对象(类对象) . 也就是把类从硬盘文件中,加载到内存中.
类加载的大致过程
1.加载
找到.class文件,打开文件,读取文件内容,并且尝试解析格式
2.验证
检查当前的.class文件的格式是否符合要求.
3.准备
给类对象分配内存
最终的目的是构造出完成的类对象,分配存在+初始化
4.解析
主要是初始化类对象中涉及到的一些字符串常量
字符串常量在.class文件本身就已经存在,直接读到内存中.
此处是将字符串的符合引用(偏移位置)替换为直接引用/真实的内存地址的过程
5.初始化
对类对象进行更具体地初始化操作,初始化静态成员,执行静态代码块,加载父类.
双亲委派模型
描述了类加载过程中,如何找.class文件
JVM中加载.class文件,需要用到类加载器模块 . JVM中自带了三个类加载器 .
Bootstrap ClassLoader
负责加载标准库的类. Java有一个标准文档,描述了都要提供的类
Extension ClassLoader
负责加载JVM扩展的库. 除了标准库之外,实现JVM的厂商,还会再添加一些类
Application ClassLoader
负责加载第三方库. 比如mysql jdbc driver / servlet / jackson
关系
第一个是第二个的父亲
第二个是第三个的父亲
此处的父子不是子类继承父类.而是对象里有一个parent引用指向父类加载器实例.
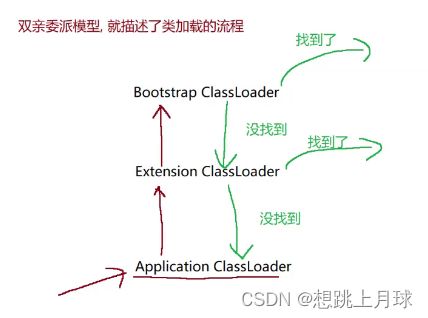
流程:
1.从Application ClassLoader开始
不会立即搜索第三方库的目录,而是先把加载任务委派给父亲,让父亲尝试加载
2.到了Extension ClassLoader
也不会立即就搜索到扩展库的目录,也是把加载任务委派给父亲.也让父亲先尝试加载
3.到了Bootstrap ClassLoader
也不会立即标准库,而是也想把任务委派给父亲,但是bootstrap ClassLoader没有父亲,就只能自己动手搜索类了.
目的:明确优先级.
标准库的类最优先加载 - >扩展库其次 -> 第三方库最低.
比如:
标准库中有一个java.lang.String , 自己写的代码中也有一个java.lang.String
JVM始终都是先加载标准库,而不会加载自己写的类, 避免程序员的代码,对标准库的代码产生负面影响.
一个类,什么时候会被加载
懒汉模式 ---- 用到才加载.
1.构造类的实例
2.使用了类的静态方法/静态属性
3.子类的加载会触发父类
类加载之后,后续使用就不必加载了.
类卸载
把对象干掉
一般情况下,不会考虑卸载,一直会保持到程序运行结束
热补丁(重启服务器)
有时候代码有bug,正常操作是修改代码,重新编译,新版本替带旧版本,重启服务器
冷不丁(不用重启服务器)
有些情况,不方便重启,就可以打补丁,通过一些方法把旧版本的类给卸载掉,直接用加载好的新的类替换,不重启服务器,也可以更新代码 .
3.垃圾回收 GC
C语言通过malloc申请的内存需要程序员手动释放,这当然是非常不靠谱的做法.而Java引入垃圾回收机制,可以自动的判定某个内存是否会继续使用;如果不会,就会把这个内存当成垃圾,自己把垃圾释放掉.再Java的影响下,后续的python/Go/PHP/Ruby大部分语言都采取了垃圾回收方式来释放内存.
而c++由于希望和C兼容还有对性能的追求,并没有引入垃圾回收机制.
引入GC机制就会引入额外的系统开销,并且还会可能影响程序效率.
可幸的是,Java中的GC已经优化多年,对于效率的影响已经越来越小了.
回收什么?
对于Java 来说,垃圾回收,回收的其实是对象,而不是字节
JVM中有好几个内存区域,GC回收的是哪里的对象
- 占空间不需要GC对象,栈里面包含很多栈帧,每个栈帧对应一个方法,该方法执行结束,此时这个栈帧就销毁了,栈帧上的局部变量自然销毁
- 每个栈帧都有的程序计数器/线程销毁,自然也销毁.
- 方法区:类对象很少会涉及到对象的卸载
- 堆:GC的主战场.
步骤
垃圾回收分两步:
1.判定对象是否是垃圾
垃圾:如果一个对象在后续代码中,不会被继续使用到了; Java中如果没有任何引用指向它,那它就是垃圾了 .
(在Java中,使用一个对象的唯一途径是:声明一个引用指向它,然后再通过引用访问对象)
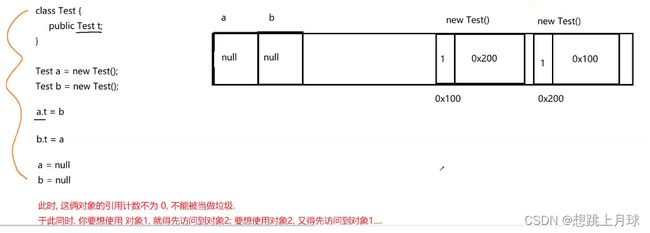
引用计数
思路1:引用计数(Python/PHP的虚拟机的GC使用的是该方法)
给对象内部安排一个计数器,每次有引用指向它,计数器+1;每次引用被销毁,计数器-1 ;
当计数器为0,意味着对象就是垃圾.
这种方案的缺陷:
1.空间利用率低,浪费更多的内存空间
每个对象都要一块空间来存储引用计数.
2.可能存在循环引用的问题. 导致对象不能被正确地识别.
可达性分析
思路2(Java使用)
JVM首先会从现有代码中的能直接访问到的引用(栈上的局部变量/常量池里的引用/方法区里的静态成员)出发,尝试遍历所有能访问到的对象.
只要对象能访问到,就会标记成"可达",完成整个遍历之后,可达之外的对象,也就是"不可达",
也就相当于是垃圾了.
gc roots进行这样的扫描 :
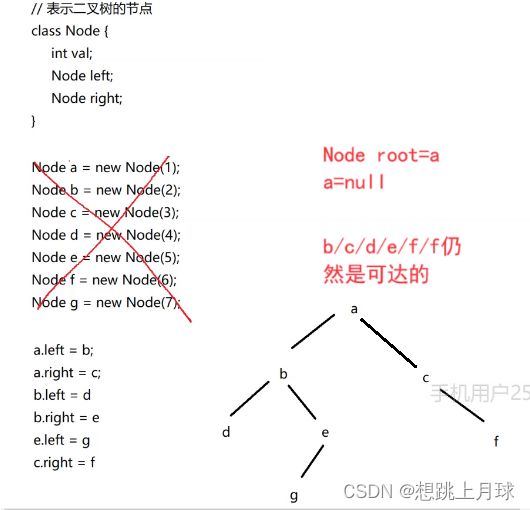
这个遍历的过程就是可达性分析.
和引用计数不同,引用计数消耗的是空间;而可达性分析,消耗的是时间,并不会引入额外的空间开销,但是进行上述的遍历,需要消耗时间.
由于一个对象是否是垃圾,往往是动态变化的.因此可达性分析是周期性的
2.释放对象
如何清理垃圾/释放对象
1.标记清楚 (直接释放)
直接释放对象,就会引起内存碎片
由于申请内存的时候,都是连续的的内存空间;如果释放,就可能会破坏原有的连续性,导致有内存,但是申请不了.
内存碎片随着程序的运行越来越多,越来越碎,内存就更难申请了.
2.复制算法
复制算法,通过冗余的内存空间,把有效对象复制到另一部分空间,来避免内存碎片

把一个内存分成两份,用一份,丢一份;
把左侧区域中有效的对象复制到右侧,接下来就可以使用右侧区域;
等右侧产生的很多碎片,再将对象复制到左侧,右边空间统一释放 ; 来回利用
缺陷:如果复制的内容很多,开销大;空间利用率也不高.
3.标记整理
类似于顺序表删除元素,搬运元素

缺陷:搬运成本高.
上述三种方法都有各自的缺陷
JVM采取的方法是在不同的场景下,使用不同的回收方式.
对象可以分为两类,一类是生命周期比较长的,一类是生命周期比较短的 ; 生命短的经历gc扫描的次数就少 ,生命长的经历gc扫描的次数就多 . 我们就可以将这两种对象放在不同的区域内,根据他们的特点使用不用的方法解决内存碎片问题 .
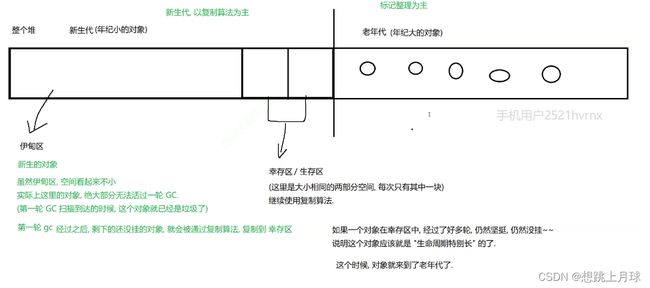
- 新生代 : 每一轮gc留下的对象比较少, 复制开销不大, 以复制算法为主
- 老年代 : 出现回收的概率比较低,此时搬运的开销不大. 以标记整理为主
- 特殊情况: 如果对象体积特别大,就会直接进入老年带(大对象不适合进行复制算法)