OCR快速入门(二)| Python版

点击关注我哦

一篇文章带你了解OCR | Python版
方法与策略
如上所示,文本识别主要是一个分两步的任务。首先,需要检测图像中的文本外观,它可能是密集的(如打印文档中的)或稀疏的。
在检测到行/字级别之后,我们可以再次从大量的解决方案中进行选择,这些解决方案通常来自三种主要方法:
1.经典的计算机视觉技术。
2.专业的深度学习。
3.标准深度学习方法(检测)。
下面我们来分析一下这三种方法:
1. 经典的计算机视觉技术
如前所述,计算机视觉在很长一段时间内解决了各种文本识别问题。你可以在网上找到很多例子:
· 在 Great Adrian Rosebrook 的网站上有大量的教程,比如下面这个链接:
https://www.pyimagesearch.com/2017/07/17/credit-card-ocr-with-opencv-and-python/
· Stack overflow上也有一些类似的教程,比如下面这个链接:https://stackoverflow.com/questions/9413216/simple-digit-recognition-ocr-in-opencv-python
传统的计算机视觉的方法通常有如下步骤:
1. 使用过滤器使字符从背景中脱颖而出
2. 应用轮廓检测对字符进行逐一分割
3. 应用图像分类识别字符
显然,如果第二部分做得好,则通过模式匹配或机器学习(例如Mnist)可以轻松实现第三部分。
然而,轮廓检测是一个具有挑战性的泛化问题。它需要大量的手动微调,因此在大多数问题中变得不可行。让我们从这里对来自 SVHN 数据集(https://scikit-image.org/docs/dev/auto_examples/segmentation/plot_label.html#sphx-glr-download-auto-examples-segmentation-plot-label-py)的一些图像应用一个简单的计算机视觉脚本。一开始我们可能会取得非常好的结果:


但是当字符之间的距离越来越近时,事情就开始变得不一样了:


我发现很难解决的问题是,当你开始弄乱参数时,可以减少此类错误,但不幸的是会导致其他错误。换句话说,如果你的任务不简单,这些方法就不可行。
2. 专业的深度学习方法
大多数成功的深度学习方法都具有通用性。然而,考虑到上面描述的属性,专业化网络可能是非常有用的。
下面将介绍一些主要方法,并对提供这些方法的文章做一个简要的总结。
EAST
EAST (高效准确的场景文本检测器)是一种简单而有效的文本检测方法。
与我们将要讨论的其他方法不同,它仅限于文本检测(而不是实际的识别) ,但是它的鲁棒性使它值得一提。另一个优点是,它还被添加到 OpenCV 库(第四版)中,因此您可以非常方便地使用它(参见这里的教程https://www.pyimagesearch.com/2018/08/20/opencv-text-detection-east-text-detector/)。这个网络实际上是著名的 U-Net 的一个版本,它可以很好地检测大小不同的特征。这个网络的底层前馈“stem”(见下图),在本文中使用的是PVANet,而 opencv中的实现使用 的是Resnet。显然,它也可以预先训练(使用 imageet 等)。和 U-Net 一样,在网络中从不同层次提取特征。

最后,网络允许两种类型的输出旋转包围盒: 一种是具有旋转角度(2X2 + 1参数)的标准包围盒,另一种是仅仅具有所有顶点坐标的旋转包围盒。

如果真实生活的结果和上面的图片一样,那么识别文本并不需要太多的努力。然而,现实生活中的结果并不完美。
CRNN
卷积递归神经网络,是2015年的一篇文章,它提出了一种混合端到端的体系结构,即用三步方法捕获单词。
它的思路是这样的: 第一层是一个标准的完全卷积网络。网络的最后一层被定义为特征层,并分为“特征列”。请参阅下面的图片,看看每一个这样的特征栏是如何用来表示文本中的某一部分的。

然后,将特征列输入一个深度双向 LSTM,该 LSTM 输出一个序列,用于查找字符之间的关系。

最后,第三部分是转录层。它的目标是采取杂乱的字符序列,其中一些字符是冗余的,另一些字符是空白的,并使用概率方法统一和理解它。
这种方法称为CTC损失,如果你相对它有更深入的了解,可以访问下面的链接:https://gab41.lab41.org/speech-recognition-you-down-with-ctc-8d3b558943f0
该层可以使用/不使用预定义的词典,虽然它可能有助于预测单词。
本文使用固定的文本词典,准确率高达95% 以上,没有固定的词典,准确率也会发生变化。
STN-net/SEE
半监督式端到端场景文本识别是Christian Bartzi的作品。他和他的同事们采用了一种真正的端到端策略来检测和识别文本。他们使用非常薄弱的监督(他们称之为半监督,与通常的含义不同)。因为它们只使用文本注释(没有边界框)来训练网络。这使他们可以使用更多数据,但使他们的训练过程充满挑战,并且他们讨论了使之起作用的不同技巧,例如,不训练多于两行文本的图像(至少在训练的第一阶段)。
这篇论文有一个早期版本,叫做STN-OCR。在最后一篇论文中,研究者们改进了他们的方法和表现形式,而且由于结果的高质量,他们更加强调他们方法的普遍性。

STN-OCR 这个名字暗示了使用空间转换器的策略(= STN,与最近的 google 转换器无关)。
它们训练两个串联的网络,其中第一个网络,即变换器,学习图像的变换,以输出更容易解释的子图像。
然后,另一个带有LSTM的前馈网络来识别文本。
研究人员在这里强调了使用resnet的重要性(他们使用了两次),因为它为前面的层提供了“强大”的传播。当然,这种做法现在已被广泛接受。
不管怎样,这都是一个值得一试的有趣的方法。
3. 标准的深度学习方法
如题所示,在检测到“单词”之后,我们可以应用标准的深度学习检测方法,如SSD、YOLO和Mask-RCNN。由于网上有大量信息,因此我将不对这些方法进行过多的阐述。
我必须说这是当前我最喜欢的方法,因为我在深度学习中喜欢的是“端到端”的思想,可以在其中应用一个强大的模型,并进行一些调整可以解决几乎所有问题。在本文的下一部分,我们将看到它是如何实际工作的。
但是,正如本文所述,SSD和其他检测模型在涉及密集的相似类时面临挑战。我觉得这有点讽刺,因为事实上,深度学习模型发现识别数字和字母要比识别更具挑战性和复杂的物体(例如狗,猫或人)困难得多。它们往往无法达到所需的精度,因此,专业的方法蓬勃发展。
实例
所以说了这么多之后,是时候上手做一些实践了。我们将尝试处理SVHN任务。SVHN数据包含三个不同的数据集:train、test和extra。这些差异并不是100%清楚,但是最大的extra数据集(大约50万个样本)包含了更容易识别的图像。因此我们将使用它。
首先我们需要以下准备工作:
· 你需要一个GPU显卡,并配置TensorFlow>=1.4,Keras>=2.0
· 从此处克隆SSD_Keras项目
· 从此处下载关于coco数据集上的预训练的SSD300模型
· 从此处拷贝项目工程
· 下载extra.tar.gz文件,其中包含SVHN数据集的其他图像
· 更新项目中json_config.json文件中的所有相关路径
要有效地执行此过程,需要仔细阅读项目资料库中的ssd_OCR.ipynb笔记。
现在让我们开始吧!
1.解析数据
不管喜欢与否,但是在检测任务中没有标准格式的数据表示形式。一些众所周知的格式是:coco,via,pascal,xml等等。SVHN数据集使用晦涩的.mat格式。但幸运的是,它提供了一个read_process_h5脚本,可以将.mat文件转换为标准json,当然我们要进一步将它转为pascal格式,代码如下所示:
def json_to_pascal(json, filename): #filename is the .mat file # convert json to pascal and save as csv pascal_list = [] for i in json: for j in range(len(i['labels'])): pascal_list.append({'fname': i['filename'] ,'xmin': int(i['left'][j]), 'xmax': int(i['left'][j]+i['width'][j]) ,'ymin': int(i['top'][j]), 'ymax': int(i['top'][j]+i['height'][j]) ,'class_id': int(i['labels'][j])}) df_pascal = pd.DataFrame(pascal_list,dtype='str') df_pascal.to_csv(filename,index=False)p = read_process_h5(file_path)json_to_pascal(p, data_folder+'pascal.csv')
现在我们已经有了一个标准的pascal.csv文件,可以继续进行下一步了。如果转换速度很慢,应该注意,我们不需要所有的数据样本。大约一万个就够了。
2.查看数据
在开始建模之前,我们最好查看一下数据,对它的构成有个大概的了解。下面只提供了一个简单的快速测试功能,小编建议您进行更深度分析哦~
def viz_random_image(df): file = np.random.choice(df.fname) im = skimage.io.imread(data_folder+file) annots = df[df.fname==file].iterrows() plt.figure(figsize=(6,6)) plt.imshow(im) current_axis = plt.gca() for box in annots: label = box[1]['class_id'] current_axis.add_patch(plt.Rectangle( (box[1]['xmin'], box[1]['ymin']), box[1]['xmax']-box[1]['xmin'], box[1]['ymax']-box[1]['ymin'], color='blue', fill=False, linewidth=2)) current_axis.text(box[1]['xmin'], box[1]['ymin'], label, size='x-large', color='white', bbox={'facecolor':'blue', 'alpha':1.0}) plt.show()viz_random_image(df)

对于以下步骤,我在项目中提供了一个utils_ssd.py,它有助于训练,减轻权重等。其中一些代码参考了SSD_Keras项目。
3.算法选择
如前所述,我们有许多解决此问题的方法。本教程将采用标准的深度学习检测方法,并将使用SSD检测模型。具体实现是采用的PierreLuigi的SSD keras。当然YOLO模型和Mask RCNN也是不错的选择。
4.训练SSD模型
导入库与定义变量
我们需要确定是否下载了改项目,并且设置好json_config.json中的路径。
首先是导入库:
import osimport sysimport skimage.ioimport scipyimport jsonwith open('json_config.json') as f: json_conf = json.load(f)ROOT_DIR = os.path.abspath(json_conf['ssd_folder']) # add here mask RCNN pathsys.path.append(ROOT_DIR)
import cv2from utils_ssd import *import pandas as pdfrom PIL import Image
from matplotlib import pyplot as plt
%matplotlib inline%load_ext autoreload% autoreload 2
然后是一些定义:
task = 'svhn'labels_path = f'{data_folder}pascal.csv'input_format = ['class_id','image_name','xmax','xmin','ymax','ymin' ] df = pd.read_csv(labels_path)
模型配置:
class SVHN_Config(Config): batch_size = 8 dataset_folder = data_folder task = task labels_path = labels_path
input_format = input_format
conf=SVHN_Config()
resize = Resize(height=conf.img_height, width=conf.img_width)trans = [resize]
定义模型,加载权重
与大多数深度学习案例一样,我们不会从头开始训练,但会加载预先训练的权重。在这种情况下,我们将加载以COCO数据集为训练对象的SSD模型权重,该模型具有80个类别。显然,我们的任务只有10个类,因此在加载权重之后,我们将重构顶层以具有正确数量的输出。我们在init_weights函数中执行此操作。
定义数据加载器
5.训练模型
现在模型已经准备好了,我们将设置一些与最后训练相关的定义,并开始训练
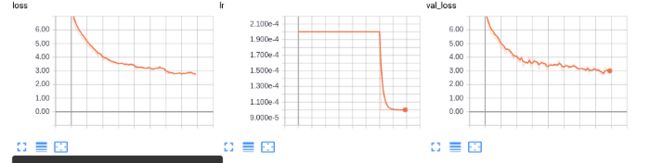
learner.init_training()history = learner.train(train_generator, val_generator, steps=100,epochs=80)
另外,我在训练脚本中加入了training_plot回调,可在每个epoch后可视化一个随机图像。例如,以下是第六个epoch之后的预测图像:

这个SSD_Keras资料库几乎在每个epoch后都会保存一次模型,所以你只需将weights_destinamtion_path这行改成相等路径进行加载模型即可。
weights_destination_path =
根据我们的步骤就可以顺利的训练模型。ssd_keras提供了更多功能,例如数据扩充,不同的加载程序和评估程序。经过短暂的训练,我达到了大于80的mAP。
你达到了多少呢?
概要
在本文中,我们讨论了OCR领域中的不同挑战和方法。深度学习/计算机视觉中有许多问题,它比起初看起来具有更多的意义。我们已经看到了它的许多子任务,以及解决它的一些不同方法,但它们目前都不是灵丹妙药。另一方面,我们已经看到要取得初步结果并不难,没有太多麻烦。
· END ·
HAPPY LIFE
