20源代码模型的数据增强方法:克隆检测、缺陷检测和修复、代码摘要、代码搜索、代码补全、代码翻译、代码问答、问题分类、方法名称预测和类型预测对论文进行分组【网安AIGC专题11.15】
Data Augmentation Approaches for Source Code Models: A Survey
- 写在最前面
-
- 对nlp领域其他方向的启发
-
- 英文版:
- 论文名片
- 论文总结
- 一个有意思的表
- 1.背景Background
-
- 1.1什么是源代码模型?What are source code models?
- 1.2什么是数据增强?What is data augmentation?
- 1.3数据增强如何在源代码中工作?How does data augmentation work in source code?
-
- 挑战Challenges
- 常见的方法Common approach
- 2.源代码模型的数据增强方法Data Augmentation Methods for Source Code Models
-
- 2.1基于规则的技术Rule-based Techniques
-
- (1)程序的基本语法Basic program syntax
- (2)更深层次的结构信息Deeper structure information
- (3)增强自然语言语境Augmenting the natural language context
- 2.2基于模型的技术Model-based Techniques
-
- (1)利用现有模型Utilization of existing models
- (2)针对源代码模型专门设计的模型Specifically designed models for source code models
- 2.3插值技术示例Example Interpolation Techniques
- 2.3插值技术示例Example Interpolation Techniques
- 3.优化数据分析质量的策略与技术Strategies and Techniques to Optimize the DA Quality
-
- 3.1方法堆叠Method Stacking
- 3.2优化Optimization
-
- (1)概率选择Probabilistic Selection
- (2)基于模型的选择Model-based Selection
- (3)基于规则的选择Rule-based Selection
- 4.将数据处理应用于源代码的场景Scenarios for Applying DA to Source Code
-
- 4.1鲁棒性的对抗性示例Adversarial Examples for Robustness
- 4.2低资源域Low-Resource Domains
- 4.3检索增强Retrieval Augmentation
- 4.4对比学习Contrastive Learning
- 5.将数据处理应用于源代码的下游任务Downstream Tasks for Applying DA to Source Code
-
- 5.1代码作者归属Code Authorship Attribution
- 5.2克隆检测Clone Detection
- 5.3缺陷检测Defect Detection
- 5.4代码汇总Code Summarization
- 5.5查找代码Code Search
- 5.6代码完成Code Completion
- 5.7代码翻译Code Translation
- 5.8代码问答Code Question Answering (CQA)
- 5.9代码分类Code Classification
- 5.10方法名称预测Method Name Prediction
- 5.11类型预测Type Prediction
- 6.挑战与机遇Challenges and Opportunities
-
- 6.1理论讨论 Discussion on theory
- 6.2对预训练模型的进一步研究 More study on pre-trained models
- 6.3处理特定于领域的数据 Working with domain-specific data
- 6.4对项目级源代码和低资源编程语言的更多探索 More exploration on project-level source code and low-resource programming languages
- 6.5缓解社会偏见 Mitigating social bias
- 6.6少射学习 Few-shot learning
- 6.7缺乏统一性Lack of unification
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
一位同学分享了Data Augmentation Approaches for Source Code Models: A Survey
《源代码模型的数据增强方法:综述》
全英文PPT,又学了很多专业术语
英文排版好好看,感觉这位同学是直接阅读的英文文献,然后根据论文做的PPT
希望三年 争取一年内,我也能直接阅读(所在领域的)英文文献,然后吸收转化
论文:https://arxiv.org/pdf/2305.19915.pdf
代码:https://github.com/terryyz/DataAug4Code
感觉很有意思,或许可以直接去读一下

“据我们所知,我们的论文构成了第一个全面的调查,提供了对源代码模型的数据处理技术的深入研究。”
“To the best of our awareness, our paper constitutes the first comprehensive survey offering an in-depth examination of DA techniques for source code models.”

对nlp领域其他方向的启发
这篇论文的调查,通过展示源代码模型中的先进技术和新应用,强调了语言模型中上下文、鲁棒性和适应性的重要性。以下是一些要点:
-
理解复杂结构:正如调查在源代码中探索更深层次的结构信息一样,可以从复杂语言结构的增强分析中受益。用于分析复杂源代码结构的技术,可以用于理解自然语言中
细微的语法和句法元素。 -
增强上下文分析:该调查的重点是增强源代码中的自然语言上下文,这可以提高对对话、文学文本或细微语言使用中的
语境的理解。 -
利用预训练模型:探索利用源代码的现有模型可以反映在NLP中,可以集中在如何对预训练的语言模型(如GPT或BERT)进行微调或调整以适应特定的语言任务或语言。
-
方法叠加和优化:调查中关于方法叠加和优化的讨论,以创新的方式结合多种方法(如
标记化、语义分析等)来提高模型性能。 -
对抗性示例和鲁棒性:
对抗性示例在源代码模型中的鲁棒性应用可以启发NLP中的类似方法,以创建更健壮和有弹性的语言模型,特别是针对不断发展的语言模式和对抗性攻击。 -
低资源语言关注:该调查对源代码中低资源领域的关注,可以更多地
关注低资源语言,开发技术来增强数据稀疏的语言模型。 -
对比学习:将调查中的对比学习应用于NLP,可以更好地
消除歧义并理解语言使用中的细微差异和相似性,从而增强情感分析或文本分类等任务。 -
减轻社会偏见:源代码模型中减轻社会偏见的重点直接适用于NLP,探索如何使语言模型
更加公平,减少偏见,确保公平和公正的语言理解。 -
探索Few-Shot Learning:受该调查的启发,NLP可以深入研究
Few-Shot Learning技术,以构建从有限数据中有效学习的模型,这对于稀有语言或特定语言现象至关重要。 -
跨学科应用:该调查在源代码中数据增强的各种应用可以激励NLP研究人员寻求跨学科应用,例如法律文本分析,文学研究或跨语言理解。
英文版:
This survey, by showcasing advanced techniques and novel applications in source code models, emphasizing the importance of context, robustness, and adaptability in language models.Here are some key takeaways:
-
Understanding Complex Structures: Just as the survey explores deeper structure information in source code, NLP can benefit from enhanced analysis of complex linguistic structures. Techniques used for analyzing intricate source code structures could be adapted to understand nuanced grammatical and syntactic elements in natural language.
-
Augmenting Contextual Analysis: The survey’s focus on augmenting the natural language context in source code can inspire NLP researchers to develop more sophisticated context-aware models. This could improve the understanding of context in conversations, literary texts, or nuanced language use.
-
Leveraging Pre-Trained Models: The exploration of utilizing existing models for source code can be mirrored in NLP. Research can focus on how pre-trained language models (like GPT or BERT) can be fine-tuned or adapted for specific linguistic tasks or languages.
-
Method Stacking and Optimization: The survey’s discussion on method stacking and optimization can encourage NLP researchers to combine multiple methodologies (like tokenization, semantic analysis, etc.) in innovative ways to enhance model performance.
-
Adversarial Examples and Robustness: The application of adversarial examples for robustness in source code models can inspire similar approaches in NLP to create more robust and resilient language models, especially against evolving linguistic patterns and adversarial attacks.
-
Low-Resource Language Focus: The survey’s attention to low-resource domains in source code could encourage NLP researchers to focus more on low-resource languages, developing techniques to enhance language models where there is sparse data.
-
Contrastive Learning: Applying contrastive learning from the survey to NLP can lead to better disambiguation and understanding of subtle differences and similarities in language usage, enhancing tasks like sentiment analysis or text classification.
-
Mitigating Social Bias: The focus on mitigating social bias in source code models is directly applicable to NLP. Research can explore how language models can be made more equitable and less biased, ensuring fair and unbiased language understanding.
-
Exploring Few-Shot Learning: Inspired by the survey, NLP can delve into few-shot learning techniques to build models that learn effectively from limited data, which is crucial for rare languages or specific linguistic phenomena.
-
Cross-Disciplinary Applications: The survey’s diverse applications of data augmentation in source code can inspire NLP researchers to seek cross-disciplinary applications, such as in legal text analysis, literary studies, or cross-lingual understanding.
论文名片
- 发现数据增强的力量:深入源代码模型中数据增强的变革世界。
- 公布的技术:探索基于规则、基于模型和创新的插值方法。
- 实际应用:了解这些技术如何在代码完成、缺陷检测等现实场景中应用。
- 未来方向:发现在推进源代码分析和增强方面的挑战和机遇。
英文版:
- Discover the Power of Data Augmentation: Dive into the transformative world of data augmentation in source code models.
- Techniques Unveiled: Explore rule-based, model-based, and innovative interpolation methods.
- Practical Applications: Learn how these techniques are applied in real-world scenarios like code completion, defect detection, and more.
- Future Directions: Uncover the challenges and opportunities in advancing source code analysis and augmentation.
论文总结
本文在源代码的背景下全面分析了数据增强技术。
The paper comprehensively analyzes data augmentation techniques in the context of source code.
本文首先阐述了数据增强的概念及其作用。
The paper first explains the concept of data augmentation and its function.
然后,本文考察了源代码研究中常用的主要数据增强方法,并探讨了典型源代码应用程序和任务的增强方法。
The paper then examines the primary data augmentation methods commonly employed in source code research and explores augmentation approaches for typical source code applications and tasks.
最后,本文总结了当前该领域面临的挑战,并提出了未来源代码研究的潜在方向。
Finally, the paper conclude by outlining the current challenges in the field and suggesting potential directions for future source code research.
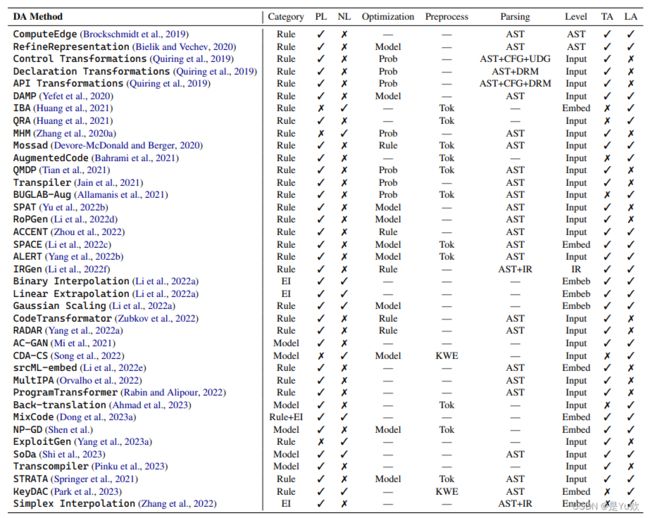
一个有意思的表
Table 1: Comparing a selection of DA methods by various aspects relating to their applicability, dependencies,and requirements. PL, NL, TA, LA, EI, Prob, Tok, and KWE stand for Programming Language, Natural Language,Example Interpolation, Probability, Tokenization, Keyword Extraction, Task-Agnostic, and Language-Agnostic.
PL and NL determine if the DA method is applied to the programming language or natural language context. Preprocess denotes preprocessing required besides the program parsing.
Parsing refers to the type of feature used by the DA method during program parsing. Level denotes the depth at which data is modified by the DA.
TA and LA represent whether the DA method can be applied to different tasks or programming languages. As most papers do not clearly state if their DA methods are TA and LA, we subjectively denote the applicability.
(见下表)PL、NL、TA、LA、EI、Prob、Tok和KWE分别代表:编程语言、自然语言、样例插值、概率、标记化、关键字提取、任务不可知论和语言不可知论。
PL和NL 确定数据处理方法是应用于编程语言还是应用于自然语言上下文。
预处理 是指除程序解析外,还需要进行的预处理。
解析 是指DA方法在程序解析过程中使用的特征类型。
级别 表示数据处理对数据进行修改的深度。
TA和LA 表示数据分析方法是否可以应用于不同的任务或编程语言。
由于大多数论文没有明确说明他们的数据分析方法是TA还是LA,我们主观地表示适用性。
| 缩写 (Abbreviation) | 英文全称 (English Full Form) | 中文全称 (Chinese Full Form) |
|---|---|---|
| PL | Programming Language | 编程语言 |
| NL | Natural Language | 自然语言 |
| TA | Example Interpolation, Probability | 样例插值、概率 |
| LA | Tokenization, Keyword Extraction | 标记化、关键字提取 |
| EI | Task Agnostic | 任务不可知论 |
| Prob | Probabilistic | 概率 |
| Tok | Tokenization | 标记化 |
| KWE | Keyword Extraction | 关键字提取 |
表1:通过与它们的适用性、依赖性和需求相关的各个方面来比较数据处理方法的选择。
1.背景Background

1.1什么是源代码模型?What are source code models?
源代码模型 是在大规模的源代码语料库上训练的,因此能够对给定代码片段的上下文表示进行建模。
Source code models are trained on large-scale corpora of source code and therefore able to model the contextual representations of given code snippets.
1.2什么是数据增强?What is data augmentation?
数据增强(Data augmentation, DA)技术 旨在通过数据合成来增加训练样本的多样性,从而提高模型在各个方面的性能(例如,准确性和鲁棒性)。
Data augmentation (DA) techniques aim to improve the model’s performance in terms of various aspects (e.g., accuracy and robustness) via increasing training example diversity with data synthesis.
1.3数据增强如何在源代码中工作?How does data augmentation work in source code?

挑战Challenges
与图像和纯文本相比,由于严格的编程语法规则的性质,源代码在扩展方面不太灵活。
Compared to images and plain texts, source code is less flexible to be augmented due to the nature of strict programming syntactic rules.
源代码的数据分析方法应该保留原始代码片段的功能和语法,以便能够成功编译增强的代码片段。
DA approaches for source code should preserve the functionality and syntax of the original code snippets so that the enhanced code snippets can be successfully compiled.
常见的方法Common approach
使用解析器从代码构建具体的语法树,并进一步将其转换为抽象语法树(AST),以简化表示,但保留关键信息。
Use a parser to build a concrete syntax tree from the code, and further transform it into an abstract syntax tree (AST) to simplify the representation but maintain the key information.
2.源代码模型的数据增强方法Data Augmentation Methods for Source Code Models
2.1基于规则的技术Rule-based Techniques
大量的数据分析方法利用预先确定的规则在不破坏语法规则和语义的情况下对程序进行转换。
A large number of DA methods utilize predetermined rules to transform the programs without breaking syntax rules and semantics.
具体地说,这些规则主要隐式地利用ast来转换代码片段。
Specifically, these rules mainly implicitly leverage ASTs to transform the code snippets.
(1)程序的基本语法Basic program syntax
(2)更深层次的结构信息Deeper structural information
(3)增强自然语言语境 Augmenting the natural language context
原文就是高糊版本的

(1)程序的基本语法Basic program syntax
-
MHM是一种在代码段中迭代重命名标识符的方法。
MHM is a method of iteratively renaming identifiers in the code snippets.
作为生成对抗性训练示例的方法,MHM极大地提高了源代码模型的鲁棒性。
Considered as the approach to generate examples for adversarial training, MHM greatly improves the robustness of source code models. -
Srikant等人认为
程序混淆是一种对抗性扰动,他们重命名程序变量,试图向读者隐藏程序的意图。
Srikant et al. considerprogram obfuscationsasadversarial perturbations, where they rename program variables in an attempt tohide the program’s intentfrom a reader.
通过将这些扰动样例应用到训练阶段,源代码模型对对抗性攻击变得更加健壮。
By applying these perturbed examples to the training stage, the source code models become more robust to the adversarial attack. -
BUGLABAug包含了更多的规则,同时强调了编程语言和自然语言,如注释删除、比较表达式镜像和if-else分支交换。
BUGLABAug contains more rules, emphasizing both the programming language and natural language, such as comment deletion, comparison expression mirroring, and if-else branch swapping.
对BUGLABAug的评估表明,DA方法可以用于自我监督的错误检测和修复。
The evaluation on BUGLABAug demonstrates that DA methods can be exploited for self-supervised bug detection and repair. -
ranspiler使用编译器转换作为数据增强,自动生成等效函数的数据集。
Transpiler uses compiler transforms as data augmentation, automatically generating a dataset of equivalent functions.
具体来说,它们通过利用程序的ast定义了11个编译器转换。
Specifically, they define 11 compiler transforms by exploiting ASTs of the programs.
(2)更深层次的结构信息Deeper structure information
通过AST和控制流图(CGF)、使用定义链(UDG)和声明引用映射(DRM)的组合实现的三种不同的增强方案
Three different augmentation schemes via the combination of AST and control-flow graph (CGF) and use-define chains (UDG) and declaration-reference mapping (DRM)
-
控制转换Control Transformations
控制转换重写控制流语句或修改函数之间的控制流。
Control Transformations rewrite control-flow statements or modifies the control flow between functions.
此转换包括将变量作为函数参数传递、更新其值以及更改调用方和被调用方的控制流。
This transformation involves passing variables as function arguments, updating their values, and changing the control flow of the caller and callee. -
声明转换Declaration Transformations
声明转换由14个转换器组成,它们修改、添加或删除源代码中的声明。
Declaration Transformations consist of 14 transformers that modify, add or remove declarations in source code.
声明转换使得数据处理必须更新变量的所有用法,这可以使用DRM表示优雅地执行。
Declaration Transformations make DA necessary to update all usages of variables which can be elegantly carried out using the DRM representation. -
API转换API Transformations
API转换利用了可以使用各种API来解决相同问题的事实。
API Transformations exploits the fact that various APIs can be used to solve the same problem.
众所周知,程序员喜欢不同的API,因此篡改API的使用是改变风格模式的有效策略。
Programmers are known to favor different APIs and thus tampering with API usage is an effective strategy for changing stylistic patterns.
(3)增强自然语言语境Augmenting the natural language context
-
QRA通过在执行代码搜索和代码问答时重写自然语言查询来增强示例。
QRA augments examples by rewriting natural language queries when performing code search and code question answering.
它通过基于规则的小修改重写查询,这些修改与原始查询共享相同的语义。
It rewrites queries with minor rule-based modifications that share the same semantics as the original one.
具体来说,它包括三种方式:随机删除一个单词,随机交换两个单词的位置,随机复制一个单词。
Specifically, it consists of three ways: randomly deleting a word, randomly switching the position of two words, and randomly copying a word. -
KeyDAC扩展了自然语言和编程语言,重点放在查询关键字上。
KeyDAC augments on both natural language and programming language with an emphasis on the query keywords.
对于自然语言查询,它遵循QRA中的规则,但只修改非关键字。
For natural language query, it follows the rules in QRA but only modifies non-keywords.
在编程语言增强方面,KeyDAC只是使用ast来重命名程序变量。
In terms of programming language augmentation, KeyDAC simply uses ASTs to rename program variables.
2.2基于模型的技术Model-based Techniques
基于模型的技术的目标是训练各种模型来增强数据。
Model-based techniques target training various models to augment data.
-
现有模型的利用Utilization of existing models
-
专门为源代码模型设计的模型Specifically designed models for source code models
(1)利用现有模型Utilization of existing models
-
Mi等人利用辅助分类器生成对抗网络(ACGAN) (Odena等人)来生成增强程序。
Mi et al. utilize Auxiliary Classifier Generative Adversarial Networks (ACGAN) (Odena et al.) to generate augmented programs… -
为了增加代码总结的训练数据,CDA-CS (Song等人)使用预训练的BERT模型(Devlin等人)替换代码注释中非关键字的同义词,这有利于源代码下游任务。
In order to increase the training data for code summarization, CDA-CS (Song et al.) uses the pre-trained BERT model (Devlin et al.) to replace synonyms for non-keywords in code comments, which benefits the source code downstream tasks.
(2)针对源代码模型专门设计的模型Specifically designed models for source code models
-
IRGen是一种基于遗传算法的模型,使用编译器中间表示(LLVM IR)来增强源代码嵌入,其中IRGen将一段源代码生成一系列语义相同但语法不同的IR代码,以提高模型的上下文理解。
IRGen is a genetic-algorithm-based model using compiler intermediate representation (LLVM IR) to augment source code embeddings, where IRGen generates a piece of source code into a range of semantically identical but syntactically distinct IR codes for improving model’s contextual understanding. -
反翻译是面向无监督编程语言翻译的多语言生成源代码模型。
Back-translation is the multilingual generative source code models for unsupervised programming language translation.
与自然语言处理不同,这里的反向翻译被定义为通过自然语言作为中间语言在两种编程语言之间进行翻译。
Unlike the one in NLP, Back-translation here is defined as translating between two programming languages via the natural language as an intermediate language. -
Transcoder是一种生成源代码模型,用于执行源到源的翻译,以增加跨语言源代码。
Transcoder is a generative source code model to perform source-to-source translation for augmenting cross-language source code.
2.3插值技术示例Example Interpolation Techniques
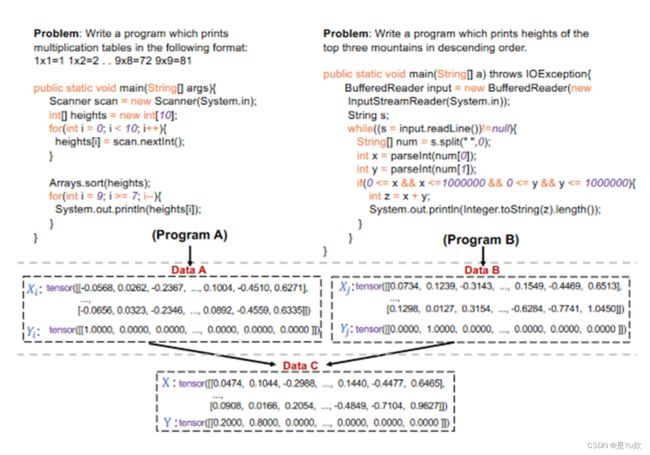
混合包括插入两个或多个实际示例的输入和标签。
Mixup involves interpolating the inputs and labels of two or more actual examples.
这样的方法很难部署在源代码领域,因为每个代码片段都受到其独特的程序语法和功能的限制。
Such methods are hard to be deployed in the realm of source code, as each code snippet is constrained by its unique program grammar and functionality.
通过模型嵌入将多个真实示例融合到单个输入中
fusing multiple real examples into a single input via model embeddings
2.3插值技术示例Example Interpolation Techniques
-
Dong等人将源代码模型的基于规则的技术与Mixup合并,通过线性插值混合原始代码片段的表示及其转换。
Dong et al. merge rule-based techniques for source code models with Mixup to blend the representations of the original code snippet and its transformation via linear interpolation. -
二值插值作为一种数据增强策略,它可以使用从伯努利分布中获得的元素在样本之间互换特征。
Binary Interpolation serves as a data augmentation strategy, which interchangeably swaps features between samples using elements acquired from a Bernoulli distribution. -
线性外推是另一种数据增强方法,它根据均匀分布扩展当前特征,从而在现有特征空间之外生成新的数据点。
Linear Extrapolation is another data augmentation approach that generates new data points beyond the existing feature space by extending current features in accordance with a uniform distribution.
3.优化数据分析质量的策略与技术Strategies and Techniques to Optimize the DA Quality
3.1方法堆叠
3.1 Method Stacking
3.2优化
3.2 Optimization
3.1方法堆叠Method Stacking
方法叠加是不同数据增强方法的组合。
Method stacking is the combination of different data augmentation methods.
通常,这种组合包含两种类型:相同类型的数据处理或不同数据处理方法的混合。
Typically, the combination entails two types: same-type DA or a mixture of different DA methods.
-
Mi等人使用AC-GAN将基于规则的代码转换方案与基于模型的数据处理相结合,创建了用于模型训练的增强语料库。
Mi et al. combined rule-based code transformation schemes with model-based DA using AC-GAN to create an augmented corpus for model training. -
CDACS包含两种数据分析技术:基于规则的非关键字提取和基于模型的非关键字替换。
CDACS encompasses two kinds of DA techniques: rule-based non-keyword extraction and model-based non-keyword replacement. -
Chen和lamouras的经验证据表明,结合反向翻译和变量重命名可以提高代码完成性能。
Empirical evidence from Chen and Lampouras shows that combining Back-translation and variable renaming can result in improved code completion performance.
3.2优化Optimization
在某些场景中,例如增强鲁棒性和最小化计算成本,最佳地选择特定的增强示例候选者是至关重要的。
In certain scenarios such as enhancing robustness and minimizing computational cost, optimally selecting specific augmented example candidates is crucial.
在数据分析中,我们把这种面向目标的候选选择称为优化。
We denote such goal-oriented candidate selections in DA as optimization.
(1)概率选择Probabilistic Selection
(2)基于模型的选择Model-based Selection
(3)基于规则的选择Rule-based Selection
(1)概率选择Probabilistic Selection
-
MHM采用马尔可夫链蒙特卡罗技术,通过标识符替换来选择对抗样本。
MHM adopts the Markov Chain Monte Carlo technique, to choose adversarial examples via identifier replacement. -
QMDP使用Q-learning方法在源代码上策略性地选择和执行基于规则的结构转换,从而指导对抗性示例的生成。
QMDP uses a Q-learning approach to strategically select and execute rule-based structural transformations on the source code, thereby guiding the generation of adversarial examples. -
在BUGLABAug中,Allamanis等人模拟了在类似于指针网络的代码片段中的某个位置应用特定重写规则的概率。
In BUGLABAug, Allamanis et al. model the probability of applying a specific rewrite rule at a location in a code snippet similar to the pointer net.
(2)基于模型的选择Model-based Selection
-
DAMP方法是一种象征性的方法,它基于模型损失进行优化,通过变量重命名来选择和生成对抗样本。
DAMP method is an emblematic approach, which optimizes based on the model loss to select and generate adversarial examples via variable renaming. -
SPACE通过梯度上升对代码标识符的嵌入进行选择和扰动,旨在最大限度地提高模型的性能影响,同时保持编程语言的语义和语法正确性。
SPACE performs selection and perturbation of code identifiers’ embeddings via gradient ascent, targeting to maximize the model’s performance impact while upholding semantic and grammatical correctness of the programming language. -
ALERT在其基于梯度的选择策略中使用遗传算法。
ALERT uses a genetic algorithm in its gradient-based selection strategy.
它在计算模型置信度差的适应度函数的指导下,迭代地进化候选解的种群,旨在识别最有效的对抗性示例。
It evolves a population of candidate solutions iteratively, guided by a fitness function that calculates the model’s confidence difference, aiming to identify the most potent adversarial examples.
(3)基于规则的选择Rule-based Selection
-
IRGen利用基于遗传算法的优化技术和基于IR相似度的适应度函数。
IRGen utilizes a Genetic-Algorithm based optimization technique with a fitness function based on IR similarity. -
ACCENT和RADAR分别应用BLEUand CodeBLEU等评估指标来指导选择和替换过程,旨在实现最大的对抗影响。
ACCENT and RADAR apply evaluation metrics such as BLEUand CodeBLEU respectively to guide the selection and replacement process, aiming for maximum adversarial impact. -
STRATA采用基于规则的技术来选择影响较大的子令牌,这些子令牌可以显著改变模型对代码的解释。
STRATA employs a rule-based technique to select high-impact subtokens that significantly alter the model’s interpretation of the code.
4.将数据处理应用于源代码的场景Scenarios for Applying DA to Source Code

4.1鲁棒性的对抗性示例Adversarial Examples for Robustness
健壮性是软件工程中一个关键而复杂的维度,需要创建语义保守的对抗性示例来识别和减轻源代码模型中的漏洞。
Robustness presents a critical and complex dimension of software engineering, necessitating the creation of semantically-conserved adversarial examples to discern and mitigate vulnerabilities within source code models.
- 几项研究Several studies(Yefet et al., 2020;Li et al., 2022d;Srikant et al.;Li et al., 2022c;Anand et al.;Henke et al., 2022) have utilized rule-based DA methods for testing and enhancing model robustness.进一步巩固了普遍接受的代码转换规则,以建立源代码模型鲁棒性的基准。
- Wang et al. (2023) have gone a step further to consolidate universally accepted code transformation rules to establish a benchmark for source code model robustness.
4.2低资源域Low-Resource Domains
在软件工程领域,编程语言资源严重失衡。
In the domain of software engineering, the resources of programming languages are severely imbalanced.
由于源代码模型是在开源存储库和论坛上训练的,编程语言资源的不平衡会对资源稀缺的编程语言的性能产生不利影响。
As source code models are trained on open-source repositories and forums, the programming language resource imbalance can adversely impact their performance on the resource-scarce programming languages.
-
为了在低资源领域增加用于表示学习的数据,Li等人(2022f)倾向于通过释放编译器IR的力量来增加更多的训练数据以增强源代码模型嵌入。
In order to increase data in the low-resource domain for representation learning, Li et al. (2022f) tend to add more training data to enhance source code model embeddings by unleashing the power of compiler IR. -
Ahmad等人(2023)考虑到低资源编程语言的情况,提出使用源代码模型执行反翻译数据分析。
Ahmad et al. (2023) propose to use source code models to perform Backtranslation DA, taking into consideration the scenario of low-resource programming languages. -
与此同时,Chen和lamouras(2023)强调了一个事实,即源代码数据集明显小于它们的NLP等效数据集,后者通常包含数百万个实例。
Meanwhile, Chen and Lampouras (2023) underscore the fact that source code datasets are markedly smaller than their NLP equivalents, which often encompass millions of instances.
因此,他们开始调查这种环境下的代码完成任务,并尝试反向翻译和变量重命名。
As a result, they commence investigations into code completion tasks under this context and experiment with Back-translation and variable renaming. -
Shen等人认为Bash注释的生成受到训练数据缺乏的阻碍,因此探索了基于模型的数据处理方法来完成这项任务。
Shen et al. contend that the generation of Bash comments is hampered by a dearth of training data and thus explore model-based DA methods for this task.
4.3检索增强Retrieval Augmentation
源代码模型的检索增强框架在预训练或微调源代码模型时包含了来自训练集的检索增强示例。
The retrieval augmentation frameworks for source code models incorporate retrieval-augmented examples from the training set when pre-training or fine-tuning source code models.
- 在各种源代码下游任务中,如代码汇总It is shown as a promising application of DA in various source code downstream tasks, such as code summarization (Zhang et al., 2020b;Liu et al.;Yu et al., 2022a), 代码完成code completion (Parvez et al., 2021) and 程序修复program repair (Nashid et al., 2023).
4.4对比学习Contrastive Learning
对比学习使模型能够学习到一个相似样本距离较近而不同样本距离较远的嵌入空间。
Contrastive learning enables models to learn an embedding space in which similar samples are close to each other while dissimilar ones are far apart.
由于训练数据集通常包含有限的正样本集,因此DA方法更倾向于构建与正样本相似的样本。
As the training datasets commonly contain limited sets of positive samples, DA methods are preferred to construct similar samples as the positive ones.
-
Liu等人(2023b)利用数据挖掘的对比学习为源代码模型设计了优越的预训练范例。
Liu et al. (2023b) make use of contrastive learning with DA to devise superior pre-training paradigms for source code models. -
一些作品研究了该应用程序在一些源代码任务中的优势Some works study the advantages of this application in some source code tasks,
如缺陷检测defect detection(Cheng et al., 2022),克隆检测clone detection(Zubkov et al., 2022;Wang et al., 2022a)和代码检索code search(Shi et al., 2022b, 2023;Li et al., 2022b).
5.将数据处理应用于源代码的下游任务Downstream Tasks for Applying DA to Source Code

5.1代码作者归属Code Authorship Attribution
代码作者归属是识别给定代码作者的过程,通常通过源代码模型实现。
Code authorship attribution is the process of identifying the author of a given code, usually achieved by source code models.
- Yang等人(2022b)最初研究在谷歌代码阻塞(GCJ)数据集上生成对抗性示例,该数据集有效地欺骗源代码模型以识别给定代码片段的错误作者。
Yang et al. (2022b) initially investigate generating adversarial examples on the Google Code Jam (GCJ) dataset, which effectively fools source code models to identify the wrong author of a given code snippet.
通过这些增广样例的训练,可以进一步提高模型的鲁棒性。
By training with these augmented examples, the model’s robustness can be further improved.
5.2克隆检测Clone Detection
代码克隆检测是指识别给定的代码片段是否从原始样本中克隆和修改的任务,在某些情况下可称为剽窃检测。
Code clone detection refers to the task of identifying if the given code snippet is cloned and modified from the original sample, and can be called plagiarism detection in some cases.
-
Jain等人(2021)提出了通过编译器信息生成具有训练样本同等功能的许多变体的构造正确数据挖掘,并展示了其在BigCloneBench和自收集的JavaScript数据集上提高模型鲁棒性的有效性。
Jain et al. (2021) propose correct-by-construction DA via compiler information to generate many variants with equivalent functionality of the training sample and show its effectiveness of improving the model robustness on BigCloneBench and a self-collected JavaScript dataset. -
Jia等人(2023)表明,通过混淆变换对对抗样本进行训练时,可以显著提高源代码模型的鲁棒性。
Jia et al. (2023) show that when training with adversarial examples via obfuscation transformation, the robustness of source code models can be significantly improved. -
Zubkov等人(2022)提供了多个对比学习的比较,并结合了克隆检测任务的基于规则的转换。
Zubkov et al. (2022) provide the comparison of multiple contrastive learning, combined with rule-based transformations for the clone detection task. -
Pinku等人(2023)后来使用Transcompiler在有限的Python和Java源代码之间进行翻译,从而增加了跨语言代码克隆检测的训练数据。
Pinku et al. (2023) later use Transcompiler to translate between limited source code in Python and Java and therefore increase the training data for cross-language code clone detection.
5.3缺陷检测Defect Detection
缺陷检测,换句话说,缺陷或漏洞检测,是捕获给定代码片段中的缺陷。
Defect Detection, in other words, bug or vulnerability detection, is to capture the bugs in given code snippets.
该任务可以被视为二元分类任务,其中标签为真或假。
The task can be considered as the binary classification task, where the labels are either true or false.
-
Allamanis等人(2021)实现了BUGLAB-Aug,这是一个自我监督的错误检测和修复的数据数据框架。
Allamanis et al. (2021) implement BUGLAB-Aug, a DA framework of self-supervised bug detection and repair.
BUGLAB-Aug有两套代码转换规则,一套是bug诱导重写,另一套是DA重写。
BUGLAB-Aug has two sets of code transformation rules, one is a bug-inducing rewrite and the other one is rewriting as DA.
他们的方法同时提高了源代码模型的性能和健壮性。
Their approach boosts the performance and robustness of source code models simultaneously. -
Cheng等人(2022)提出了一种名为ContraFlow的路径敏感代码嵌入技术,该技术使用自监督对比学习来检测基于价值流路径的缺陷。
Cheng et al. (2022) present a path-sensitive code embedding technique called ContraFlow, which uses self-supervised contrastive learning to detect defects based on value-flow paths.
ContraFlow利用数据分析生成三个数据集(即D2A、Fan和FFMPeg+Qemu)的对比价值流表示,以了解程序之间的(非)相似性。
ContraFlow utilizes DA to generate contrastive value-flow representations of three datasets (namely D2A , Fan and FFMPeg+Qemu) to learn the (dis)similarity among programs. -
Ding等人(2021)提出了一种新的自监督模型,专注于识别(不)相似的源代码功能。
Ding et al. (2021) present a novel self-supervised model focusing on identifying (dis)similar functionalities of source code.
具体来说,他们设计了代码转换启发式来自动创建有缺陷的程序和类似的代码来增加预训练数据。
Specifically, they design code transformation heuristics to automatically create bugged programs and similar code for augmenting pre-training data.
5.4代码汇总Code Summarization
代码摘要被认为是为一段源代码生成注释的任务,因此也被称为代码注释生成。
Code summarization is considered as a task that generates a comment for a piece of the source code, and is thus also named code comment generation.
-
(Zhang et al., 2020c)将MHM应用于扰动训练样例,并与原始训练样例混合进行对抗性训练,有效提高了源代码模型在总结对抗性代码片段方面的鲁棒性。
(Zhang et al., 2020c) apply MHM to perturb training examples and mix them with the original ones for adversarial training, which effectively improves the robustness of source code models in summarizing the adversarial code snippets. -
(Zhang et al., 2020b)开发了一种用于代码摘要的检索增强框架,依靠相似的代码摘要对在PCSD和JCSD数据集上生成新的摘要。
(Zhang et al., 2020b) develop a retrieval-augmentation framework for code summarization, relying on similar code-summary pairs to generate the new summary on PCSD and JCSD datasets. -
基于该框架,(Liu et al.)利用Hybrid GNN提出了一种新的检索增强代码摘要方法,并将其用于自收集的CCSD数据集的模型训练。
Based on this framework, (Liu et al.) leverage Hybrid GNN to propose a novel retrieval-augmented code summarization method and use it during model training on the self-collected CCSD dataset.
5.5查找代码Code Search
代码搜索或代码检索是基于给定的自然语言查询搜索代码片段的文本代码任务。
Code search, or code retrieval, is a text-code task that searches code snippets based on the given natural language queries.
此任务上的源代码模型需要将文本的语义映射到源代码。
The source code models on this task need to map the semantics of the text to the source code.
-
Bahrami等人(2021)通过增加自然语言上下文(如文档字符串、代码注释和提交消息)来增加代码搜索查询。
Bahrami et al. (2021) increase the code search queries by augmenting the natural language context such as doc-string, code comments and commit messages. -
Shi等人(2023)引入了软数据增强(SoDa),不需要对代码和文本进行外部转换规则。
Shi et al. (2023) introduce soft data augmentation (SoDa), without external transformation rules on code and text.
使用SoDa,该模型在处理CodeSearchNet时基于动态屏蔽或替换来预测令牌。
With SoDa, the model predicts tokens based on dynamic masking or replacement when processing CodeSearchNet.
5.6代码完成Code Completion
代码完成需要源代码模型生成代码行来完成给定的编程挑战。
Code completion requires source code models to generate lines of code to complete given programming challenges.
-
(Lu et al., 2022)提出了一个由基于规则的DA模块组成的检索增强代码补全框架,用于在PY150和GitHub Java语料库数据集上生成。
(Lu et al., 2022) propose a retrieval-augmented code completion framework composed of the rulebased DA module to generate on PY150 and GitHub Java Corpus datasets. -
Wang等人(2023)专门为文档字符串、函数和变量名、代码语法和代码格式上的代码定制了30多种转换,并在HumanEval和MBPP上对生成源代码模型进行了基准测试。
Wang et al. (2023) customize over 30 transformations specifically for code on docstrings, function and variable names, code syntax, and code format and benchmark generative source code models on HumanEval and MBPP.
5.7代码翻译Code Translation
代码翻译任务是将用特定编程语言编写的源代码翻译成另一种编程语言。
The code translation task is to translate source code written in a specific programming language to another one.
-
Ahmad等人(2023)通过反向翻译应用数据增强来增强无监督代码翻译。
Ahmad et al. (2023) apply data augmentation through Back-Translation to enhance unsupervised code translation.
他们使用预先训练的序列到序列模型将代码翻译成自然语言摘要,然后再转换成不同编程语言的代码。
They use pre-trained sequence-to-sequence models to translate code into natural language summaries and then back into code in a different programming language. -
Chen和lamouras(2023)利用反向翻译和变量增强技术来提高CodeTrans上的代码翻译。
Chen and Lampouras (2023) utilize Back-Translation and variable augmentation techniques to yield the improvement in code translation on CodeTrans .
5.8代码问答Code Question Answering (CQA)
CQA可以表述为一个任务,其中需要源代码模型根据给定的代码片段和问题生成文本答案。
CQA can be formulated as a task where the source code models are required to generate a textual answer based on given a code snippet and a question.
- Li等人(2022c)在CodeQA(一个自由格式的CQA数据集)上探索了基于规则的DA在连续嵌入空间上对抗性训练的效果。
Li et al. (2022c) explore the efficacy of adversarial training on the continuous embedding space with rule-based DA on CodeQA , a free-form CQA dataset.
5.9代码分类Code Classification
代码分类任务根据程序的功能对程序进行分类。
Code classification task performs the categorization of programs regarding their functionality.
-
Zhang等人(2022)结合了单纯形插值,一种基于IR的实例插值数据分析方法,在CodeXGLUE的POJ-104上创建中间嵌入。
Zhang et al. (2022) incorporate simplex interpolation, an example-interpolation DA approach on IR, to create intermediate embeddings on POJ-104 from CodeXGLUE. -
Dong等人(2023a)也探索了示例插值数据分析来融合代码片段的嵌入。
Dong et al. (2023a) also explore the example-interpolation DA to fuse the embeddings of code snippets.
他们在两个数据集JAVA250和Python800上评估该方法。
They evaluate the method on two datasets, JAVA250 and Python800.
5.10方法名称预测Method Name Prediction
方法名称预测的目标是预测给定程序的方法名称。
The goal of method name prediction is to predict the name of a method given the program.
-
Yefet et al.(2020)通过在Code2Seq数据集上使用变量名称替换的对抗程序来攻击和防御源代码模型。
Yefet et al. (2020) attack and defense source code models by using variable-name-replaced adversarial programs on the Code2Seq dataset. -
Pour等人(2021)提出了一个专门针对对抗鲁棒性的基于搜索的测试框架。
Pour et al. (2021) propose a search-based testing framework specifically for adversarial robustness.
他们用Java中广泛使用的10个流行重构操作符生成了Java的对抗性示例。
They generate adversarial examples of Java with ten popular refactoring operators widely used in Java. -
Rabin等人(2021)和Yu等人(2022b)都实现了数据增强框架和各种转换规则,用于在Code2Seq数据集上处理Java源代码。
Rabin et al. (2021) and Yu et al. (2022b) both implement data augmentation frameworks and various transformation rules for processing Java source code on the Code2Seq dataset.
5.11类型预测Type Prediction
类型预测或类型干扰的目的是预测程序中的参数和函数类型。
Type prediction, or type interference, aims to predict parameter and function types in programs.
-
Bielik和Vechev(2020)使用转换ast的示例对源代码模型进行对抗性攻击。
Bielik and Vechev (2020) conduct adversarial attacks on source code models with examples of transformed ASTs.
他们将攻击实例化为JavaScript和TypeScript上的类型预测。
They instantiate the attack to type prediction on JavaScript and TypeScript. -
Jain等人(2021)应用编译器变换在DeepTyper中生成许多程序变体,具有11条规则的等效功能。
Jain et al. (2021) apply compiler transforms to generates many variants of programs in DeepTyper, with equivalent functionality with 11 rules. -
Li等人(2022e)采用srcML元语法嵌入来增强三个数据集(DeepTyper、Typilus Data和CodeSearchNet)中示例的语法特征。
Li et al. (2022e) incorporate srcML meta-grammar embeddings to augment the syntactic features of examples in three datasets, DeepTyper, Typilus Data and CodeSearchNet.
6.挑战与机遇Challenges and Opportunities

6.1理论讨论 Discussion on theory
目前,对源代码中数据处理方法的深入探索和理论认识还存在明显的差距。
Currently, there’s a noticeable gap in the in-depth exploration and theoretical understanding of DA methods in source code.
以前的许多工作都介绍了新的方法或演示了数据处理技术如何有效地用于后续任务。
Much of the previous work introduces new methods or demonstrates how DA techniques can be effective for subsequent tasks.
然而,这些研究往往忽略了为什么和如何特别是从数学的角度来看。
However, these studies often overlook why and how particularly from a mathematical perspective.
我们应该从更广阔的角度来理解数据分析,而不仅仅是看实验结果。
We should understand DA from a broader perspective, not just by looking at experimental results.
6.2对预训练模型的进一步研究 More study on pre-trained models
一个新兴的研究机会在于利用在大量文本和源代码上训练的大型语言模型(llm)来探索数据处理在源代码领域的潜力。
An emergent research opportunity lies in exploring the potential of DA in the source code domain with the help of large language models (LLMs) trained on a large amount of text and source code.
llm具有基于提示指令和提供示例的上下文生成能力,使其成为NLP中自动化数据处理过程的选择。
LLMs have the capability of context generation based on prompted instructions and provided examples, making them a choice to automate the DA process in NLP.
相比之下,对源代码领域中基于提示的数据分析的探索仍然是一个相对未触及的研究领域。
In contrast, the exploration of prompt-based DA in source code domains remains a relatively untouched research area.
6.3处理特定于领域的数据 Working with domain-specific data
我们的调查所涵盖的数据分析方法不能直接推广到API推荐和API序列生成等任务,因为它们中的大多数只针对程序级的增强,而不是API级。
DA methods covered by our survey can not be directly generalized to tasks such as API recommendation and API sequence generation, as most of them only target program-level augmentation but not API-level.
我们观察到这两个不同层之间的数据处理技术的差距,这为未来的工作提供了探索的机会。
We observe a gap of DA techniques between these two different layers, which provides opportunities for future works to explore.
此外,源代码建模并没有完全证明数据分析用于分布外泛化。
Additionally, the source code modeling has not fully justified DA for out-of-distribution generalization.
6.4对项目级源代码和低资源编程语言的更多探索 More exploration on project-level source code and low-resource programming languages
现有的方法已经在函数级代码片段和通用编程语言方面取得了足够的进展。
The existing methods have made sufficient progress in function-level code snippets and common programming languages.
强调功能级别的代码片段无法捕捉到现实场景中编程的复杂性,在现实场景中,开发人员经常同时处理多个文件和文件夹。
The emphasis on code snippets at the function level fails to capture the intricacies and complexities of programming in realworld scenarios, where developers often work with multiple files and folders simultaneously.
因此,我们强调在项目层面探索数据分析方法的重要性。
Therefore, we highlight the importance of exploring DA approaches on the project level.
同时,由于数据资源的限制,低资源语言的扩充方法比较少,但对数据处理的需求比较大。
At the same time, limited by data resources, augmentation methods of low-resource languages are scarce, although they have more demand for DA.
6.5缓解社会偏见 Mitigating social bias
由于源代码模型促进了软件开发,它们可以用于开发以人为中心的应用程序,例如人力资源和教育,在这些应用程序中,有偏见的程序可能会导致对代表性不足的人做出不公正和不道德的决定。
As source code models have advanced software development, they may be used to develop human-centric applications such as human resources and education, where biased programs may result in unjustified and unethical decisions for underrepresented people.
虽然NLP中的社会偏见已经得到了很好的研究,并且可以通过数据处理来减轻,但源代码中的社会偏见尚未引起人们的注意。
While social bias in NLP has been well studied and can be mitigated with DA, the social bias in source code has not been brought to attention.
为了使这些模型在源代码中更负责任,我们敦促对减轻偏见进行更多的研究。
To make these models more responsible in source code, we urge more research on mitigating bias.
6.6少射学习 Few-shot learning
在少数场景下,需要模型达到与传统机器学习模型相媲美的性能,但训练数据的数量非常有限。
In few-shot scenarios, models are required to achieve performance that rivals that of traditional machine learning models, yet the amount of training data is extremely limited.
主流的预训练源代码模型通过语言建模获得丰富的语义知识。
Mainstream pre-trained source code models obtain rich semantic knowledge through language modeling.
传统数据分析方法对预训练源代码模型的改进空间被大大压缩。
The improvement space that traditional DA methods bring to pre-trained source code models has been greatly compressed.
因此,如何在少镜头场景中生成高质量的增强数据,从而为模型提供快速泛化和问题解决能力是一个有趣的问题。
Therefore, it is an interesting question how to provide models with fast generalization and problem-solving capability by generating high-quality augmented data in few-shot scenarios.
6.7缺乏统一性Lack of unification
虽然有广泛接受的用于CV的数据处理框架(例如PyTorch中的默认增强库,RandAugment)和用于NLP的数据处理框架(例如NL-Augmenter),但明显缺乏用于源代码模型的通用数据处理技术的相应库。
Whereas there are well-accepted frameworks for DA for CV (e.g. default augmentation libraries in PyTorch, RandAugment) and DA for NLP (e.g. NL-Augmenter), a corresponding library of generalized DA techniques for source code models is conspicuously absent.
此外,由于现有的数据分析方法通常使用不同的数据集进行评估,因此很难真正确定其疗效。
Furthermore, as existent DA methods are usually evaluated with various datasets, it is hard to truly determine the efficacy.
因此,我们认为,建立标准化和统一的基准任务,以及用于对比和评估不同增强方法有效性的数据集,将极大地促进数据挖掘研究的进展。
Therefore, we posit that the progression of DA research would be greatly facilitated by the establishment of standardized and unified benchmark tasks, along with datasets for the purpose of contrasting and evaluating the effectiveness of different augmentation methods.