LLM大模型 (chatgpt) 在搜索和推荐上的应用
目录
- 1 大模型在搜索的应用
-
- 1.1 召回
-
- 1.1.1 倒排索引
- 1.1.2 倒排索引存在的问题
- 1.1.3 大模型在搜索召回的应用 (实体倒排索引)
- 1.2 排序
-
- 1.2.1 大模型在搜索排序应用(融入LLM实体排序)
- 2 大模型在推荐的应用
-
- 2.1 学术界关于大模型在推荐的研究
- 2.2 推荐存在的一些问题
- 2.3 大模型在推荐的应用 (加强用户实时兴趣识别)
- 3 总结
1 大模型在搜索的应用
1.1 召回
我们知道在搜索中,item的召回主要还是基于关键词召回,但是用户表达与商家对item的描述存在差异导致一些长尾query可能召回很少或者召不回item,虽然现在有语义模型可以减少这种问题出现,但当数据稀疏,训练样本较少的情况下,基于语义向量召回效果也并不好。
那么大模型是不是可以提高召回的效果?答案是可以的,大模型的一个优势就是有多领域知识,可以更好的理解信息。接下来介绍用大模型做基础工作提升召回效果
1.1.1 倒排索引
基于关键词的召回,我们首先要清楚什么是倒排索引,如下图所示:

上述整个流程表示了倒排索引是如何建立的以及ES如何基于倒排索引进行检索。
1.1.2 倒排索引存在的问题
由于用户与商家存在表达差异以及数据噪声等问题,导致基于倒排索引进行召回存在一些问题,假设我们有如下倒排索引数据:
| 索引词 | 文档 |
|---|---|
| 挂面 | 福临门挂面500g*2袋 |
| 面 | 福临门挂面500g*2袋,佰草集白泥面膜组合 |
| 白 | 佰草集白泥面膜组合 |
| … | … |
当用户搜索query=‘白面’,通过切词,可以切分为:"白|面"两个term,从上面倒排索引表可以看出,同时命中“白"和"面“文本是:“佰草集白泥面膜组合”,反而和query相关的文本:“福临门挂面500g*2袋”没能够同时命中这两个term。主要原因是用户表达与商家描述存在差异,同时数据噪声加大了索引建立的复杂性通过语义向量进行召回减少了这种问题,但是需要大量的数据训练模型,才有较好的效果,当数据量不足的时候,效果并不佳。
1.1.3 大模型在搜索召回的应用 (实体倒排索引)
大模型的优势是基于庞大的多类型数据进行学习的,所以有很强的通用知识能力。我们可以基于大模型来优化倒排索引,提升召回的效果。通过大模型对文本生成标准的实体词,比如 {洗面奶,手机,苹果,牛奶,口红,馒头,香蕉,面, 面膜,蛋糕等},基于大模型的理解能力,将文本映射到标准的实体词中,同时对用户输入的query也映射到实体词,这样就可以将query与item的标准实体词建立关联。首先,我们构造好我们的promp,让chatgpt生成我们想要的结果,我们prompt模板可以这么写:
给定如下实体词和文本内容,给出每条文本内容对应的实体词
输出格式:{文本内容:实体词}
实体词:{洗面奶,手机,苹果,牛奶,口红,馒头,香蕉,面, 面膜,蛋糕}
文本内容: {白面, 平安质优 福临门挂面500g*2袋,佰草集白泥面膜组}
然后我们调用chatgpt进行预测,如下所示:
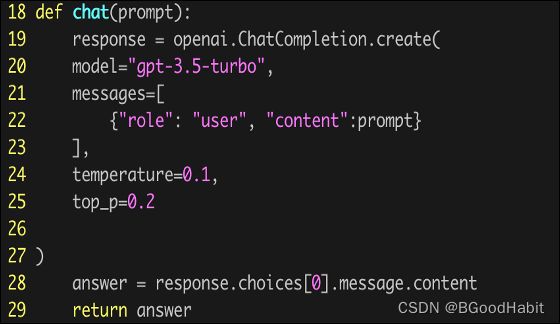
得到的结果如下:
{白面: 面, 平安质优 福临门挂面500g*2袋: 面, 佰草集白泥面膜组合: 面膜}
从测试来看,预测的还是比较准确的。这样,我们可以基于大模型建立标准化的实体索引,索引建立如下:
| 索引词 | 标准化实体索引 | 文档 |
|---|---|---|
| 挂面 | 面 | 福临门挂面500g*2袋 |
| 面 | 面 | 福临门挂面500g*2袋,佰草集白泥面膜组合 |
| 白 | 面膜 | 佰草集白泥面膜组合 |
| … | … | … |
用chatgpt对query和item生成标准实体词,通过实体词建立索引关系,这种方式可以减少用户表达与item信息描述的差异导致召不回或者召不准的问题,索引建立流程图如下所示:

1.2 排序
在搜索中,影响语义排序算法主要有三个核心部分,我们基于双塔模型的结构来讲解,如下所示:

第一部分 (人的特征):在搜索里面,核心是用户搜索的query,还有用户历史行为以及画像等特征
第二部分 (货的特征):这里主要包括货(item)的标题,标签等特征
第三部分 (人与货的关系):主要基于用户行为比如:曝光,点击,转化等反馈数据中建立关系,这也是我们的模型训练样本主要来源。若用户点击了一个item,则这个用户与item的样本label我们就认为是正样本y=1,否则y=0。但是在现实场景中,数据稀疏,数据噪声等问题,导致模型对人与货的匹配学习存在较大的挑战,有可能会犯我们人看来很“低级“的错误,比如用户搜索一个“橙",模型反而将“梨子"相关的item给出的排序分比有“橙子"的item分还高。
1.2.1 大模型在搜索排序应用(融入LLM实体排序)
所以,顺着我们上述部分讲述的大模型在搜索召回层的应用,在排序层我们其实也可以利用大模型的通用知识理解能力,融入大模型的通用知识实体排序,如下图所示:
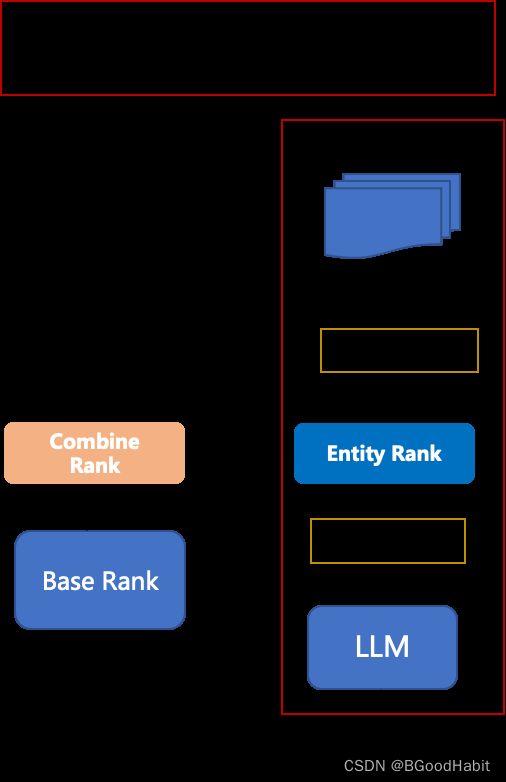
我们可以基于大模型对query与item生成的标准实体进行简单的匹配打分再融合到最终的排序的模型里,融合部分可以简单的进行加权求和得到最终的排序分也可以将大模型对query和item生成的标准实体作为基础排序模型特征输入等。
在这里也尝试了下用大模型生成向量,基于余弦值做相似度分计算,如下是调用chatgpt计算向量相似分代码:
def embedding(content):
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=content
)
embs = response.data[0].embedding
return embs
if __name__=='__main__':
query = '白面'
content_1 ='福临门挂面500g*2袋'
content_2 = '草集白泥面膜组合'
q_emb = np.array(embedding(query))
c1_emb = np.array(embedding(content_1))
c2_emb = np.array(embedding(content_2))
# cos simi
qc1_cos = q_emb.dot(c1_emb) / (np.linalg.norm(q_emb) * np.linalg.norm(c1_emb))
qc2_cos = q_emb.dot(c2_emb) / (np.linalg.norm(q_emb) * np.linalg.norm(c2_emb))
print('query:%s\nitem:%s\n相似度为:%s' % (query, content_1, qc1_cos))
print('query:%s\nitem:%s\n相似度为:%s' % (query, content_2, qc2_cos))
输出结果为:

从结果来看,query=‘白面’与item='草集白泥面膜组合’相似分更高
看来不理想,不过具体openai提供的抽取词向量模型model="text-embedding-ada-002"具体结构是怎样也不是很清楚。
2 大模型在推荐的应用
2.1 学术界关于大模型在推荐的研究
如下是一些大模型在推荐的研究论文:
- Is ChatGPT a Good Recommender? A Preliminary Study
- Uncovering ChatGPT’s Capabilities in Recommender Systems
- LKPNR: LLM and KG for Personalized News Recommendation Framework
- HeterogeneousKnowledgeFusion:ANovelApproachforPersonalized RecommendationviaLLM
- LLM-Rec:Personalized Recommendation via Prompting Large Language Models
- PALR:Personalization Aware LLMs for Recommendation
- …
从上面的一些paper关于大模型在推荐的应用,整体总结如下图所示:
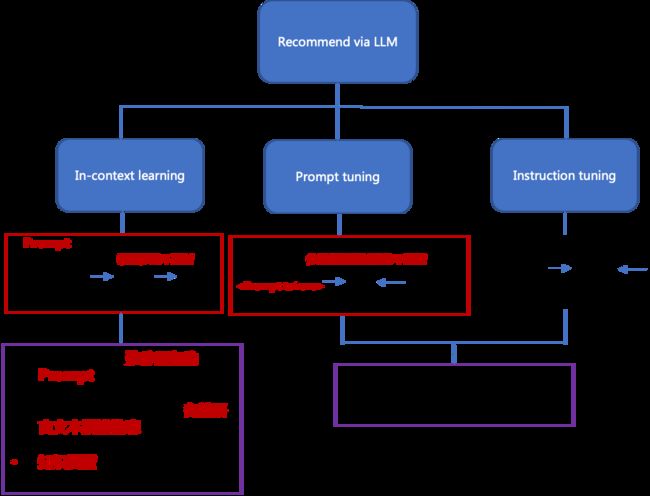
整体还是偏向In-context learning。通过构造 task-specific prompt让大模型进行推荐或者生成更丰富的信息内容提升base推荐模型的效果。
2.2 推荐存在的一些问题
当用户行为数据稀疏,数据量不足的时候,推荐系统存在的一些基础问题如下图所示:

主要是两大类问题:个性化弱以及精准度问题。
2.3 大模型在推荐的应用 (加强用户实时兴趣识别)
我们可以利用大模型的强大推理以及通用知识能力,让大模型根据用户实时的行为以及场景信息进行用户实时兴趣识别,提升推荐的精准度。下面给出了一个基本方案的流程图:

让我们给定一些场景信息测试下chatgpt对用户的实时场景兴趣的理解,我们的prompt构造如下:
Task Description:
基于如下用户的画像以及环境信息,针对给出的服务类型:[洗车,加油,代驾,保养,租车],推测出用户接下来在什么时间点做什么服务
Behavior Injection:
{“用户画像":[女,35岁,居住深圳],
“环境信息”:[晚上9点,在北京]
}
Format Indicator:
输出格式:{服务类型:理由:服务概率}
我们调用chatgpt api如下:
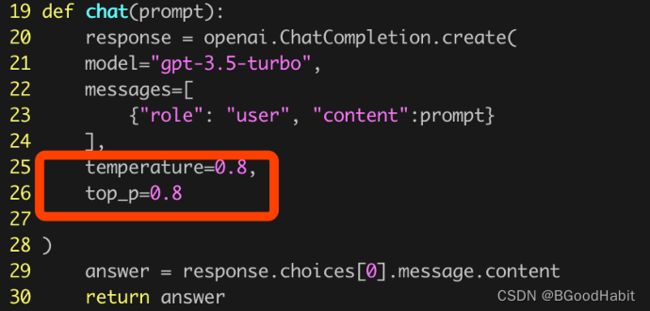
上面红色框的两个参数控制生成文本保守和确定性控制,值越低表示越保守。如下是chatgpt给出的结论:
{“服务类型”:“租车”,“理由”:“用户属性为女性,35岁,长住深圳,晚上9点位于北京,可能是因为需要在北京出差或旅行,所以最有可能需要租车服务。“服务概率”:0.8}
整体来说还是比较符合常规的,我们可以基于实时用户行为数据以及场景信息,借助大模型的强大推理以及通用知识能力进行用户实时意图的理解,让推荐算法更加智能,更好的理解用户的实时用兴趣和需求。
3 总结
本博文给出了大模型在搜索和推荐的一些基础应用,主要针对现有搜索和推荐存在的问题,借助大模型强大的推理能力以及通用知识能力进行一些优化。但大模型在搜索和推荐上的应用还有更多更好的方式,欢迎有新兴趣的小伙伴能够一起交流和学习。