「研读笔记」MIT 6.S081 Chapter7 File system
#Chapter7 File system
- I. Source
- II. Chapter7 - File system
-
- 7.8 - Inode layer
- 7.9 - Code: Inodes
- 7.10 - Code: Inode content
- 7.4 - Logging layer
- 7.5 - Log design
- 7.6 - Code: logging
- III. Summary
I. Source
- MIT-6.S081 xv6 book
- B站 - MIT-6.S081 Lec14: File Systems
- MIT 6.S081 Lab8 locks
- MIT 6.S081 Lab9 file system
II. Chapter7 - File system
写在前头,研读 xv6 的 File system 所做的笔记并没有按照 MIT-6.S081 2020 xv6 book 第 7 章节目录顺序展开,而是先从 Inode 开始,介绍 File system 具体工作流程。在阐述完其工作原理之后,再引入应对 Crash Recovery 的重要举措:Logging
教科书是先讲 Logging ,然后再讲 Inode 。我在第一次阅读时,看的不是很通透,所以我想在自己的文章中调整顺序,希望能够把 xv6 File system 讲明白
哦,对了,在 Inode 开始之前,需要先对 File system 最底层的组件 Buffer cache 有所了解,我在之前的 MIT 6.S081 Lab8 locks 中有详细介绍,需要请移步
还有其他几小节,我选择跳过,因为这些内容我认为不是 xv6’s File system 的重点,Inode 和 Logging 才是
7.8 - Inode layer
在我们开始之前,先要清楚 xv6’s File system 在 disk 中的布局,如下图,

从图中我们可以看出,inodes 是分布在 disk 中的一连续区域,且每个 inode 大小相等,xv6 中是 64 个字节,在 kernel/fs.h 中有所定义,即是,
// Inodes per block.
#define IPB (BSIZE / sizeof(struct dinode))
因为 xv6 中 1 块 block 是 1024 字节,所以每块 block 能够容纳 16 个 inode 。另外,需要注意的是 block 不是 xv6 硬件读写的最小单位,sector 才是,且 1 个 block 通常由 2 个 sector 组成
如其名,inode 其实就是 index node 的缩写,即是索引节点,我们可以根据 inode 找到对应的文件及内容。xv6 将第 32 ~ 44 块 block 划分给 inodes ,其实也就把 xv6 支持的文件个数固定死了,即是 ( 44-32+1 )x( 1024/64 )= 14 x 16 = 224
每个 inode 包含了文件的 metadata ,包括文件的类型、文件的链接数、文件的大小以及文件内容的位置,除了文件名。在 kernel/fs.h 中定义为 struct dinode ,
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+2]; // Data block addresses
};
为什么叫 dinode ?是因为 struct dinode 是存储在 disk 中所需记录的状态。type 支持文件、目录、特殊文件类型,其值为 0 表示该 dinode 此刻空闲;nlink 是指向该 inode 的符号链接数;size 是文件大小;addrs[] 存放的是文件内容所在的 block 编号
而 struct inode 是 struct dinode 在 memory 中的拷贝,只有当有进程使用到该 inode 时,kernel 才会将存放在 disk 中的 struct dinode 激活,拉取到 memory 。它的定义在 kernel/file.h 中,
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+2];
};
struct inode 比起 struct dinode 多了几个字段,其中包括引用计数 ref ,其意为此时有多少 C 指针正指向该 inode ,只有当没有 C 指针再指向该 inode 时,kernel 才会考虑将其驱逐回 disk
7.9 - Code: Inodes
kernel/fs.c 中定义的 iget() 和 iput() 就是用来管理引用计数 ref 的,其中 iget() 大致做的事,就是在 inode cache 中尝试寻找名为 dev ,编号为 inum 的 inode 。如果 inode 在 inode cache 中,则直接返回;反之,则分配 1 个空闲块作为新 inode 。让我们先看看代码,
// Find the inode with number inum on device dev
// and return the in-memory copy. Does not lock
// the inode and does not read it from disk.
static struct inode*
iget(uint dev, uint inum)
{
struct inode *ip, *empty;
acquire(&icache.lock);
// Is the inode already cached?
empty = 0;
for(ip = &icache.inode[0]; ip < &icache.inode[NINODE]; ip++){
if(ip->ref > 0 && ip->dev == dev && ip->inum == inum){
ip->ref++;
release(&icache.lock);
return ip;
}
if(empty == 0 && ip->ref == 0) // Remember empty slot.
empty = ip;
}
// Recycle an inode cache entry.
if(empty == 0)
panic("iget: no inodes");
ip = empty;
ip->dev = dev;
ip->inum = inum;
ip->ref = 1;
ip->valid = 0;
release(&icache.lock);
return ip;
}
我们注意到,如果成功的话, ip->ref 会有所变动。要不是 memory 中已有拷贝时的 ++ ;要不就是新分配时的置 1 。或许还有个疑问,inode cache 到底是何物?不妨先看看这张 xv6 File system 的层次图,

之前在 MIT 6.S081 Lab8 locks 中提到的 Buffer cache 是与 disk 打交道的最底层,inode cache 是处于 Inode 和 Logging 之间的,可以理解成 inode cache 就是 inodes 集合,存储目前活跃的 inode ,且 inode cache 是 Buffer cache 的子集,即是 inode cache 在 Buffer cache 中,请看 kernel/fs.c 中定义,
struct {
struct spinlock lock;
struct inode inode[NINODE];
} icache;
就可以简简单单理解为缓冲区,存放 inode 的缓冲区。其中宏 NINODE 定义在 kernel/param.h 中,
#define NINODE 50 // maximum number of active i-nodes
我们可以看到,在 memory 中的 inodes 数是远小于 disk 中 dinode 的 224 的。另外 iget() 还有一个值得注意的地方,即是它不对返回的 struct inode* 上锁,这意味着同一时刻可以有多个 C 指针指向同一个 inode ,这也就回答了在 memory 中 inode 为什么要有引用计数 ref 字段?书中原话,
iget() provides non-exclusive access to an inode, so that there can be many pointers to the same inode
相反,iput() 所做的事是减少 inode 的引用计数,在没有其他 C 指针指向且无符号链接的时候将 inode 驱逐回 disk ,腾出空间。且看定义,
// Drop a reference to an in-memory inode.
// If that was the last reference, the inode cache entry can
// be recycled.
// If that was the last reference and the inode has no links
// to it, free the inode (and its content) on disk.
// All calls to iput() must be inside a transaction in
// case it has to free the inode.
void
iput(struct inode *ip)
{
acquire(&icache.lock);
if(ip->ref == 1 && ip->valid && ip->nlink == 0){
// inode has no links and no other references: truncate and free.
// ip->ref == 1 means no other process can have ip locked,
// so this acquiresleep() won't block (or deadlock).
acquiresleep(&ip->lock);
release(&icache.lock);
itrunc(ip);
ip->type = 0;
iupdate(ip);
ip->valid = 0;
releasesleep(&ip->lock);
acquire(&icache.lock);
}
ip->ref--;
release(&icache.lock);
}
从上面代码可以看出,在没有其他 C 指针指向及 inode 已被覆写过且无符号链接的情况下,将该 inode 置为空闲状态并与 disk 的 dinode 同步
需要注意的是,没有符号链接( ip->nlink == 0 )意味着该 inode 不属于任一目录。我们想想,无论是在 xv6 还是 Linux 等现代 OS 中,存在一个文件,它不属于任一目录的情况嘛?文件一定是要在某一目录下的,哪怕是根目录,所以显然是不存在的!进而说明无符号链接的 inode 是没人用的,也没人管,我们是可以回收的
何为没有其他 C 指针指向,在代码中就表现为 ip->ref == 1 ,意为只有当前 Caller 在使用
其中的 kernel/fs.c:itrunc() 暂时知道它负责清空 inode 所包含的文件内容就可以啦!kernel/fs.c:iupdate() 将 inode 中的内容回写至 disk 中。因为不是主要内容,就不再这里展示代码了,需有请阅读 MIT 6.S081 Lab9 File system 源代码
在本小节的最后,还想提一下 kernel/fs.c:ialloc() 。这个函数和 kernel/kalloc.c:kalloc() 及 kernel/fs.c:balloc() 功能类似,都是为 Caller 分配空闲空间。区别就在 Caller 有所不同,kalloc() 是为 pagetable 分配空间;balloc() 是为 Buffer cache ;此处的 ialloc() 是为 inode cache
ialloc() 做的事大致就是,尝试在 inode cache 中寻找空闲的 inode ,定义如下,
// Allocate an inode on device dev.
// Mark it as allocated by giving it type type.
// Returns an unlocked but allocated and referenced inode.
struct inode*
ialloc(uint dev, short type)
{
int inum;
struct buf *bp;
struct dinode *dip;
/** 尝试在 icache 中寻找空闲的 inode */
for(inum = 1; inum < sb.ninodes; inum++){
bp = bread(dev, IBLOCK(inum, sb)); /** 返回包含第 inum 号 inode 的 block */
dip = (struct dinode*)bp->data + inum%IPB; /** 在 block 中定位到第 inum 号 inode */
if(dip->type == 0){ // a free inode
memset(dip, 0, sizeof(*dip));
dip->type = type;
log_write(bp); // mark it allocated on the disk
brelse(bp);
return iget(dev, inum);
}
brelse(bp);
}
panic("ialloc: no inodes");
}
其中 log_write() 可以简单理解成 bwrite() ,是将 buf 回写至 disk 中。在 ialloc() 的业务流程中,调用 log_write() 把第 inum 号的 inode 标记为已分配,这样 File system 下次就不会再将这块 inode 分配给其他进程了
7.10 - Code: Inode content
在 #7.8 - Inode layer 中我们讲到 struct dinode 的定义,其中包含 addrs[] ,当时我们说这个地址数组是用来保存文件内容所在的 block 编号。这样,以后我们就可以通过串联 addrs[] 来读写操作文件了,可能有点抽象,请看结构图,
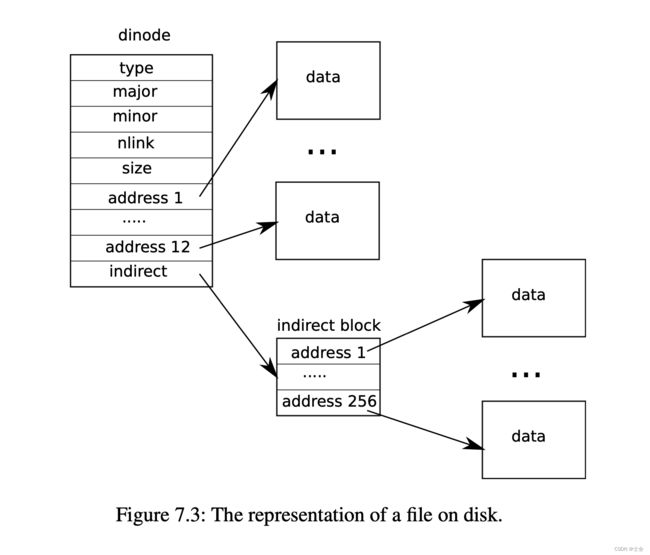
我们注意到 xv6 在 struct dinode 中有 12 个一级地址(直接指向 data-block ),还有 1 个二级地址(指向了一个 addrs-block ,addrs-block 又指向 data-blocks )。在 kernel/fs.h 中定义为宏 NDIRECT,
#define NDIRECT 12
可以计算出 addrs[] 长度为 NDIRECT+1 (因为只有 1 个二级地址),1 块 block 包含 1024 个字节,我们有 12 个指向 data-block 的一级地址和 1 个指向 addrs-block 的二级地址,计算大小为(12x1024 + 256x1024)B = 268 KB
围绕着 addrs[] 有两个重要的功能函数 kernel/fs.c:bmap() 和 kernel/fs.c:itrunc() ,前者负责为 inode 分配地址空间,后者释放 inode 地址空间,具体放在 MIT 6.S081 Lab9 file system 中详细叙述
7.4 - Logging layer
本小节主要讲了 xv6 在运行的过程中会发生 Crash ,如果应对 Crash 的方式不当,会造成用户文件的安全问题,我想通过一个 demo 来说明:在调用文件清空的 system call (文件长度置 0 并释放内容 block )时,执行到一半,xv6 突然断电了,在没有 Crash Recovery 手段的情况下,通常会发生两种情况(这依赖于文件清空这个 system call 是如何实现的?)
- inode 依然指向一块已被释放的 block
- File system 中遗留了一块已被分配但没人引用的 block
第二种情况还算不错,顶多会浪费 disk 一块 block ,但并不会对其他进程造成影响;而第一种情况就很不妙啦,它就类似于多个 C 指针指向同一块内存的问题,这是非常危险的
试想,inode A 在 Crash 后依然指向之前的 block0 ,但 block0 已经被 File system 标记为可分配的,并在不久后分配给 inode B 。此时 inode B 是名正言顺地拥有 block0 ,而 inode A 属于是恍然隔世,不知大清已亡的那种情况,依然认为 block0 还属于自己,但其实不是!
文件清空就意味着 inode A 应该归还 block0,只是因为文件清空中途 Crash ,导致清空和释放青霞不接
Logging 机制就是为了解决 Crash 带来的状态不一致问题,书中原话,
The problem arises because many file-system operations involve multiple writes to the disk, and a crash after a subset of the writes may leave the on-disk file system in an inconsistent state.
且看 #7.5 - Log design 是如何设计 Logging 机制的
7.5 - Log design
在本小节开头,我们回顾一下 xv6’s File system 在 disk 中的布局(见 #7.8 - Inode layer 的 Figure 7.2 - Structure of the xv6 file system ),从图中我们可以看出,第 2 ~ 31 块 block 是 logspace ,其第 1 块( disk 的第 2 块) block 存放 logheader
logheader 是 Logging 机制中至关重要的组件,它在 kernel/log.c 中定义如下,
// Contents of the header block, used for both the on-disk header block
// and to keep track in memory of logged block# before commit.
struct logheader {
int n;
int block[LOGSIZE];
};
可以将其理解成一个向量,用来存放 block 编号,其 n 指向 block[] 的已用区域中最后一个元素,再看 logspace 是如何定义的?在 kernel/log.c 中,
struct log {
struct spinlock lock;
int start;
int size;
int outstanding; // how many FS sys calls are executing.
int committing; // in commit(), please wait.
int dev;
struct logheader lh;
};
其 start 记录了 logspace 逻辑上的第 1 块 block 的编号,在 xv6 中对应是第 2 块 block ;size 表示 logspace 包含的 block 数,在 xv6 中第 2 ~ 31 块 block 属于 logspace ;outstanding 记录了目前有多少个 system call 正在使用 File system ;committing 很好理解,就是 xv6 此时是否有事务正在 commit ,如果当前有事务正在 commit ,那么别的事务就应该等一等;最后的 logheader 是 logspace 的第 1 块 block
好,讲完这两个重要的数据结构定义后,我想通过 demo 来走一遍 Logging 的具体流程,假设我们在 shell 里输入了,
$echo "hi" > x
这个命令,就是将 “hi” 保存到文件 x 中,在 echo() 中,
- 先为文件 x 分配 inode x( write block33 )
- 初始化 inode x( write block 33 )
- 在 bitmap 中标记 block33 已被使用( write 46 )
- 更新 root inode( write block32 )
- 更新 inode x( write block33 )
等等操作,我可能列举的不全面,但是已经到了可以把问题讲明白的程度了。我们注意到,echo() 都是写操作,不是写这个 block ,就是写那个 block
我们都知道,写操作都是要通过 Buffer cache 的,这是什么意思呢?就是我们想更新 on-disk 中 block33 的内容,不能跳过 memory 直接操纵 disk ,而是告诉 memory 我们想更新 on-disk 的 block33 ,让 memory 帮我们去更新。这里的 memory 可以理解成 Buffer cache(请移步 MIT 6.S081 Lab8 locks )
我们是先把数据写到 Buffer cache 中的,然后才会写回至 disk 。在 MIT 6.S081 Lab8 locks 中是通过 bwrite() 来完成的,但是在 File system 中要用 kernel/log.c:log_write() 代替,其功能和 bwrite() 差不多,bwrite() 更直接,第一时间将内容写回至 disk ;而 log_write() 是先将内容保存在 memory 中并记下内容所在的 block 编号,等待合适的时机再将其写回至 disk
它的拖一拖,就是 Logging 机制必要的妥协。针对 echo() ,统计出 File system 需要将 block33.46.32 写回至 disk ,看一下流程,
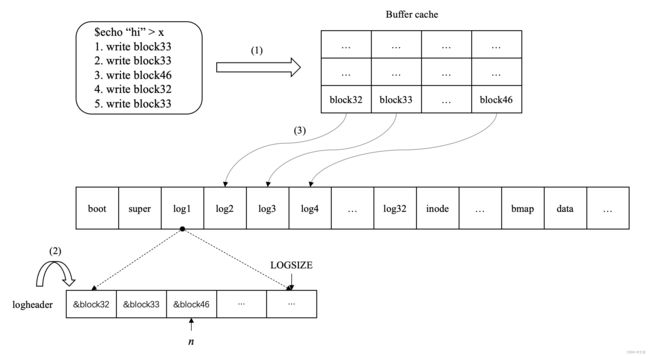
写操作的第 1 步,先将写的内容更新至 Buffer cache 中,这个和没有引入 Logging 机制时的做法相同,应该没有疑问;在更新至 Buffer cache 之后,流程会要求我们调用 log_write() ,将写操作涉及的 block 编号记下来,存放在 logheader 中,如上图步骤 2 所示。在书中也强调:用 log_write() 代替 bwrite() ,将以前的直接写回做法改为,
bp = bread(...);
modify bp->data[]
log_write(bp);
brelse(bp);
待 system call 结束后,也就是 Caller 调用 end_op() 时,将一连串写操作 commit ,写回 on-disk 的 logspace 中,完成数据持久化工作,对应上图的步骤 3 :将 block32 写到 log2 中,block33 写到 log3 中,block46 写到 log4 中
一旦完成数据持久化,我们就不再害怕突然断电等 Crash 了,因为数据已经被我们保存在 disk 中了,即使断电了,数据也不会消失;而放在 memory 中始终担心随时 gone
可以说,上图很好地阐释了 xv6’s File system 的 Logging 机制
7.6 - Code: logging
Caller 调用 end_op() 意味着写操作已经结束,可以在 disk 中更新 Caller 的数据。更新在 File system 中有另外一种说法,叫事务。end_op() 会调用 kernel/log.c:commit() 主动更新 disk ,持久化 Caller 之前的操作,且看定义,
// called at the end of each FS system call.
// commits if this was the last outstanding operation.
void
end_op(void)
{
int do_commit = 0;
acquire(&log.lock);
log.outstanding -= 1;
if(log.committing)
panic("log.committing");
if(log.outstanding == 0){
do_commit = 1;
log.committing = 1;
} else {
// begin_op() may be waiting for log space,
// and decrementing log.outstanding has decreased
// the amount of reserved space.
wakeup(&log); /** 唤醒 begin_op() 中因 committing 或 log space 不足而休眠的进程 */
}
release(&log.lock);
if(do_commit){
// call commit w/o holding locks, since not allowed
// to sleep with locks.
commit();
acquire(&log.lock);
log.committing = 0;
wakeup(&log);
release(&log.lock);
}
}
大致流程,就是如果此时没有进程 commit 事务且没有 system call 使用 File system ,则发起 commit 。没有进程 commit 事务很好理解,因为 xv6 一次只能处理一个事务;没有 system call 使用 File system ,这意味着所有 system call 已经完成全部的写操作了,这非常重要,我们都知道,事务的几大原则,其一就是原子性:要么做要么不做,不能做事只做到一半!
需要注意的是,commit 时 logspace 中的写操作可能不止涉及一个 system call ,xv6 是允许同时有多个 system call 的写操作,在同一批次的 logspace 中 commit ,比如,echo() 涉及的 block 写入 log1.2.3 中,write() 涉及的 block 写入 log4.5.6 中,等两个 system call 都结束后,Logging 再统一 commit
这样做有个好处,就是为了提高 disk 的利用率。因为每次操控 disk 定位到 block 的代价有点大,我们想聚少成多,等写操作成势了之后,再一口气写入 disk ,这样就省去了一次旋转 disk 的功夫,而且效果是相同的。书中原话,
The idea of committing several transactions together is known as group commit. Group commit reduces the number of disk operations because it amortizes the fixed cost of a commit over multiple operations. Group commit also hands the disk system more concurrent writes at the same time, perhaps allowing the disk to write them all during a single disk rotation. Xv6’s virtio driver doesn’t support this kind of batching, but xv6’s file system design allows for it.
下面,我们来看看 commit() 里面做了哪些事,
static void
commit()
{
if (log.lh.n > 0) {
write_log(); // Write modified blocks from cache to log
write_head(); // Write header to disk -- the real commit
install_trans(0); // Now install writes to home locations
log.lh.n = 0;
write_head(); // Erase the transaction from the log
}
}
第 1 件事,将原先在 Buffer cache 中写操作涉及的 block 内容拷贝到 logspace 中,对应上图的步骤 3 ;随后,将 in-memory 的 logheader 内容也拷贝到 logspace 中(其第 1 块 block ),这两件事都是为了数据持久化,即是 Crash 了也不怕,可以恢复
这两个函数的定义不在此展开了,没什么特别的地方,代码写的很到位,细细体会。我想讲的是 install_trans() ,
// Copy committed blocks from log to their home location
static void
install_trans(int recovering)
{
int tail;
for (tail = 0; tail < log.lh.n; tail++) {
/** 已持久化的写操作内容 */
struct buf *lbuf = bread(log.dev, log.start+tail+1); // read log block
/** on-disk 对应的 block */
struct buf *dbuf = bread(log.dev, log.lh.block[tail]); // read dst
memmove(dbuf->data, lbuf->data, BSIZE); // copy block to dst
bwrite(dbuf); // write dst to disk
if(recovering == 0) /** 正在恢复,需要用到 dbuf */
bunpin(dbuf);
brelse(lbuf);
brelse(dbuf);
}
}
其实,就是将 logspace 中已持久化的写操作内容回写至 on-disk 对应的 block ,完成真正的更新工作,写不就意味着更新嘛?重点是,如果在 install_trans() 中 Crash 了,会怎么办?我想 xv6 的数据是不受影响的,因为在 commit 之后,logspace 中已有持久化数据,不惧怕 Crash ,大不了在 reboot 之后,调用 kernel/log.c:initlog() ,其中的 kernel/log.c:recover_from_log() 会重新将写操作的内容覆盖回 data-block
如果在 write_log() 时 Crash 了,怎么办?其实也没事,reboot 之后就当没发生过写操作一样。这就是 Logging ,只要还没 write_head() ,就不算数
在 install_trans() 之后,我们需要将 logheader 清空,即是 n 置 0 ,这非常重要!清空意味着 logspace 又可以接纳新的写操作了,还有一点,就是避免重复 commit
III. Summary
总结一下,fk 教授讲的 Logging 流程,其实就是 4 件事,
- write
- commit
- install transaction
- clean up
至此,我想我已经讲完了 xv6 较为简单的 Logging 机制了