【阅读整理】Implementation of an algorithm for automated phenotyping through plant 3D-modeling
目录
主体篇幅目录:
Abstract
Conclusion
实验方案设计(2.1 Experimental design and data collection)
三维重建&处理(2.2 Three-dimensional reconstruction and processing)
三维模型分割(2.3 3D-model segmentation)
植物生长表型分析(2.4 Plant growth phenotyping)
实验结果(3 Result)
Discussion
原文:
主体篇幅目录:
1、Introduction
2、Materials and methods
2.1 Experimental design and data collection
2.2 Three-dimensional reconstruction and processing
2.3 3D-model segmentation
2.3.1 Orientation and scaling
2.3.2 Main stem and petioles segmentation
2.3.3. Single-leaf segmentation
2.4 Plant growth phenotyping
2.4.1. Plant growth analysis
Abstract
(cv. 栽培变种)
高通量植物表型需要集成的基于图像的工具来自动和同时定量多种形态和生理性状,这是植物对限制环境条件的敏感性的有价值的指标。
在本研究中,我们提出了一种新的基于三维(3D)建模的分割算法,通过表型平台和结构从Structure from motion(SfM)方法获得。该算法最初在4个盆栽商业番茄品种的3D模型上进行了测试,即“圣皮埃尔”(S)、“科斯特罗托”(C)、“雷吉内拉”(R)和“Gianna”(G),用于鉴定植物的主要表型性状(高度、角度和面积)。
结果表明,该算法能够自动检测和测量株高(![]() =0.98、
=0.98、![]() =0.34cm、
=0.34cm、![]() =3.12%和
=3.12%和![]() =6.03)、叶柄倾斜度(
=6.03)、叶柄倾斜度(![]() =0.96、
=0.96、![]() =1.35◦、MAPE=3.64%和
=1.35◦、MAPE=3.64%和![]() =22.16)、单叶面积(
=22.16)、单叶面积(![]() =0.98、
=0.98、![]() =0.95cm2、
=0.95cm2、![]() =7.40%和
=7.40%和![]() =14.91)和单叶角(
=14.91)和单叶角(![]() =0.84、
=0.84、![]() =1.43◦、
=1.43◦、![]() =2.17%和
=2.17%和![]() =15.83)。
=15.83)。
作为研究案例,利用该算法监测了同一番茄品种对早期土壤水分(FTSW)连续20天的动态响应。对植株进行三种处理(100%全灌、50%亏缺灌溉和0%无灌溉)。
结果表明,R和G cv. 的株高是对水分胁迫最敏感的表型性状(FTSW值为0.58时,植株生长抑制),而FTSW较低时,总叶面积和蒸腾速率开始受到影响(分别为0.52和0.40)。
相反,S和C cv. 在分析的表型性状中没有表现出任何显著的变化,可能是因为这些品种的生长速度缓慢,允许它们消耗更少的水,因此没有达到水分胁迫阈值。结果表明,株高性状可用于后续分析,便于快速鉴定抗逆境番茄品种,从而加强杂交方案。
含义公式与代码实现原文:预测评价指标RMSE、MSE、MAE、MAPE、SMAPE_手撕机的博客-CSDN博客_mae
均方根误差RMSE、均方误差MSE、平均绝对误差MAE、平均绝对百分比误差MAPE、对称平均绝对百分比误差SMAPE
# MAPE和SMAPE需要自己实现
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true)) * 100
def smape(y_true, y_pred):
return 2.0 * np.mean(np.abs(y_pred - y_true) / (np.abs(y_pred) + np.abs(y_true))) * 100
y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_pred = np.array([1.0, 4.5, 3.5, 5.0, 8.0, 4.5, 1.0])
# MSE
print(metrics.mean_squared_error(y_true, y_pred)) # 8.107142857142858
# RMSE
print(np.sqrt(metrics.mean_squared_error(y_true, y_pred))) # 2.847304489713536
# MAE
print(metrics.mean_absolute_error(y_true, y_pred)) # 1.9285714285714286
# MAPE
Conclusion
本研究提出了一种新的基于图像的植物三维模型自动分割和高通量表型数据提取算法。结果表明,该算法在对不同品种的主茎、叶柄和叶进行无损分类方面具有鲁棒性,可以准确估计3d空间中的主要生长参数(即植株和器官高度、角度和面积)。
此外,本研究通过将我们的算法与一个自动称重和成像的低成本平台相结合,证明了冠层结构和生理日变化的动态量化,以表征早期水分胁迫对番茄表型的影响。这种自动化可以将表型应用扩展到更多的植物样本,并获得更精细的时间分辨率,尽管需要对图像处理框架进行优化,以提高植物3Dmodel重建的吞吐量。
基于该案例研究,我们选择的样本量足够大,可以通过可接受的计算和经济努力,识别出早期水分胁迫所造成的每日冠层发育的显著差异。具体来说,相对生长速率与实际蒸水(FTSW)的响应有助于清楚地区分4个番茄品种对渐进土壤干燥的总体行为。在此背景下,我们可以推测,保守的冠层生长有利于植物在有限的供水条件下的生存,它可以作为具有提高抗旱能力的番茄品种的育种指导。此外,由于该算法仅依赖于植物三维模型的点级几何特性,因此该途径有望适用于绝大多数作物和树种。当然,我们的算法如何很好地池化到其他叶状(和/或)分支模式还有待研究。
为此,未来甚至需要在具有更复杂的冠层作物中促进高通量表型分析的可重复性。对大量基因型的成功测试将更有力地支持我们关于对土壤干燥的形态-生理反应的大小和时间的发现。这将可以用于工厂实时检测植物的水分状态,以加强适当的灌溉调节。
实验方案设计(2.1 Experimental design and data collection)
该实验采用了Rossi等人(2020年)中描述的低成本表型平台,对盆栽植物进行了自动称重和360◦扫描。该系统(图1)由9个旋转板(Ø15cm)组成,并配有一个自动称重模块(1000g/0.01g),用于监测单株蒸腾速率的动态,以及一个安装在滑动系统上的通用RGB摄像机,用于与看台运动同步的图像采集。为了提高平台在监测不同生长阶段的多个物种和品种时的灵活性,倾斜调节器允许根据被扫描目标的大小调整相机视点的高度和角度。

实验对照组
S、C、R、G四个番茄品种
S&C cv. 晚至中晚种植品种,耐寒性高,需水量稳定。
R&G cv. 是早期到非常早期的番茄品种(Rcv. 旺盛植物能适应高温和充分灌溉的盐渍土壤,G cv. 中等强度需水量更低)
番茄植株播种在36个塑料盆中(分别为12.00cm×,直径和高度10.50cm),填充约2/3的商业表土和1/3的沙子(图1)。为了减少基质损失,每个盆的底部涂上一层透气的防滤层。
在全灌后3小时后测量最高有效水量(FCW)样品的初始重量。
然后将幼苗转移到加热的生长室,在27±1.5◦C和24小时/天的光照条件下生长20-32天(欧司朗FluoraL36W/77荧光灯,1400腔;OSRAMLichtAG®,慕尼黑,德国),每两天浇水至土壤饱和度。
在BBCH的第十二个生长阶段,与主茎上的第二叶展开相对应,每个花盆在顶部用一层遮蔽胶带密封,以避免土壤表面蒸发造成的水分流失。
选取幼苗,每个变量组每个品种三株,灌溉灌溉(T100),每两天浇水一次,保持FCW;50%的赤字灌溉(T50),分配在过去48小时内消耗的一半水;不灌溉(T0),不浇水。在使用低成本表型平台进行单株扫描之前,使用刻度注射器(50ml/1ml)进行处理。
该平台用于自动称重和扫描来自第12个BBCH生长阶段和连续20天的所有36株番茄植株。为了尽量减少环境对表型的影响,每个处理组9株幼苗从每天上午8点到下午14点从生长室转移到旋转板上,进行称重(Wn)和浇水。

拍摄场景布置
Nikon D810相机,AF-S DX NIKKOR 35mm f/.8G lens镜头,手动曝光。
在整个实验过程中,两盏冷白(5500K)霓虹灯保证了均匀的照明条件,同时在场景后面放置一块黑色面板以覆盖背景中的物体。为了防止部分植物在生长周期中离开框架,每天通过手动调整倾斜调节器和登记(将倾斜度从5◦降低到15◦)来修正相机视点(Rt)。该场景还包括一个已知尺寸(3x3厘米/边缘)的魔方,放置在花盆的固定位置,作为连续植物的3D坐标(xyz)提取的参考。
后续处理
在监测结束时,在ImageJ®成像软件(https://imagej.nih.gov/ij/)上手动提取株高(PH)、叶柄倾角(PI)和单叶角(LI),并从每株植物采集的三幅图像中取平均值,作为地面真实值,计算长度和角度披露的准确性。这些特征的测量在ImageJ®中采用标准的水平数码摄影(LDP)方法进行,以避免通过更具侵入性的人工调查改变冠层内单个器官的安排。
同时,将每株植物的叶片初始分离,并在网格表面上正交拍照,作为实际个体叶面积(LA)和总叶面积(TLA)测量的参考(建昌等,2011),并对单株植物进行切片,获得叶片、主茎、叶柄和根的新鲜重量,使用精确平衡(1000/0.001g;Radwag®,Radom,波兰)。最后,将每个样品在50◦C的烘箱中干燥72h,得到叶片、主茎、叶柄和根的干重。
三维重建&处理(2.2 Three-dimensional reconstruction and processing)
根据基于SFM的程序,对20天监测期间获得的图像进行处理,获得每个植株的3d密集点云(DPC)模型。
首先,在MATLAB环境中,通过颜色阈值分割方法自动去除背景。
其次,用DPC光扫描专业软件对掩码图像进行图像对齐。
最后,采用Agisoft光扫描专业内置滤波算法清除离群点。
三维模型分割(2.3 3D-model segmentation)
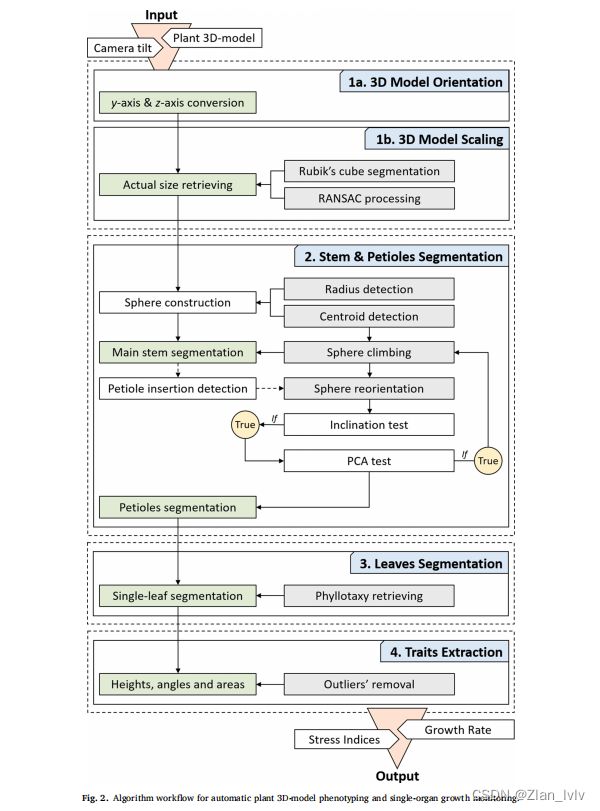
1、Orientation and scaling 定位与缩放
(1)该方法的起点是恢复场景的方向和尺度。该算法以工厂的点云和摄像机倾斜值作为输入,使z轴沿主轴自动对齐。模型中每个点的原始y轴和z轴坐标通过围绕x轴的空间旋转进行转换。
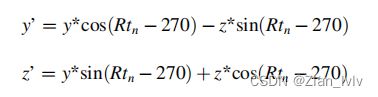
y和z分别为模型的原始y轴和z轴坐标,Rt为扫描第n天时的相机倾斜值。
(2)其次,利用颜色阈值化方法从DPC中分割出魔方,并用RANdom随机共识(RANSAC)方法进行处理。该函数计算三维点上的最佳拟合长方体,并返回顶点的估计坐标。
(3)最后,利用最近拟合顶点之间的欧几里得空间中的平均直线距离(d’),通过缩放xyz点来检索整个模型的实际大小。随后将从![]() 模型中删除用于大小调整过程的多维数据集。
模型中删除用于大小调整过程的多维数据集。

xyz为模型的定向x轴、y轴和z轴坐标,d‘和d’分别为魔方边的实际长度(在本研究中为d=3cm)和模拟长度。
2、Main stem and petioles segmentation 主茎和叶柄分割
主茎的实际形状是通过考虑一个包含了所有轴的轴点的可变半径的球体,从植物底部沿着z轴攀爬。(意思是以植物底部为坐标系远点?)
为了满足适应生长周期中茎几何变化的算法的需要,通过提取1cm到3cm之间平均茎直径的一半,自动估计每个模型的球的初始半径(![]() )。在此计算中不考虑1cm以下的茎的部分,以避免三维重建的不准确造成的错误(例如,不寻常的茎的厚度和花盆的遮挡。)而利用聚类过滤器解决了对其他器官(如子叶)的错误选择问题。
)。在此计算中不考虑1cm以下的茎的部分,以避免三维重建的不准确造成的错误(例如,不寻常的茎的厚度和花盆的遮挡。)而利用聚类过滤器解决了对其他器官(如子叶)的错误选择问题。
特别是,下采样点根据0.50厘米的最小欧氏距离值进行分组,只要它们在较大的聚集之外,即聚集只包含茎的点,就考虑离群值。
通过计算被包围成两个环(半径为![]() ,高度为
,高度为![]() ,从植株底部的
,从植株底部的![]() 和
和![]() 分别建立)的所有
分别建立)的所有![]() 点的中点,球体的质心(
点的中点,球体的质心(![]() )被自动拟合到茎的中心。然后,利用球体质心(
)被自动拟合到茎的中心。然后,利用球体质心(![]() )附近相邻点的局部主成分分析(PCA)得到的三个有序特征值(λ0≤λ1≤λ2)的值进行茎分类。假设大致平面分布的k点所描述的λ0比λ1≅λ2小得多,我们使用λ0和λ1≅λ2之间的比率作为指标的共存茎和其他器官(即叶柄和/或叶)在相同的相邻框架。通过对本研究中考虑的一半植物模型的试验实验,我们发现λ0值比λ1≅λ2小10倍,可以区分一组只属于茎的k点。因此,当满足这个条件时,
)附近相邻点的局部主成分分析(PCA)得到的三个有序特征值(λ0≤λ1≤λ2)的值进行茎分类。假设大致平面分布的k点所描述的λ0比λ1≅λ2小得多,我们使用λ0和λ1≅λ2之间的比率作为指标的共存茎和其他器官(即叶柄和/或叶)在相同的相邻框架。通过对本研究中考虑的一半植物模型的试验实验,我们发现λ0值比λ1≅λ2小10倍,可以区分一组只属于茎的k点。因此,当满足这个条件时,![]() 周围的k-邻近点被分割为茎。相反,进行了进一步的测试,以避免由于部分重建(缺失点)而进行的误解。
周围的k-邻近点被分割为茎。相反,进行了进一步的测试,以避免由于部分重建(缺失点)而进行的误解。
具体来说,![]() 由2*
由2*![]() 沿z轴移动,以克服茎点云中的潜在断裂,并对邻近点计算了一种新的基于pca的分析。如果满足10*λ0≤λ1≅λ2的条件,则将k-相邻点分割为茎,球体通过rsp1 2向上移动,并对j邻近点计算了一种新的基于pca的分析。如果满足10*λ0≤λ1≅λ2的条件,则将k-相邻点分割为茎,球体通过
沿z轴移动,以克服茎点云中的潜在断裂,并对邻近点计算了一种新的基于pca的分析。如果满足10*λ0≤λ1≅λ2的条件,则将k-相邻点分割为茎,球体通过rsp1 2向上移动,并对j邻近点计算了一种新的基于pca的分析。如果满足10*λ0≤λ1≅λ2的条件,则将k-相邻点分割为茎,球体通过![]() 向上移动。
向上移动。
在球体在垂直轴上的每一个位移时,计算一个法线约束,以使球体更好地适应主茎的曲率。
在球的下限(图3b)上封闭的两个环( 半径为![]() ,高度为
,高度为![]() )的中点之间的法向量(图3b)用于重新调整沿茎的质心(
)的中点之间的法向量(图3b)用于重新调整沿茎的质心(![]() )(图3c)。在相对于y轴和z轴的异常倾斜的情况下,茎的分割过程被中断,以避免非法侵入叶片。
)(图3c)。在相对于y轴和z轴的异常倾斜的情况下,茎的分割过程被中断,以避免非法侵入叶片。
为了考虑番茄幼苗下胚轴和上胚轴之间的茎径的收缩,当下胚轴上方的第一个球体建立时,会自动计算一个半径减小因子并应用于![]() ,应用方程如下。
,应用方程如下。

式中,E为球体的质心(csp)与茎的最低点之间的欧氏距离,if E < 2 cm or ≥ 2 cm,ne = 1 or 5;Rsp2 提取的平均茎直径(1cm-2cm)的一半;Rsp3 提取的平均茎直径(2cm-3cm)的一半。
与番茄样品上胚轴直径的低变异性相关,子叶以上的所有球体都有![]() 作为不变半径。
作为不变半径。
因此,所有球体的融合都符合z轴的曲率,允许与实际主干对应的![]() 点集被分割。当球体沿z轴上升时,一个半径内frsp和半径外frsp2的球壳建立在质心(
点集被分割。当球体沿z轴上升时,一个半径内frsp和半径外frsp2的球壳建立在质心(![]() )周围,用于识别任何叶柄。点落在周围的壳聚集根据最小欧氏距离值0.50厘米和叶柄插入(
)周围,用于识别任何叶柄。点落在周围的壳聚集根据最小欧氏距离值0.50厘米和叶柄插入(![]() )被确定为相邻点的中点段连接
)被确定为相邻点的中点段连接![]() 每个集群的中点(
每个集群的中点( )。如果单个叶柄被几个n-定位,则
)。如果单个叶柄被几个n-定位,则![]() 被提取为相关n-
被提取为相关n-![]() 的平均值。一旦主球到达植物的顶端,将分割为茎的
的平均值。一旦主球到达植物的顶端,将分割为茎的![]() 点从模型中去除,其余的(对应于叶柄和叶)根据其欧氏最小距离(0.50cm)进行聚类;
点从模型中去除,其余的(对应于叶柄和叶)根据其欧氏最小距离(0.50cm)进行聚类;
每个ppi都与最近的聚类相关联,并扩展为单叶柄分割。具体来说,自动计算在质心![]() 和半径为0.20cm的球体中封闭的点的直径(
和半径为0.20cm的球体中封闭的点的直径(![]() )和法向(
)和法向(![]() )(根据番茄幼苗的标准叶柄半径获得)。然后,调整
)(根据番茄幼苗的标准叶柄半径获得)。然后,调整![]() 的大小,以避免在叶柄分割过程中在侧叶上溢出。
的大小,以避免在叶柄分割过程中在侧叶上溢出。
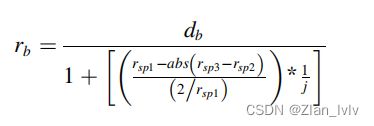
其中j可能根据所考虑的物种而变化(在本研究中j=4.50)。
与茎的分类类似,叶柄的分割是考虑模型中所有剩余的点,包括在一个半径为![]() ,由
,由![]() 从
从![]() 移动的球体中。 通过在两个环的上下极限点的中点之间的向量来定位质心,使球适当地拟合到叶柄轮廓。环半径=
移动的球体中。 通过在两个环的上下极限点的中点之间的向量来定位质心,使球适当地拟合到叶柄轮廓。环半径=![]() 和高度=
和高度=![]() ,考虑了标准番茄叶柄曲率的最小变化而得到的。在每一步中,测试球面倾斜的相干性以及基于
,考虑了标准番茄叶柄曲率的最小变化而得到的。在每一步中,测试球面倾斜的相干性以及基于![]() 附近l-邻近点的,基于PCA的分析所产生的特征值。通过排除具有进一步形状约束的分散点,避免了同一子集中叶柄和叶子的联合选择(λ0 ≅ λ1 ≅ λ2)。为此,当条件10*λ0≤λ1≅λ2和2*λ0≥λ1≅λ2均满足时,将相邻点分割为叶柄。最后,将每个叶柄根据其插入到茎的最低点之间的直线距离进行排序。
附近l-邻近点的,基于PCA的分析所产生的特征值。通过排除具有进一步形状约束的分散点,避免了同一子集中叶柄和叶子的联合选择(λ0 ≅ λ1 ≅ λ2)。为此,当条件10*λ0≤λ1≅λ2和2*λ0≥λ1≅λ2均满足时,将相邻点分割为叶柄。最后,将每个叶柄根据其插入到茎的最低点之间的直线距离进行排序。

【作为一个小白来说看这段的时候,满脑子都是这玩意儿是搞计算机的人能写的出来的???但是看到引用的时候,又开始觉得笔者这文献阅读的,真牛逼。。。总而言之,还是不知道是怎么能够写出来这么厉害的学科交叉的产物的】
3、Single-leaf segmentation 单叶分割
将插入在同一叶柄上的所有叶按0.50cm的最小欧氏距离值进行分离,并从顶端到茎上的叶柄插入点(![]() )按升序编号。通过分离n个簇聚集并匹配最近的插入点,解决了与几个
)按升序编号。通过分离n个簇聚集并匹配最近的插入点,解决了与几个![]() 相关的n个重叠叶所产生的误差,从而获得了实际的叶状结构和单叶监测。为了提取叶面积(
相关的n个重叠叶所产生的误差,从而获得了实际的叶状结构和单叶监测。为了提取叶面积(![]() )和总叶面积(
)和总叶面积(![]() ),从
),从![]() 模型中去除受叶柄影响的点,并分别对叶片进行分割。
模型中去除受叶柄影响的点,并分别对叶片进行分割。
然后,对每个器官的分割结果进行视觉验证(并在必要时进行手动校正),以确保高完整性,并根据正确 (True Positive) 、遗漏/不完整 (False Negative) 和错误(False Positive)检测的数量来定义所提出的方法的准确性、鲁棒性和泛化能力。
【手动校正?】
4、Phenotypic data extraction 表型数据提取
株高:![]() 是指分段茎的最低点和最高点之间的欧几里得空间中的直线距离。
是指分段茎的最低点和最高点之间的欧几里得空间中的直线距离。
叶柄倾斜度:![]() 为从顶点到假设的叶柄拟合平面的角度。
为从顶点到假设的叶柄拟合平面的角度。
叶面积与总叶面积:![]() 通过计算每个叶片点云的三维α形状,而植物
通过计算每个叶片点云的三维α形状,而植物![]() 为单个
为单个![]() 的和。
的和。
单叶角度:![]() 是顶点与垂直于单叶中心平面的向量之间的夹角
是顶点与垂直于单叶中心平面的向量之间的夹角
【点?点的法向量?】

【emmm这段是真没看懂】
植物生长表型分析(2.4 Plant growth phenotyping)
1、生长分析
以通过对![]() 、
、![]() 、
、![]() 、
、![]() 和
和![]() 的日值进行分段回归分析植物生长,以检测这些表型性状发育过程中的显著变异(断点、Ks)。在线性分段上拟合了一个具有指定最大断点数(Kmax=2)的分段线性函数,以评估当增长率发生变化时的阈值(公式(6))。每个估计区间的p值通过使用名义水平α=0.05的评分统计检验获得。
的日值进行分段回归分析植物生长,以检测这些表型性状发育过程中的显著变异(断点、Ks)。在线性分段上拟合了一个具有指定最大断点数(Kmax=2)的分段线性函数,以评估当增长率发生变化时的阈值(公式(6))。每个估计区间的p值通过使用名义水平α=0.05的评分统计检验获得。

y是![]() 或
或![]() 当x是Day After Sowing(DAS)和
当x是Day After Sowing(DAS)和![]() ,
,![]() 或
或![]() 当x是Day After Emergence(DAE),
当x是Day After Emergence(DAE), 和
和 (i=1、2)子函数的拦截和斜率,ε是错误项和Kn结果断点-n(n={1、2})。
(i=1、2)子函数的拦截和斜率,ε是错误项和Kn结果断点-n(n={1、2})。
2、对土壤水分有效性的动态形态-生理响应
各植株的日生长高度(cm)和叶面积发育(cm2)率分别为连续日![]() 和
和![]() 的差异,
的差异,
用植株失水量(g)除以![]() 得到日蒸腾速率(
得到日蒸腾速率(![]() ;g/cm2)。
;g/cm2)。
为了减少环境波动的影响,首先使用3天移动平均函数对![]() 、
、![]() 和
和![]() 率进行处理,并将胁迫植物的日平均速率除以对照植物的日平均速率归一化。
率进行处理,并将胁迫植物的日平均速率除以对照植物的日平均速率归一化。
第二种归一化分别表示为植物高度相对生长(rPH)、相对叶片发育(rTLA)和相对蒸腾量(rTR)。
可转化土壤水(FTSW)的比例 (必要时每个花盆都要称重,直到达到相对蒸水的终点,rTR=0.10)

 为当天上午记录的花盆重量(g),
为当天上午记录的花盆重量(g),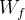 为rTR达到0.10当天的花盆重量(g),FCW为最高有效水量的花盆重量(g)。
为rTR达到0.10当天的花盆重量(g),FCW为最高有效水量的花盆重量(g)。
通过将rPH、rTLA和rTR速率作为每个盆栽水分亏缺的函数,确定个体植物对水分处理的形态生理响应(公式(8))。该模型中不包括生长后期叶片脱落导致的负rTLA值。作为水分胁迫的证据,当植物生长发生显著变化时(断点、Kmax=2和α=0.05)时,估计rPH和rTR的FTSW阈值。
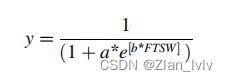
其中,y为rPH、rTLA或rTR变量,a和b为通过非线性回归分析估计的经验系数。
确定番茄品种对内非线性回归分析估计的回归系数之间差异的显著性(公式(9)),以检验它们在水分胁迫条件下的行为相似性。
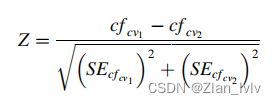
式中,![]() 是第一(
是第一(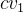 )和第二(
)和第二(![]() )测试品种的经验回归系数(a或b),
)测试品种的经验回归系数(a或b),![]() 是与n个品种相关的系数方差。
是与n个品种相关的系数方差。
数据分析指标


式中, 为观测值i,O为观测值的平均值,
为观测值i,O为观测值的平均值, 为模拟值i,n为观测数,K为模型中估计参数的个数,
为模拟值i,n为观测数,K为模型中估计参数的个数,![]() 是该模型的最大似然函数的值。
是该模型的最大似然函数的值。
实验结果(3 Result)
plant height (R2 = 0.98, RMSE = 0.34 cm, MAPE = 3.12% and AIC = 6.03)
petioles inclination (R2 = 0.96, RMSE = 1.35◦, MAPE = 3.64% and AIC = 22.16)
single-Leaf Area (R2 = 0.98, RMSE = 0.95 cm2 , MAPE = 7.40% and AIC = 14.91)
single-leaf angle (R2 = 0.84, RMSE = 1.43◦, MAPE = 2.17% and AIC = 15.83)
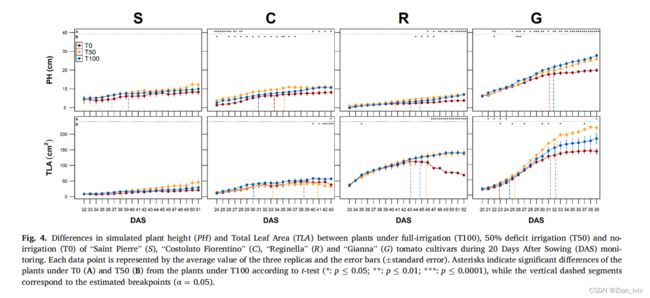



Discussion
我们的方法不需要手动标记3d数据作为解剖单个器官和估计其生长方向的先验知识。因为用于自适应分割的攀爬球的数学和方向参数和方向参数是根据每个植物的实际几何和拓扑特性自动调整的。因此,我们基于点的分析对整体和成分表型的形状随时间的变化是稳健的,而不是之前针对具有相似生长习惯的特定枝条结构量身定制的分割策略。
在这种情况下,我们的向上分割对于准确捕捉植物任意变化的拓扑结构至关重要,因为它提供了与其他实例相比被分析的器官空间分布的信息。这使得根据它们对整体表型(如主茎和冠层)的有序排列,可以对单个成分(如叶、叶柄和分支)进行分类,这是自动跟踪不同时间描述的同一器官的关键。
该算法的主要优点是能够自动将植物三维模型自动分类为主茎、叶柄和叶(平均成功率=95.74%)。与基于二维图像的方法会由于器官闭塞而不可避免的分割失败不同,本研究的三维数据驱动算法避免了深度信息的缺乏,以更好地识别植物的主要形态特征。与其他用人工提取图像的方法相比,我们的方法在器官尺度分割的准确率提高了10.68%。