Java——数组的引用类型与应用
目录
前言
1. JVM内存分布
2. 数组的引用类型
2.1 引用类型的含义
2.2 共享性和引用传递
2.3 初始化与存储
2.3.1 数组的引用复制
2.3.2 初始化的区别
3. 数组的应用
3.1 遍历数组
3.2 查找数组中的指定元素
3.3 数组的拷贝
3.4 冒泡排序
3.5 数组逆序
4. 二维数组
总结
前言
在上一篇的内容中,我们已经了解了数组的基本概念、定义、初始化和基本使用方法。现在,我们进一步深入研究数组,了解更多有关引用类型、内存分布以及应用方面的知识。
在本篇文章中,我们将探讨数组的引用类型,这将帮助我们更好地理解数组在内存中的存储和传递方式。我们还将研究数组的一些应用,包括遍历、查找、拷贝和排序等操作并了解二维数组,这些操作对于处理数据非常重要。
接下来我们将一起深入研究这些概念,为了更好地理解,我们将从JVM内存分布开始,逐步探讨数组在Java编程中的关键角色。希望这篇文章将为您提供有关数组更深入的见解,并帮助您在实际编程中更好地利用它们。
1. JVM内存分布

在开篇的 Java—缘起 中我们介绍过,JVM(Java虚拟机)是Java程序的运行环境,而它在运行时会将内存划分为不同的区域来承载不同的数据和功能。下面是初始JVM的内存分布:
-
程序计数器(Program Counter Register):它是一块较小的内存区域,用于存储当前线程执行的字节码指令的地址。在线程之间切换时,程序计数器会被更新到下一条需要执行的指令。
-
Java虚拟机栈(Java Virtual Machine Stacks):每个Java线程在运行时都会有一个对应的栈,用于存储局部变量、方法调用和方法返回等信息。每个方法在执行的时候都会创建一个栈帧,栈帧中包含了方法的局部变量和操作数栈等。
-
本地方法栈(Native Method Stacks):与Java虚拟机栈类似,用于执行Native方法的栈。
-
堆(Heap):用于存储对象实例。所有的对象都在堆上分配内存空间,并且由垃圾收集器自动管理。堆是JVM中最大的一块内存区域,也是GC(垃圾收集)的主要工作区域。
-
方法区(Method Area):用于存储已加载的类信息、常量、静态变量、编译器编译后的代码等。在Java 8及以前的版本中,方法区被实现为永久代(Permanent Generation)。而在Java 8及以后的版本中,方法区被实现为元数据区(Metaspace)。
需要注意的是,以上是初始的JVM内存分布,实际上,JVM的内存结构还可能包括其他内存区域,如直接内存(Direct Memory)等。此外,不同的JVM实现或配置也可能会有所不同。
But,当下我们研究数据的引用类型时,只需先了解堆和虚拟机栈即可。(其他内容在后续学习中介绍)

2. 数组的引用类型
2.1 引用类型的含义
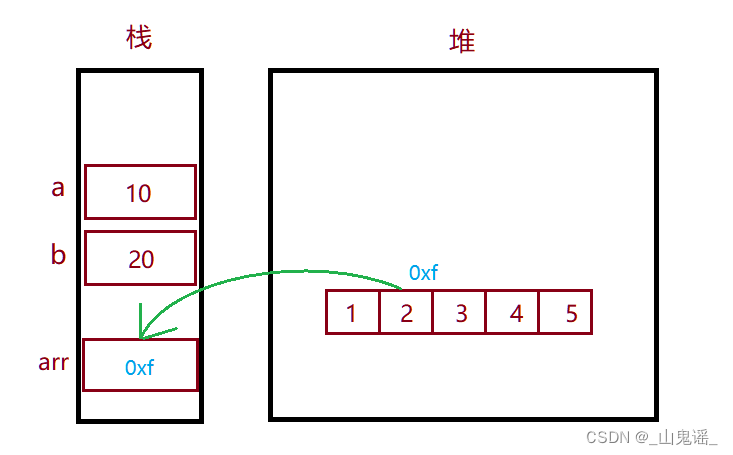
在Java语言中,数组被视为引用类型。' 引用类型 ' 是指在内存中只保存了对象或数据的地址(栈上保存),而不是直接保存对象或数据本身(堆上保存)的值。当创建一个数组时,实际上是在内存中分配了一块连续的内存空间来存储数组的元素。这个数组变量本身实际上是一个指向该内存空间的引用,而不是直接保存数组的值。
例:定义整形 a,b 与 整形数组 arr
publi static void func(){
int a = 10;
int b = 20;
int[] arr = {1,2,3,4,5};
}上述代码中,a、b、arr,都是函数内部的变量,因此其空间都在方法对应的栈帧中分配。
- a、b是基本数据类型的变量,因此其空间中保存的就是给该变量初始化的值。
- arr 是数组类型的引用变量,其内部保存的内容可以理解为数组在堆空间中的地址。
其内存分布如下图 ↓
2.2 共享性和引用传递
由于数组是引用类型,对数组变量的操作实际上是对该内存空间的操作。这意味着 多个数组变量可以引用同一个数组对象,它们可以共享相同的值和内存地址。对数组对象的修改会影响到所有引用该数组对象的变量。
当我们将一个数组赋值给另一个数组变量时,实际上是将数组对象的引用复制给了新的变量,而不是将数组的内容进行复制。因此,新的变量和原始变量会指向同一个数组对象。
同时,当对数组进行修改时,无论是通过原始变量还是其他引用变量进行的操作,都会反映在所有引用变量上。这是因为它们实际上都指向同一个内存位置,即同一个数组对象。
例:
int[] arr1 = {1,2,3,4,5,6}; //定义数组arr1并赋值
int[] arr2 = arr1; //定义数组arr2等于arr1
//更改arr1的0下标位置为5,分别打印两数组
arr1[0] = 6;
System.out.println(Arrays.toString(arr1));
System.out.println(Arrays.toString(arr2));
//分割线
System.out.println("***************");
//更改arr2的5下标位置为0,分别打印两数组
arr2[5] = 0;
System.out.println(Arrays.toString(arr1));
System.out.println(Arrays.toString(arr2));运行结果:
 通过代码的运行结果可以看出,
通过代码的运行结果可以看出,arr1 和 arr2 实际上引用的是同一个数组对象。因此,对于任一数组的修改操作都会同时影响到另一个数组,因为它们共享同一个内存空间。
内存示意图: ↓

2.3 初始化与存储
2.3.1 数组的引用复制
在Java中,当我们创建一个新的数组时,如果该数组已经存在,新数组并不会在堆上新开辟一块内存空间,而是直接使用已有数组的地址。这种机制称为数组的引用复制或共享。简而言之,新数组与原数组共享相同的内存地址。
int[] arr1 = {1,2,3,4,5,6};
int[] arr2 = {6,5,4,3,2,1};
int[] arr3 = {1,2,3,4,5,6};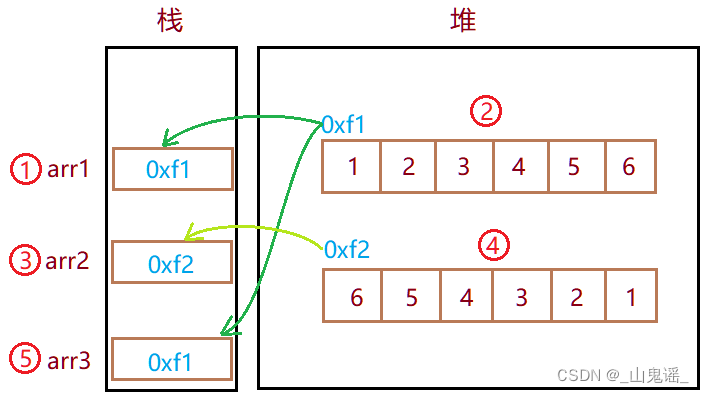
这种设计有助于提高内存利用率和程序的性能。因为在许多情况下,我们可能只是需要一个副本或者对原数组进行一些改动,而不需要额外分配新的内存空间。通过共享地址,我们可以避免不必要的内存分配和复制操作。
2.3.2 初始化的区别
在Java中,int[] arr = {1,2,3,4,5}; 和 int[] arr = new int[]{1,2,3,4,5}; 两种方式都是创建一个数组对象,并将该对象的引用存储在变量 arr 中,但是二者在内存大储存中略有不同。
具体来说:
- int[] arr = {1,2,3,4,5}; 使用了数组的初始化简写方式,它会在编译时期将简写的形式转化为完整的形式,即 int[] arr = new int[]{1,2,3,4,5};。在这种情况下,arr 存储的是在堆内存中创建的数组对象的地址。
- int[] arr = new int[]{1,2,3,4,5}; 是一种显式创建数组对象的方式。通过 new int[]{1,2,3,4,5} 创建了一个新的数组对象,并将该对象的地址存储在 arr 变量中。在这种情况下,确实是在堆内存中创建了一个新的数组对象,并将其地址存储在 arr 中。
例:
int[] arr1 = {1,2,3,4,5,6}; //定义arr1
int[] arr2 = arr1;
int[] arr3 = new int[]{1,2,3,4,5,6};
boolean x = (arr1 == arr2);
boolean y = (arr1 == arr3);
System.out.println(x+"\n"+y);
输出:
true
false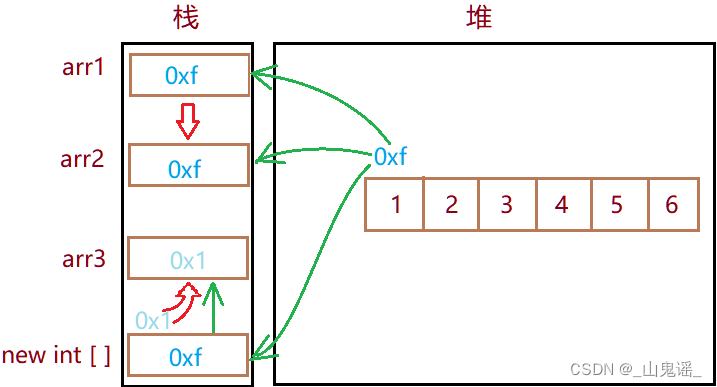
3. 数组的应用
3.1 遍历数组
遍历数组最简单的方式就是获取到数组每个下标所对应的值并将其打印:
int[] arr = {1,2,3};
Systme.out.println(arr[0]);
Systme.out.println(arr[1]);
Systme.out.println(arr[2]);
输出:
1
2
3但是,如果当数组容量较大时,显然不能使用这种方式,这时候我们可以通过前面学到的 for 循环遍历打印数组:
int[] arr = {1,2,3,4,5,6};
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
输出:
1
2
3
4
5
6也可以写成 for-each 的形式:
int[] arr = {1,2,3,4,5,6};
for (int j : arr) {
System.out.println(j);
}如果我们仅仅需要将数组打印出来,则可以用上期所讲到的Arrays.toString()来将数组转换为字符串类型并打印:
int[] arr = {1,2,3,4,5,6};
System.out.println(Arrays.toString(arr));
//需在文件开头import java.util.Arrays;
输出:
[1, 2, 3, 4, 5, 6]3.2 查找数组中的指定元素
1.顺序查找
遍历数组,逐一判断是否为目标数字 :
public static int find(int[] arr, int n) {
for (int i : arr) {
if (arr[i] == n) {
return i;
}
public static void main(String[] args) {
int[] arr = {1,6,5,0,4,3};
System.out.println(find(arr, 0));
}
输出:32.二分查找
现将数组排序,后取中间位置的元素, 将其与指定元素比较:
- 如果相等,即找到了返回该元素在数组中的下标
- 如果小于,以类似方式到数组左半侧查找
- 如果大于,以类似方式到数组右半侧查找
public static void main(String[] args) {
int[] arr = {1,6,5,0,4,3};
System.out.println(ret(arr, 0));
}
public static int ret(int[] arr, int n) {
Arrays.sort(arr);
int l = 0;
int r = arr.length - 1;
while (l <= r) {
int mid = (l + r) / 2;
if (n < arr[mid]) {
r = mid - 1;
} else if (n > arr[mid]) {
l = mid + 1;
} else {
return mid;
}
}
return -1;
}
输出:
0相较于顺序查找,二分查找算法在对有序数组进行查找时效率更高,而且随着数据规模的增大,其性能优势会更加明显。但是需要注意的是,二分查找要求数据必须有序,如果数据无序或频繁变动,就需要重新排序或使用其他查找算法。
3.3 数组的拷贝
前边我们提到了数组之间存在共享性与应用传递,那么如何能复制出一个完全独立于原数组的新的数组呢,这时就可以使用 Arrays 类中的 copyOf( ) 方法实现对数组的拷贝。
该方法会创建并返回一个新的数组对象,其中包含原始数组中的所有元素。新数组与原数组是完全独立的,对新数组的修改不会影响原数组,反之亦然。
Arrays.copyOf(目标数组,数组长度);
例:
import java.util.Arrays;// 文件头部添加
int[] arr = {1, 2, 3, 4, 5};
int[] newArr = Arrays.copyOf(arr,arr.length);//克隆arr
arr[0] = 6;
System.out.println(Arrays.toString(arr));
System.out.println(Arrays.toString(newArr));
System.out.println("******************");
newArr[1] = 9;
System.out.println(Arrays.toString(arr));
System.out.println(Arrays.toString(newArr));
输出:
[6, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
******************
[6, 2, 3, 4, 5]
[1, 9, 3, 4, 5]通过打印结果可以看出,通过克隆产生的新数组与原数组之间完全独立,它们之间不会相互影响。对新数组的修改不会改变原数组的值,同样,对原数组的修改也不会影响新数组的值。
还可以控制拷贝范围: Arrays.copyOfRange(目标数组 ,起始位置,结束位置);
例:
int[] arr = {1, 2, 3, 4, 5};
int[] newArr = Arrays.copyOfRange(arr,1,4);
System.out.println(Arrays.toString(newArr));
输出:
[2, 3, 4]注意:起始与终止位置左开右闭—— [ 1 , 4) 。
3.4 冒泡排序
关于数组的排序,除了Java内置的 sort( ) 方法,我们也可以自己通过代码来实现;
冒泡排序思路:
以升序为例,从第一个元素开始逐一向后比较,遇到后者比前者大,则调换位置,当行进到末尾时,最后一位元素一定是数组中最大的,此时回到第一个元素继续向后比较直到倒数第二个元素,如此循环,循环 n 次(n 为数组长度)后数组排序完成。
实践代码:
public static String func(int[] arr) {
for (int i = 0; i < arr.length; i++) { // 外层循环,控制内循环的次数
for (int j = 0; j < arr.length-i-1; j++) { // 内循环从头至尾依次排序
if (arr[j] > arr[j+1]) {
int m = arr[j]; // 交换元素
arr[j] = arr[j+1];
arr[j+1] = m;
}
}
}
return Arrays.toString(arr); // 将数组转换成字符串用于输出
}
public static void main(String[] args) {
int[] arr = {1,6,4,5,8,1,9,7,3,8,2};
System.out.println(func(arr));
}
输出:
[1, 1, 2, 3, 4, 5, 6, 7, 8, 8, 9]3.5 数组逆序
介绍过了顺序排列接下来我们来了解数组的逆序。
逆序思路:
对于给定的数组,我们设立两个下标,一个指向数组的首位,一个指向数组的末位。然后进行以下操作:将首尾元素进行互换,并分别将首下标自增,尾下标自减。然后继续循环执行交换操作,直到两个下标相遇或首下标小于尾下标为止。最后返回得到的新数组。
实现代码:
public static void func(int[] arr){
int start = 0; // 定义起始下标
int end = arr.length - 1; // 定义末尾下标
while (start < end) { // 当起始下标小于末尾下标时执行循环
int m = arr[start];
arr[start] = arr[end];
arr[end] = m;
start++; // 起始下标自增
end--; // 末尾下标自减
}
System.out.println(Arrays.toString(arr)); // 输出交换后的数组
}
public static void main(String[] args) {
int[] arr1 = {1, 2, 3, 4, 5};
int[] arr2 = {2, 4, 6, 8, 10};
func(arr1);
func(arr2);
}
输出:
[5, 4, 3, 2, 1]
[10, 8, 6, 4, 2]4. 二维数组
在Java中,二维数组是一种特殊的数组类型,它可以理解为包含其他数组的数组,也就是数组的数组。
定义方法:
1. 使用指定的行数和列数来创建一个二维数组:
数据类型[ ][ ] 数组名称 = new 数据类型[行数][列数];
2. 使用初始化数据来创建一个二维数组,可以省略行数和列数的指定,由初始化数据自动确定:
数据类型[ ][ ] 数组名称 = new 数据类型[][] {
{初始化数据1},
{初始化数据2},
// 更多行
};
3. 或者更简洁地写成:
数据类型[][] 数组名称 = {
{初始化数据1},
{初始化数据2},
// 更多行
};
需要注意的是:对于二维数组,直接使用 Arrays.toString() 方法是不会以期望的方式打印其内容的。这是因为 Arrays.toString() 方法返回的是每个元素的引用,而在二维数组中,每个元素实际上是一个数组对象,它会默认调用 Object 类的toString ( ) 方法,以显示对象的内存地址。因此 Arrays.toString() 方法会返回一串数组对象的地址,而不是我们期望的数组内容。所以,我们通常需要使用嵌套循环来遍历并打印二维数组的内容,以确保每个元素都能以正确的格式显示出来。
public static void main(String[] args) {
int[][] arr = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};
// toString打印
System.out.println(Arrays.toString(arr));
System.out.println("++++++++++++++++++");
// 遍历并打印二维数组的内容
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr[i].length; j++) {
System.out.print(arr[i][j] + " ");
}
System.out.println(); // 换行
}
}
输出:
[[I@1b6d3586, [I@4554617c, [I@74a14482]
++++++++++++++++++
1 2 3
4 5 6
7 8 9 通过结果可以看到:需要使用嵌套循环来遍历并逐个打印数组元素,才能确保以所需的格式显示二维数组的内容。
关于二维数组的其他使用方式与一维数组相同,此处不在赘述。
总结
本文深入研究了Java数组的引用类型、内存分布和部分应用。我们了解了数组的引用类型,即数组变量存储的是数组对象的地址。我们学习了如何遍历、查找、拷贝和排序数组,以及二维数组的定义和打印方法。最重要的是,我们理解了数组的引用性质,使多个数组变量可以共享相同的数组对象。这些知识将有助于更好地理解和应用数组在Java编程中的关键作用。
