剑指OFFER刷题笔记 Kaze-1
剑指OFFER刷题记录
- 数据结构:链表,队列,栈
-
-
- JZ24 反转链表
- JZ25 合并两个排序的链表
- JZ52 找两个链表的第一个公共结点
-
- 数据结构:图论,树
-
-
- JZ82 二叉树中和为某一值的路径(一)
- JZ34 二叉树中和为某一值的路径(二)
-
- 算法
-
- 模拟
-
- JZ29 顺时针打印矩阵
-
- 原创解法
- 受LC讨论区启发的解法
- 动态规划
-
- JZ42 连续子数组的最大和
- JZ85 连续子数组的最大和(二)
数据结构:链表,队列,栈
JZ24 反转链表
牛客网链接
难度:简单
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* ReverseList(ListNode* pHead) {
//初始化部分(初始化指针p,pre等) 有时还要初始化q, pNext
ListNode*p=pHead; //“基础指针”p从第一个元素开始
ListNode*pre=nullptr; //pre自然初始化成nullptr
ListNode*pNext=nullptr;
while(p!=nullptr)//遍历条件部分
{
//操作部分
pNext=p->next;
p->next=pre;
//遍历迭代部分
pre=p;
p=pNext;
}
return pre;
}
};
链表是基础数据结构——线性表的一种,另一种是顺序表,常见的各类数据的数组,字符串等都是顺序表。所以顺序表不会专门考察。
简单链表题的通解
如上述代码所示,简单的链表题解法往往只包含一次对单个链表的遍历,这一次遍历中即可完成很多题目要求的操作(打印,反转,求和,删除,查找等等)
代码模板如下:
分成初始化部分和遍历部分(遍历条件和迭代部分不用更高)
显然,只用更改初始化部分和操作部分就够了
//初始化部分(初始化指针p,pre等) 有时还要初始化q, pNext
ListNode*p=pHead; //“基础指针”p从第一个元素开始
ListNode*pre=nullptr; //pre自然初始化成nullptr
其他指针初始化(如果有必要)
while(p!=nullptr)//遍历条件部分
{
//操作部分
通过p,pre等指针对链表执行操作
//遍历迭代部分
pre=p;
p=pNext;
}
//此时p=nullptr, pre
JZ25 合并两个排序的链表
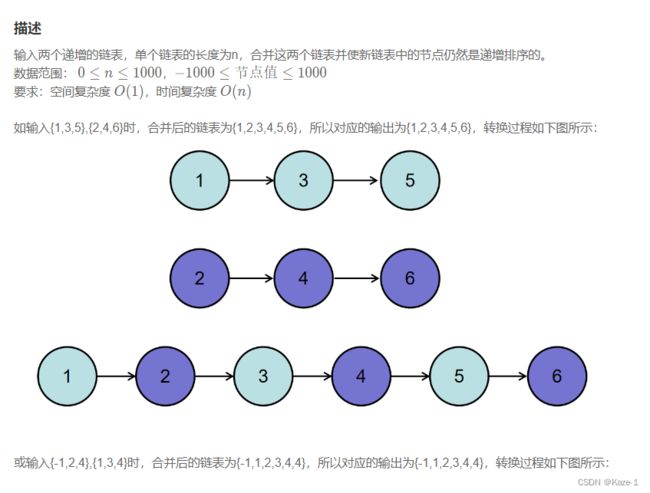
最优算法时间复杂度O(N),空间复杂度O(1)
递归解法:
class Solution {
public:
ListNode* Merge(ListNode* pHead1, ListNode* pHead2) {
if(pHead1==nullptr)
return pHead2;
else if(pHead2==nullptr)
return pHead1;
else if(pHead1->val>pHead2->val)
{pHead2->next=Merge(pHead1,pHead2->next);
return pHead2;}
else
{
pHead1->next=Merge(pHead2,pHead1->next);
return pHead1;
}
}
};
非递归:(迭代方式)
ListNode* Merge(ListNode* pHead1, ListNode* pHead2) {
if(pHead1==nullptr)
return pHead2;
else if(pHead2==nullptr)
return pHead1;
ListNode *cur=new ListNode(-1);//新建一个链表头,而不是只是建个指针
ListNode *res=cur;//备份一下表头(之后cur要移动)
while(pHead1&&pHead2)
{
if(pHead1->val<pHead2->val)
{
cur->next=pHead1;
pHead1=pHead1->next;
}
else
{
cur->next=pHead2;
pHead2=pHead2->next;
}
cur=cur->next;//别忘记!
}
if(pHead1==nullptr)
cur->next=pHead2;
else cur->next=pHead1;
return res->next;
}
JZ52 找两个链表的第一个公共结点
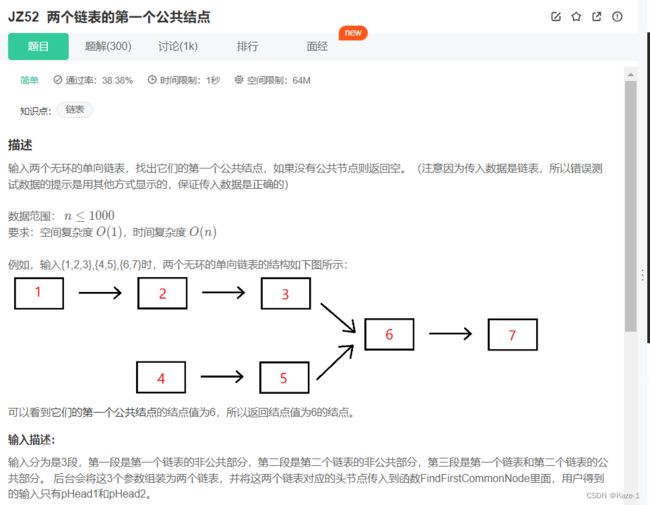
双指针法:
需要组合数学的基础,一个指针遍历到表尾就顺接着遍历另一个表,如果有相同部分则必定相遇(不太好想)
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
ListNode *l1 = pHead1, *l2 = pHead2;
while(l1 != l2){
l1 = (l1==nullptr)?pHead2:l1->next;
l2 = (l2==nullptr)?pHead1:l2->next;
}
return l1;
数据结构—集合:
用集合查重,分别遍历一次就完事
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
set<ListNode*>visited;
ListNode *p1 = pHead1, *p2 = pHead2;
while(p1)
{
visited.insert(p1);
p1=p1->next;
}
while(p2)
{
if(visited.find(p2)!=visited.end())
return p2;
p2=p2->next;
}
return nullptr;
}
数据结构:图论,树
JZ82 二叉树中和为某一值的路径(一)
牛客网链接
难度:简单
题目:给定一个二叉树root和一个值 sum ,判断是否有从根节点到叶子节点的节点值之和等于 sum 的路径。
1.该题路径定义为从树的根结点开始往下一直到叶子结点所经过的结点
2.叶子节点是指没有子节点的节点
3.路径只能从父节点到子节点,不能从子节点到父节点
4.总节点数目为n
class Solution {
public:
/**
*
* @param root TreeNode类
* @param sum int整型
* @return bool布尔型
*/
bool hasPathSum(TreeNode* root, int sum) {
//用rLR遍历的思想
if(root==nullptr)return false;
return(rLR_path(root,sum,0));
// write code here
}
bool rLR_path(TreeNode* root, int sum, int path_val)
{
if(root==nullptr)return false;
path_val+=root->val;
if(path_val==sum&&root->left==nullptr
&&root->right==nullptr)return true;
else
return rLR_path(root->left,sum,path_val)||
rLR_path(root->right,sum,path_val);
}
};
思路:rRL遍历即可(事实上四种遍历方法都可以),判断当前节点是否为根节点并且积累了刚刚好的路径长度,否则就继续向下扫描
和链表题一样,简单的数据结构题解就是基于基础的遍历算法稍加改造
二叉树的遍历方法是rLR, LrR, LRr, 层次遍历,一共四种
PS: 进一步的优化方法:剪枝算法,如果上述终止条件没满足,并且当前积累的路径长度超过了sum,就直接返回false,不再遍历这个节点的子代
因为当前题解已经通过了,就没继续优化
JZ34 二叉树中和为某一值的路径(二)
难度相比JZ82有了更进一步的提升,要求vector形式返回所有的满足条件的路径,需要使用栈的操作(push, pop)来回溯,从而检验和存储可行路径
也就是带记忆的DFS/全局变量下DFS
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
vector<vector<int>> FindPath(TreeNode* root,int expectNumber) {
if(root==nullptr)return{};
vector<vector<int>> all_path={};
CollectPath(root,expectNumber,all_path,{});//从根开始DFS
return all_path;
}
//DFS函数部分:带记忆的DFS
void CollectPath(TreeNode* root,int s,
vector<vector<int>>& all_path,vector<int> path)
{
//先访问该节点自身
if(root==nullptr)return;
path.push_back(root->val);
if(root->left==nullptr&&root->right==nullptr
&&root->val==s)
{all_path.push_back(path);//收纳可行路径
return; }
//再访问左右子节点
CollectPath(root->left, s-root->val, all_path, path);
CollectPath(root->right, s-root->val, all_path, path);
//回溯操作(要求输出单个节点所有可行路径时需要回溯来检验-记录节点,也就是需要DFS时,用回溯舍弃掉“走不通”的节点)
path.pop_back();
}
};
重要:对二叉树而言,最常用的DFS方法就是rLR+回溯(栈),用于回溯的栈(vector)可以是全局变量或者是引用类型形参,因为要同时更新多个参数,不宜设置函数返回值(直接void类型即可)
封装性考虑:引用类型形参
简便性考虑:全局变量
解题通法为:
访问节点自身,检验返回条件—(没有return)—>递归调用,访问左右子结点—(没有return)—>回溯(弹栈)
算法
模拟
JZ29 顺时针打印矩阵
题目:
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如,如果输入如下4 X 4矩阵:
[[1,2,3,4],
[5,6,7,8],
[9,10,11,12],
[13,14,15,16]]
则依次打印出数字
[1,2,3,4,8,12,16,15,14,13,9,5,6,7,11,10]
原创解法
用状态值判断当前“输出流”的状态(0,1,2,3),然后让输出流顺时针移动
class Solution {
public:
vector<int> printMatrix(vector<vector<int>> matrix)
{
int m = matrix.size();//行数
int n = matrix[0].size();//列数
//用拷贝构造函数初始化flags为m*n 全为0的矩阵
vector<vector<int>> flags(m, vector<int>(n));
int status = 0;//记录当前节点的状态(移动方向 0->1->2->3)
int num, i = 0, j = 0;
vector<int>res;
for (num = 0; num < m * n; num++)
{
//访问:打印,标记
res.push_back(matrix[i][j]);
flags[i][j] = 1;
//边界处理部分 更新flags和status
if ((j == n - 1 || (j!=n-1&&flags[i][j + 1])) && status == 0)
status++;
else if ((i == m - 1 || (i!=m-1&&flags[i + 1][j])) && status == 1)
status++;
else if ((j == 0 || (j!=0&& flags[i][j - 1])) && status == 2)
status++;
else if ((i == 0 || (i!=0&&flags[i - 1][j])) && status == 3)
status = 0;
//移动部分
if (status == 0)
j++;
else if (status == 1)
i++;
else if (status == 2)
j--;
else if (status == 3)
i--;
}
return res;
}
};
模拟部分(循环体)思路:
模拟一个指针,按题目顺序逐个访问矩阵节点,然后移动即可,使用i,j两个坐标指明指针的位置
分成两块:
- 访问该点:
1、打印和标记已经访问
2、检查边界条件——如果该点在边界上,要更新status - 移动指针:
根据status的值来移动 - 缺点:维护状态值较为繁琐
受LC讨论区启发的解法
vector<int> spiralOrder(vector<vector<int>>& matrix) {
int m = matrix.size();//行数
int n = matrix[0].size();//列数
int top = 0, bottom = m - 1, left = 0, right = n - 1, i, j;
vector<int>res;
while (bottom >= top && right >= left)//循环继续条件:严格大于
{
for (i = left; i <= right; i++)
res.push_back(matrix[top][i]);
top++;
for (i = top; i <= bottom; i++)
res.push_back(matrix[i][right]);
right--;
for (i = right; i >= left; i--)
res.push_back(matrix[bottom][i]);
bottom--;
for (i = bottom; i >= top; i--)
res.push_back(matrix[i][left]);
left++;
}
while (res.size() > m * n) //有时会多push一两个点
res.pop_back();
return res;
}
只用维护四个坐标值(top, bottom, left, right)描述出当前的矩阵边缘即可,更容易更新维护。
略微缺点是边界条件不好找,可以放宽边界条件(使用 ≤ \leq ≤, ≥ \geq ≥),最后将多余入栈的部分弹出。
动态规划
JZ42 连续子数组的最大和
输入一个长度为n的整型数组array,数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
数据范围:
1 < = n < = 1 0 5 1 <= n <= 10^5 1<=n<=105
− 100 < = a [ i ] < = 100 -100 <= a[i] <= 100 −100<=a[i]<=100
要求:时间复杂度为 O ( n ) O(n) O(n),空间复杂度为 O ( n ) O(n) O(n)
进阶:时间复杂度为 O ( n ) O(n) O(n),空间复杂度为 O ( 1 ) O(1) O(1)
class Solution {
public:
int FindGreatestSumOfSubArray(vector<int> array) {
vector<int> S_max(array.size(),0);
int res=array[0];
for(int i=0;i<array.size();i++)
{
//DP一定是递归方程!下一个状态对上一次的解进行最优筛选,转移到当前最优解
S_max[i]=max(S_max[i-1]+array[i], array[i]);
res=max(res,S_max[i]);
}
return res;
}
};
用 S m a x ( i ) S_{max}(i) Smax(i)表示当前第i个元素结尾构成字串的和
状态转移方程为:
S m a x ( i ) = m a x ( S m a x ( i − 1 ) + a r r a y ( i ) , a r r a y ( i ) ) S_{max}(i)=max(S_{max}(i-1)+array(i),array(i)) Smax(i)=max(Smax(i−1)+array(i),array(i))
JZ85 连续子数组的最大和(二)
输入一个长度为n的整型数组array,数组中的一个或连续多个整数组成一个子数组,找到一个具有最大和的连续子数组。
和上一道题类似,但是要求更进一步了,要求输出最长数组本身
思路是在上一次迭代 S m a x ( i ) S_{max}(i) Smax(i)的同时,用一个数组 r e s ( i ) res(i) res(i)来存储末端为 i i i元素的子串的起始点,从而记录 S m a x ( i ) S_{max}(i) Smax(i)的同时也记录下了对应的具体子串。
一边遍历完后再根据记录输出即可
#include注意:
对于vector而言:
v e c t o r . b e g i n ( ) + v e c t o r . s i z e ( ) = v e c t o r . e n d ( ) vector.begin()+vector.size()=vector.end() vector.begin()+vector.size()=vector.end()恒成立
所以begin()相当于是0, end()相当于是n,而所有需要传入起始和结尾元素迭代器的函数:eg max_element(),min_element(),accumulate()等
都是左闭右开区间
所以上述代码中对array的闭区间 [ r e s [ i ] , i ] [res[i],i] [res[i],i]求和时需要执行的是
sum_tem=accumulate(array.begin()+res[i],array.begin()+i+1,0);
而不是
sum_tem=accumulate(array.begin()+res[i],array.begin()+i,0);//这样会少加一个array[i]