大数据研发工程师课前环境搭建
大数据研发工程师课前环境搭建
第一章 VMware Workstation 安装
在Windows的合适的目录来进行安装,如下图

1.1 双击打开
1.2 下一步,接受协议
1.3 选择安装位置
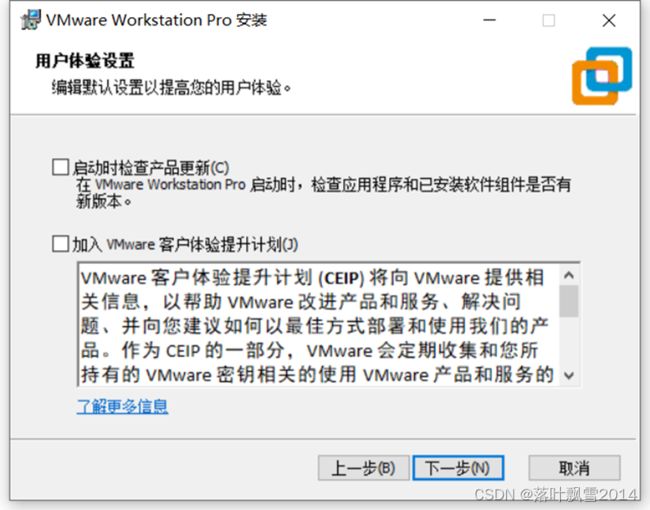
1.4 用户体验设置
1.5 快捷方式

已经准备好安装,点击安装
1.6 安装中

1.7 安装完成
1.8 启动界面
注意,需要注册的时候,自己解决。
第二章 安装CentOS7操作系统
2.1 点击新建虚拟机
选择自定义安装

2.2 选择虚拟机硬件兼容性,默认即可
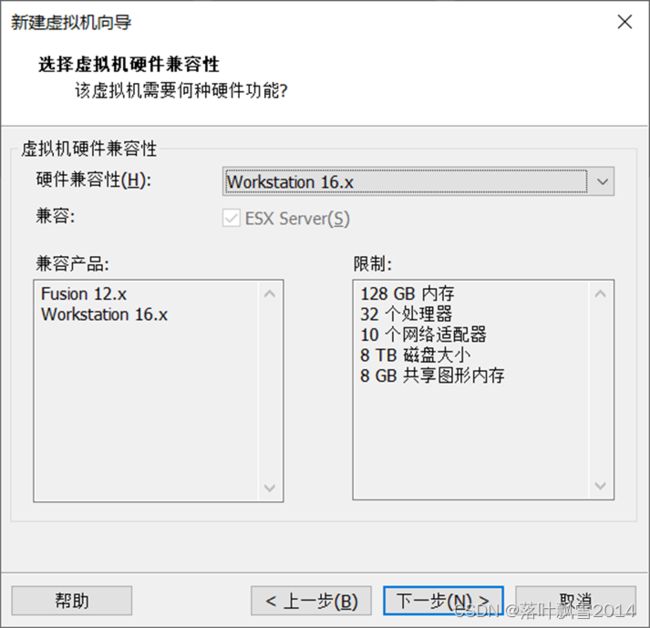
2.3 选择安装的操作系统位置
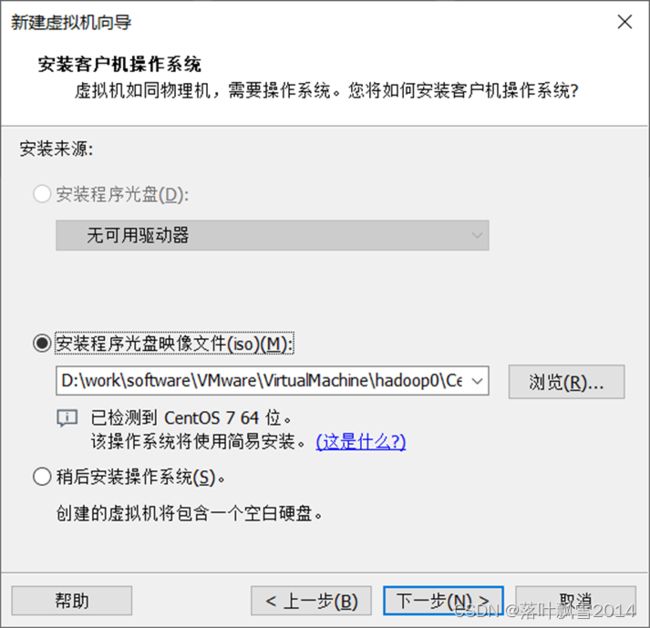
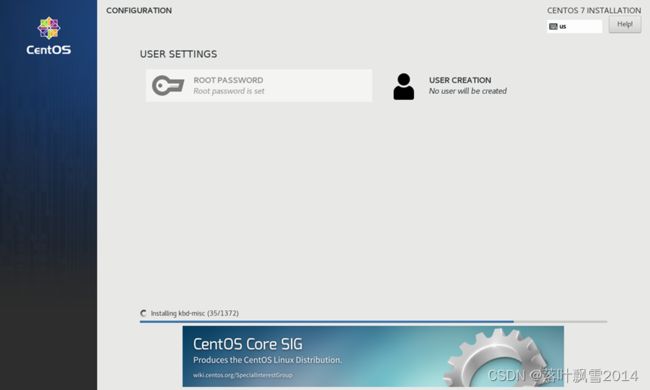
2.4 创建用户和密码
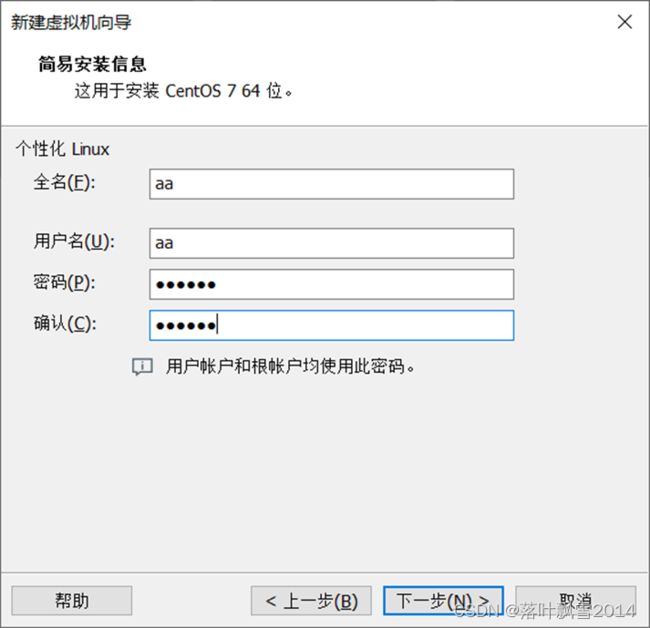
2.5 命名虚拟机并选择安装位置
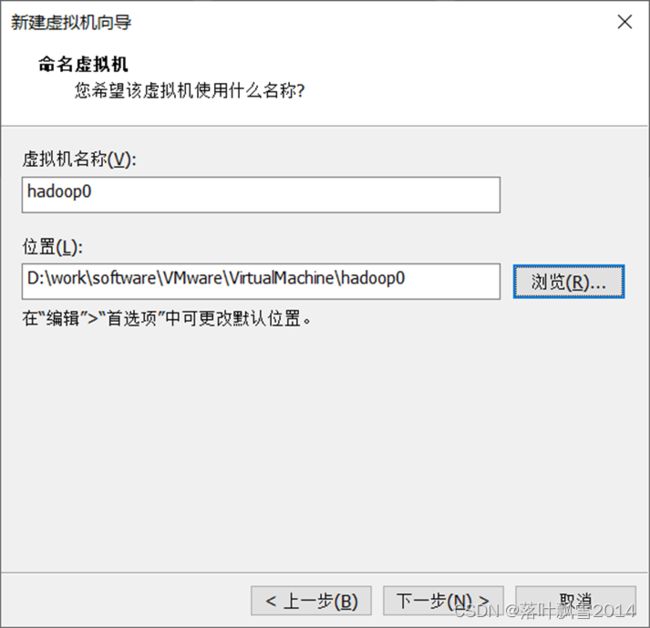
2.6 处理器配置
根据自己的电脑的设置配置即可,后期可更改。

2.7 设置内存
根据自己的机器配置设置即可
2.8 设置网络类型
选择NAT即可
2.9 选择I/O控制器类型
默认即可
2.10 选择磁盘类型
默认即可

2.11 选择使用的磁盘

2.12 指定磁盘大小
尽量设置大一些,50gb往上。

2.13 指定磁盘文件
默认即可
2.14 已准备好创建虚拟机,确认页面
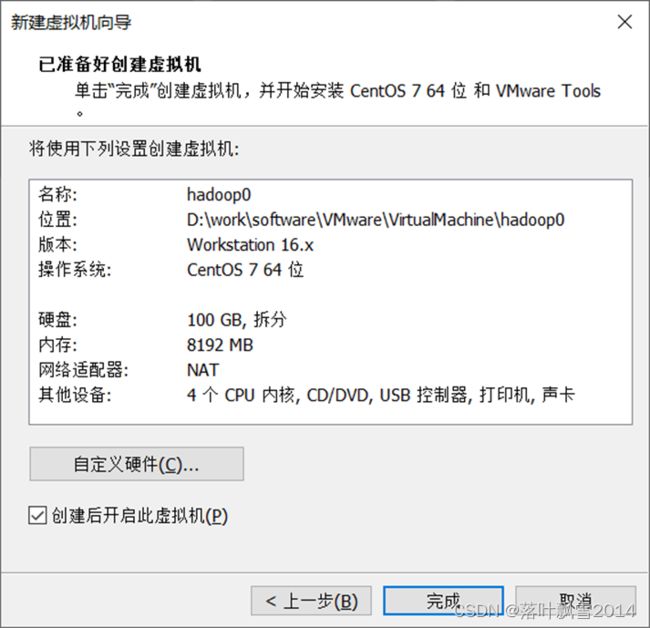
2.15 点击完成,进行安装
然后等待漫长的安装过程即可。
根据机器性能差异,安装时间在10-30分钟之间。
2.16 在安装过程中进行相关内容的设置
设置界面

2.17 设置时区

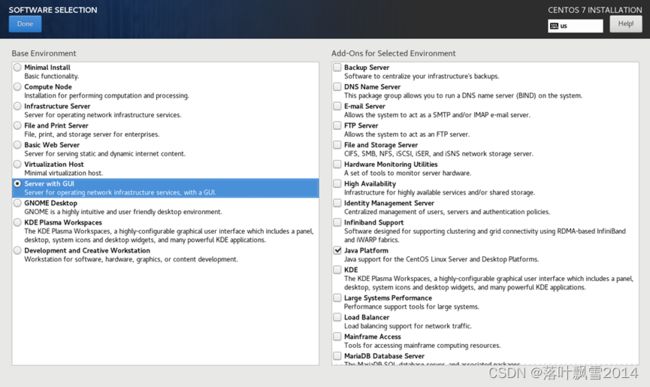
2.18 选择安装的内容
选择GUI,对初学者比较友好。
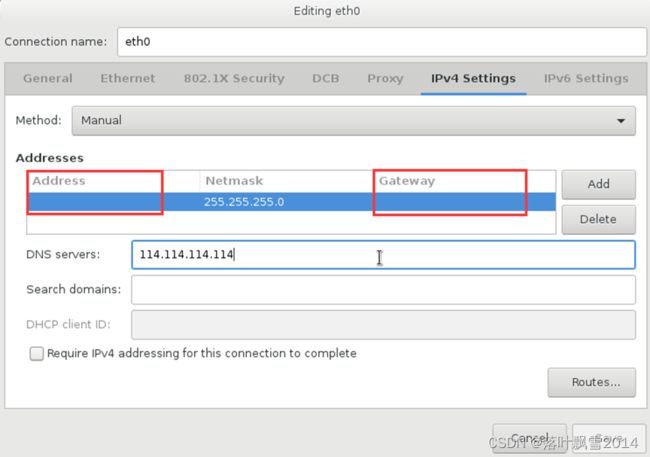
2.19 设置网络
2.20 设置之后的页面
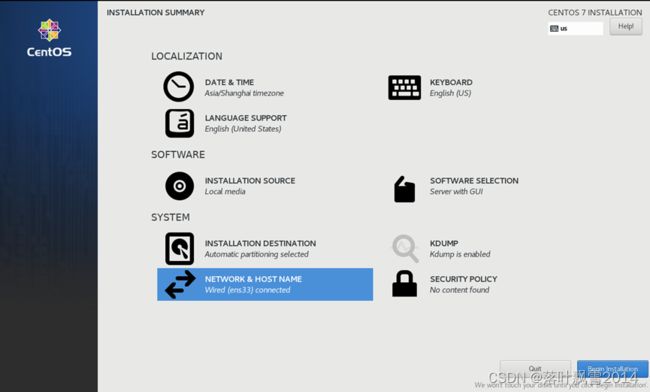
2.21 继续安装页面
第三章 安装XShell和Xftp
首先准备软件

3.1 安装XShell
3.1.1 双击打开

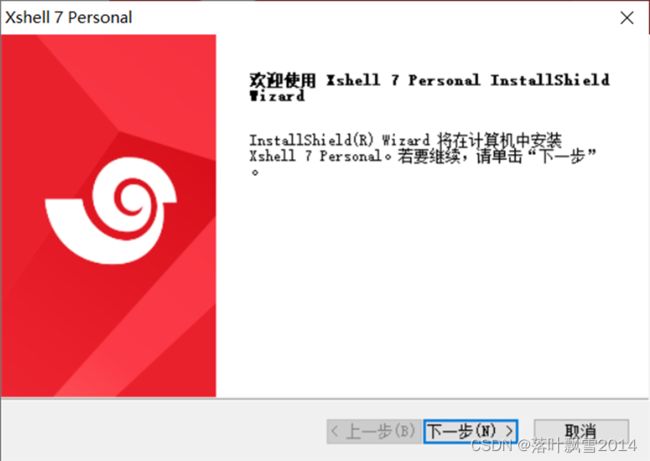
3.1.2 点击接受协议
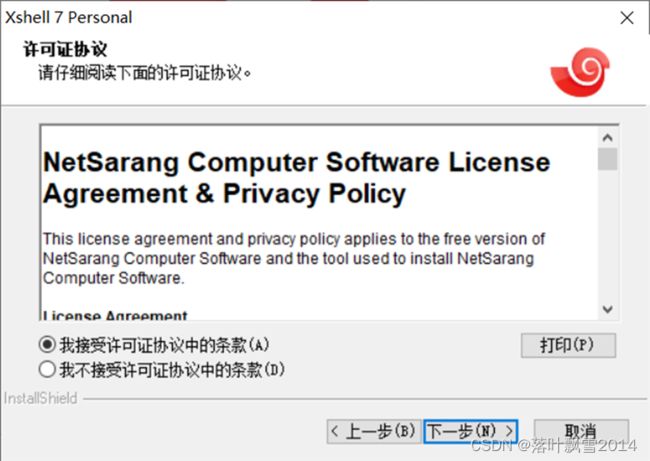
3.1.3 选择安装位置
选择自己的合适的目录即可
3.1.4 点击下一步,之后点击安装
3.1.5 安装过程

3.1.6 安装完成
3.1.7 点击完成,查看成功界面
3.2 安装Xftp
3.2.1 双击打开

3.2.2 点击接受协议
3.2.3 选择安装位置

3.2.4 点击下一步,之后点击安装
3.2.5 安装过程
3.2.6 安装完成
3.2.7 点击完成,查看成功界面

3.3 通过XShell连接虚拟机
3.3.1 在文件中点击新建

3.3.2 输入相应的信息

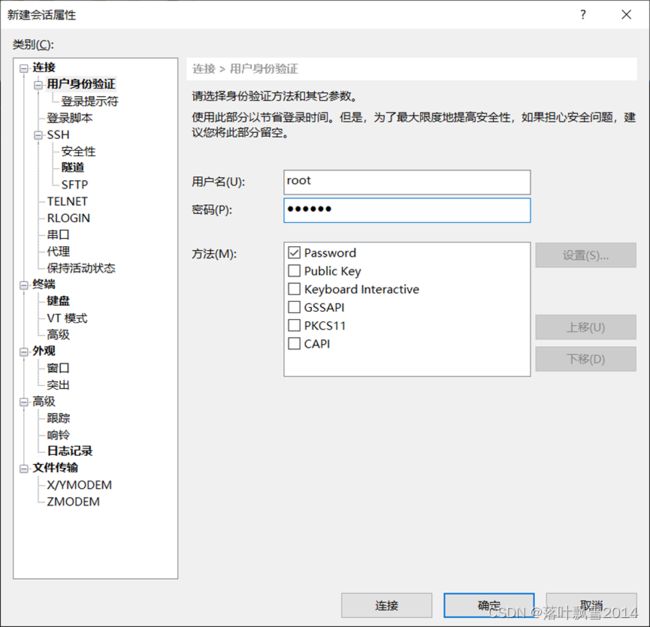
3.3.3 一些小操作
注意连接之前需要给虚拟机防火墙关闭
| CentOS7查看防火墙状态 systemctl status firewalld.service 关闭防火墙 systemctl stop firewalld.service 永久关闭(重启也没有用) systemctl enable firewalld.service |
关闭selinux参考(其实不关闭也不影响):
| 临时关闭 [root@localhost ~]# setenforce 0 查看selinux状态 [root@localhost ~]# sestatus 永久关闭 可以修改配置文件/etc/selinux/config,将其中SELINUX设置为disabled。 [root@localhost ~]# vim /etc/selinux/config |
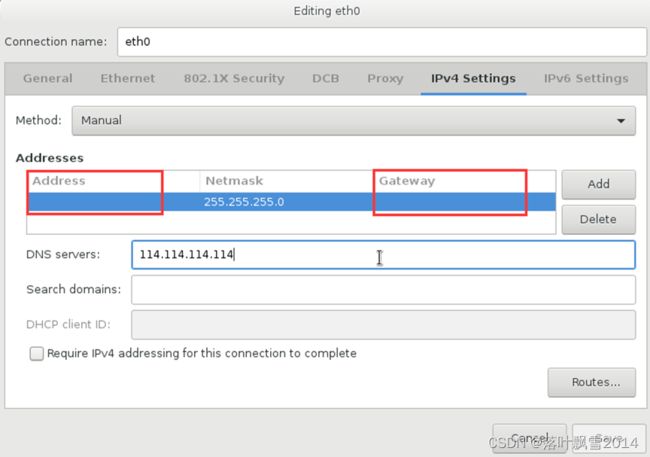
注意,子网掩码的设置!!!
第四章 分布式集群安装前序准备
4.1 配置网络
网络配置修改成Manual手动的,并填写相应的ip地址
4.2 hostname查看并修改
CentOS6.x: vi /etc/sysconfig/network
CentOS7.4: vi /etc/hostname
修改主机名,修改之后要重启才能生效。
![]()
4.3 修改 /etc/hosts
修改hosts文件
vi /etc/hosts
192.168.22.136 hadoop10
192.168.22.137 hadoop11
192.168.22.138 hadoop12
示例如下:

4.4 防火墙策略
在虚拟机测试,关闭即可,阿里云主机上面需要配置策略
systemctl status firewalld.service
systemctl stop firewalld.service
只使用前面两行重启之后防火墙就开启了。
systemctl disable firewalld.service 永久关闭(重启也不行)

4.5 SSH相互免密码登录
先在hadoop0上面执行。
cd ~ 也就是进入/root目录
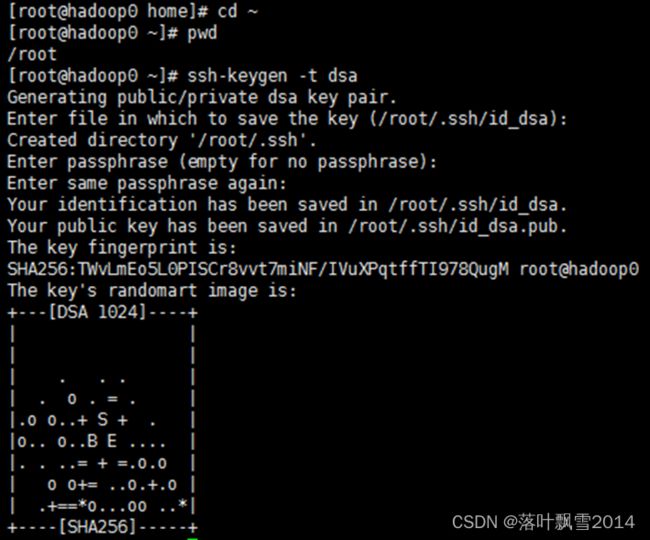
ssh-keygen -t dsa
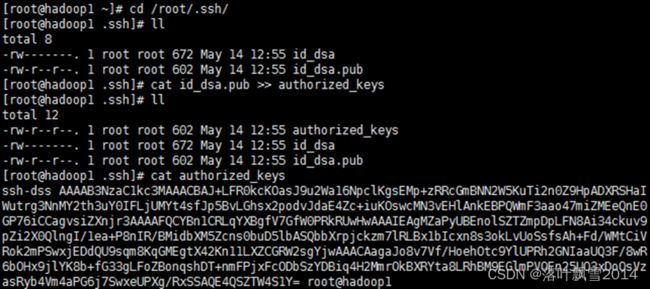
cd /root/.ssh/
cat id_dsa.pub >> authorized_keys
上面四步骤需要在三台虚机上做同样的操作
cat authorized_keys查看秘钥
若是有原来有秘钥先删除
rm -rf *
ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop2
在hadoop0上执行上面一句将hadoop0上面的秘钥拷贝到hadoop2上
然后再hadoop1上面再次执行上面一句将hadoop1上面的秘钥拷贝到hadoop2上
scp /root/.ssh/authorized_keys hadoop0:/root/.ssh/
在hadoop2上面执行上面一句将hadoop2上面的秘钥拷贝到hadoop0 上
scp /root/.ssh/authorized_keys hadoop1:/root/.ssh/
在hadoop2上面执行上面一句将hadoop2上面的秘钥拷贝到hadoop1 上第五章 JDK安装
5.1 准备环境并上传软件
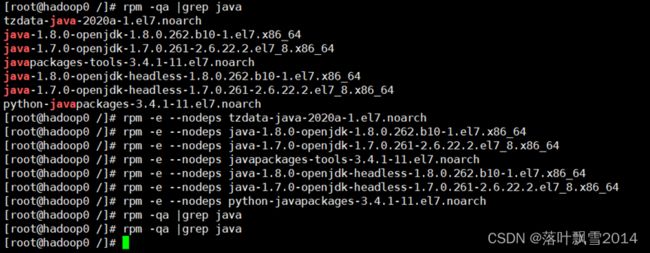
1、安装之前先查看一下有无系统自带jdk
rpm -qa |grep java
rpm -e --nodeps 软件名字
| [root@hadoop0 /]# rpm -qa |grep java tzdata-java-2020a-1.el7.noarch java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64 javapackages-tools-3.4.1-11.el7.noarch java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64 java-1.7.0-openjdk-headless-1.7.0.261-2.6.22.2.el7_8.x86_64 python-javapackages-3.4.1-11.el7.noarch [root@hadoop0 /]# rpm -e --nodeps tzdata-java-2020a-1.el7.noarch [root@hadoop0 /]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 [root@hadoop0 /]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64 [root@hadoop0 /]# rpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarch [root@hadoop0 /]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64 [root@hadoop0 /]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.261-2.6.22.2.el7_8.x86_64 [root@hadoop0 /]# rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch [root@hadoop0 /]# rpm -qa |grep java |
使用下面的语句可以快捷删除完
| rpm -qa |grep java rpm -e --nodeps tzdata-java-2020a-1.el7.noarch rpm -e --nodeps java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 rpm -e --nodeps java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64 rpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarch rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64 rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.261-2.6.22.2.el7_8.x86_64 rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch rpm -qa |grep java |
实际配置的内容:
| [root@hadoop10 ~]# rpm -qa |grep java tzdata-java-2020a-1.el7.noarch python-javapackages-3.4.1-11.el7.noarch java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64 java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 javapackages-tools-3.4.1-11.el7.noarch [root@hadoop10 ~]# rpm -e --nodeps tzdata-java-2020a-1.el7.noarch [root@hadoop10 ~]# rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch [root@hadoop10 ~]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64 [root@hadoop10 ~]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 [root@hadoop10 ~]# rpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarch [root@hadoop10 ~]# rpm -qa |grep java [root@hadoop10 ~]# |
为了方便,整理一下:
| rpm -qa |grep java rpm -e --nodeps tzdata-java-2020a-1.el7.noarch rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64 rpm -e --nodeps java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 rpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarch rpm -qa |grep java |
2、在根目录下面创建software文件夹,然后将文件上传到此文件夹下面,将所有的文件的安装都放到这个文件夹下面,方便统一管理。
5.2 上传解压重命名文件
上传到software文件夹下面

tar -zxvf jdk-8u202-linux-x64.tar.gz
mv jdk1.8.0_202/ jdk
重命名

5.3 修改配置
修改之前最好先备份一下配置文件

vi /etc/profile
export JAVA_HOME=/software/jdk
export PATH=.:$PATH:$JAVA_HOME/bin

source /etc/profile
java
java -version
javac

同理在其他节点上一样安装即可。
第六章 Hadoop安装
先在一台机器上面安装,然后复制到其他的机器上面即可。
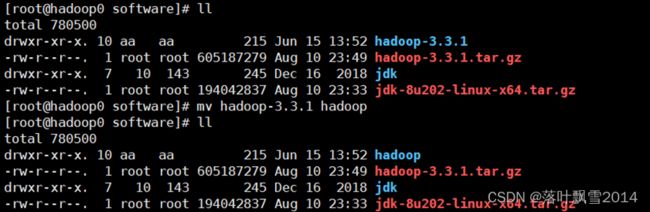
6.1 在节点1上面上传解压重命名
tar -zxvf hadoop-3.3.1.tar.gz
mv hadoop-3.3.1 hadoop
3.2 添加环境变量
vi /etc/profile
export JAVA_HOME=/software/jdk
export HADOOP_HOME=/software/hadoop
export PATH=.:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
线上实际配置
| export JAVA_HOME=/software/jdk export PATH=.:$PATH:$JAVA_HOME/bin export HADOOP_HOME=/software/hadoop export PATH=.:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin |

6.3 修改配置文件
在hadoop0上修改Hadoop的配置文件
cd hadoop/etc/hadoop
6.3.1 在一个节点上配置
(1)配置hadoop-env.sh
vi hadoop-env.sh
export JAVA_HOME=/software/jdk

(2)配置hdfs-site.xml
| |
(3)配置yarn-site.xml
先使用默认的即可
(4)配置core-site.xml
| |
注意:端口可以不指定,默认是8020,也可以指定
(5)配置workers
hadoop1
hadoop2
6.3.2 将hadoop0上的配置拷贝到其他节点上
拷贝hadoop0上的配置到hadoop1和hadoop2上面
(1)拷背hadoop配置
| scp -r /software/hadoop hadoop1:/software/ scp -r /software/hadoop hadoop2:/software/ |
(2)拷贝
scp /etc/profile hadoop11:/etc/
scp /etc/profile hadoop12:/etc/
source /etc/profile
(3)或者手动配置
export HADOOP_HOME=/software/hadoop
export PATH=.:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.4 启动/停止Hadoop集群
3.4.1 格式化文件系统
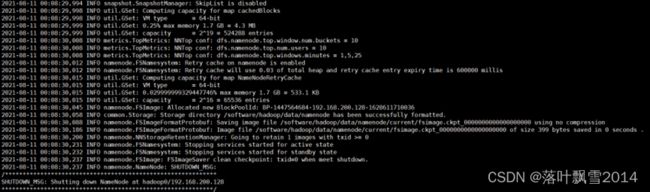
hdfs namenode -format
执行上面的命令后,在后面的提示中如果看到successfully formatted的字样,说明hdfs格式化成功!
3.4.2 第一次启动时候遇到的问题
start-all.sh或者start-dfs.sh 和 start-yarn.sh来启动
出现问题如下:
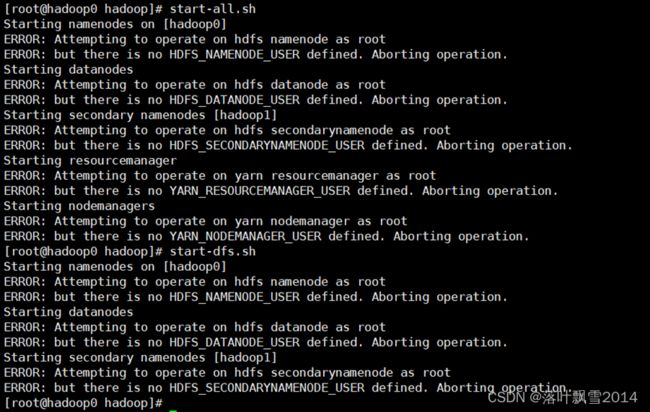
解决方案:
cd /software/hadoop/etc/hadoop
修改hadoop-env.sh。(只需要在主节点上面配置一些即可,因为只在主节点上启动)
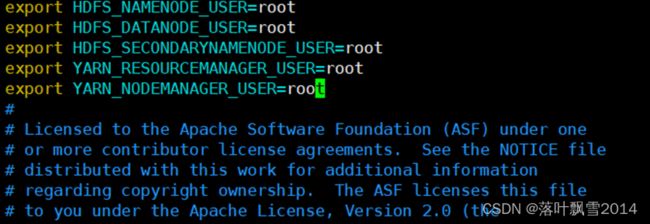
在最上面添加如下内容:
| export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root |
配置结果如下:
3.4.3 正确启动关闭
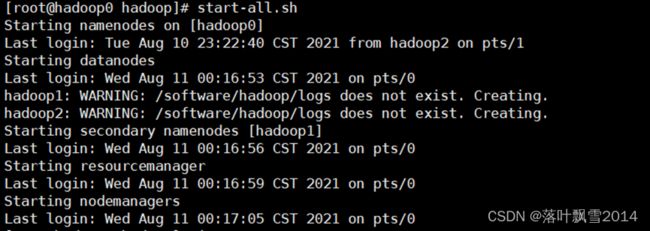
查看进程
| [root@hadoop0 hadoop]# jps 5538 Jps 5196 ResourceManager 4733 NameNode |
| [root@hadoop1 hadoop]# jps 3681 SecondaryNameNode 3860 Jps 3770 NodeManager 3567 DataNode |
| [root@hadoop2 software]# jps 51234 DataNode 51362 NodeManager 51452 Jps |
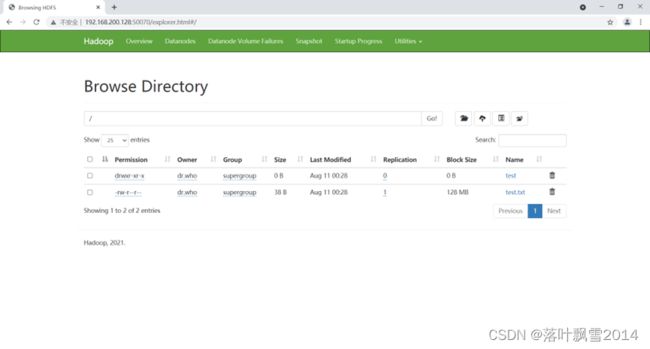
3.4.4 查看页面
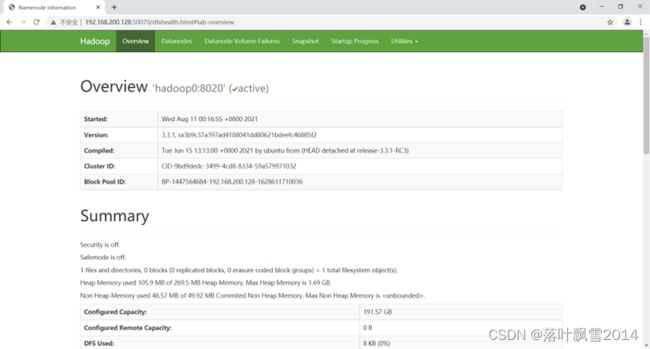
3.4.5 在页面创建文件夹时候出现的问题
问题如下:
| Permission denied: user=dr.who, access=WRITE, inode="/":root:supergroup:drwxr-xr-x |
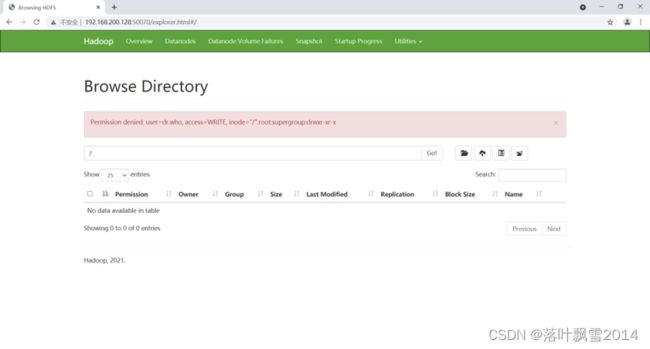
解决方案:
配置权限:
| [root@hadoop0 hadoop]# hadoop fs -chmod -R 777 / |
修改之后创建文件夹以及上传文件都正常了