PgSQL技术内幕-Bitmap Index Scan
PgSQL技术内幕-Bitmap Index Scan
1、简介
Bitmap索引扫描是对索引扫描的一个优化,通过建立位图的方式将原来的随机堆表访问转换成顺序堆表访问。主要分为两点:1)管理每个Bitmap的hash slot没用完时,每个Bitmap代表每个heap页中满足条件元组的ItemIDs,通过Bitmap扫描heap页时需要将所有Bitmap按照页号进行排序,然后依次获取heap页中记录,依次完成顺序回表。2)当hash slot用完时,就需要将heap页的bitmap范围扩大,转换成一个chunk的bitmap,也就是Bitmap中一位代表页内具有满足条件元组的页。此时,整个Bitmaps有chunk的bitmap也有页的bitmap,该chunk的页号为chunk内最小页号,所以Bitmaps排序后,整体上也是有序的。如此完成顺序扫描heap页,只不过对于Chunk的bitmap中一位代表的heap 页需要再次进行条件检测,将满足条件的tuple输出。
2、Bitmap Index Scan中的Bitmap是什么
Bitmap index scan先利用索引获取满足条件的Tid,将其保存到TIDBitmap中。由TIDBitmap管理满足条件的heap tuple的Bitmap。TIDBitmap结构主要成员如下图所示:

各个成员变量的说明:
1)每一页的bitmap由PagetableEntry结构来管理,里面成员主要有blockno:页号,用做hash表的key。最初仅使用entry1,entry1满了,才会使用hash表。这样btgetbitmap扫描完成所有存在的TID,就完成了按照页聚合。
2)pagetable哈希表,初始时(tbm_create调用时指定)仅创建128个hash桶。若一个page对应一个PagetableEntry,当有大量page需要构建bitmap时,就不够用了。所以Hash桶用完则转换chunk进行lossy,从而腾出空闲槽。等hash桶都变成chunk时,就需要扩展了,每次扩展2倍大小(2*128)。
3)nentries表示hash表中已使用桶的个数
4)maxentries为hash表hash桶的最大个数限制。该成员主要作用:控制何时进行lossy,也就是nentries > maxentries时,需要tbm_lossify。大小由work_mem控制,至少16个。当然,如果最终扩展的超过work_mem时,桶仍旧都是chunk,则更新maxentries扩展2倍大小。
5)entriy1表示最开始使用的entry,不用申请到hash表
6)spages和schunks则是从hash桶弄过来排过序的entry。在BitmapHeapScan阶段使用。当然,分别存储Page和lossy的chunk。这样就可以顺序访问了。
另外TIDBitmap中的几个成员有:
1)TBMStatus status:
typedef enum
{
TBM_EMPTY, /* no hashtable, nentries == 0 */
TBM_ONE_PAGE, /* entry1 contains the single entry */
TBM_HASH /* pagetable is valid, entry1 is not */
} TBMStatus;为什么会有TBM_ONE_PAGE和TBM_HASH呢?因为如果TIDBitmap只存储一个PagetableEntry,不需要耗费实际构建动态hash表,查找时也不需要通过hash查找,只需要使用entry1即可。
3、Bitmap Index Scan阶段
MultiExecBitmapIndexScan函数实现了Exec逻辑,主要通过调用index_getbitmap函数,获取bitmap,然后将bitmap返回给上一层算子。我们这里以btree索引为例,所以index_getbitmap指向btgetbitmap索引扫描函数:

btgetbitmap函数的逻辑:当然时先创建TIDBitmap,然后调用_bt_first/_bt_next逐条获取满足条件的item,接着通过tbm_add_tuples将其添加到TIDBitmap中,最终构建一个完整的bitmap,核心函数为_bt_first/_bt_next/tbm_add_tuples:
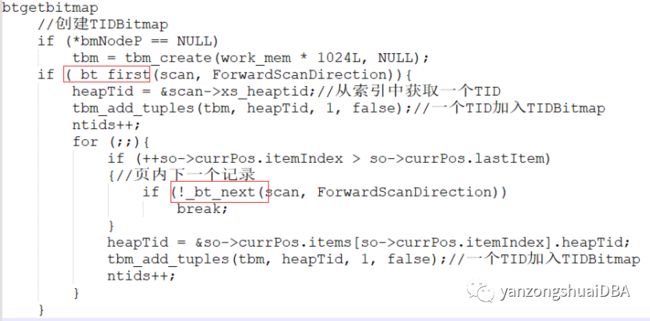
1)_bt_first函数时索引扫描的开始。首先调用_bt_preprocess_keys预处理扫描key,所扫描key条件无法满足,则设置BTScanOpaque->qual_ok为false,提前结束扫描。若没有找到有用的边界keys,需要调用_bt_endpoint从第一页开始,否则调用_bt_search从btree的root节点_bt_getroot开始扫描,直到找到符合扫描key和快照的第一个叶子节点。之后使用二分查找_bt_binsrch找到符合扫描key的页内item偏移,最好将找到的页面载入buffer并返回tuple。
2)_bt_next函数从当前页获取下一条tuple,若当前页没有tuple,则调用_bt_steppage拿到下一页页号,之后调用_bt_readnextpage读取文件块中的内容,然后_bt_next获取吓一跳tuple,重复以上过程,直至扫描结束。
3)tbm_create创建TIDBitmap:

4)tbm_add_tuples函数添加CTID,构建TIDBitmap

tbm_add_tuples要干的事如上图所示:
(1)btgetbitmap调用tbm_add_tuples每次仅添加一个TID,从TID中解析出对应heap tuple的页号blk及页内偏移off
(2)判断blk是否是lossy:页号定位到所属chunk;然后据该chunk页号从hash表中查找;hash表中找到,再看下页号所属的bitmap位是否1,即是否lossy;bitmap为1,则返回true:
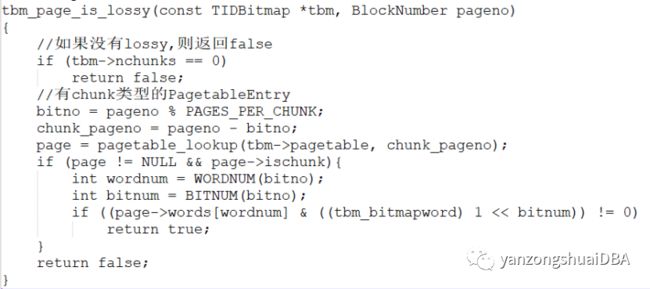
blk非lossy,则调用tbm_get_pageentry从hash表中找一个PagetableEntry(不存在则会创建)。但是若此时只有一个PagetableEntry(TBM_ONE_PAGE状态)则直接返回entry1,不需要从hash查找:
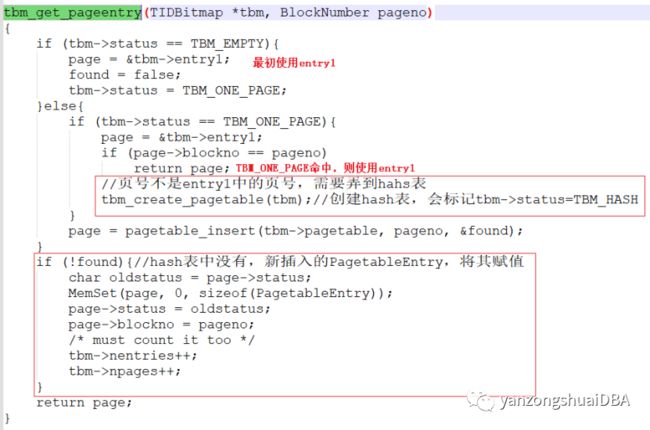
blk是lossy:已经位于chunk中的一位了,不必再向hash表添加了,因为btree下仅一个TID,所以退出循环
(3)计算bitmap的位于哪个字节wordnum及哪一位bitnum,标记到PagetableEntry的bitmap中words,并设置recheck为false
(4)tbm_get_pageentry创建了一个新PagetableEntry,发现npages超过tbm->maxentries只,则会调用tbm_lossify函数,将TIDBitmap中部分PagetableEntry转成成lossy chunk,同时按照exact page的减少和lossy page的增加,相应修改npages和nchunks
tbm_lossify函数:

那么hash表何时扩展呢?只要向hash表插入PagetableEntry,就有可能涉及到扩展,扩展后maxentries并不是立即更新;pagetable_insert调用结束后,若插入则需要更新nentries

当然,还会有Bitmap And和Bitmap Or的情况。BitmapAnd节点对两个Bitmap进行与操作,生成交集位图;BitmapOr节点对两个Bitmap进行或操作,生成并集位图。
至此,bitmap index scan阶段完成bitmap的构建,下一步就是根据TID bitmap来扫描heap,返回符合条件的tuple,即Bitmap Heap Scan。
4、Bitmap Heap Scan阶段
Bitmap Heap Scan使用Bitmap Index Scan阶段生成的bitmap来查找相关数据。位图的每个页可以是精确的(直接指向heap页的tuple),也可以是有损的(指向包含至少一行与查询匹配的页)。算子由ExecBitmapHeapScan函数执行,主要实现函数为BitmapHeapNext:

BitmapHeapNext的核心逻辑如下:
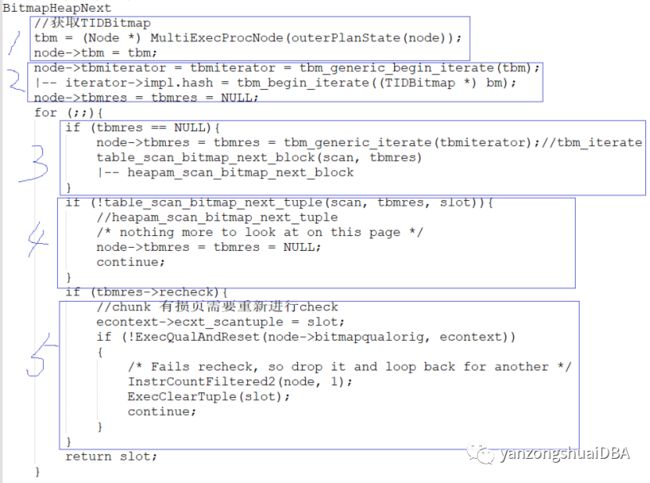
1)从下层节点拿到TIDBitmap结果tbm
2)tbm_generic_begin_iterate->tbm_begin_iterate基于tbm构建一个iterator:从hash表中取出PagetableEntry,根据它是exact page还是lossy page,分别放到spages[]和schunks[]数组;然后根据页号进行排序

3)先调用tbm_iterate从spages[]和schunks[]数组拿一个较小页号的页,然后通过table_scan_bitmap_next_block->heapam_scan_bitmap_next_block读取一个page到ScanDesc的rs_buffer里。

4)调用table_scan_bitmap_next_tuple->heapam_scan_bitmap_next_tuple根据TBMIterateResult里的偏移,再内存buffer里获取相应的tuple。当这一页扫描完,则重置node->tbmres = tbmres = NULL,重新获取下一个PagetableEntry的bitmap继续循环。
5)如果是lossy,则还需要继续过滤
5、总结
Bitmap索引扫描分为两个阶段,第一阶段通过索引进行扫描,将满足条件的元组TID构建到bitmap中,一般情况一个页一个bitmap;第二阶段将bitmap按照页号进行排序,按次序从页的bitmap中取出heap tuple的TID,从而达到索引顺序扫描heap的目的。