本文试图将大约15年的工作量浓缩为今天最重要的八个里程碑,因此省略了许多相关和重要的发展。特别是,主要介绍神经网络方法,其他方法暂时忽略。更重要的是,本文中提出的许多神经网络模型建立在同一时代的非神经网络上。
2001年 - 神经语言模型
语言建模是在给定前面的单词的情况下预测文本中的下一个单词的任务。它可能是最简单的语言处理任务,具有实际应用,如智能键盘,电子邮件响应建议(Kannan et al。,2016),拼写自动修正等。不出所料,语言建模有着丰富的历史。经典方法基于n-gram并采用平滑处理看不见的n-gram(Kneser&Ney,1995)。
Bengio等人于2001年提出了第一个神经语言模型,一个前馈神经网络。如下图1所示。
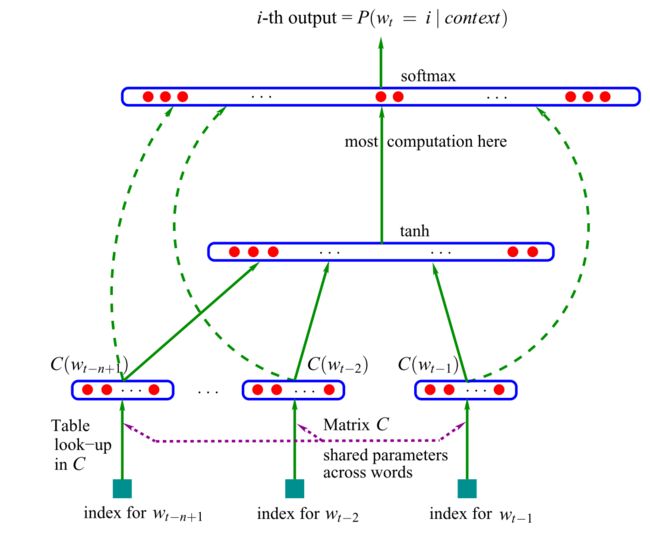
该模型用作输入向量表示以前的单词,在表中查找。如今,这种载体被称为单词嵌入。这些单词嵌入被连接并馈入隐藏层,然后将其输出提供给softmax层。
最近,前馈神经网络已被循环神经网络所取代(RNNs; Mikolov等,2010) 和长期短期记忆网络(LSTMs; Graves,2013)用于语言建模。近年来已经提出了许多扩展经典LSTM的新语言模型(请参阅此页面以获得概述)。尽管有这些发展,但经典的LSTM仍然是一个强大的基础 (Melis et al 2018)。甚至Bengio等人的经典前馈神经网络在某些情况下也能与更复杂的模型竞争,因为这些通常只学会考虑最近的单词(Daniluk et al 2017)。更好地理解这些语言模型捕获的信息是一个活跃的研究领域(Kuncoro 2018; Blevins 2018)。
语言建模通常是应用RNN时的首选训练场,并成功捕捉到了想象力,许多人通过Andrej的博客文章获得了他们的第一次曝光。语言模型是无监督学习的一种形式。关于语言建模最显着的方面可能是,尽管它很简单,但它是本文讨论的许多后期进展的核心:
Word嵌入:word2vec的目标是简化语言建模。
序列到序列模型:这种模型通过一次预测一个单词来生成输出序列。
预训练语言模型:这些方法使用语言模型中的表示来进行转移学习。
为了做“真正的”自然语言理解,仅仅从原始形式的文本中学习可能是不够的,我们将需要新的方法和模型。
2008年 - 多任务学习
多任务学习是在多个任务上训练的模型之间共享参数的一般方法。在神经网络中,这可以通过绑定不同层的权重来轻松完成。Rich Caruana于1993年首次提出了多任务学习的想法 并应用于道路跟踪和肺炎预测(Caruana,1998)。直观地说,多任务学习鼓励模型学习对许多任务有用的表示。这对于学习一般的低级表示,集中模型的注意力或在有限量的训练数据的设置中特别有用。
Collobert和Weston于2008年首次将多任务学习应用于NLP的神经网络。在他们的模型中,查找表(或单词嵌入矩阵)在两个在不同任务上训练的模型之间共享,如下面的图2所示。
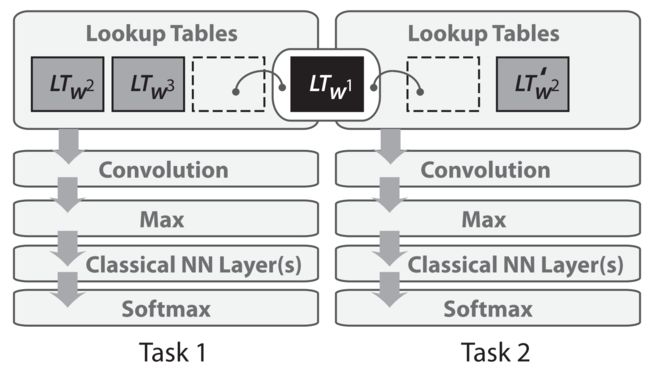
共享单词嵌入使模型能够在单词嵌入矩阵中协作和共享一般的低级信息,这通常构成模型中最大数量的参数。Collobert和Weston在2008年的论文中证明了它在多任务学习中的应用。它引领了诸如预训练单词嵌入和使用卷积神经网络(CNN)之类的思想,这些思想仅在过去几年中被广泛采用。它赢得了在ICML 2018测试的时间奖励(见测试的时间奖励谈话情境纸这里)。
多任务学习现在用于各种NLP任务,并且利用现有或“人工”任务已成为NLP指令集中的有用工具。虽然通常预定义参数共享,但在优化过程中也可以学习不同的共享模式(Ruder et al。,2017)
。随着模型越来越多地评估多项任务以评估其泛化能力,多任务学习越来越重要,最近提出了多任务学习的专用基准(Wang et al。,2018; McCann et al 2018)。
2013年 - Word嵌入
文本的稀疏矢量表示,即所谓的词袋模型在NLP中具有悠久的历史。正如我们在上面所看到的,早在2001年就已经使用了单词或单词嵌入的密集向量表示。Mikolov等人在2013年提出的主要创新。是通过删除隐藏层和近似目标来使这些单词嵌入的训练更有效。虽然这些变化本质上是简单的,但它们与有效的word2vec实现 - 字嵌入的大规模培训一起实现了。
Word2vec有两种风格,可以在下面的图3中看到:连续词袋(CBOW)和skip-gram。它们的目标不同:一个基于周围的单词预测中心词,而另一个则相反。
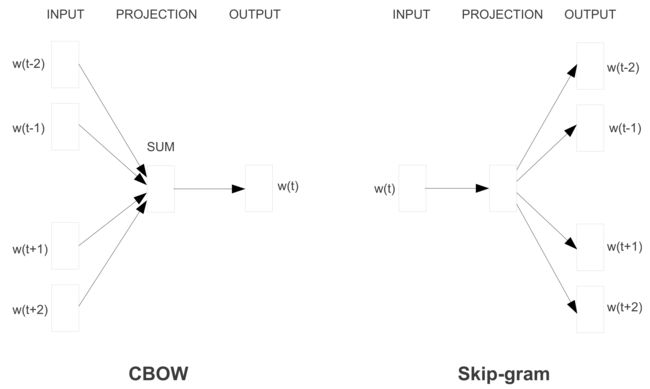
连续的词袋和跳跃式结构
然这些嵌入在概念上与使用前馈神经网络学习的嵌入技术没有什么不同,但是对非常大的语料库的训练使它们能够捕获诸如性别,动词时态和国家 - 资本关系之类的单词之间的某些关系,这可以看出在下面的图4中。
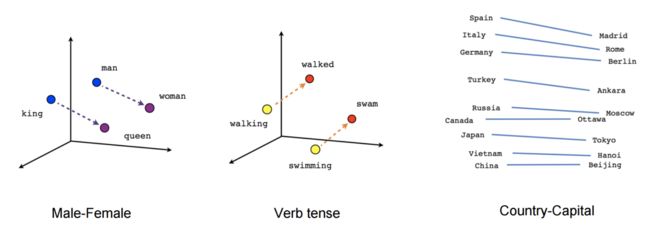
图4
这些关系及其背后的意义引发了对嵌入词的初步兴趣,许多研究调查了这些线性关系的起源(Arora等,2016; Mimno&Thompson,2017; Antoniak&Mimno,2018; Wendlandt等,2018) )。然而,使用预训练嵌入作为初始化的固定词嵌入作为当前NLP的主要内容被证明可以提高各种下游任务的性能。
虽然捕获的关系word2vec具有直观且几乎神奇的质量,但后来的研究表明word2vec没有任何固有的特殊性:通过矩阵分解也可以学习单词嵌入(Pennington等,2014; Levy&Goldberg,2014) 通过适当的调整,经典的矩阵分解方法(如SVD和LSA)可以获得类似的结果(Levy等,2015)。
从那时起,许多工作已经开始探索单词嵌入的不同方面(正如原始论文的引用次数所示)。看看这篇文章,了解一些趋势和未来方向。尽管有许多发展,但word2ve仍然是一种流行的选择并且在今天被广泛使用。Word2vec的范围甚至超出了单词级别:带有负抽样的skip-gram,一个基于本地环境学习嵌入的方便目标,已被应用于学习句子的表示(Mikolov&Le,2014; Kiros et al 2015)---甚至超越NLP ---到网络(Grover&Leskovec,2016) 和生物序列(Asgari&Mofrad,2015)等等。
一个特别令人兴奋的方向是将不同语言的单词嵌入投影到同一空间中以实现跨语言转移。越来越有可能以完全无监督的方式学习良好的投射(至少对于类似的语言)(Conneau等,2018; Artetxe等,2018;Søgaard等,2018),打开低资源语言和无监督机器翻译的应用程序(Lample等,2018; Artetxe等,2018)。看看(Ruder et al。,2018) 概述。
2013年 - NLP的神经网络
2013年和2014年是神经网络模型开始在NLP中被采用的时间。三种主要类型的神经网络成为使用最广泛的:循环神经网络,卷积神经网络和递归神经网络。
循环神经网络 循环神经网络(RNN)是处理NLP中普遍存在的动态输入序列的明显选择。Vanilla RNNs(Elman,1990)被经典的长期短期记忆网络迅速取代(Hochreiter&Schmidhuber,1997),证明了对消失和爆炸梯度问题更具弹性。在2013年之前,仍然认为RNN很难训练;Ilya Sutskever的博士论文是改变这种说法的一个关键例子。LSTM结构图可以在下面的图5中看到。双向LSTM(Graves et al。,2013) 通常用于处理左右上下文。
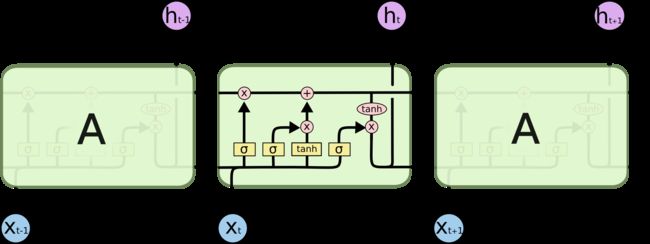
图5
卷积神经网络 随着卷积神经网络(CNN)被广泛应用于计算机视觉,它们也开始应用于语言(Kalchbrenner等,2014; Kim等,2014)。用于文本的卷积神经网络仅在两个维度上操作,其中滤波器仅需要沿时间维度移动。下面的图6显示了NLP中使用的典型CNN。
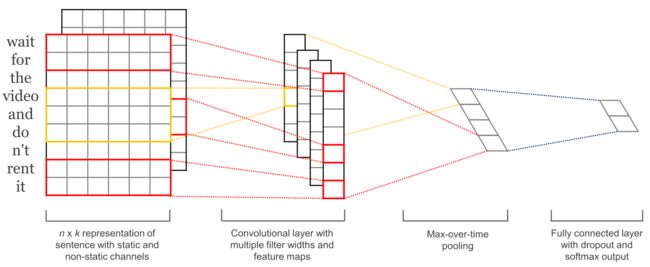
图6
卷积神经网络的一个优点是它们比RNN更可并行化,因为每个时间步的状态仅取决于本地环境(通过卷积运算)而不是像RNN中的所有过去状态。CNN可以使用扩张的卷积扩展到更广泛的感受野,以捕捉更广泛的背景(Kalchbrenner等,2016)。CNN和LSTM也可以组合和堆叠(Wang et al。,2016) 和卷积可以用来加速LSTM(Bradbury et al。,2017)
递归神经网络 RNN和CNN都将语言视为序列。然而,从语言学的角度来看,语言本质上是等级的:单词被组成高阶短语和子句,它们本身可以根据一组生产规则递归地组合。将句子视为树而不是序列的语言启发思想产生了递归神经网络(Socher et al。,2013),可以在下面的图7中看到。
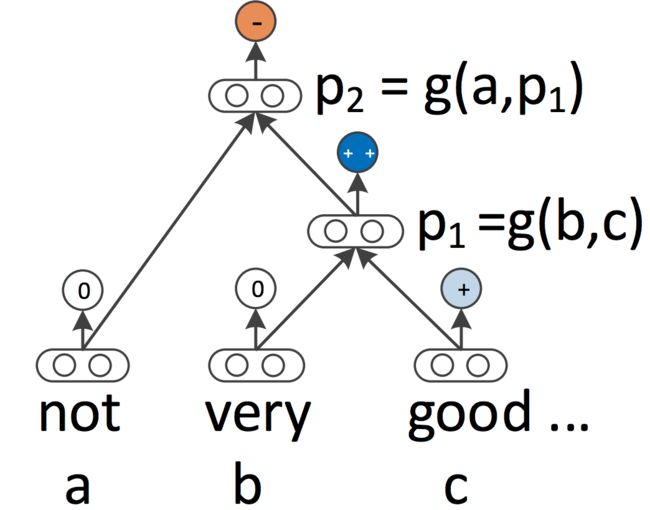
图7
机器翻译成了这个框架的杀手级应用。2016年,谷歌宣布开始用神经机器翻译模型替换其基于单片短语的MT模型(Wu et al。,2016)。根据Jeff Dean的说法,这意味着用500行神经网络模型替换500,000行基于短语的机器翻译代码。
与从左到右或从右到左处理句子的RNN相比,递归神经网络从下到上构建序列的表示。在树的每个节点处,通过组合子节点的表示来计算新表示。由于树也可以被视为在RNN上施加不同的处理顺序,LSTM自然地扩展到树木(Tai et al。,2015)
不仅可以扩展RNN和LSTM以使用分层结构。不仅可以基于本地语言而且可以基于语法背景来学习单词嵌入(Levy&Goldberg,2014); 语言模型可以基于句法堆栈生成单词(Dyer et al。,2016); 图形卷积神经网络可以在树上运行(Bastings等,2017)
2014年 - 序列到序列模型
2014年,Sutskever等人。提出的序列到序列学习,一种使用神经网络将一个序列映射到另一个序列的通用框架。在该框架中,编码器神经网络按符号处理句子并将其压缩成矢量表示; 然后,解码器神经网络基于编码器状态逐个符号地预测输出符号,在每个步骤中将先前预测的符号作为输入,如下面的图8所示。
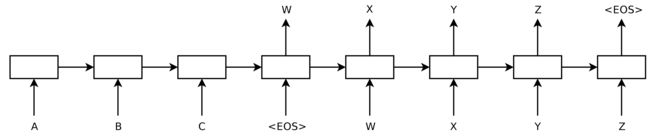
图8
机器翻译成了这个框架的杀手级应用。2016年,谷歌宣布开始用神经MT模型替换其基于单片短语的MT模型(Wu et al。,2016)
。根据Jeff Dean的说法,这意味着用500线神经网络模型替换500,000行基于短语的MT代码。
由于其灵活性,该框架现在是自然语言生成任务的首选框架,不同的模型承担编码器和解码器的角色。重要的是,解码器模型不仅可以以序列为条件,而且可以以任意表示为条件。这使得例如基于图像生成标题(Vinyals等,2015)
(如下图9所示),基于表格的文本(Lebret等,2016),以及基于源代码更改的描述(Loyola等,2017),以及许多其他应用程序。
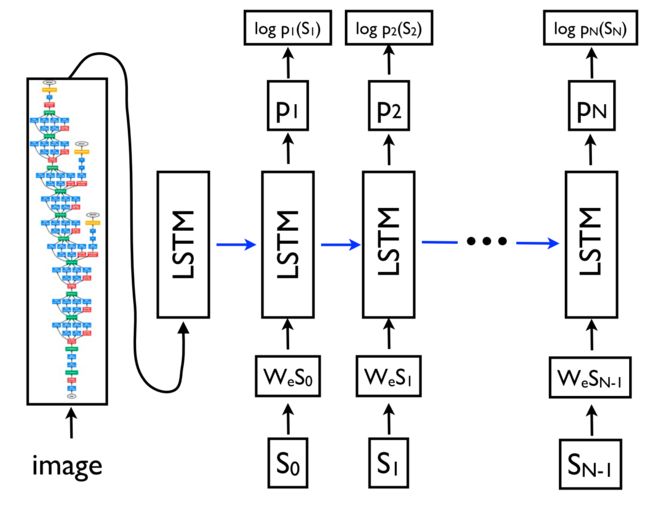
图9 基于图像生成标题
序列到序列学习甚至可以应用于NLP中常见的结构化预测任务,其中输出具有特定结构。为简单起见,输出是线性化的,如下面图10中的选区解析所示。在给予选区解析的足够数量的训练数据的情况下,神经网络已经证明能够直接学习产生这种线性化输出(Vinyals等,2015)和命名实体识别(Gillick等,2016)等等。
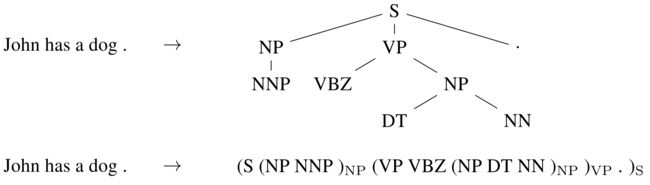
图10 线性化选区分析树
用于序列和解码器的编码器通常基于RNN,但是可以使用其他模型类型。新架构主要来自MT的工作,MT作为序列到序列架构的培养皿。最近的模型是深LSTM(Wu et al。,2016),卷积编码器(Kalchbrenner等,2016; Gehring等,2017),变压器(Vaswani等,2017),将在下一节讨论,以及LSTM和变压器的组合(Chen et al。,2018)
2015年 - 注意力
注意力(Bahdanau等,2015)是神经MT(NMT)的核心创新之一,也是使NMT模型优于基于经典短语的MT系统的关键思想。序列到序列学习的主要瓶颈是它需要将源序列的整个内容压缩成固定大小的矢量。注意力通过允许解码器回顾源序列隐藏状态来减轻这种情况,然后将其作为加权平均值提供给解码器的附加输入,如下面的图11所示。
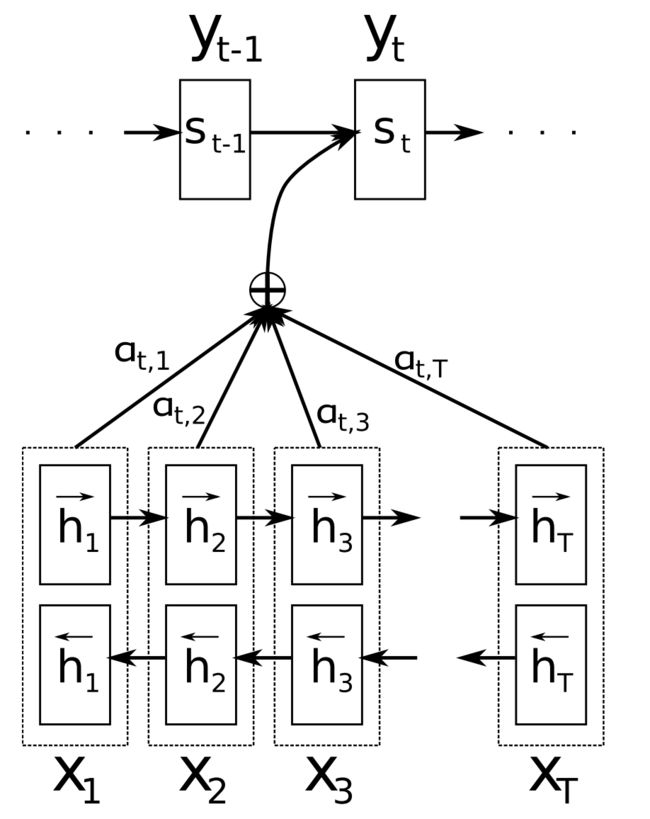
图11 注意力
有不同形式的关注(Luong等,2015)。注意力广泛适用,并且可能对任何需要根据输入的某些部分做出决策的任务有用。它已被应用于选区解析(Vinyals等,2015)阅读理解(Hermann et al。,2015)和一次性学习(Vinyals等,2016)等等。输入甚至不需要是序列,但可以包含其他表示,如图像字幕的情况(Xu et al。,2015),这可以在下面的图12中看到。注意力的一个有用的副作用是,它通过检查输入的哪些部分基于注意力权重与特定输出相关,提供了一种罕见的 - 如果只是肤浅的 - 一瞥模型的内部工作。

图12 图像字幕模型中的视觉注意,指示模型在生成单词“飞盘”时所遵循的内容
注意力也不仅限于查看输入序列; 自我注意可用于查看句子或文档中的周围单词以获得更多上下文敏感的单词表示。多层自我关注是Transformer架构的核心(Vaswani等,2017),目前最先进的NMT模型。
2015年 - 基于内存的网络
注意力可以看作是模糊记忆的一种形式,其中记忆由模型的过去隐藏状态组成,模型选择从记忆中检索的内容。有关注意事项及其与内存的关联的更详细概述,请查看此文章。已经提出了许多具有更明确记忆的模型。它们有不同的变体,例如神经图灵机(Graves et al。,2014),Memory Networks(Weston et al。,2015) 和端到端内存网络(Sukhbaatar等,2015),动态记忆网络(Kumar et al。,2015),神经可微分计算机(Graves et al。,2016)和经常性实体网络(Henaff等,2017)。
通常基于与当前状态的相似性来访问存储器,类似于注意,并且通常可以写入和读取存储器。模型在实现和利用内存方面有所不同。例如,端到端内存网络多次处理输入并更新内存以启用多个推理步骤。神经图灵机还具有基于位置的寻址,允许他们学习简单的计算机程序,如排序。基于内存的模型通常应用于任务,其中保留较长时间跨度的信息应该是有用的,例如语言建模和阅读理解。存储器的概念非常通用:知识库或表可以用作存储器,而存储器也可以基于整个输入或其特定部分来填充。
2018年 - 预训练语言模型
预训练的单词嵌入与上下文无关,仅用于初始化模型中的第一层。最近几个月,一系列监督任务被用于预训练神经网络(Conneau等,2017; McCann等,2017; Subramanian等,2018)。相比之下,语言模型只需要未标记的文本; 因此,培训可以扩展到数十亿个令牌,新域和新语言。2015年首次提出预训练语言模型(Dai&Le,2015); 直到最近,它们才被证明对各种各样的任务都有益。语言模型嵌入可以用作目标模型中的特征(Peters等,2018) 或者可以根据目标任务数据微调语言模型(Ramachandran等,2017; Howard&Ruder,2018)。添加语言模型嵌入比许多不同任务的最新技术有了很大的改进,如下面的图13所示。
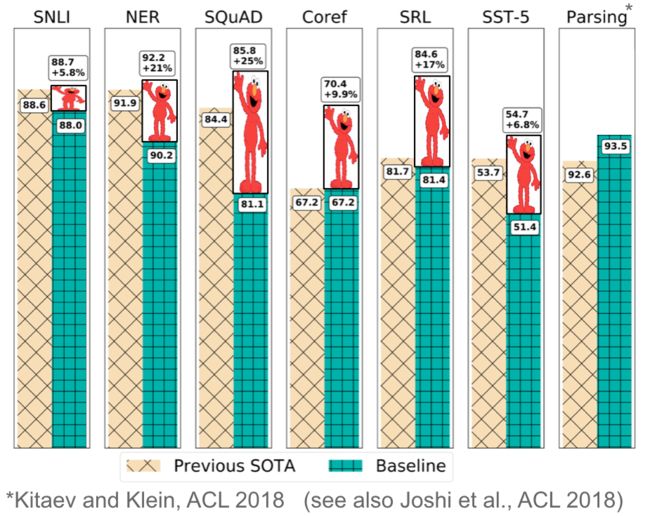
图13:语言模型嵌入优于现有技术的改进
已经展示了预训练语言模型,可以用更少的数据进行学习。由于语言模型仅需要未标记的数据,因此对于标记数据稀缺的低资源语言尤其有用。有关预训练语言模型潜力的更多信息,请参阅本文。
其他里程碑
其他一些发展不如上面提到的那么普遍,但仍然具有广泛的影响。
基于字符的表示,在字符上使用CNN或LSTM来获得基于字符的单词表示是相当普遍的,特别是对于形态学丰富的语言和形态信息很重要或具有许多未知单词的任务。据我所知,基于特征的表示首先用于序列标记(Lample等,2016; Plank等,2016)。基于字符的表示减少了必须以增加的计算成本处理固定词汇表的需要,并且能够实现诸如完全基于字符的NMT之类的应用(Ling等人,2016; Lee等人,2017)。。
对抗性学习 对抗性方法已经在风暴中占据了ML的领域,并且在NLP中也以不同的形式使用。对抗性示例越来越广泛地被广泛使用,不仅作为探测模型和理解其失败案例的工具,而且还使它们更加健壮(Jia&Liang,2017)。(虚拟)对抗性训练,即最坏情况的扰动(Miyato等,2017; Yasunaga等,2018) 和域对抗性损失(Ganin等,2016; Kim等,2017)是有用的正则化形式,可以同样使模型更加健壮。生成对抗网络(GAN)对于自然语言生成来说还不是太有效(Semeniuta et al。,2018),但在匹配分布时很有用(Conneau et al。,2018)
强化学习 强化学习已被证明对于具有时间依赖性的任务非常有用,例如在训练期间选择数据(Fang et al。,2017; Wu et al。,2018) 和建模对话(Liu et al。,2018)。RL对于直接优化诸如ROUGE或BLEU的不可微分的末端度量而不是优化代理损失(例如总结中的交叉熵)也是有效的(Paulus等,2018; Celikyilmaz等,2018)。 和机器翻译(Ranzato等,2016)。类似地,反向强化学习在奖励太复杂而无法指定的环境中非常有用,例如视觉叙事(Wang et al。,2018)。
非神经里程碑
1998年以及随后几年,引入了FrameNet项目(Baker等,1998)这导致了语义角色标记的任务,这是一种浅层语义分析,至今仍在积极研究中。在21世纪初期,与自然语言学习会议(CoNLL)共同组织的共同任务催化了核心NLP任务的研究,如分块(Tjong Kim Sang et al。,2000),命名实体识别(Tjong Kim Sang et al。,2003)和依赖解析(Buchholz et al。,2006)等等。许多CoNLL共享任务数据集仍然是当今评估的标准。
2001年,条件随机场(CRF; Lafferty等,2001),引入了最具影响力的序列标记方法之一,获得了ICML 2011的时间测试奖。CRF层是当前最先进的模型的核心部分,用于序列标记问题,标签相互依赖性,如命名实体识别(Lample et al。,2016)。
2002年,双语评估替补(BLEU; Papineni等,2002)提出了度量标准,这使得MT系统能够扩展,并且仍然是目前MT评估的标准度量标准。在同一年,结构化的先行者(柯林斯,2002年)介绍,为结构化感知工作奠定了基础。在同一次会议上,引入了最受欢迎和广泛研究的NLP任务之一的情绪分析(Pang et al。,2002)。这三篇论文都获得了2018年NAACL的时间测试奖。
2003年引入了潜在的dirichlet分配(LDA; Blei等,2003),机器学习中使用最广泛的技术之一,它仍然是进行主题建模的标准方法。在2004年,提出了新的最大边际模型,它们更适合捕获结构化数据中的相关性而不是SVM(Taskar等,2004a; 2004b)。
2006年,OntoNotes(Hovy等,2006),介绍了一个具有多个注释和高交互注入协议的大型多语言语料库。OntoNotes已被用于培训和评估各种任务,例如依赖性解析和共参考解析。米尔恩和维滕(2008)2008年描述了维基百科如何用于丰富机器学习方法。到目前为止,维基百科是用于训练ML方法的最有用的资源之一,无论是用于实体链接和消歧,语言建模,作为知识库还是各种其他任务。
2009年,远程监督的想法(Mintz et al。,2009)提出了。远程监督利用来自启发式或现有知识库的信息来生成可用于从大型语料库中自动提取示例的噪声模式。远程监督已被广泛使用,并且是关系提取,信息提取和情感分析以及其他任务中的常用技术。
作者:readilen
链接:https://www.jianshu.com/p/03a76d45fb08
來源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。