Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review(自动驾驶图像点云融合深度学习综述)论文笔记
原文链接:https://arxiv.org/pdf/2004.05224.pdf
II.深度学习的简要回顾
B.点云深度学习
本文将点云深度学习方法分为5类,即基于体素、基于2D视图、基于点、基于图以及基于索引/树的方法。
(2)基于索引/树的方法引入树状数据结构(如kd树、八叉树),自适应地划分分辨率,减小计算量。通过建立不平衡的树,可以根据点云密度划分区域。这样,点密度低的区域可以有低分辨率。根据树的结构提取点的特征。
(3)基于2D多视图的方法使用视图池化层聚合多视图特征,实现平移不变性。
(4)图卷积可在空间域或者谱域进行,前者使用MLP对空间相邻点操作,后者通过拉普拉斯谱对图进行谱滤波。
(5)基于点的方法中,与PointNet++中使用PointNet聚合局部特征不同,RandLA-Net使用按层堆叠的随机点采样模块和基于注意力的局部特征聚合模块,逐步提高感受野的同时保持高效率。
使用点卷积可以明确建模点的空间关系。点卷积通过将离散权重转化为连续的权值函数,将2D离散卷积泛化到3D连续域。这个权值函数在PointConv中使用MLP来近似。PCNN将卷积核定义为一些带权点,核点和输入点坐标的高斯相关函数用于计算任意坐标的权值矩阵。
KPConv使用线性相关函数,且分层应用卷积核。
![]()
其中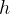 是逐点的核函数;
是逐点的核函数; 是输入点,
是输入点, 与
与 为附近第
为附近第 个点的坐标和特征。邻域
个点的坐标和特征。邻域![]() 通常由KNN或半径定义。
通常由KNN或半径定义。
III.深度补全
目标是将稀疏不规则的深度图上采样为密集规则的深度图,如将来自遥远物体的少量点上采样,使点云更匹配该物体。可以减轻激光雷达点云的不均匀分布。高分辨率图像常用于指导深度上采样。
A.单目相机与激光雷达融合
(1)信号层面上的融合:即直接处理RGB-D图像(将图像与激光雷达的稀疏深度图拼接的图像)。
(2)特征层面上的融合:即分别处理图像和深度图后融合。可以使用单阶段融合或多阶段融合。
(3)多层面融合:前两种融合方法的结合。
B.立体相机与激光雷达融合
立体相机含有密集的深度信息,而激光雷达含有稀疏但更精确的深度信息。均为特征层面上的融合。
IV.动态目标检测
分为顺序检测(即两阶段检测)和一步检测(一阶段检测,2D和3D数据并行处理,通常更高效)。
A.基于2D提案的顺序模型
提案阶段使用图像检测器生成2D提案,投影到3D空间作为检测种子。
投影方法:2D边界框投影到3D(棱台状空间)、3D点云投影到图像。
(1)结果层面上的融合:使用2D检测器,以减少3D搜索空间从而减少计算。
- 例如F-PointNet先在图像上生成2D提案,投影到3D空间,然后使用基于PointNet的检测器处理每个棱台。
- 其他一些方法在生成3D提案的时候过滤掉背景点以节省计算。

上述方法都基于一个提案只有一个物体的假设。解决方法可以是通过将2D目标检测替换为2D语义分割,将区域提案替换为点的提案。
- 例如IPOD使用2D语义分割过滤掉背景点(通过将点云投影到图像上),然后使用两个基于PointNet++的网络提取提案特征和预测边界框。PointsIoU准则用于加速训练和推断。
(2)特征层面上的融合:
早期工作的融合是像素级的,即将3D几何信息转化为图像特征,或者作为图像的额外通道。这样可以使用图像处理方法提取特征,但结果也只是图像平面上的。
- 例如DepthRCNN将水平视差、离地高度和与重力的角度(HHA)作为新的通道。
直接将RGB值附加到点云上会丢失纹理信息,因为图像的密集和点云的稀疏导致只有少部分像素有对应点。
- 如PointPainting先提取图像语义特征,然后通过投影将语义信息附加到点上;缺点是会造成图像网络和点云网络的耦合,即图像模型改变时,点云模型需要重新训练。
(3)多层面融合:使用2D检测器,提案投影到3D搜索空间,然后在提案内再次融合特征。
- PointFusion先使用2D检测器生成2D边界框,然后将点云投影到图像上,选择在边界框内的点。最后基于ResNet和PointNet的网络逐提案地融合图像和点云特征。
- SIFRNet先从图像生成棱台提案,然后提案内的点云特征和对应的图像特征结合估计3D边界框。引入PointSIFT实现尺度不变性;SENet模块用于抑制信息量少的特征。
B.基于3D提案的顺序模型
3D提案生成是通过2D或3D数据直接生成3D提案,方法主要包括基于多视图的方法和基于体素的方法。前者基于点云的BEV表达,因其无遮挡,且保留了物体的方向和具体位置信息。
均为特征层面的融合。
- MV3D:在BEV上生成3D提案,然后将提案投影到前视域和图像平面提取和融合提案特征。融合是通过RoI池化操作实现的。缺点是不适合小物体检测、冗余检测会耗费不必要的计算。
- AVOD:结合BEV与图像的特征图来提出提案。编码器会上采样最终特征图到原始大小,以解决小物体在下采样后可能只剩下1个像素的问题。特征融合区域提案网络(RPN)从被裁剪和缩放的图像和BEV中提取等长特征,然后使用1x1卷积减小维度减轻计算。


物体中心融合方法的一个缺点是RoI池化丢失了细粒度的几何信息。
- ContFuse:使用逐点融合,由连续卷积融合层实现,在网络的不同阶段,将不同尺度的图像和点云特征之间建立桥梁。即提取BEV每个像素中的KNN点,然后投影到图像上得到图像特征,最后融合的特征根据其对像素的几何偏移量进行加权,输入到MLP中。
逐点融合可能不能充分利用图像信息,特别是点云稀疏的时候。一些方法使用深度补全上采样点云,来减轻这个问题。
- MVX-Net:使用预训练的2D CNN处理图像。逐像素融合方法先将点云投影到图像获取图像特征,然后体素化送入VoxelNet。逐体素融合方法先将点云体素化,再将非空体素投影到图像上得到体素特征。这些体素特征只在VoxelNet的后期附加到相应的体素。
C.单阶段模型
- LaserNet使用2个CNN分别并行处理深度图和前视图,然后通过将点投影到图像来融合特征。然后LaserNet使用融合特征预测。
V.静态目标检测
分别路面目标检测(如车道或道路标记)和路上目标检测(如交通标志)。
A.车道检测
传统车道检测方法主要使用视觉方法,激光雷达仅用于路缘拟合和障碍检测。
融合方法包含基于BEV的检测,和基于前摄像机视图的检测。
前者将点云和图像投影到BEV。
- 如MSRF在网络的多个层次融合图像和点云信息。

后者将点云投影到图像,但存在边界从2D到3D转换的精度损失。如
- LCNet使用交叉融合方法。
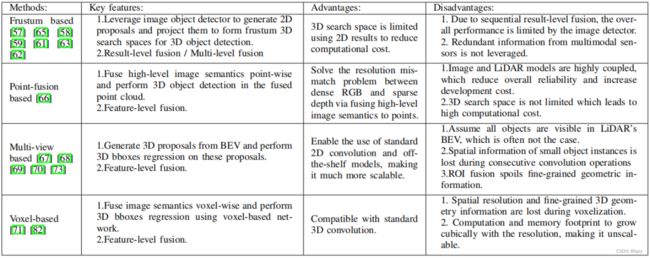
- PLARD逐步融合图像和点云特征。

B.交通标志检测
交通标志因其反光特性在激光雷达中高度可区分,但由于其稀疏的纹理信息,分类很困难;图像中分类很容易,但定位很困难。
经典融合方法先利用其反光特性在激光雷达点云中定位交通标志,再投影到图像得到相应区域,最后使用图像分类器分类(结果层面的融合)。但这都基于交通标志在激光雷达点云中可见的假设,但有时因为遮挡而不成立。

新融合方法往往基于多模态数据和先验知识。如有的方法将RGB值附加到点云上生成带颜色的点云进行检测,然后使用路标的几何先验减少FP的出现。
VI.语义分割
A.2D语义分割
特征层面的融合:
- 如Sparse & Dense分别编码图像和稀疏深度图,然后融合输入解码器。

B.3D语义分割
特征层面的融合:
- 如3DMV在体素化点云中融合图像语义和体素特征。图像特征由2D CNN从多视角的对齐图像中提取,并投影到3D空间。然后在体素内使用最大池化,并与3D几何信息融合,输入到3D CNN进行语义分割。
- UPF和MVPNet直接使用融合的点云输入到PointNet(++)进行分割。

C.实例分割
(1)基于提案的方法:
- 3D-SIS:使用RGB-D扫描数据和多视角图像。多视角图像使用基于ENet的网络提取特征并下采样,以解决图像和体素化点云分辨率不一致的问题。然后图像特征投影到体素空间,附加到3D几何信息上,使用3D CNN估计类别和边界框。最后将图像、点云特征和3D目标检测结果输入3D CNN得到逐体素标签。

(2)无需提案的方法:
- 3D-BEVIS:从2D BEV提取语义和实例特征,然后使用GNN传播到点云。最后均值移位算法,利用语义特征将点云聚类为实例。
VII.目标跟踪
根据目标初始化方法,分为基于检测的跟踪(DBT)和无需检测的跟踪(DFT)。前者使用目标检测器提供的线索,通过数据关联或者多重跟踪假设;后者使用有限集统计量(FISST)进行状态估计,包括多目标多伯努利(MeMBer)滤波器和概率假设密度(PHD)滤波器等。

A.基于检测的跟踪
两个阶段:目标检测和数据关联(线性规划)。
常见的模型分为三步:目标检测、提案匹配(相邻估计)和线性优化(如使用最小代价流求最优轨迹)。
- 此外,如MOTSFusion使用3D重建来使跟踪对完全遮挡鲁棒。第一阶段将目标与tracklet相关联,然后使用匈牙利算法将tracklet匹配和合并为轨迹。
B.无需检测的跟踪
目标被手动初始化,使用基于滤波器的方法。
- Complexer-YOLO:实现了目标检测和跟踪的解耦。2D语义被提取和融合到点云中,然后点云体素化输入到complex-YOLO进行3D目标检测。用缩放-旋转-平移分数(评估边界框的3DoF)替换IoU作为指标以加速训练。目标跟踪是通过Labeled Multi-Bernoulli Random Finite Sets Filter (LMB RFS)实现的。
VIII.在线跨传感器校正
离线校正麻烦而耗时;机械振动和温度变换都会导致校准参数变化。因此需要在线校正。
A.经典在线校正
在无校正目标的情况下估计外参。例如通过最大化多模态之间的互信息(MI),但对纹理丰富的环境和遮挡等不鲁棒。基于激光雷达的视觉测程法使用相机的自我运动估计相机和激光雷达的外参,但不能实时运行。
B.基于深度学习的在线校正
基于深度学习的方法计算复杂度更高。
- RegNet:使用随机去校正的数据来训练。并行提取图像和深度特征,拼接融合,输入到Network In Network(NiN)模块和两个全连接层进行特征匹配和全局回归。但因为其不知道内参,一旦内参变化就要重新训练。
- CalibNet:以自监督方式最小化错误校正深度和目标深度在几何和光度的不一致性。能在任何校正了内参的相机上使用。
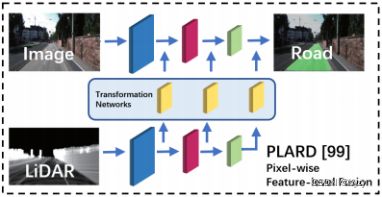
IX.挑战
(4)传统方法有更好的可解释性,且计算复杂度往往更低;深度学习方法往往是不可回溯的。因此目前传统方法不能完全丢掉。
(5)现在的融合引入了传感器耦合,一个传感器失效会导致性能丢失,影响后续任务。
(8)open set:检测未知类别的物体。目前缺乏测试协议和评价指标。
(9)可放缩性:通过减小输入或者减小网络层数实现。基于点和多视图的融合方法比基于体素的融合方法在可放缩性上更好。