【Android Jetpack】DataStore的介绍
DataStore
Jetpack DataStore是一种数据存储解决方案,允许您使用协议缓冲区存储键值对或类型化对象。DataStore使用Kotlin协程和Flow以异步、一致的事务方式存储数据。
注意:如果您需要支持大型或复杂数据集、部分更新或参照完整性,请考虑使用 Room,而不是 DataStore。DataStore非常适合简单的小型数据集,不支持部分更新或参照完整性。
Preferences DataStore和Proto DataStore
DataStore提供两种不同的实现:Preferences DataStore和Proto DataStore。
- Preferences DataStore像SharedPreferences一样,以键值对的形式进行基本类型的数据存储。DataStore基于Flow实现异步存储,避免因为阻塞主线程带来的ANR问题
- Proto DataStore基于Protobuf实现任意自定义类型的数据存储,需要定义Protobuf的IDL,但是可以保证类型安全的访问。存储类的对象(typed objects ),通过protocol buffers将对象序列化存储在本地,protocol buffers现在已经应用的非常广泛,无论是微信还是阿里等等大厂都在使用。
SharedPreferences的缺点
SharedPreference是一个轻量级的数据存储方式,使用起来也非常方便,以键值对的形式存储在本地,初始化SharedPreference的时候,会将整个文件内容加载内存中,因此会带来以下问题:
-
通过
getXXX()方法获取数据,可能会导致主线程阻塞所有getXXX()方法都是同步的,在主线程调用get方法,必须等待SharedPreference加载完毕,会导致主线程堵塞。
-
SharedPreference不能保证类型安全
调用getXXX()方法的时候,可能会出现ClassCastException异常,因为使用相同的key进行操作的时候,putXXX()方法可以使用不同类型的数据覆盖相同的key。
-
SharedPreference 加载的数据会一直留在内存中,浪费内存
通过getSharedPreferences()方法加载的数据,最后会将数据存储在静态的成员变量中。
-
apply()方法虽然是异步的,但是可能会发生ANR,在8.0之前和8.0之后实现各不相同
apply()方法是异步的,本身是不会有任何问题,但是当生命周期处于handleStopService()、handlePauseActivity()、handleStopActivity()的时候会一直等待apply()方法将数据保存成功,否则会一直等待,从而阻塞主线程造成ANR。 -
apply()方法无法获取到操作成功或者失败的结果apply()方法无法获取到操作成功或者失败的结果,而commit()方法是可以接收MemoryCommitResult里面的一个boolean参数作为结果 -
SP不能用于跨进程通信
DataStore的优点
Preferences DataStore主要用来替换SharedPreferences,Preferences DataStore解决了SharedPreferences带来的所有问题
**Preferences DataStore相比于SharedPreferences优点: **
- DataStore是基于Flow实现的,所以保证了在主线程的安全性
- 以事务方式处理更新数据,事务有四大特性(原子性、一致性、 隔离性、持久性)
- 自动完成SharedPreferences迁移到DataStore,保证数据一致性,不会造成数据损坏
- 可以监听到操作成功或者失败结果
使用Preferences DataStore存储键值对
Preferences DataStore实现使用DataStore和Preferences 类将简单的键值对保留在磁盘上。
创建Preferences DataStore
使用由preferencesDataStore 创建的属性委托来创建Datastore实例。在您的Kotlin文件顶层调用该实例一次,便可在应用的所有其余部分通过此属性访问该实例。这样可以更轻松地将DataStore保留为单例。
// At the top level of your kotlin file
val Context.dataStore: DataStore<Preferences> by preferencesDataStore(name = "settings") //name = "" 中填写的为名字
从Preferences DataStore读取内容
由于Preferences DataStore不使用预定义的架构,因此您必须使用相应的键类型函数为需要存储在DataStore实例中的每个值定义一个键。
例如,如需为int 值定义一个键,请使用intPreferencesKey()。然后,使用DataStore.data 属性,通过Flow 提供适当的存储值。
val EXAMPLE_COUNTER = intPreferencesKey("example_counter")
val exampleCounterFlow: Flow<Int> = context.dataStore.data .map {
preferences ->
// No type safety.
preferences[EXAMPLE_COUNTER] ?: 0}
将内容写入Preferences DataStore
Preferences DataStore提供了一个edit() 函数,用于以事务方式更新DataStore中的数据。该函数的transform参数接受代码块,您可以在其中根据需要更新值。转换块中的所有代码均被视为单个事务。
suspend fun incrementCounter() { context.dataStore.edit { settings -> val currentCounterValue = settings[EXAMPLE_COUNTER] ?: 0 settings[EXAMPLE_COUNTER] = currentCounterValue + 1 }}
使用Proto DataStore存储类型化的对象
既生Preference DataStore何生Proto DataStore,它们之间有什么区别?
- Preference DataStore主要是为了解决SharedPreferences所带来的性能问题
- Proto DataStore比Preference DataStore 更加灵活,支持更多的类型
- Preference DataStore支持Int、Long、Boolean、Float、String
- protocol buffers支持的类型,Proto DataStore都支持
- Preference DataStore以XML的形式存储key-value数据,可读性很好
- Proto DataStore使用了二进制编码压缩,体积更小,速度比XML更快
序列化
序列化:将一个对象转换成可存储或可传输的状态,数据可能存储在本地或者在蓝牙、网络间进行传输。序列化大概分为对象序列化、数据序列化。
对象的序列化
Java对象序列化 将一个存储在内存中的对象转化为可传输的字节序列,便于在蓝牙、网络间进行传输或者存储在本地。把字节序列还原为存储在内存中的Java对象的过程称为反序列化。
在Android中可以通过Serializable和Parcelable两种方式实现对象序列化。
Serializable
Serializable是Java原生序列化的方式,主要通过ObjectInputStream和ObjectOutputStream来实现对象序列化和反序列化,但是在整个过程中用到了大量的反射和临时变量,会频繁的触发GC,序列化的性能会非常差,但是实现方式非常简单,来看一下ObjectInputStream和ObjectOutputStream源码里有很多反射的地方。
ObjectOutputStream.java
private void writeObject0(Object obj, boolean unshared)
throws IOException{
......
Class<?> cl = obj.getClass();
......
}
ObjectInputStream.java
void readFields() throws IOException {
......
ObjectStreamField[] fields = desc.getFields(false);
for (int i = 0; i < objVals.length; i++) {
objVals[i] =
readObject0(fields[numPrimFields + i].isUnshared());
objHandles[i] = passHandle;
}
......
}
复制代码
在Android中存在大量跨进程通信,由于Serializable性能差的原因,所以Android需要更加轻量且高效的对象序列化和反序列化机制,因此Parcelable出现了。
Parcelable
Parcelable的出现解决了Android中跨进程通信性能差的问题,而且Parcelable比Serializable要快很多,因为写入和读取的时候都是采用自定义序列化存储的方式,通过writeToParcel()方法和describeContents()方法来实现,不需要使用反射来推断它,因此性能得到提升,但是使用起来比Serializable要复杂很多。
Kotlin语言的话可以使用 @Parcelize注解,快速的实现Parcelable序列化。
Serializable和Parcelable的区别:

数据序列化
对象序列化记录了很多信息,包括Class信息、继承关系信息、变量信息等等,但是数据序列化相比于对象序列化就没有这么多沉余信息,数据序列化常用的方式有JSON、Protocol Buffers、FlatBuffers。
-
JSON:是一种轻量级的数据交互格式,支持跨平台、跨语言,被广泛用在网络间传输,JSON的可读性很强,但是序列化和反序列化性能却是最差的,解析过程中,要产生大量的临时变量,会频繁的触发GC,为了保证可读性,并没有进行二进制压缩,当数据量很大的时候,性能上会差一点。
-
Protocol Buffers:它是Google开源的跨语言编码协议,可以应用到C++、C#、Dart 、Go 、Java、Python等等语言,Google内部几乎所有RPC都在使用这个协议,使用了二进制编码压缩,体积更小,速度比JSON更快,但是缺点是牺牲了可读性
RPC指的是跨进程远程调用,即一个进程调用另外一个进程的方法。
-
FlatBuffers:同Protocol Buffers一样是Google开源的跨平台数据序列化库,可以应用到C++、C#,Go、Java、JavaScript、PHP、Python 等等语言,空间和时间复杂度上比其他的方式都要好,在使用过程中,不需要额外的内存,几乎接近原始数据在内存中的大小,但是缺点是牺牲了可读性
最后我们用一张图来分析一下JSON、Protocol Buffers、FlatBuffers 它们序列化和反序列的性能,数据来源于JSON vs Protocol Buffers vs FlatBuffers

FlatBuffers和Protocol Buffers无论是序列化还是反序列都完胜JSON,FlatBuffers 最初是Google为游戏或者其他对性能要求很高的应用开发的,接下来我们来看一下今天主角Protocol Buffer。
Protocol Buffer
Protocol Buffer(简称Protobuf) 它是Google开源的跨语言编码协议,可以应用到C++、C#、Dart、Go、Java、Python等等语言,Google内部几乎所有RPC都在使用这个协议,使用了二进制编码压缩,体积更小,速度比JSON更快。
从Proto3.0.0 Release Note 得知:protocol buffers最初开源时,它实现了Protocol Buffers语言版本2(称为 proto2), 这也是为什么版本数从v2.0.0开始,从v3.0.0开始, 引入新的语言版本(proto3),而旧的版本(proto2)继续被支持。所以到目前为止Protobuf共两个版本proto2和proto3。
proto2和proto3应该学习那个版本?
proto3简化了proto2的语法,提高了开发的效率,因此也带来了版本不兼容的问题,因为2019年的时候才发布proto3稳定版本,所以在这之前使用Protocol Buffer的公司,大部分项目都是使用proto2的版本,从上文的源码分析部分可知,在DataStore中使用了proto2语法,所以proto2和proto3这两种语法都同时在使用。
对于初学者而言直接学习proto3语法就可以了,为了适应技术迭代的变化,当掌握proto3语法之后,可以顺带了解一下proto2语法以及proto3和proto2语法的区别,这样可以更好的理解其他的开源项目。
为了避免混淆proto3和proto2语法,在本文仅仅分析proto3语法,当我们了解完这些基本概念之后,我们开始分析如何在项目中使用Proto DataStore。
Proto DataStore实现使用DataStore和协议缓冲区将类型化的对象保留在磁盘上。
定义架构
Proto DataStore 要求在 app/src/main/proto/ 目录的 proto 文件中保存预定义的架构。此架构用于定义您在 Proto DataStore 中保存的对象的类型。如需详细了解如何定义 proto 架构,请参阅 protobuf 语言指南。
syntax = "proto3"; option java_package = "com.example.application"; option java_multiple_files = true; message Settings { int32 example_counter = 1; }
注意:您的存储对象的类在编译时由 proto 文件中定义的 message 生成。请务必重新构建您的项目。
创建 Proto DataStore
创建 Proto DataStore 来存储类型化对象涉及两个步骤:
- 定义一个实现
Serializer的类,其中T是 proto 文件中定义的类型。此序列化器类会告知 DataStore 如何读取和写入您的数据类型。请务必为该序列化器添加默认值,以便在尚未创建任何文件时使用。 - 使用由
dataStore创建的属性委托来创建DataStore的实例,其中T是在 proto 文件中定义的类型。在您的 Kotlin 文件顶层调用该实例一次,便可在应用的所有其余部分通过此属性委托访问该实例。filename参数会告知 DataStore 使用哪个文件存储数据,而serializer参数会告知 DataStore 第 1 步中定义的序列化器类的名称。
KotlinJava
object SettingsSerializer : Serializer { override val defaultValue: Settings = Settings.getDefaultInstance() override suspend fun readFrom(input: InputStream): Settings { try { return Settings.parseFrom(input) } catch (exception: InvalidProtocolBufferException) { throw CorruptionException("Cannot read proto.", exception) } } override suspend fun writeTo( t: Settings, output: OutputStream) = t.writeTo(output)}val Context.settingsDataStore: DataStore by dataStore( fileName = "settings.pb", serializer = SettingsSerializer)
从 Proto DataStore 读取内容
使用 DataStore.data 显示所存储对象中相应属性的 Flow。
KotlinJava
val exampleCounterFlow: Flow = context.settingsDataStore.data .map { settings -> // The exampleCounter property is generated from the proto schema. settings.exampleCounter }
将内容写入 Proto DataStore
Proto DataStore 提供了一个 updateData() 函数,用于以事务方式更新存储的对象。updateData() 为您提供数据的当前状态,作为数据类型的一个实例,并在原子读-写-修改操作中以事务方式更新数据。
KotlinJava
suspend fun incrementCounter() { context.settingsDataStore.updateData { currentSettings -> currentSettings.toBuilder() .setExampleCounter(currentSettings.exampleCounter + 1) .build() }}
在同步代码中使用 DataStore
注意:请尽可能避免在 DataStore 数据读取时阻塞线程。阻塞界面线程可能会导致 ANR 或界面卡顿,而阻塞其他线程可能会导致死锁。
DataStore 的主要优势之一是异步 API,但可能不一定始终能将周围的代码更改为异步代码。如果您使用的现有代码库采用同步磁盘 I/O,或者您的依赖项不提供异步 API,就可能出现这种情况。
Kotlin 协程提供 runBlocking() 协程构建器,以帮助消除同步与异步代码之间的差异。您可以使用 runBlocking() 从 DataStore 同步读取数据。RxJava 在 Flowable 上提供阻塞方法。以下代码会阻塞发起调用的线程,直到 DataStore 返回数据:
KotlinJava
val exampleData = runBlocking { context.dataStore.data.first() }
对界面线程执行同步 I/O 操作可能会导致 ANR 或界面卡顿。您可以通过从 DataStore 异步预加载数据来减少这些问题:
KotlinJava
override fun onCreate(savedInstanceState: Bundle?) { lifecycleScope.launch { context.dataStore.data.first() // You should also handle IOExceptions here. }}
这样,DataStore 可以异步读取数据并将其缓存在内存中。以后使用 runBlocking() 进行同步读取的速度可能会更快,或者如果初始读取已经完成,可能也可以完全避免磁盘 I/O 操作。
https://developer.android.com/topic/libraries/architecture/datastore#typed-datastore
https://android-developers.googleblog.com/2020/09/prefer-storing-data-with-jetpack.html
https://blog.csdn.net/zzw0221/article/details/109274610
SharedPreferences 有着许多缺陷: 看起来可以在 UI 线程安全调用的同步 API 其实并不安全、没有提示错误的机制、缺少事务 API 等等。DataStore 是 SharedPreferences 的替代方案,它解决了 Shared Preferences 的绝大部分问题。DataStore 包含使用 Kotlin 协程和 Flow 实现的完全异步 API,可以处理数据迁移、保证数据一致性,并且可以处理数据损坏。
https://blog.csdn.net/weixin_42324979/article/details/112650189?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-3.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-3.control
缺点:
- 目前Jetpack Security没有支持DataStore,所以不能像SharedPreference一样支持加密
- 不能安全的进行IPC,这点相对于SharedPreferences没有提升,有较强IPC需求的话首选MMKV
- 使用PB进行序列化时需要额外定义IDL,这会产生一定工作量
最后用一张表格来对比一下 MMKV、DataStore、SharedPreferences 的不同之处,如果发现错误,或者有其他不同之处,期待你来一起完善。
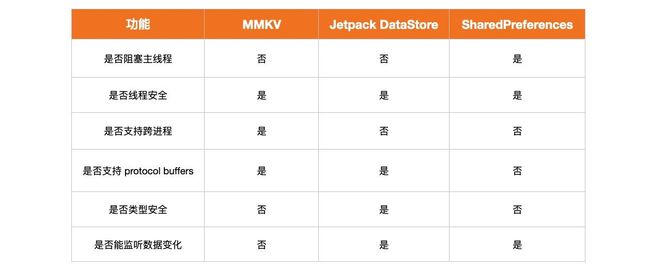
目前为止,MMKV 功能比 DataStore 强大,毕竟 MMKV 已经经历好几个年头了, DataStore 才只是 alpha01 版本,但是 DataStore 作为 Jetpack 的成员,背靠 Google 的支持,加上全球的开发者一起来完善,从未来角度 DataStore 功能会逐渐完善。DataStore 的版本还是挺优势的,例如:类型安全检查,DataStore 编译的时候,就会告诉开发者类型不对,相比于运行时错误,编译时错误提示更好