13-数据采集项目03
一、Hive上的数据导入
##4. 创建ods层
[root@hadoop hive-1.2.1]# beeline -u jdbc:hive2://caiji:10000 -n root -p 123456 -e "create database if not exists ods_news"
[root@hadoop hive-1.2.1]# beeline -u jdbc:hive2://caiji:10000 -n root -p 123456 -e "show databases"
也可以使用hive中的命令,hive -e "sql语句"接着上传两个jar包:
这两个jar包使用来处理json数据的。因为我们上传到hdfs上的数据是json格式的。
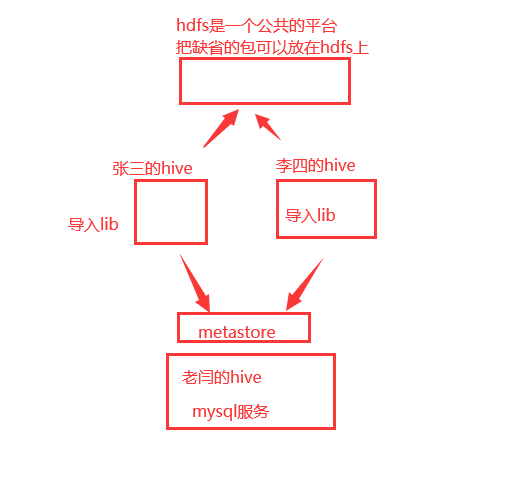
创建文件夹:hdfs dfs -mkdir -p /common/lib
将两个文件上传至hdfs的这个/common/lib目录下面
hdfs dfs -put json-serde-1.3.8-jar-with-dependencies.jar /common/lib
hdfs dfs -put json-udf-1.3.8-jar-with-dependencies.jar /common/lib[root@hadoop ~]# vi ~/.hiverc
add jar hdfs:///common/lib/json-udf-1.3.8-jar-with-dependencies.jar;
add jar hdfs:///common/lib/json-serde-1.3.8-jar-with-dependencies.jar;
##7.beeline需要手动指定这个文件的位置
beeline -i ~/.hiverc
.hiverc 文件到底放在哪里?
假如你经常使用hive,就把这个文件放在hive/conf 下,每次hive 进入的时候就会加载这个文件。创建表的语句,解析:
{
"ctime": 1589781236541,
"project": "news",
"content": {
"distinct_id": "51818968",
"event": "AppClick",
"properties": {
"element_page": "新闻列表页",
"screen_width": "640",
"app_version": "1.0",
"os": "GNU/Linux",
"battery_level": "11",
"device_id": "886113235750",
"client_time": "2020-05-18 13:53:56",
"ip": "61.233.88.41",
"is_charging": "1",
"manufacturer": "Apple",
"carrier": "中国电信",
"screen_height": "320",
"imei": "886113235750",
"model": "",
"network_type": "WIFI",
"element_name": "tag"
}
}
}CREATE EXTERNAL TABLE if not exists ods_news.news
(
project string,
ctime string,
content struct<
distinct_id:string,
event:string,
properties:
struct>)
PARTITIONED BY(logday string)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION '/sources/news/'
两种办法:第一种,进入hive ,执行建表语句
第二种:beeline -i ~/.hiverc -u jdbc:hive2://caiji:10000 -n root -p 123456 -e "CREATE EXTERNAL TABLE if not exists ods_news.news
(
project string,
ctime string,
content struct<
distinct_id:string,
event:string,
properties:
struct>)
PARTITIONED BY(logday string)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION '/sources/news/'" 由于 数据中有json,想要将json解析为 数据,需要指定解析的规则 org.openx.data.jsonserde.JsonSerDe
你想使用这个类,就必须导入包。使用一个脚本,创建news表,并且添加分区
alter table ods_news.news add partition(logday='20230913') location '/sources/news/20230913';
复习一下如何获取一个日期的前一天
[root@caiji ~]# date -d "2023-09-14 1 days ago" +%Y%m%d
20230913
[root@caiji ~]# date -d "1 days ago" +%Y%m%d
20230912news_add_partition.sh
#!/bin/bash
# filename:news_add_partition.sh
# author:laoyan
# date:2022-06-15
# desc:将hdfs的行为数据和hive做映射
##1. 申明变量
B_HOST=caiji
B_PORT=10000
B_USER=root
HIVE_HOME=/opt/installs/hive
##2. 导入的日期
exec_date=$1
if [ "${exec_date}" ]; then
exec_date=`date -d "${exec_date} 1 days ago" +%Y%m%d`
else
exec_date=`date -d "1 days ago" +%Y%m%d`
fi
echo "news_add_partition.sh exec_date is ${exec_date}"
##3. 建表的SQL
CREATE_TABLE_SQL="CREATE EXTERNAL TABLE if not exists ods_news.news(project string,ctime string,content struct>) PARTITIONED BY(logday string) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' LOCATION '/sources/news/'"
echo "${CREATE_TABLE_SQL}"
${HIVE_HOME}/bin/beeline -i ~/.hiverc -n ${B_USER} -p 123456 -u jdbc:hive2://${B_HOST}:${B_PORT} -e "${CREATE_TABLE_SQL}"
##4. 修改表:添加分区
ADD_PARTITION_SQL="alter table ods_news.news drop if exists partition(logday='${exec_date}');alter table ods_news.news add partition(logday='${exec_date}') location 'hdfs://${B_HOST}:9820/sources/news/${exec_date}';"
echo "${ADD_PARTITION_SQL}"
${HIVE_HOME}/bin/beeline -i ~/.hiverc -n ${B_USER} -p 123456 -u jdbc:hive2://${B_HOST}:${B_PORT} -e "${ADD_PARTITION_SQL}"
##5. 结束
echo "insert successful" 以上脚本只干了两件事情:
1、创建分区表
2、创建分区表中的一个分区
查看分区信息:
show partitions news;映射到有数据的分区文件夹下,比如,我有20221008有数据
sh news_add_partition.sh 202309140: jdbc:hive2://spark01:10000> select * from news limit 10;
Error: java.lang.Error: Data is not JSONObject but java.lang.String with value {"distinct_id":"0","type":"profile_set","uuid":"b5fb482e-e2e6-470e-8f35-6cf0524f49a3","properties":{"gender":"男","nick_name":"Delilah BrekkePadberg.2556","mobile":"+8616658378336","name":"薄婉静","signup_time":1665215649000,"email":"[email protected]","age":"82"}} (state=,code=0)
删除掉之前的数据:
hdfs dfs -rm -R /sources/news/20230913/*
重新采集一下。
[root@caiji scripts]# pgrep -af nginx
107947 nginx: master process openresty -p /opt/apps/collect-app/
107948 nginx: worker process
107949 nginx: worker process
107950 nginx: worker process
107951 nginx: worker process
启动frpc服务:
frpc http --sd yanlaoshi -l 8802 -s frp.qfbigdata.com:7001 -u yanlaoshi
同步一下时间:
ntpdate time1.aliyun.com
启动flume脚本,抽取数据
./flume-agent.sh
定时任务需要启动 systemctl status crond进入hive ,查看数据:
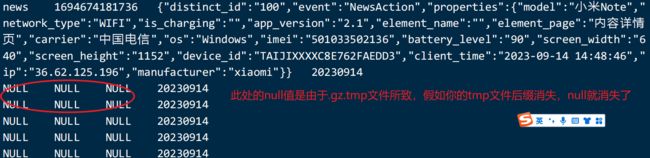
hive 在进入数据库的时候,会加载 conf / .hiverc 文件,你没有,加载不了jar包,所以报错,怎么解决,在conf下创建一个hiverc
cp ~/.hiverc /opt/installs/hive/conf/
或者直接使用beeline , beeline -i ~/.hiverc
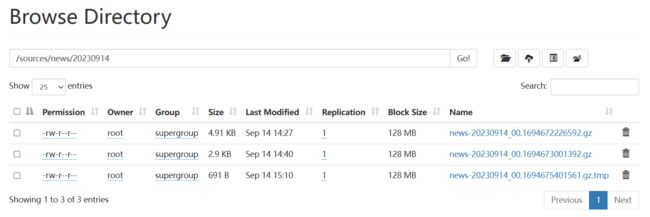
当你的分区下有tmp文件的时候,就会查询到null,这个是一个正常的现象。
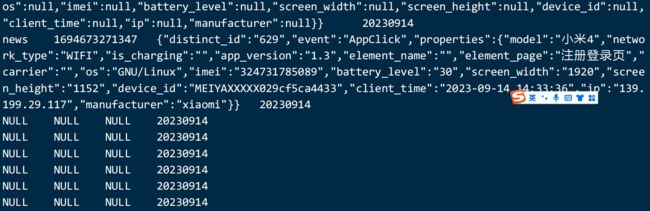
假如你执行sql语句:select count(1) from news; 报错
yarn-site.xml中
yarn.application.classpath
你的路径信息(刚才复制的路径信息)
value值,通过 hadoop classpath命令获取到
yarn.application.classpath
/opt/installs/hadoop/etc/hadoop:/opt/installs/hadoop/share/hadoop/common/lib/*:/opt/installs/hadoop/share/hadoop/common/*:/opt/installs/hadoop/share/hadoop/hdfs:/opt/installs/hadoop/share/hadoop/hdfs/lib/*:/opt/installs/hadoop/share/hadoop/hdfs/*:/opt/installs/hadoop/share/hadoop/mapreduce/*:/opt/installs/hadoop/share/hadoop/yarn:/opt/installs/hadoop/share/hadoop/yarn/lib/*:/opt/installs/hadoop/share/hadoop/yarn/*
重启yarn服务,即可。假如你flume抽取数据的时候,抽取不成功,什么错误都不报。
flume的执行 flume 的job 下面。
flume-ng agent -n a1 -c ../conf/ -f collect-app-agent.conf
在别的目录下,执行的是绝对路径:
flume-ng agent -n a1 -c /opt/installs/flume/conf/ -f /opt/installs/flume/job/collect-app-agent.conf
尝试使用相对路径,不要使用绝对路径
还有一个错误:
你的文件夹下 20230913日的数据
但是你创建了一个20230914号的分区
分区是不是每天都要创建一个?是,谁创建,自动创建(使用脚本+定时任务)二、业务数据【数据库】采集
1、业务数据来自于数据
创建数据库biz,然后导入数据 biz.sql

2、sqoop连接数据库
sqoop list-databases \
--connect jdbc:mysql://caiji:3306?useSSL=false \
--username root \
--password 1234563、通过sqoop 将mysql的数据采集到hdfs上
sqoop import --connect jdbc:mysql://192.168.235.140:3306/sqoop \
--username root --password 123456 \
--query 'select empno,sal,mgr,job from emp where empno<7788 and $CONDITIONS' \
--target-dir /home \
--delete-target-dir \
--split-by empno \
-m 14、编写一个脚本可以抽取数据到hdfs上
如果指定了时间,就抽取这个时间的前一天,如果没有指定时间,当前时间的前一天
biz2hdfs.sh
#!/bin/bash
# filename:biz2hdfs.sh
# author:laoyan
# date:2022-06-15
# desc:sqoop导入biz的数据到hdfs
## 变量
SQOOP_HOME=/opt/installs/sqoop
MYSQL_URI=jdbc:mysql://caiji:3306/biz?useSSL=false
MYSQL_USR=root
MYSQL_PWD=123456
## 定义一个日期,如果你输入了日期,就采集这个日期的前一天的数据。如果没有输入日期,我们就采集昨天的数据
exec_date=$1
if [ "${exec_date}" ]; then
exec_date=`date -d "${exec_date} 1 days ago" +%Y%m%d`
else
exec_date=`date -d "1 days ago" +%Y%m%d`
fi
echo "biz2hdfs.sh exec_date is ${exec_date}"
## 将exec_date转换为sql_date: %Y%m%d -> %Y-%m-%d
SQL_DATE=`date -d "${exec_date}" +%Y-%m-%d`
echo "SQL_Date is ${SQL_DATE}"
## 导入数据
## ad_info
${SQOOP_HOME}/bin/sqoop import \
--connect ${MYSQL_URI} \
--username ${MYSQL_USR} \
--password ${MYSQL_PWD} \
--query "select id, cast(ad_id as char(50)) as ad_id, cast(advertiser_id as char(50)) as advertiser_id, advertiser_name, date_format(create_time, '%Y-%m-%d %H:%i:%s') as create_time, date_format(update_time, '%Y-%m-%d %H:%i:%s') as update_time from ad_info where 1=1 and create_time<='${SQL_DATE} 00:00:00' and \$CONDITIONS" \
--as-parquetfile \
--target-dir /sources/news-biz/ad_info/${exec_date} \
--delete-target-dir \
--split-by id \
--num-mappers 3
## meta
${SQOOP_HOME}/bin/sqoop import \
--connect ${MYSQL_URI} \
--username ${MYSQL_USR} \
--password ${MYSQL_PWD} \
--query "select id, field, field_type, field_desc, app_version, cast(status as char(50)) as status, date_format(create_time, '%Y-%m-%d %H:%i:%s') as create_time, date_format(update_time, '%Y-%m-%d %H:%i:%s') as update_time from meta where 1=1 and create_time<'${SQL_DATE} 00:00:00' and \$CONDITIONS" \
--as-parquetfile \
--target-dir /sources/news-biz/meta/${exec_date} \
--delete-target-dir \
--split-by id \
--num-mappers 3运行过程出现这个错误:

在yarn-site.xml中,添加如下配置:
yarn.application.classpath
你的路径信息(刚才复制的路径信息)
value值,通过 hadoop classpath命令获取到如果之前采集过,直接删除hdfs上的数据
hdfs dfs -rm -r /sources/news-biz执行脚本进行采集
sh biz2hdfs.sh
为什么有时候 ./biz2hdfs.sh 有时候 sh biz2hdfs.sh
如果./ 当前文件夹的意思,这个sh文件必须是可执行文件,是需要赋权限的 chmod u+x biz2hdfs.sh
sh biz2hdfs.sh 它的意思是通过sh 解释器解释执行这个文件,不需要添加权限 
5、将hdfs上的数据映射到hive表中
编写 biz_add_partition.sh
使用hive创建了两个表,并且增加了分区
#!/bin/bash
# filename:biz_add_partition.sh
# author:laoyan
# date:2022-06-16
# desc:将hdfs的业务数据和hive做映射
##1. 申明变量
B_HOST=caiji
B_PORT=10000
B_USER=root
HIVE_HOME=/opt/installs/hive
##2. 导入的日期
exec_date=$1
if [ "${exec_date}" ]; then
exec_date=`date -d "${exec_date} 1 days ago" +%Y%m%d`
else
exec_date=`date -d "1 days ago" +%Y%m%d`
fi
echo "biz_add_partition.sh exec_date is ${exec_date}"
##3. 建表的SQL
##3.1 meta
CREATE_META_TABLE_SQL="CREATE external TABLE ods_news.meta (
field string,
field_type string,
field_desc string,
app_version string,
status string,
create_time string,
update_time string
)
partitioned by(logday string)
stored as parquet
location '/sources/news-biz/meta'"
echo "${CREATE_META_TABLE_SQL}"
${HIVE_HOME}/bin/beeline -i ~/.hiverc -n ${B_USER} -p 123456 -u jdbc:hive2://${B_HOST}:${B_PORT} -e "${CREATE_META_TABLE_SQL}"
##3.2 ad
CREATE_AD_TABLE_SQL="CREATE external TABLE ods_news.ad_info (
ad_id string,
advertiser_id string,
advertiser_name string,
create_time string,
update_time string
)
partitioned by(logday string)
stored as parquet
location '/sources/news-biz/ad_info'"
echo "${CREATE_AD_TABLE_SQL}"
${HIVE_HOME}/bin/beeline -i ~/.hiverc -n ${B_USER} -p 123456 -u jdbc:hive2://${B_HOST}:${B_PORT} -e "${CREATE_AD_TABLE_SQL}"
##4. 修改表:添加分区
ADD_PARTITION_SQL="alter table ods_news.meta drop if exists partition(logday='${exec_date}');alter table ods_news.ad_info drop if exists partition(logday='${exec_date}');alter table ods_news.meta add partition(logday='${exec_date}') location '/sources/news-biz/meta/${exec_date}';alter table ods_news.ad_info add partition(logday='${exec_date}') location '/sources/news-biz/ad_info/${exec_date}';"
echo "${ADD_PARTITION_SQL}"
${HIVE_HOME}/bin/beeline -i ~/.hiverc -n ${B_USER} -p 123456 -u jdbc:hive2://${B_HOST}:${B_PORT} -e "${ADD_PARTITION_SQL}"
##5. 结束
echo "insert successful"