三十分钟学会Hive
Hive的概念与运用
Hive 是一个构建在Hadoop 之上的数据分析工具(Hive 没有存储数据的能力,只有使用数据的能力),底层由 HDFS 来提供数据存储,可以将结构化的数据文件映射为一张数据库表,并且提供类似 SQL 的查询功能,本质就是将 HQL 转化成 MapReduce 程序。
Hive和传统数据库的区别
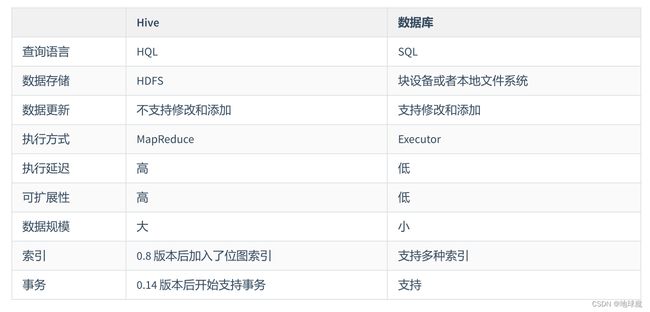
Hive和传统数据库的区别在于数据存储和处理⽅式不同
1.Hive是基于Hadoop的分布式数据存储和处理平台,适合处理⼤规模数据集,⽽传统的关系型数据库则着重于⾼度规范化的数据模式和事务处理。
2.Hive使⽤类SQL语⾔HQL进⾏查询和数据操作,可以将查询转换为MapReduce任务进⾏处理。同时,Hive⽀持⾃定义函数和UDF,能够⽅便地添加⾃定义逻辑来处理数据。
3.传统数据库的查询语⾔通常使⽤SQL,数据模式被⾼度规范化以确保数据的⼀致性和可靠性。传统数据库还⽀持ACID(原⼦性、⼀致性、隔离性和持久性)事务,可以确保事务的安全性和完整性。
Hive 优缺点
优点:
- 操作接口采用类似 SQL 的语法,提供快速开发的能力(简单、容易上手)。
- 免去了写 MapReduce 的过程,减少开发人员的学习成本。
- Hive 的执行延迟比较高,因此 Hive 常用于离线数据分析,对实时性要求不高的场合。
- Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。
- Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 集群可自由拓展并且具有良好的容错性,节点出现问题 SQL 仍可完成执行。
缺点:
-
Hive 的 HQL 表达能力有限,当逻辑需求特别复杂的时候,还是要借助 MapReduce。
迭代式算法无法表达数据挖掘方面不擅长
-
Hive 操作默认基于 MapReduce 引擎,而 MapReduce 引擎与其它的引擎(如 Spark 引擎)相比,特点就是慢、延迟高、不适合交互式查询,所以 Hive 也有这个缺点(这里讲的是默认引擎,Hive 是可以更改成其他引擎的)。
-
Hive 自动生成的 MapReduce 作业,通常情况下不够智能化。
-
Hive 调优比较困难,粒度较粗。
Hive架构
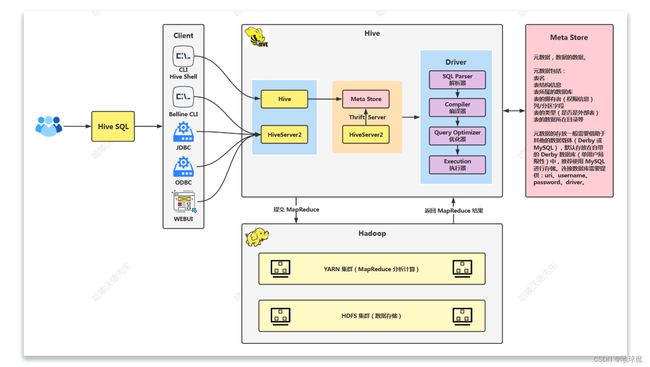
Client
Hive 允许 Client 连接的方式有三个 CLI(Hive Shell)、JDBC/ODBC(Java 访问 Hive)、WEBUI(浏览器访问 Hive)。
MetaStroe
通常用来存放:元数据,数据的数据。
元数据包括:表名、表结构信息、表所属的数据库(默认是 default 库)、表的拥有者(权限信息)、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。
元数据的存放一般需要借助于其他的数据载体(Derby 或 MySQL),默认存放在自带的 Derby 数据库(单用户局限性)中,推荐使用 MySQL 进行存储。连接数据库需要提供:uri、username、password、driver。
元数据服务的作用是:客户端连接 MetaStroe 服务,MetaStroe 服务再去连接 MySQL 数据库来存取元数据。
Driver

解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 ANTLR;对AST 进行语法分析,分析查询语法和查询计划,检查 SQL 语义是否有误。
编译器(Compiler):获取元数据,检查表是否存在、字段是否存在,然后将 AST 编译生成逻辑执行计划。
优化器(Query Optimizer):对逻辑执行计划进行优化。
执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。最后根据优化后的物理执行计划生成底层代码进行执行,对于 Hive 来说,就是 MR/Spark。
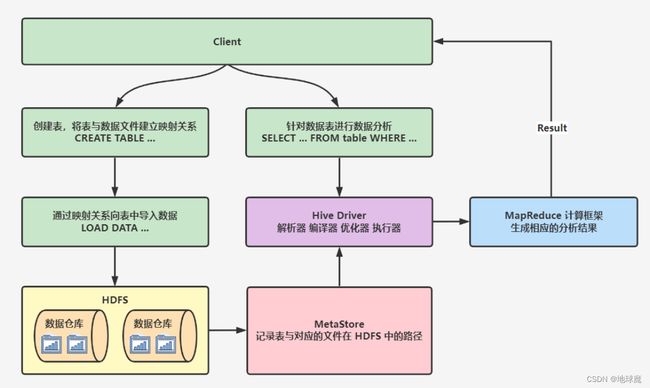
Hive 工作原理
当创建表的时候,需要指定 HDFS 文件路径,表和其文件路径会保存到 MetaStore,从而建立表和数据的映射关系。当数据加载入表时,根据映射获取到对应的 HDFS 路径,将数据导入。
用户输入 SQL 后,Hive 会将其转换成 MapReduce 或者 Spark 任务,提交到 YARN 上执行,执行成功将返回结果。
Hive 交互方式
hive
beeline -u jdbc:hive2://node01:10000 -n root
使用 -e 参数来直接执行 HQL 的语句。
bin/beeline -u "jdbc:hive2://node01:10000/default" hive -e "SHOW DATABASES;"
使用 -f 参数通过指定文本文件来执行 HQL 的语句。
bin/beeline -u "jdbc:hive2://node01:10000/default" hive -f "default.sql"
Hive 基础
数据库
创建数据库
创建一个数据库,数据库在 HDFS 上默认的存储路径是 /hive/warehouse/*.db 。
避免要创建的数据库已经存在错误,可以使用 IF NOT EXISTS 选项来进行判断。(标准写法)
CREATE DATABASE IF NOT EXISTS crm;
指定数据库创建的位置(数据库在 HDFS 上的存储路径)。
CREATE DATABASE IF NOT EXISTS school location '/hive/school.db';
修改数据库
用户可以使用 ALTER DATABASE 命令为某个数据库的 DBPROPERTIES 设置键-值对属性值,来描述这个数据库的属性信息。数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
ALTER DATABASE school SET DBPROPERTIES('createtime'='20220803');
数据库详情
显示所有数据库。
SHOW DATABASES;
可以通过 like 进行过滤。
SHOW DATABASES LIKE 's*';
查看某个数据库的详情。
DESC DATABASE school;
DESCRIBE DATABASE school;
切换数据库。
USE school;
删除数据库
DROP DATABASE IF EXISTS school;
如果数据库不为空,使用 CASCADE 命令进行强制删除。
DROP DATABASE IF EXISTS school CASCADE;
数据表
CREATE DATABASE IF NOT EXISTS test;
CREATE TABLE IF NOT EXISTS test.t_user (
id int,
username string,
password string,
gender string,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
LOAD DATA INPATH '/yjx/user.txt' INTO TABLE test.t_user;
简单的查询不会执行 MapReduce,复杂的查询会调用 MapReduce 模板生成 MapReduce 任务。
表详情
显示所有数据表。
SHOW TABLES;
可以通过 like 进行过滤。
SHOW TABLES LIKE 't*';
查看某个数据表的详情。
DESC t_person;
DESC FORMATTED t_person;
DESCRIBE FORMATTED t_person;
重命名
内部表会同时修改文件目录,外部表因为目录是共享的,所以不会修改目录名称。
ALTER TABLE old_table_name RENAME TO new_table_name;
修改列
-- 添加列
ALTER TABLE table_name ADD COLUMNS (new_col INT);
-- 一次增加一个列(默认添加为最后一列)
ALTER TABLE table_name ADD COLUMNS (new_col INT);
-- 可以一次增加多个列
ALTER TABLE table_name ADD COLUMNS (c1 INT, c2 STRING);
-- 添加一列并增加列字段注释
ALTER TABLE table_name ADD COLUMNS (new_col INT COMMENT 'a comment');
-- 更新列
ALTER TABLE table_name CHANGE old_col new_col STRING;
-- 将列 a 的名称更改为 a1
ALTER TABLE table_name CHANGE a a1 INT;
-- 将列 a1 的名称更改为 a2,将其数据类型更改为字符串,并将其放在列 b 之后
ALTER TABLE table_name CHANGE a1 a2 STRING AFTER b;
-- 将 c 列的名称改为 c1,并将其作为第一列
ALTER TABLE table_name CHANGE c c1 INT FIRST;
清空表
TRUNCATE TABLE table_name;
注意:清空表只能删除内部表的数据(HDFS 文件),不能删除外部表中的数据。
在 SQL 中,TRUNCATE 属于 DDL 语句,主要功能是彻底删除数据,使其不能进行回滚。
删除表
DROP TABLE table_name;
注意:删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
内外部表
内部表和外部表的区别
- 存储位置:内部表的数据存储在 Hive 的默认文件系统中,外部表的数据存储在外部文件系统中。
- Hive 内部表的管理既包含逻辑以及语法上的,也包含实际物理意义上的,即创建 Hive 内部表时,数据将真实存在于表所在的目录内,删除内部表时,物理数据和文件也⼀并删除。默认创建的是内部表。 外部表(external table)则不然,其管理仅仅只是在逻辑和语法意义上的,即新建表仅仅是指向⼀个外部目录。同样,删除时也并不物理删除外部⽬录,仅仅是将引⽤和定义删除 。
- 数据管理:对于内部表,当 DROP TABLE 时,表的元数据和数据都会被删除。⽽对于外部表,DROP TABLE 仅会删除表的元数据,数据仍然存在于外部⽂件系统中。
- 数据加载:对于内部表,数据可以通过 LOAD DATA 或 INSERT INTO 命令加载,且Hive 会负责将数据直接写⼊表的默认⽂件系统中。⽽对于外部表,数据必须通过外部⽂件系统中的⽂件进⾏加载,并且不能使⽤ INSERT INTO 命令。外部表的创建需要使⽤EXTERNAL关键字。
- 数据更新:对于内部表,可以使⽤ UPDATE 和 DELETE 命令来更新和删除数据。⽽对于外部表,由于数据存储在外部⽂件系统中,⽆法直接更新或删除其中的数据。
总的来说,内部表和外部表在数据存储、管理和更新⽅⾯有很⼤的差别,选择哪种类型的表应根据具体的场景需求⽽定。
内部表
即创建 Hive 内部表时,数据将真实存在于表所在的目录内,删除内部表时,物理数据和文件也一并删除。默认创建的是内部表。Hive 内部表的管理既包含逻辑以及语法上的,也包含实际物理意义
上的。
-- 创建表
CREATE TABLE IF NOT EXISTS test.t_user (
id int,
username string,
password string,
gender string,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
-- 载入数据
LOAD DATA INPATH '/yjx/user/user.txt' INTO TABLE test.t_user;
执行 LOAD DATA 语句后 user.txt 文件将会被移动到 t_user 表所在路径下(/hive/warehouse/test.db/t_user/user.txt )。此时如果使用 DROP 语句删除 t_user 后,其数据和表的元数据都会被删除。
外部表
外部表(external table)则不然,其管理仅仅只是在逻辑和语法意义上的,即新建表仅仅是指向一个外部目录而已。同样,删除时也并不物理删除外部目录,而仅仅是将引用和定义删除。数据的创建和删除完全由自己控制,Hive 不管理这些数据。
方案一:创建时指定数据位置*
数据的位置可以在创建时指定,在 Hive 的数据仓库 /hive/warehouse/test.db 目录下不会创建 t_user 目录。
CREATE EXTERNAL TABLE IF NOT EXISTS test.t_user (
id int,
username string,
password string,
gender string,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
-- 可以指定到某个目录(该目录下的文件都会被扫描到),也可以指定到某个具体的文件
LOCATION '/yjx/user';
提示:如果 /yjx/user 目录不存在 Hive 会帮我们自动创建,我们只需要将 t_user 表所需的数据上传至 /yjx/user 目录即可。或者数据已经存在于 HDFS 某个目录,Hive 创建外部表时直接指定数据位置即可。
方案二:先建表再导入
也可以先单独建立外部表,建立时不指定数据位置,然后通过 LOAD DATA 命令载入数据。
CREATE EXTERNAL TABLE IF NOT EXISTS test.t_user2 (
id int,
username string,
password string,
gender string,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
在这种情况下,Hive 的数据仓库 /hive/warehouse/test.db 目录下会创建 t_user2 目录。
然后通过 LOAD DATA 命令载入数据。
LOAD DATA INPATH '/yjx/user/user.txt' INTO TABLE test.t_user2;
注意:在这种情况下,执行 LOAD DATA 语句后 user.txt 文件将会被移动到 t_user2 表所在路径下(/hive/warehouse/test.db/t_user2/user.txt )。唯一的区别是,外部表此时如果使用 DROP 语句删除t_user2 后,只会删除元数据,也就是说 t_user2 目录和 user.txt 数据并不会被删除。
推荐使用方案一,数据不会被随意移动,更易于团队使用。
导出数据
1通过 SQL 操作
将查询结果导出到本地
首先在 HiveServer2 的节点上创建一个存储导出数据的目录。
mkdir -p /root/user
-- 将查询结果导出到本地
INSERT OVERWRITE LOCAL DIRECTORY '/root/user' SELECT * FROM t_user;
如果需要按指定的格式将数据导出到本地。
-- 按指定的格式将数据导出到本地
INSERT OVERWRITE LOCAL DIRECTORY '/root/person'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n'
SELECT * FROM t_person;
将查询结果输出到 HDFS
首先在 HDFS 上创建一个存储导出数据的目录。
hdfs dfs -mkdir -p /yjx/export/user
-- 将查询结果导出到 HDFS
INSERT OVERWRITE DIRECTORY '/yjx/export/user'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT * FROM t_user;
2通过 HDFS 操作
首先在 HDFS 上创建一个存储导出数据的目录。
hdfs dfs -mkdir -p /yjx/export/person
使用 HDFS 命令拷贝文件到其他目录。
hdfs dfs -cp /hive/warehouse/t_person/* /yjx/export/person
将元数据和数据同时导出
首先在 HDFS 上创建一个存储导出数据的目录。
hdfs dfs -mkdir -p /yjx/export/person
-- 将表结构和数据同时导出
EXPORT TABLE t_person TO '/yjx/export/person';
注意:时间不同步,会导致导入导出失败。
基本查询
内置运算符与函数
-- 查看系统自带函数
SHOW FUNCTIONS;
-- 显示某个函数的用法
DESC FUNCTION UPPER;
-- 详细显示某个函数的用法
DESC FUNCTION EXTENDED UPPER;
sort by、order by、distrbute by、cluster by 的区别
-
(局部排序)SORT BY:和 ORDER BY 类似,⽤于对结果进⾏排序,但是它不保证结果的全局排序,只保证在各个 reducer 中排序。
-
(全局排序)ORDER BY:⽤于对结果集进⾏排序,可以排序⼀个或多个列,并且可以指定升序或降序排列
-
(分区排序)DISTRIBUTE BY:⽤于将数据分发到指定的 reducer,但是不保证每个 reducer中的数据是有序的。如果需要排序再使⽤ ORDER BY 或 SORT BY。
-
(分组排序)CLUSTER BY:⽤于对表按照指定的列进⾏分组并且排序,与 GROUP BY 相似。但是CLUSTER BY 是在 Map 端完成的,可以⼤⼤减少数据在 Reduce 端的交换量,提⾼计算效率。
Hive 高级
分区/分桶
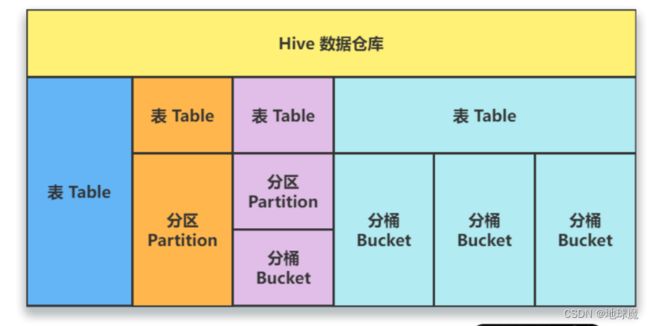
单独的一个表;
对表进行分区;
对表进行分区,再分桶;
对表直接分桶。
分区
使用分区技术,可以避免 Hive 全表扫描,提升查询效率;同时能够减少数据冗余进而提高特定(指定分区)查询分析的效率。
注意,在逻辑上分区表与未分区表没有区别,在物理上分区表会将数据按照分区键的键值存储在表目录的子目录中,目录名为“分区键=键值”。你可以把建立分区想象成建了个文件夹,把一些相似(或者说相同类型)的数据存放到文件夹中。
使用分区表时,尽量利用分区字段进行查询,如果不使用分区字段查询,就会全部扫描,这样就失去了分区的意义。
静态分区
分区表类型分为静态分区和动态分区。区别在于前者是我们手动指定的,后者是通过数据来判断分区的。根据分区的深度又分为单分区与多分区。
创建静态分区表语法(静态分区和动态分区的建表语句是一样的):
-- 单分区:创建分区表 PARTITIONED BY (分区字段名 分区字段类型)
-- 多分区:创建分区表 PARTITIONED BY (分区字段名 分区字段类型, 分区字段名2 分区字段类型2)
CREATE TABLE IF NOT EXISTS t_student (
sno int,
sname string
) PARTITIONED BY (grade int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
注意: PARTITIONED BY () 括号中指定的分区字段名不能和表中的字段名一样。
需要注意的是,分区查询会将分区中所有的数据都查询出来,所以如果文件中的数据本身已经出问题了,那么查询的结果也会出问题
添加分区(也可以在载入数据时添加分区):
ALTER TABLE t_student ADD IF NOT EXISTS PARTITION (grade=1);
查看分区:
SHOW PARTITIONS t_student;
删除分区:
-- ALTER TABLE 表名 DROP PARTITION(分区字段名=键值)
多分区:
-- 单分区:创建分区表 PARTITIONED BY (分区字段名 分区字段类型)
-- 多分区:创建分区表 PARTITIONED BY (分区字段名 分区字段类型, 分区字段名2 分区字段类型2)
CREATE TABLE IF NOT EXISTS t_teacher (
tno int,
tname string
) PARTITIONED BY (grade int, clazz int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
注意:前后两个分区的关系为父子关系,也就是 grade 文件夹下面有多个 clazz 子文件夹
动态分区*
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来判断分区的。详细来说,静态分区的列是在编译时期通过用户传递来决定的;动态分区只有在 SQL 执行时才能决定。
开启动态分区首先要在 Hive 会话中设置以下参数:
-- 开启动态分区支持(默认 true)
SET hive.exec.dynamic.partition=true;
-- 是否允许所有分区都是动态的,strict 要求至少包含一个静态分区列,nonstrict 则无此要求(默认 strict)
SET hive.exec.dynamic.partition.mode=nonstrict;
其余参数的详细配置如下:
-- 每个 Mapper 或 Reducer 可以创建的最大动态分区个数(默认为 100)
-- 比如:源数据中包含了一年的数据,如果按天分区,即 day 字段有 365 个值,那么该参数就需要设置成大于 365,如果
使用默认值 100,则会报错
hive.exec.max.dynamic.partition.pernode=100;
-- 一个动态分区创建可以创建的最大动态分区个数(默认为 1000)
hive.exec.max.dynamic.partitions=1000;
-- 全局可以创建的最大文件个数(默认为 100000)
hive.exec.max.created.files=100000;
-- 当有空分区产生时,是否抛出异常(默认为 false)
hive.error.on.empty.partition=false;
-- 是否开启严格模式 strict(严格模式)和 nostrict(非严格模式,默认)
hive.mapred.mode=nostrict;
严格模式
开启严格模式,主要是为了禁止某些查询(这些查询可能会造成意想不到的坏结果),目前主要禁止三种类型的查询:
分区表查询时,必须在 WHERE 语句后指定分区字段,否则不允许执行。因为在查询分区表时,如果不指定分区查询,会进行全表扫描。而分区表通常有非常大的数据量,全表扫描非常消耗资源。
ORDER BY 查询必须带有 LIMIT 语句,否则不允许执行。因为 ORDER BY 会进行全局排序,这个过程会将处理的结果分配到一个 Reduce 中进行处理,处理时间长且影响性能。
笛卡尔积查询(多使用 JOIN 和 ON 语句查询)。数据量非常大时,笛卡尔积查询会出现不可控的情况,因此严格模式下也不允许执行。
分区表载入数据
-- 从本地载入
LOAD DATA LOCAL INPATH '/root/teacher.txt' INTO TABLE t_teacher_d;
-- 从 HDFS 载入
LOAD DATA INPATH '/yjx/teacher.txt' INTO TABLE t_teacher_d;
-- 通过查询载入
INSERT INTO OVERWRITE TABLE t_teacher_d PARTITION (grade, clazz) SELECT * FROM t_teacher;
分桶
分桶是将数据集分解为更容易管理的若干部分的另一种技术,也就是更为细粒度的数据范围划分,将数据按照字段划分到多个文件中去。
注意:分区针对的是数据的存储路径,分桶针对的是数据文件。
使用分桶表时,尽量利用分桶字段进行查询,如果不使用分桶字段查询,就会全部扫描,这样就失去了分桶的意义。
分桶原理
Hive 采用对列值哈希,然后除以桶的个数求余的方式决定该条记录要存放在哪个桶中。
计算公式: bucket num = hash_function(bucketing_column) mod num_buckets 。
分桶优势
方便抽样:使抽样(Sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
提高 JOIN 查询效率:获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理某些查询的时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side Join)高效的实现。比如 JOIN 操作。对于 JOIN 操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行 JOIN 操作就可以,可以大大较少 JOIN 的数据量。
分桶实践
开启分桶功能首先要在 Hive 会话中设置以下参数:
-- 开启分桶功能,默认为 false
SET hive.enforce.bucketing=true;
-- 设置 Reduce 的个数,默认是 -1,-1 时会通过计算得到 Reduce 个数,一般 Reduce 的数量与表中的 BUCKETS 数量
一致
-- 有些时候环境无法满足时,通常设置为接近可用主机的数量即可
SET mapred.reduce.tasks=-1;
分桶语法:
CREATE TABLE 表名(字段1 类型1,字段2,类型2 )
CLUSTERED BY (表内字段)
SORTED BY (表内字段)
INTO 分桶数 BUCKETS
动态分区和静态分区的区别
静态分区是指增加数据是需要⼿动指定具体的分区⽬录
静态分区的列实在编译时期,通过⽤户传递列名来决定的
静态分区不管有没有数据都将会创建该分区
动态分区增加数据时不⽤⼿动指定分区⽬录,⽽是由系统通过数据来进⾏判断。
动态分区实在SQL执⾏的时候确定的。
动态分区是有结果集将创建分区,否则不创建。
动态分区虽然⽅便快捷,但创建太多分区时可能会占⽤⼤量资源
Hive 的分区分桶
HIve的分区可以分为静态分区和动态分区。静态分区的规则需要⽤户⾃定义,动态分区由系统通过⽤户数据判断。
Hive分桶主要是采⽤对列值哈希,然后除以桶的个数求余的⽅式决定该条记录要存放在哪个桶中。
分区和分桶的区别主要有以下⼏点:
- 分区是按列的值进⾏划分,⽽分桶是按列的哈希值进⾏划分。
- 分区是针对表或分区进⾏划分,⽽分桶是针对表或分区中的某个列进⾏划分。
- 分区可以提⾼查询效率,⽽分桶可以提⾼查询效率和数据均匀性。
分区和分桶可以根据具体的业务需求进⾏选择:
- 如果需要提⾼查询效率,可以使⽤分区或分桶。
- 如果需要提⾼数据均匀性,可以使⽤分桶。
- 如果需要按业务属性进⾏数据管理,可以使⽤分区。
分区和分桶的注意事项:
- 分区和分桶会增加数据存储的成本。
- 分区和分桶会影响数据的插⼊和删除操作。
数据抽样
块抽样(Block Sampling)
使用 TABLESAMPLE(n percent) 函数根据 Hive 表数据的大小按比例抽取数据,并保存到新的 Hive 表中。
-- 该方式允许 Hive 随机抽取 N 行数据,数据总量的百分比(n百分比)或 N 字节的数据
SELECT * FROM TABLESAMPLE(N PERCENT|ByteLengthLiteral|N ROWS) s;
TABLESAMPLE(nM) :指定抽样数据的大小,单位为 M。
TABLESAMPLE(n ROWS) :指定抽样数据的行数,其中 n 代表每个 Map 任务均取 n 行数据,Map 数量可通过 Hive 表的简单查询语句确认(关键词:number of mappers: x)。
TABLESAMPLE(n PERCENT) :按百分比抽样数据,如果数据不超过 128M 还是全量数据。
缺点:不随机。该方法实际上是按照文件中的顺序返回数据,对分区表,从头开始抽取,可能造成只有前面几个分区的数据。
优点:速度快。
分桶抽样 (Smapling Bucketized Table)
Hive 中分桶其实就是根据某一个字段 Hash 取模,放入指定数据的桶中,比如将表 Table_1 按照 ID 分成 100 个桶,其算法是 hash(id) % 100,这样 hash(id) % 100 = 0 的数据会被放到第一个桶中,hash(id) % 100 = 1 的记录被放到第二个桶中。
-- 其中 x 是要抽样的桶编号,桶编号从 1 开始,colname 表示抽样的列,y 表示桶的数量
TABLESAMPLE(BUCKET x OUT OF y [ON colname])
优点 : 随机且速度最快(不走 MR)。
随机抽样(Random() Sampling)
使用 rand() 函数进行随机抽样,Limit 关键字限制抽样返回的数据,其中 RAND() 函数前的 DISTRIBUTE 和 SORT 关键字可以保证数据在 Mapper 和 Reducer 阶段是随机分布的。
-- 使用RAND()函数和LIMIT关键字来获取样例数据,使用DISTRIBUTE和SORT关键字来保证数据随机分散到Mapper和Reducer
-- SORT BY 提供了单个 Reducer 内的排序功能,但不保证整体有序
SELECT * FROM DISTRIBUTE BY RAND() SORT BY RAND() LIMIT ;
-- ORDER BY RAND() 语句可以获得同样的效果,但是性能会有所降低
SELECT * FROM WHERE col=xxx ORDER BY RAND() LIMIT ;
优点:提供真正的随机抽样。
缺点 : 速度慢。
事务
- 不支持 BEGIN、COMMIT、ROLLBACK,所有操作自动提交;
- 事务表仅支持 ORC 文件格式;
- 表参数 transactional 必须为 true;
- 外部表不能成为 ACID 表,不允许从非 ACID 会话读取/写入 ACID 表(例如会话开启了事务,才可以查询事务表,否则查询就会报错);
- 默认事务关闭,需要额外配置
# 开启 hive 并发
SET hive.support.concurrency=true;
# 配置事务管理类
SET hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
# 如果事务表配合分区分桶一起使用建议开启以下参数
# 开启分桶功能
SET hive.enforce.bucketing=true;
# 启用自动压缩
SET hive.compactor.initiator.on=true;
# 这里的压缩线程数必须大于 0,理想状态和分桶数一致
SET hive.compactor.worker.threads=2;
# 是否允许所有分区都是动态的,strict 要求至少包含一个静态分区列,nonstrict 则无此要求(默认 strict)
SET hive.exec.dynamic.partition.mode=nonstrict;
视图/物化视图
视图
视图是一个虚拟的表,只保存定义,不实际存储数据,实际查询的时候改写 SQL 去访问实际的数据表。不同于直接操作数据表,视图是依据 SELECT 语句来创建的,所以操作视图时会根据创建视图的 SELECT 语句生成一张虚拟表,然后在这张虚拟表上做 SQL 操作。
-- 创建视图
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name (<列名1>, <列名2>, ...) AS ;
-- 查看视图
SHOW TABLES;
-- 查看某个视图
DESC view_name;
-- 查看某个视图详细信息
DESC FORMATTED view_name;
-- 修改视图
ALTER VIEW [db_name.]view_name AS ;
-- 删除视图
DROP VIEW [IF EXISTS] [db_name.]view_name [, <视图名2>, ...];
优缺点
总结:
- Hive 中的视图是一种虚拟表,只保存定义,不实际存储数据;
- 通常从真实的物理表查询中创建生成视图,也可以从已经存在的视图上创建新视图;
- 创建视图时,将冻结视图的结构,如果删除或更改基础表,则视图将失败;
- 视图是用来简化操作的,不缓冲记录,也不会提高查询性能。
优点:
- 通过视图可以提高数据的安全性,将真实表中特定的列提供给用户,保护数据隐私;
- 上层的业务查询和底层数据表解耦,业务上可以查的一张表,但是底层可能映射的是三张或多张表的数据;
- 修改底层数据模型只需要重建视图即可,不需要上层业务修改业务逻辑;
- 降低查询复杂度,优化查询语句(注意不是提高查询效率)。
缺点:
- 无法再对视图进行优化,而且并没有提升查询速度,只是使上层的业务逻辑变得更清晰简洁。
物化视图
物化视图(Materialized View),是一个包括查询结果的数据库对象,可以用于预先计算并保存表连接或聚集等耗时较多的操作结果。在执行查询时,就可以避免进行这些耗时的操作,从而快速的得到结果。
物化视图只可以在事务表上创建。
-- 创建物化视图
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db_name.]materialized_view_name
[DISABLE REWRITE]
[COMMENT materialized_view_comment]
[PARTITIONED ON (col_name, ...)]
[CLUSTERED ON (col_name, ...) | DISTRIBUTED ON (col_name, ...) SORTED ON (col_name, ...)]
[
[ROW FORMAT row_format]
[STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
AS
;
-- 物化视图是一种特殊的数据表,可以使用 SHOW TABLES 等语法
-- 删除物化视图
DROP MATERIALIZED VIEW [db_name.]materialized_view_name;
刷新物化视图
增量刷新
当物化视图满足一定条件时,默认会执行增加刷新,即只刷新原始源表中的变动会影响到的数据,增量刷新会减少重建步骤的执行时间。要执行增量刷新,物化视图的创建语句和更新源表的方式都须满足一定条件:
- 物化视图只使用了事务表;
- 如果物化视图中包含 GROUP BY,则该物化视图必须存储在 ACID 表中,因为它需要支持 MERGE 操作。对于由 Scan-Project-Filter-Join 组成的物化视图,不存在该限制。
定时刷新
可以通过 SET hive.materializedview.rewriting.time.window=10min; 设置定期刷新,默认为 0min。该参数也可以作为建表语句的一个属性,在建表时设置。
全量刷新
若只用 INSERT 更新了源表数据,可以对物化视图进行增量刷新。若使用 UPDATE、INSERT 更新了源表数据,那么只能进行重建,即全量刷新(REBUILD)。
当数据源变更(新数据插入 Inserted、数据被修改 Modified),物化视图也需要更新以保持数据一致性,需要用户主动触发 Rebuild
ALTER MATERIALIZED VIEW [db_name.]materialized_view_name REBUILD;
注意:如果一张表创建了许多物化视图,那么在数据写入这张表时,可能会消耗许多机器的资源,比如数据带宽占
满、存储增加等等。
物化视图和视图的什么区别
物化视图和视图都是数据库中的数据对象,但它们的性质和⽤途有所不同:
- 视图是⼀种虚拟表,它并不实际存储数据,⽽是基于⼀个或多个表的查询结果以某种特定⽅式创建的。
- 视图可以⽤来简化复杂的查询,隐藏数据的细节,减少应⽤程序的代码量,提⾼性能等。
- 物化视图(Materialized View)是⼀种实际存储数据的表,它是基于⼀个或多个表的查询结果以某种特定⽅式创建的,与视图不同的是,物化视图存储查询结果,⽽不是每次查询时动态⽣成。具体来说,当创建物化视图时,数据库会执⾏查询操作,并将查询结果存储在⼀个表中。在之后的查询中,数据库可以直接使⽤物化视图中的数据,⽽不需要再次执⾏查询操作,从⽽提⾼查询性能。
总的来说,物化视图和视图的区别在于视图是⼀种虚拟表,不实际存储数据,物化视图是⼀种实际存储数据的表。视图适合处理动态数据集,物化视图适合处理静态数据集,它们应根据具体场景需要选择使⽤。

高级查询
一行变多行(行转列)
EXPLODE() 可以将 Hive 一行中复杂的 Array 或者 Map 结构拆分成多行,配置 SPLIT 函数一起使用可将某个列的数据转为数组。
多行变一行(列转行)
COLLECT_SET() 和 COLLECT_LIST() 可以将多行数据转成一行数据,区别就是 LIST 的元素可重复而 SET 的元素是去重的。
MySQL 实现方式: GROUP_CONCAT([DISTINCT] 要连接的字段 [ORDER BY 排序字段 ASC/DESC] [SEPARATOR‘分隔符’])
URL 解析
侧视图 LATERAL VIEW 配合 PARSE_URL_TUPLE 函数可以实现 URL 字段的一列变多列。
JSON 解析
使用 JSON 函数处理:
GET_JSON_OBJECT(json_txt, path)
第一个参数:指定要解析的 JSON 字符串
第二个参数:指定要返回的字段,通过 $.column_name 的方式来指定
JSON_TUPLE(jsonStr, p1, p2, …, pn)
第一个参数:指定要解析的 JSON 字符串
第二个参数:指定要返回的第 1 个字段
……
使用 JsonSerDe:建表时指定 JSON 序列化器,加载 JSON 文件到表中时会自动解析为对应的表格式
窗口函数
窗口函数可以为窗口中的每行都返回一个值。就是在查询的结果上再多出一列,这一列可以是聚合值,也可以是排序值
窗口函数语法
窗口函数指的就是 OVER() 函数,其窗口是由一个 OVER 子句定义的多行记录。窗口函数一般分为三类:聚合型窗口函数和分析型窗口函数以及取值型窗口函数。
SELECT XX函数() OVER (PARTITION BY 用于分组的列 ORDER BY 用于排序的列 ROWS/RANGE BETWEEN 开始位置 AND 结
束位置);
XX函数() :聚合型窗口函数/分析型窗口函数/取值型窗口函数
OVER() :窗口函数
PARTITION BY :后跟分组的字段,划分的范围被称为窗口
ORDER BY :决定窗口范围内数据的排序方式,当 ORDER BY 与聚合函数一起使用时,会形成顺序聚合,如 SUM 聚合与 ORDER BY 结合使用时,就实现类似于累计和的效果。
移动窗口 :
移动方向:
CURRENT ROW :当前行
PRECENDING :向当前行之前移动
FOLLOWING :向当前行之后移动
UNBOUNDED :起点或终点(一般结合 PRECEDING,FOLLOWING 使用)
UNBOUNDED PRECEDING :表示该窗口第一行(起点)
UNBOUNDED FOLLOWING :表示该窗口最后一行(终点)
移动范围: ROWS 和 RANGE
与 GROUP BY 的区别:
结果数据形式
窗口函数可以在保留原表中的全部数据
GROUP BY 只能保留与分组字段聚合的结果
排序范围不同
窗口函数中的 ORDER BY 只是决定着窗口里的数据的排序方式
普通的 ORDER BY 决定查询出的数据以什么样的方式整体排序
SQL 顺序
GROUP BY 先进行计算
窗口函数在 GROUP BY 后进行计算
移动窗口(滑动窗口)
移动方向:
CURRENT ROW :当前行
PRECENDING :向当前行之前移动
FOLLOWING :向当前行之后移动
UNBOUNDED :起点或终点(一般结合 PRECEDING,FOLLOWING 使用)
UNBOUNDED PRECEDING :表示该窗口第一行(起点)
UNBOUNDED FOLLOWING :表示该窗口最后一行(终点)
移动范围:
ROWS :ROWS 后定义窗口从哪里开始(当前行也参与计算),与 BETWEEN 搭配可以表示范围。如果省略 BETWEEN仅指定一个端点,那么将该端点视为起点,终点默认为当前行。ROWS 会根据 ORDER BY 子句排序后,按分组后排序列的顺序取前 N 行或后 N 行进行计算(当前行也参与计算)。
ROWS 2 PRECEDING :窗口从当前行的前两行开始计算,计算到当前行;
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW :等同于上一句;
ROWS BETWEEN CURRENT ROW AND 2 FOLLOWING :窗口从当前行开始计算,计算到当前行的后两行;
ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING :窗口从当前行的前两行开始计算,计算到当前行的下一
行,当前行也参与计算;
ROWS UNBOUNDED PRECEDING :窗口从第一行(起点)计算到当前行;
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW :等同于上一句;
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING :窗口从当前行计算到最后一行(终点);
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING :窗口从第一行(起点)计算到当前行下一行;
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING :窗口从第一行(起点)计算到最后一行(终点)。
RANGE :RANGE 后定义窗口从哪里开始(当前行也参与计算),与 BETWEEN 搭配可以表示范围。如果省略
BETWEEN 仅指定一个端点,那么将该端点视为起点,终点默认为当前行。RANGE 会根据 ORDER BY 子句排序后,按分组后排序列的值的整数区间取前 N 行或后 N 行进行计算(相同排序值的行都会被算进来,当前行也参与计算)。
RANGE 的窗口范围子句语法与 ROWS 一模一样,唯一的区别就在于 RANGE 会根据 ORDER BY 子句排序后,按分组后排序列的值的整数区间取前 N 行或后 N 行进行计算(相同排序值的行都会被算进来,当前行也参与计算)。
整数区间解释:如果窗口范围子句为 RANGE BETWEEN 2 PRECEDING AND CURRENT ROW ,假设排序列的值为
1 2 3 4 5 7 8 11,计算规则如下:
1 => 1,因为前面没有任何行,所以只有自己
2 => 1 + 2,因为前面只有一行,所以只加了 1
3 => 1 + 2 + 3,前面两行加当前行
4 => 2 + 3 + 4,前面两行加当前行
5 => 3 + 4 + 5,前面两行加当前行
7 => 5 + 6 + 7,因为 6 不存在,所以实际上只加了 5
8 => 6 + 7 + 8,因为 6 不存在,所以实际上只加了 7
11 => 9 + 10 + 11,因为 9 和 10 都不存在,所以实际上只有自己
当 ORDER BY 缺少窗口范围子句时,窗口范围子句默认为: RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 。
当 ORDER BY 和窗口范围子句都缺失时,窗口范围子句默认为: ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 。
分析型窗口函数
RANK() :间断,相同值同序号,例如 1、2、2、2、5。
DENSE_RANK() :不间断,相同值同序号,例如 1、2、2、2、3。
ROW_NUMBER() :不间断,序号不重复,例如 1、2、3、4、5(2、3 可能是相同的值)。
PERCENT_RANK() :计算小于当前行的值在所有行中的占比:小于 x 的行数 / 窗口或 PARTITION 分区内的总行数。其中 x 等于 ORDER BY 子句中指定的列的当前行中的值。
CUME_DIST() :计算小于等于当前行的值在所有行中的占比。
NTILE(N) :如果把数据按行数分为 N 份,那么该行所属的份数是第几份。注意:N 必须为 INT 类型。
取值型窗口函数
LAG(COL, N, DEFAULT_VAL) :往前第 N 行数据,没有数据的话用 DEFAULT_VAL 代替。
LEAD(COL, N, DEFAULT_VAL) :往后第 N 行数据,没有数据的话用 DEFAULT_VAL 代替。
FIRST_VALUE(EXPR) :分组内第一个值,但是不是真正意义上的第一个,而是截至到当前行的第一个。
LAST_VALUE(EXPR) :分组内最后一个值,但是不是真正意义上的最后一个,而是截至到当前行的最后一个。
自定义函数
UDF(普通函数,⼀进⼀出,可以⽤于字符串处理、⽇期处理)
实现 UDF 的方式有两种:
第一种是比较简单的形式,继承 UDF 类通过 evaluate 方法实现,目前已过时。
第二种是继承 GenericUDF 重写 initialize 方法、evaluate 方法、getDisplayString 方法实现。
UDAF(聚合函数,多进⼀出,可以⽤于求平均值、求最⼤值、求最⼩值等场景)
实现 UDAF 的方式有两种:
第一种是比较简单的形式,先继承 UDAF 类,然后使用静态内部类实现 UDAFEvaluator 接口,目前已过时。
第二种是先继承 AbstractGenericUDAFResolver 类重写 getEvaluator 方法,然后使用静态内部类实现
GenericUDAFEvaluator 接口。
UDTF(表⽣成函数,⼀进多出,⽤于数据拆分、数据过滤等场景 )
实现 UDTF 需要继承的 GenericUDTF,然后重写⽗类的三个抽象⽅法( initialize , process ,close ),输出后有⼏列,在 initialize 中定义,主要处理逻 辑在 process 中实现。
将自定义 UDTF 程序打成 jar 包并上传至 HDFS。
在 Hive 中定义自定义函数。
重新加载函数。
Hive自定义函数的作用是为了解决系统内置函数无法满足实际业务需求的问题,开发者可以根据自身的业务需求编写函数来实现个性化的功能。
Hive 压缩/存储
压缩技术能够有效减少存储系统的读写字节数,提高网络带宽和磁盘空间的效率。
注意:压缩特性运用得当能提高性能,但运用不当也可能降低性能。
压缩的优点:减少存储系统读写字节数、提高网络带宽和磁盘空间的效率。
压缩的缺点:使用数据时需要先对文件解压,加重 CPU 负载,压缩算法越复杂,解压时间越长。
压缩的条件:空间和 CPU 要充裕。如果机器 CPU 比较紧张,慎用压缩。
压缩的技术:
有损压缩(LOSSY COMPRESSION):压缩和解压的过程中数据有丢失,使用场景:视频。
无损压缩(LOSSLESS COMPRESSION):压缩和解压的过程中数据没有丢失,使用场景:日志数据。
对称和非对称:
对称:压缩和解压的时间一致。
非对称:压缩和解压的时间不一致。
计算密集型(CPU-Intensive)作业,少用压缩。
IO 密集型(IO-Intensive)作业,多用压缩。
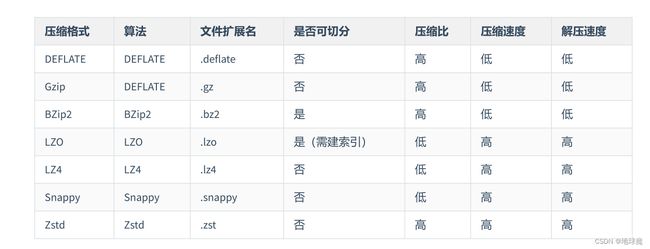
Hive 压缩
Mapper 压缩
# 开启 Hive 中间传输数据压缩功能
SET hive.exec.compress.intermediate=true
在 Hive 客户端通过命令的方式开启 Mapper 端压缩。
# 开启 Mapper 输出压缩
SET mapreduce.map.output.compress=true;
# 设置 Mapper 输出压缩的压缩方式
SET mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
Reducer 压缩
在 Hive 客户端通过命令的方式启用压缩。
# 开启 Hive 最终结果数据压缩功能
SET hive.exec.compress.output=true;
在 Hive 客户端通过命令的方式开启 Reducer 压缩。
SET hive.exec.compress.output=true;
# 开启 Reducer 输出压缩
SET mapreduce.output.fileoutputformat.compress=true;
# 设置 Reducer 输出压缩的压缩方式
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec;
# SequenceFiles 输出可以使用的压缩类型:NONE、RECORD 或者 BLOCK
# 如果作业输出被压缩为 SequenceFiles,该属性用来控制使用的压缩格式。默认为 RECORD,即针对每条记录进行压缩,如果将其改为 BLOCK,将针对一组记录进行压缩,这是推荐的压缩策略,因为它的压缩效率更高。
SET mapreduce.output.fileoutputformat.compress.type=BLOCK;
存储
当今的数据处理大致可分为两大类:OLTP 和 OLAP

OLTP 事务处理
LTP 联机事务处理(On-Line Transaction Processing):OLTP 是传统关系型数据库的主要应用,来执行一些基本的、日常的事务处理,比如数据库记录的增、删、查、改等。
数据计算和数据存储分开,所有用户发过来的请求都是一个事件 Event,事件处理从关系型数据库中查询并进行返回。特点实时性很好,来一个事件处理一个事件,额外数据存储在关系型数据库中。最大问题是能够同时处理的数据有限,数据库做连表查询的代价很高。
OLAP 分析处理
OLAP 联机分析处理(On-Line Analytical Processing):OLAP 则是分布式数据库的主要应用,它对实时性要求不高,但处理的数据量大通常应用于复杂的动态报表系统上。
一般 OLTP 都是使用行式存储,因为实时性要求高,而且有大量的更新操作;OLAP 都是使用列式存储,因为实时性要求不高,主要是要求性能好。
行式存储(Row-oriented)
- 查询满足条件的一整行数据的时,只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
- 传统的关系型数据库,如 Oracle、DB2、MySQL、SQL SERVER 等都是采用行式存储,在基于行式存储的数据库中,数据是按照行数据为基础逻辑存储单元进行存储的,一行中的数据在存储介质中以连续存储形式存在。
- Text File 和 Sequence File 的存储格式都是基于行存储的。
- 这种存储格式比较方便进行 INSERT/UPDATE 操作,不足之处就是如果查询只涉及某几个列,它会把整行数据都读取出来,不能跳过不必要的列读取。当然数据比较少,一般没啥问题,如果数据量比较大就比较影响性能,还有就是由于每一行中,列的数据类型不一致,导致不容易获得一个极高的压缩比,也就是空间利用率不高。
列式存储(Column-oriented)
与行存(将每一行的数据连续存储)不同,列存将每一列的数据连续存储。
- 在行存模式下,数据按行连续存储,所有列的数据都存储在一个 Block 中,不参与计算的列在 IO 时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了 IO Cost,加速了查询。
- 同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
- 更高的压缩比意味着更小的 Data Size,从磁盘中读取相应数据耗时更短。
- 自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
- 高压缩比意味着同等大小的内存能够存放更多数据,系统 Cache 效果更好。官方数据显示,通过使用列存,在某些分析场景下,能够获得 100 倍甚至更高的加速效应。
- INSERT/UPDATE 很麻烦或者不方便,不适合扫描小量的数据。
- 列式存储相对于行式存储来说,是新兴的 HBase、HPVertica、EMCGreenplum、ClickHouse 等分布式数据库均采用的存储方式。在基于列式存储的数据库中, 数据是按照列为基础逻辑存储单元进行存储的,一列中的数据在存储介质中以连续存储形式存在。
存储格式
- ORC 文件格式压缩比 Parquet 要高,Parquet 文件的数据格式
- Schema 要比 ORC 复杂,占用的空间也就越高。
- ORC 文件格式的读取效率要比 Parquet 文件格式高。
- 如果数据中有嵌套结构的数据,则 Parquet 会更好。
- Hive 对 ORC 的支持更好,对 Parquet 支持不好,ORC 与 Hive 关联紧密。
- ORC 还可以支持 ACID、Update 操作等。
- Spark 对 Parquet 支持较好,对 ORC 支持不好。
- 为了数据能够兼容更多的查询引擎,Parquet 也是一种较好的选择。
表的文件存储格式尽量采用 Parquet 或 ORC,不仅降低存储量,还优化了查询,压缩,表关联等性能。
Hive 优化
EXPLAIN 执行计划
EXPLAIN 会将 HQL 语句的依赖关系、实现步骤、实现过程进行解析返回,有助于我们了解 HQL 语句在底层是如何实现数据的查询与处理的,辅助我们对 Hive 进行优化。
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
- EXTENDED:提供一些额外信息。通常是像文件名这样的物理信息。
- CBO:输出由 Calcite 优化器生成的计划。CBO(Cost Based Optimizer 对查询进行动态评估、获取最佳物理计划) 。
- AST:输出查询的抽象语法树。AST 在 Hive 2.1.0 版本删除了,存在 Bug,转储 AST 可能会导致 OOM 错误,将在 4.0.0版本修复。
- DEPENDENCY:以 JSON 格式返回查询所依赖的表和分区信息。
- AUTHORIZATION:显示执行查询需要授权的条目。
- LOCKS:这对于了解系统将获得哪些锁很有用。LOCKS 从 Hive 3.2.0 开始支持。
- VECTORIZATION:显示是否启用了向量化查询,以及为什么没有启用的原因。
- ANALYZE:用实际的行数注释计划。从 Hive 2.2.0 开始支持。
- query:Hive SQL 语句。
查询计划由以下几个部分组成:
- The Abstract Syntax Tree for the query:抽象语法树
- The dependencies between the different stages of the plan:计划不同阶段之间的依赖关系
- The description of each of the stages:阶段描述
SQL 优化
RBO 优化
Rule-Based Optimization,简称 RBO:基于规则优化的优化器,是一种经验式、启发式的优化思路,优化规则都已经预先定义好了,只需要将 SQL 往这些规则上套即可。
谓词下推
谓词下推(Predicate Pushdown)基本思想:将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。在文件格式使用 Parquet 或 ORC 时,甚至可能整块跳过不相关的文件。
而 Hive 中的谓词下推主要思想是把过滤条件下推到 Map 端,提前执行过滤,以减少 Map 到 Reduce 的传输数据,提升整体性能。简而言之,就是在不影响结果的情况下,尽量将过滤条件提前执行。
Hive 会自动帮助我们优化 SQL 实现谓词下推,但是当 SQL 很复杂的时候可能会导致谓词下推失效。
列裁剪
列裁剪(Column Pruning)也叫投影下推,表示扫描数据源的时候,只读取那些与查询相关的字段。
常量折叠
常量折叠(Constant Folding)也叫表达式折叠,表示将表达式提前计算出结果,然后使用结果对表达式进行替换。
CBO 优化
CBO(Cost-Based Optimization)意为基于代价优化的策略,它需要计算所有可能执行计划的代价,并挑选出代价最小的执行计划。
要使用基于成本的优化,需要在查询开始时设置以下参数:
# 开启 CBO 优化,默认为 true
SET hive.cbo.enable=true;
# 统计 SQL 的查询结果是否从统计信息中获取,默认为 true
SET hive.compute.query.using.stats=true;
# 是否统计列信息,默认为 false
SET hive.stats.fetch.column.stats=true;
# 是否统计分区信息,默认为 true。3.1.1 版本被废弃,不允许用户修改该属性,因为禁用分区状态的获取可能会导致分区
表出现问题
SET hive.stats.fetch.partition.stats=true;
然后统计表的相关信息才能使用 CBO 优化:
新创建的表或者分区,插入数据时是否统计其信息,默认为 true
# 新创建的表或者分区,如果通过 INSERT OVERWRITE 的方式插入数据,那么 Hive 会自动将该表或分区的统计信息更新到
元数据
SET hive.stats.autogather=true;
# 对于已经存在表或分区可以通过 ANALYZE 命令手动更新其 Statistics 信息
# 统计全表的所有分区的信息
ANALYZE TABLE 表名 COMPUTE STATISTICS;
# 只统计文件数和文件大小,不扫描文件行数,执行较快
ANALYZE TABLE 表名 COMPUTE STATISTICS NOSCAN;
# 统计指定字段的信息
ANALYZE TABLE 表名 COMPUTE STATISTICS FOR COLUMNS 列名1,列名2,列名n;
# 统计指定分区的信息
ANALYZE TABLE 表名 PARTITION(分区列1=值1, 分区列2=值2) COMPUTE STATISTICS;
对于非分区表列的 Statics 信息存在 Hive 元数据表 TABLE_COL_STATS 中;
对于分区表列的 Statics 信息存在 Hive 元数据表 PART_COL_STATS 中。
JOIN 优化
而 Hive JOIN 的底层是通过 MapReduce 来实现的,Hive 实现 JOIN 时,为了提高 MapReduce 的性能,提供了多种 JOIN 方案:
-
小表 JOIN 大表的 Map Join
-
大表 JOIN 大表的 Reduce Join,Reduce Join 又分为以下两种:
Bucket Map Join(中型表和大表 JOIN)
Sort Merge Bucket Join(大表和大表 JOIN)
Map Join
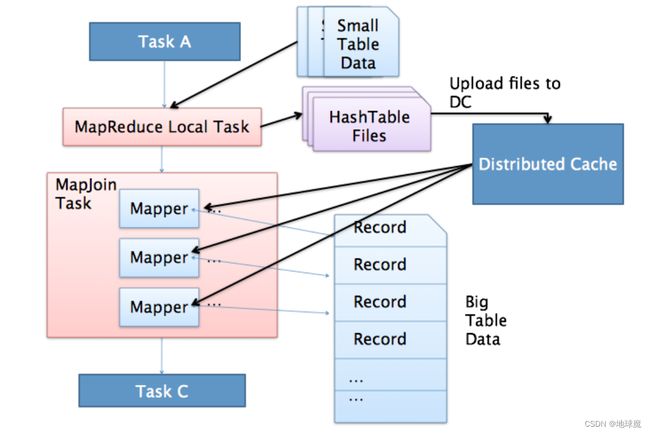
Map Join 顾名思义,就是在 Map 阶段进行表之间的连接。而不需要进入到 Reduce 阶段才进行连接。这样就节省了在 Shuffle 阶段时要进行的大量数据传输。
Map Join 简单说就是在 Map 阶段将小表读入内存,顺序扫描大表完成 Join。
Reduce Join
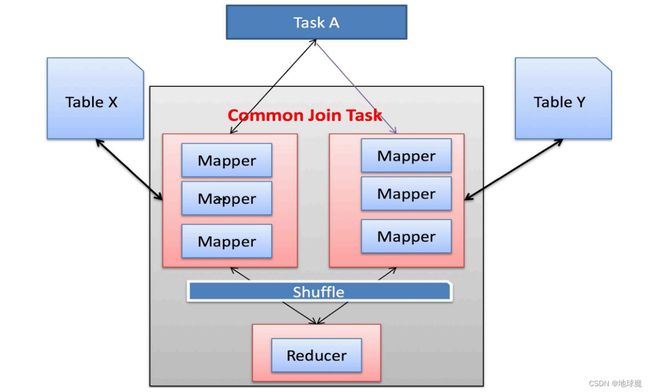
Map 端的主要工作:为来自不同表或文件的数据,进行打标签以区别不同来源的记录。然后用 JOIN 字段作为 Key,其余部分数据和新加的标志作为 Value,最后进行输出。
Reduce 端的主要工作:在 Reduce 端以 JOIN 字段作为 Key 完成分组,接下来只需要在每一个分组中,将那些来源于不同 Map 端的文件的记录进行合并即可。
应用场景:大表(相较于 Map Join 小表的数据更大) JOIN 大表。
实现原理:将两张表的数据在 Shuffle 阶段利用 Shuffle 的分组将数据按照 JOIN 字段进行合并。
具体使用:Hive 会自动判断是否满足 Map Join,如果不满足 Map Join,则会自动执行 Reduce Join。
Bucket Map Join6
两个 JOIN 表都在 Join Key 上都做 Hash Bucket,并且把你打算复制的那个(相对)小表的 Bucket 数设置为大表的倍数。这样数据就会按照 Key Join 做 Hash Bucket。小表依然复制到所有节点,Map Join 的时候,小表的每一组 Bucket 加载成HashTable,与对应的一个大表 Bucket 做局部 JOIN。
更大的表对更大的表
- 将两张大表的数据构建分桶
- 数据按照分桶的规则拆分到不同的文件中
分桶规则 = MapReduce 分区的规则 = Key 的 Hash 取余
Key = 分桶的字段 - 只需要实现桶与桶的 JOIN 即可,减少了比较次数
分桶本质:底层 MapReduce 的分区,桶的个数 = Reduce 个数 = 文件个数。
Map Join 条件:
SET hive.optimize.bucketmapjoin=true; ,默认为 false
所有要 JOIN 的表必须分桶,如果表不是 Bucket 的,则只是做普通 JOIN
大表的 Bucket 数是小表的 Bucket 数的整数倍(或相等)
Bucket 列 == JOIN 列
必须是应用在 Map Join 的场景中
SMB Join
SMB Join 是基于 Bucket Map Join 的有序 Bucket,可实现在 Map 端完成 JOIN 操作,只要桶内的下一条不是,就不用再比较了,有效地减少或避免 Shuffle 的数据量。
SET hive.optimize.bucketmapjoin=true;
SET hive.optimize.bucketmapjoin.sortedmerge=true;
SET hive.auto.convert.sortmerge.join=true;
所有要 JOIN 的表必须分桶,如果表不是 Bucket 的,则只是做普通 JOIN
大表的 Bucket 数 = 大表的 Bucket 数
Bucket 列 == JOIN 列 == SORT 列
必须是应用在 Bucket Map Join 的场景中
数据倾斜
⾸先数据倾斜(Data Skew)是指在分布式系统中,不同的数据分区或计算任务之间存在数据量或计算处理时间的严重不均衡情况。
原因
任务读取大文件,最常见的就是读取压缩的不可分割的大文件。
任务需要处理大量相同键的数据。
- 单表聚合操作,部分 Key 数据量较大,且大 Key 分布在很多不同的切片。
- 两表进行 JOIN,都含有大量相同的倾斜数据键。
- 分组列的数据含有大量无意义的数据,例如空值(NULL)、空字符串等。
- 含有倾斜数据在进行聚合计算时无法聚合中间结果,大量数据都需要经过 Shuffle 阶段的处理,引起数据倾斜。
- 数据在计算时做多维数据集合,导致维度膨胀引起的数据倾斜。
压缩引发的数据倾斜
单表聚合数据倾斜
JOIN 数据倾斜
业务无关数据引发的数据倾斜
无法消减中间结果的数据量引发的数据倾斜
多维聚合计算数据膨胀引起的数据倾斜