Java之内存管理
write:2022-5-25
视频学习笔记,视频来源:B站——寒食君。
文章目录
- JVM内存管理
- 1. 程序计数器
- 2. 虚拟机栈
-
- 2.1 虚拟机栈概念
- 2.2 栈帧
- 3. 本地方法栈
- 4. 方法区
-
- 4.1 方法区概念
- 4.2 方法区存储
- 4.3 常量池
- 4.4 运行时常量池
- 4.5 方法区的垃圾回收
- 5. 堆
JVM内存管理
java能够发展到如今,很大程度上取决于JVM(Java虚拟机),而内存管理又是虚拟机中的一个重要命题。JVM如何对内存进行管理的,JVM首先需要对内存进行抽象和分区,接下来讲讲各个内存区域划分原因和自身的作用;
注意:不要混淆Java内存分区和Java内存模型
从逻辑上可将JVM内存分为5个部分,分为被所有线程共享的内存区域和仅被当前线程独占的内存区域,其中线程共享的内存区域包括堆和方法区,线程独占的内存区域包括虚拟机栈,本地方法栈,程序计数器;
也就是说,当你在写程序时,需要判断当前数据读写的是存在于哪类内存区域,如果存在的是线程共享的内存区域,那么就要考虑是否存在线程安全问题,如果存在线程独占的内存区域,那么久可以打消这种顾虑;
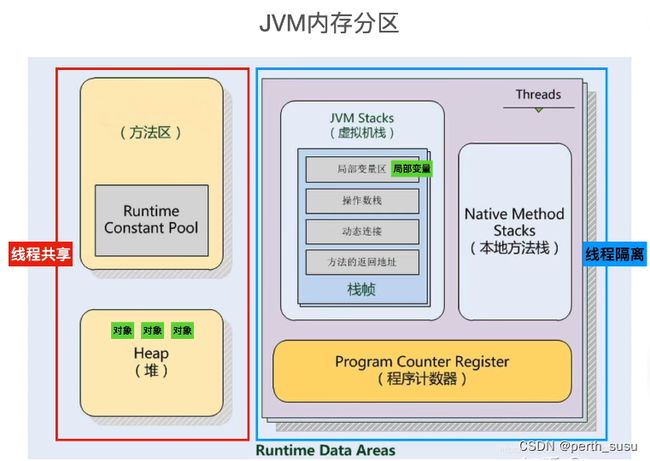
接下来,我们先看线程独占的内存区域!!!
1. 程序计数器
在计算机组成硬件层面,程序计数器是一种寄存器,他用来存储指令地址提供给处理器执行;
在JVM这种软件层面,程序计数器也是一样的作用,它用来存储字节码的指令地址,提供给执行引擎去执行;
可以这么认为,这两种程序计数器分别存在于硬件与软件中,实现方式不—样,但是设计思想类似,明白了JVM中程序计数器是做什么的,那么在程序运行时,能不能监控到程序计数器的值,答案是不能,因为虚拟机没有向外暴露查询程序计数器的接口,但是我们可以从侧面的角度去进行观察,写一个简单的demo:

通过javap反编译class之后,得到可读性比较好的字节码

可以看到第一列的数字,代表了字节码指令之间的偏移量,叫做bytecode index,这其实的就是程序计数器所需要读取的数据,看到这边bytecode index为11的这行,指令为goto,操作数为2,代表了回到index为2的那行指令,这里的就体现出了源码中的循环逻辑,也体现出了程序计数器的工作方式。
2. 虚拟机栈
2.1 虚拟机栈概念
虚拟机栈这个名字乍一听可能让人觉得有点难以理解,在这里换一个称呼,叫做Java方法栈,对应着,后面需要介绍的本地方法栈,那什么是Java方法栈呢?
大家应该知道,程序执行的过程对应方法的调用,而方法的调用,实际上对应着栈帧的入栈出栈,比如我们写这样一段代码:

运行时,程序会先调用A方法,那么将A方法封装成"栈帧”入栈,由于A方法中调用了B,那么B方法封装成"栈帧”入栈,

然后,先执行B中的逻辑,等于B栈帧出栈,然后执行A方法,等于A栈帧出栈

以前写递归的时候稍不留神将会出现栈溢出的异常情况,原因那就是没有编写适当的递归退出条件导致无限量的栈帧入栈,超出了方法栈的最大深度,所以就抛出了StackOverFlow的异常,这里有三点需要注意:
(1)栈帧:后面详讲,目前可以简单地将其当作方法调用的一种封装
(2)栈帧的生成时机
在编译期间,无法确定Java方法栈的深度,因为栈帧的生成是根据程序运行时的实际情况来决定的,这是动态的,比如你写了藏有StackOverFlow的递归代码,编译器是无法检查出这种异常的
(3)栈帧的构成
在编译期间由于每一个方法的源码都是确定的,而栈帧是根据方法调用来产生的,那么可以猜想,栈帧内部一些元素是可以确定的,比如说有多少个局部变量,存储局部变量所需要的空间等,而有一些元素的是无法确定的,比如说该方法与其他方法之间的动态连接,后面详讲
因此,接下来重点学习栈帧:
2.2 栈帧
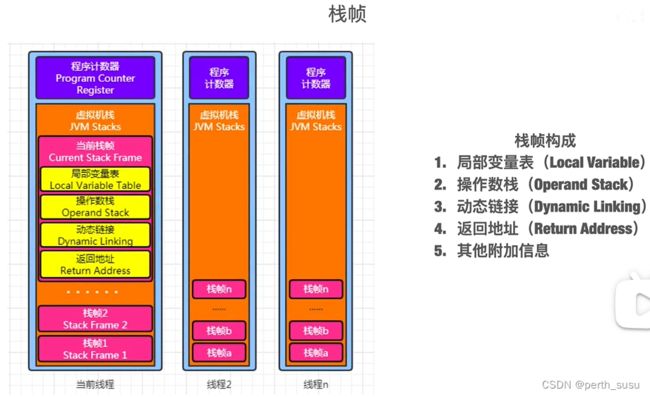
栈帧中主要存在四种结构:
(1)局部变量表
完整的局部变量表概念:
1。主要存储方法的参数、定义在方法内的局部变量,包括基本数据类型(8大),对象的引用地址,返回值地址。
2。局部变量表中存储的基本单元为变量槽(Slot),32位(4字节)以内的数据类型占一个slot,64位(long,double)的占两个slot。
3。局部变量表是一个数字数组,byte、short、char都会被转化为int,boolean类型也会被转化为int,0代表false、非0代表true。
4。局部变量表的大小是在编译期间决定下来的,所以在运行时它的大小是不会变的。
5.局部变量表中含有直接或者间接指向的引用类型变量时,不会被垃圾回收处理。
理解其中要点:栈帧是通过方法源码来生成的,当调用该方法时呢,传入方法的参数类型,局部变量的类型,这些在源码中都是已经确定的,既然数量与类型能够确定,那么需要占用的存储空间就已经确定。但是怎么进行存储呢?在局部变量表中通过4字节的变量槽(Slot)来进行存储。
写一个例子:

在LocallVariableTable这一栏中,可以看到局部变量表,其中参数args占用了index为0的slot并且声明了签名为String,剩下的三个局部变量abc,分别占用其余三个slot,签名都是int;
(2)操作数栈
在操作系统层面的操作数是计算机指令的一部分;而这里操作数栈是在JVM层面的,作用是相似的,顾名思义,这里操作数栈就是一个用来存储操作数的栈,这里的操作数大部分就是方法内的变量;
那为什么需要使用操作数栈来对操作数(变量)进行入栈出栈操作,主要由两个作用:
第一点:存储操作数;(这里的操作数是变量以及中间结果)
第二点:操作数能够方便指令顺序读取操作数;虚拟机的执行引擎在执行字节码指令的时候呢,会通过当前指令类型从操作数栈中,取出栈顶的操作数进行计算,然后再将计算结果入栈继续执行后续的指令;
写一个例子:
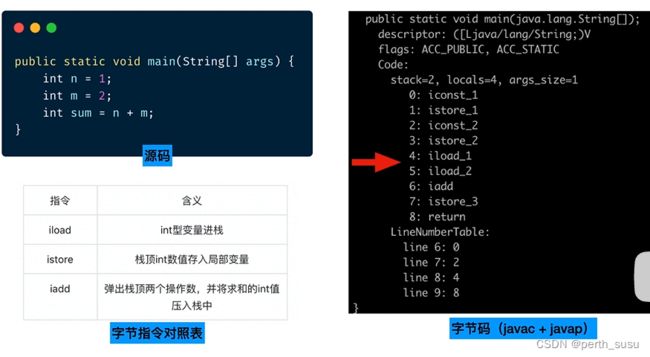
可以看到bytecode index为4和5的这两行对应的字节码指令是iload,iload就是将int类型的操作数压栈,所以4和5两行,其实就是将m和n两个变量压栈,接着是iadd这个指令,它是取出栈顶的两个操作数,进行求和计算并将计算结果压入栈中,接着就是istore这个指令,它就是将栈顶的操作数存入局部变量表;
关于操作数栈,其实还隐藏着另外—个小问题:上面演示的例子中只有一个栈帧,如果虚拟机中存在多个栈帧,可以想象,先执行完的方法的返回值,需要被当做后执行方法的变量,看个例子:
在运行时,虚拟机中出现两个栈帧A和B,首先执行栈帧B,n和m将会作为两个操作数入栈,通过求和字节码指令计算结果并将计算结果存入局部变量表,那这个中间结果又将会成为栈帧A的操作数,所以,需要再从栈帧B的局部变量表中将该值复制进入栈帧A的操作数栈,这样做当然可以,

但是JVM做了一些优化,看下图:在JVM的实现中,将两个栈帧的一部分重叠,让下面栈帧的操作数栈和上面栈帧的部分局部变量表重叠在一起,这样在进行方法调用时可以共享一部分数据,无需进行额外的参数复制传递,这算是一个优化的细节:

(3)动态链接
OOP的主要特性之一就是多态,而Java中的多态就是就是通过栈帧中的动态链接来实现的;
先看一句话概念:每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态链接(Dynamic Linking)。下面来理解一下这句话:Java在类加载过程中有一个步骤叫做“连接”,在这个步骤中,JVM将会将class对象(存储在方法区的运行时常量池中)中部分符号引用替换为直接引用,为什么是部分呢,因为对于有些方法JVM不能够判断这些方法所在的具体类型,所以就可以放心大胆的对方法进行连接,这叫做静态解析,而对于有些方法因为多态的存在,JVM无法在类加载阶段就确定被调用的具体类型,只能在运行时真正产生调用的时候,根据实际的类型信息来进行连接,这就叫做动态连接。
看一个例子:

由于B为抽象类,所以在类A的加载阶段无法确定B的具体实现类,在运行时呢,当方法A中调用方法B时,首先需要查询栈帧B在运行时常量池中的符号引用,然后根据当前具体的类型信息进行动态链接;
(4)返回地址
这一块了解就好;只有出现以下两种情况,当前方法就会返回;
第一种:方法正常,执行完成,所以返回;
第二种:方法执行期间遇到异常情况返回;
3. 本地方法栈
先来讲讲Java方法栈和本地方法栈的区别:本地方法栈Native Method Statck,非java语言实现的函数,往往是由C/C++编写的,和操作系统相关性比较强的底层函数;其实本地方法栈就是用来支持本地方法调用逻辑的;
接下来,我们再看线程共享的内存区域!!!
4. 方法区
4.1 方法区概念
方法区是虚拟机规范中的抽象概念。什么是虚拟机规范,换句话说,无论你用的虚拟机是HotSpot还是JRockit等等,他们的具体实现中,必须需要存在方法区这个结构,但具体的实现可以灵活发挥,打个比方,规范就好比建造一所房子的图纸,其中规定了一定要有书房这个房间,建造商拿到图纸以后,需要在限定的条件下去设计这个房间,如何进行设计建造,这就是具体的实现方式。
再看目前最主流的HotSpot虚拟机,在JDK8以前呢,HotSpot的开发者将面向堆的分代设计复用在了方法区上,他们使用“永久代”来作为HotSpot上的方法区的实现,但是后来发现这种设计并不好,所以从JDK8开始借鉴了一些JRockit的设计思路,使用了元空间来代替“永久代”作为新的实现方式,**总结来说,“方法区”是抽象,“永久代”和“元空间”是实现。**很多人背八股文的时候喜欢说:JDK8以后元空间代替了方法区,这种说法是错误的,而且显得很不专业。
图解:


那么为什么要用元空间这种本地内存的方法来代替“永久代”呢,使用“永久代”实现方法区的两个主要缺点:
- 可能引起内存溢出;(“永久代”的大小设置为多少,可以通过启动数来指定,但其中存储的数据大小是动态变化的着,阈值设置的太小则可能导致频繁的类卸载或者说内存溢出问题设置的太大有可能会存在空间浪费,所以将会由此出现一些调优问题)
- 永久代本身的复杂设计并不是方法区需要的,并可能带来未知异常(“永久代”本身是面向堆来设计的。所以存储在“永久代”内的对象不是内存连续的,需要通过额外的存诸信息以及实现额外的对象查找机制来定位对象所以比较麻烦。虚拟机设计团队之所以一开始会使用永久在这种方式来实现方法区是为了进行—定程度的代码复用,但是后来发现存在一些问题,以上两个缺点,对于方法区说并不是不可回避的,所以目前使用基于直接内存的元空间来代替“永久代”就不会有这些问题。)
理清了概念,下面来看看方法区内到底存储了一些什么东西。
4.2 方法区存储
把Java源文件编译成Java类文件的Java编译器是javac.exe ,类加载的第一个阶段叫做“加载”,在这个阶段内,虚拟机将会读取被编译的Class文件生成Class对象,Class对象存储了一些类型信息,这些信息就是存储在方法区内的,这里所说的类型信息大家猜—猜的话也应该都知道是,诸如像“类的签名”,“属性”,“方法”,既然类型信息是从class文件读取的,那我们就写个demo编译成字节码之后,来看看其中具体有哪些类型信息;
demo:源码
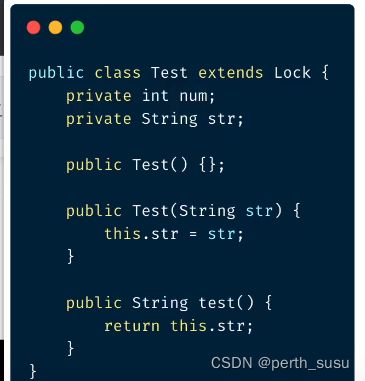
通过javap反编译class之后,可以得到可读性比较好的字节码,字节码中展示了当前类的全限定名以及父类或者接口的全限定名

Test类中有两个属性:int num和String str,这部分呢我们可以看到,在字节码中几乎没有什么理解歧义。已经表达得很清楚了

Test类中还有三个方法,分别是无参构造方法,含参构造方法,以及一个自定义函数。这—块的字节码其实更多体现的是虚拟机栈的相关内容,因为方法调用直接和虚拟机栈有关,可以回顾上面写的虚拟机栈,

这里有一个细节,我们看到bytecode index为1的这行字节码,调用了invokespecial指令,可以看得出来这里的意图是首先调处类的构造方法,这就验证了大家熟知的”子类在构造对象时默认先调用父类无参构造函数“的这一概念;
另外,发现一个名为LineNumberTable的变量,他的数据格式非常统一,呈现处理一种line xx : xx的形式,这是干什么的呢?这其实是便是源码行数和bytecode index之间的映射,就是当我们在debug的时候,为什么程序能够精准的停留在源码的断点处,因为程序运行的是字节码,而断点的所在行是源码,他们是怎么对应起来的,就是通过这里的LineNumberTable来解决的,前一个数字代表源码的所在行,后一个数字代表bytecode index;
4.3 常量池
此外呢,注意到字节码中存在名为“Constant pool”的内容占据了大量的篇幅,下面来看看这个常量池有何作用?
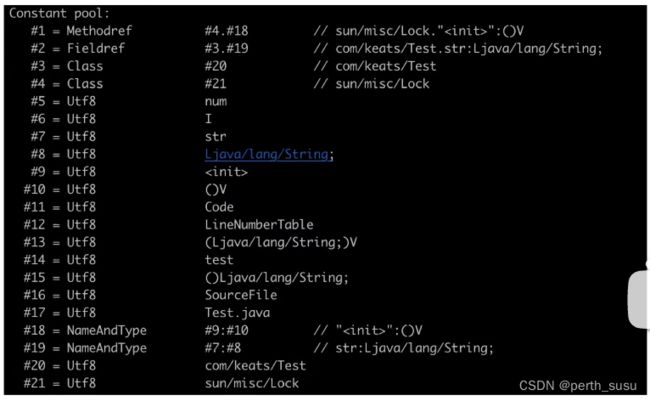
先来思考一个问题,从上层来看,大部分类都不是孤岛,他们之间存在着相互调用的关系,下图
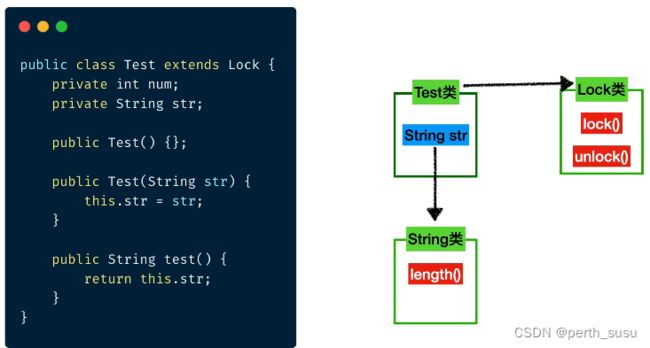
上面例子中的test类就继承了lock类,拥有了lock的能力,此外还存在String类的这个属性,就可以调用String的相关方法,那么这些调用是如何实现的呢?
先说一种最简单最无脑的实现方式:如果类A的源码中调用了类B源码中的逻辑,那么在编译期间把类B的源码直接引入到类A一起编译,这样的话也能够达到最终目的。但显然是不合理的,因为这会造成代码大量膨胀;比较合理的方式,就是通过类似指针的方式,在类A的字节码中留下一个指针,指向想要调用的类B的字节码,这里指针就起到了“链接”的作用;
在类加载中,在虚拟机加载字节码的时候,首先加载的就是一些静态的“符号引用”,然后在类加载的“链接”阶段或者说程序运行时将符号引用转化为直接引用。上面说到的符号引用既然是从字节码中加载进来的。那么在字节码中怎么体现呢?Constant Pool(常量池)内的数据就体现了符号引用与一些其他的静态引用,需要注意的是,这里的“常量”与平时写代码的“常量”意义上不太一样,这里的常量池也不是说仅仅用来存储源码中定义的那一些常量和字面上的,这里的常量池更像是一张链接表。

我们可以看到第一行和第二行分别对应了方法和属性所需要使用到的外部链接,第三行和第四行对应了当前类信息需要使用的外部链接;
4.4 运行时常量池
说完了常量池,接下来说说“运行时常量池”,你可能会疑惑,怎么还有“运行时常量池”?它和上文提到的常量池有什么关系,简单来说,运行时常量池存储着两大类数据:
(1)编译期间产生的,主要字节码中定义的静态信息,比如:
——由字节码生成的Class对象(上面所说的常量池就包含在内)
——由字码生成的字面量(这就是我们在编写代码中所定义的常量自变量)
(2)运行期间产生的,这部分比较灵活,
虚拟机开发者可以将必要的信息都放进去,比如:
——运行时会将一部分符号引用转换为直接引用,那么这些直接引用可以存储进来
——常见的字符串常量池
4.5 方法区的垃圾回收
方法区的垃圾回收不算是重点,因为方法区的数据大部分需要稳定使用,所以一般不关注该区域的垃圾回收,但是这并不意味着完全不需要垃圾回收了,当方法区的内存占用到达一定阈值,还是需要回收一下意思意思的,不然也可能会抛出OOM的异常。那么哪些信息可能会被回收呢?
比如说通过类加载进入方法区的类型信息,就是上面提到的运行时常量池中的字节码生成的class对象,当内存紧张的时候可能会对小部分类进行卸载,被卸载的类需要再次使用的时候呢,就需要再次重新加载;再此如说,上面提到的运行时常量池中的这个字符串常量值池,当内存紧张时,也会对其进行部分回收。
5. 堆
堆呢,其实从JVM的规范上来说没有进行严格意义上的分区,只是从不同的角度去看,可以进行不同的逻辑划分,最主流最常见的就是从垃圾回收的角度对堆内存进行划分,大家应该也都知道,堆内存是垃圾回收的主战场,这部分内容单独讲解;