openGauss学习——SQL引擎概述

引言
这篇博客中我将对openGauss SQL引擎做简单的概述,之后的学习也将主要在这一方向的内容展开。
SQL及openGauss支持的SQL标准
SQL是用于访问和处理数据库的标准计算机语言。SQL提供了各种任务的语句,包括:
- 查询数据。
- 在表中插入,更新和删除行。
- 创建,替换,更改和删除对象。
- 控制对数据库及其对象的访问。
- 保证数据库的一致性和完整性。
SQL语言由用于处理数据库和数据库对象的命令和函数组成,该语言还会强制实施有关数据类型、表达式和文本使用的规则。openGauss默认支持SQL2、SQL3和SQL4的主要特性。
openGauss SQL引擎简述
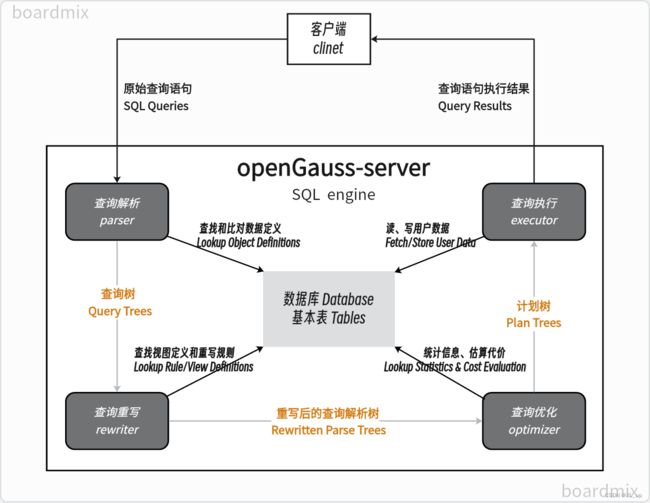
数据库的SQL引擎是数据库重要的子系统之一,它对上负责承接应用程序发送过来的SQL语句,对下则负责指挥执行器运行执行计划。其中优化器作为SQL引擎中最重要、最复杂的模块,被称为数据库的“大脑”,优化器产生的执行计划的优劣直接决定数据库的性能。
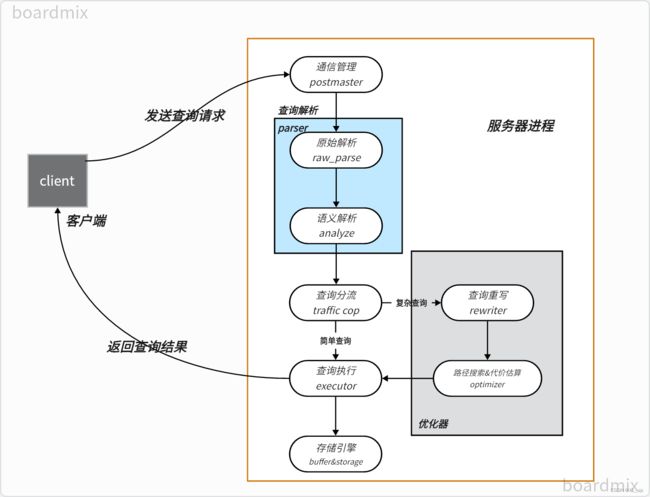
openGauss SQL引擎可大致分为查询解析(parser)、查询分流(Traffic Cop)、查询重写(Rewriter)、查询优化(Optimizer)和查询执行(Executor)五个部分,一次SQL查询的执行流程大致如上图所示:前端程序发送启动信息给通信管理模块postmaster,postmaster根据信息内容建立后端响应线程。查询首先通过parser完成词法、语法、语义的分析,再根据查询任务的复杂程度进行查询分流;如果是复杂查询,则需要通过Rewriter进行查询重写,对SQL查询树进行化简,再通过Optimizer生成查询计划以及估计查询代价;最后将查询任务交由Executor执行。
接下来对各模块的架构进行简单介绍。
查询解析(parser)
parser源码目录为:/src/common/backend/parser。
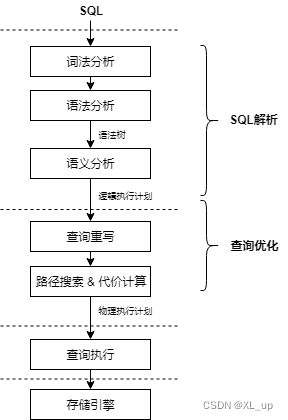
parser对输入的SQL语句进行词法、语法和语义分析,获得查询解析树或者逻辑计划,具体阶段包括如下:
- 词法分析:从语句中识别出系统支持的关键字、标识符、操作符、终结符等,为每个词确定固有的词性。
- 语法分析:根据SQL的标准定义语法规则,使用词法分析中产生的词去匹配语法规则,如果一个SQL语句能够匹配一个语法规则,则生成对应的语法树。
- 语义分析:对语法树进行检查与分析,检查语法树中对应的表、列、函数、表达式是否有对应的元数据(指数据库中定义有关数据特征的数据,用来检索数据库信息)描述,基于分析结果对语法树进行扩充,输出查询树。 其中词法和语法分析代码基于gram.y和scan.l中定义的规则,词法分析器在文件scan.l中定义,它负责识别标识符、SQL关键字等。语法解析器在文件gram.y中定义,由一组语法规则和每当触发规则时执行的动作组成,基于这些动作代码构架并输出语法树。
解析器在词法和语法分析阶段仅使用有关SQL语法结构的固定规则来创建语法树。它不会在系统目录中进行任何查找,因此无法理解所请求操作的详细语义。语法解析完成后,语义分析将解析器返回的语法树作为输入,并进行语义分析以了解查询所引用的表、函数和运算符。用来表示此信息的数据结构称为查询树。
查询分流(traffic cop)
traffic cop(tcop)源码目录为:/src/common/backend/tcop。
模块负责查询的分流,它负责区分简单和复杂的查询指令。事务控制命令(例如BEGIN和ROLLBACK)非常简单,因此不需要其它处理,而其它命令(例如SELECT和JOIN)则传递给重写器。这种区分通过对简单命令执行最少的优化,并将更多的时间投入到复杂的命令上,从而减少了处理时间。
查询重写(rewriter)
rewriter源码目录为:/src/gausskernel/optimizer/rewrite。
rewriter利用已有语句特征和关系代数运算来生成更高效的等价语句。SQL语言是一种描述性语言,数据库的使用者只是描述了想要的结果,而不关心数据的具体获取方式,输入数据库的SQL语言很难做到是以最优形式表示的,往往隐含了一些冗余信息,这些信息可以被挖掘用来生成更加高效的SQL语句。查询重写就是把用户输入的SQL语句转换为更高效的等价SQL,其遵循2个基本原则:
(1)等价性:原语句和重写后的语句,输出结果相同。
(2)高效性:重写后的语句,比原语句在执行时间和资源使用上更高效。
此处简单介绍openGauss如下三个关键的查询重写技术:
(1)常量表达式化简:常量表达式即用户输入SQL语句中包含运算结果为常量的表达式,分为算数表达式、逻辑运算表达式、函数表达式。查询重写可以对常量表达式预先计算以提升效率。例如“SELECT * FROM table WHERE a=1+1; ”被重写为“SELECT * FROM table WHERE a=2”语句。
(2)子查询提升:用户输入的SQL语句往往包含了大量的子查询,但是相关子查询往往需要使用嵌套循环的方法来实现,执行效率较低,因此将子查询优化为“Semi Join”的形式可以在优化规划时选择其它的执行方法,或能提高执行效率。例如“SELECT * FROM t1 WHERE t1.a in (SELECT t2.a FROM t2); ”语句可重写为“SELECT * FROM t1 LEFT SEMI JOIN t2 ON t1.a=t2.a”语句。
(3)谓词下推:谓词通常为SQL语句中的条件,例如“SELECT * FROM t1 WHERE t1.a=1; ”语句中的“t1.a=1”即为谓词。等价类是指等价的属性、实体等对象的集合,例如“WHERE t1.a=t2.a”语句中,t1.a和t2.a互相等价,组成一个等价类{t1.a,t2.a}。利用等价类推理(又称作传递闭包),我们可以生成新的谓词条件,从而达到减小数据量和最大化利用索引的目的。
查询优化(optimizer)
optimizer源码目录为:/src/gausskernel/optimizer。
optimizer的任务是创建最佳执行计划。一个给定的查询树实际上可以以多种不同的方式执行,每种方式都会产生相同的结果集。如果在计算上可行,则查询优化器将检查这些可能的执行计划中的每一个,最终选择预期运行速度最快的执行计划。
在某些情况下,检查执行查询的每种可能方式都会占用大量时间和内存空间,特别是在执行涉及大量连接操作的查询时。为了在合理的时间内确定合理的(不一定是最佳的)查询计划,当查询连接数超过阈值时,openGauss使用遗传查询优化器(genetic query optimizer),通过遗传算法来做执行计划的枚举。
优化器的查询计划(plan)搜索过程实际上与称为路径(path)的数据结构一起使用,该路径只是计划的简化表示,其中仅包含确定计划所需的关键信息。确定代价最低的路径后,将构建完整的计划树以传递给执行器。这足够详细地表示了所需的执行计划,供执行者运行。
查询执行(executor)
executor源码目录为:/src/gausskernel/runtime/executor。
执行器(executor)采用优化器创建的计划,并对其进行递归处理以提取所需的行的集合。这本质上是一种需求驱动的流水线执行机制,即每次调用一个计划节点时,它都必须再传送一行,或者报告已完成传送所有行。
执行器机制用于执行所有4种基本SQL查询类型:SELECT、INSERT、UPDATE和DELETE。
(1)对于SELECT,顶级执行程序代码仅需要将查询计划树返回的每一行发送给客户端。
(2)对于INSERT,每个返回的行都插入到为INSERT指定的目标表中。这是在称为ModifyTable的特殊顶层计划节点中完成的。(1个简单的“INSERT … VALUES”命令创建了1个简单的计划树,该树由单个Result节点组成,该节点仅计算一个结果行,并传递给ModifyTable树节点实现插入)。
(3)对于UPDATE,优化器对每个计算的更新行附着所更新的列值,以及原始目标行的TID(元组ID或行ID);此数据被馈送到ModifyTable节点,并使用该信息来创建新的更新行并标记旧行已删除。
(4)对于DELETE,计划实际返回的唯一列是TID,而ModifyTable节点仅使用TID访问每个目标行并将其标记为已删除。
执行器的主要处理控制流程如下:
(1) 创建查询描述。
(2) 查询初始化:创建执行器状态(查询执行上下文)、执行节点初始化(创建表达式与每个元组上下文、执行表达式初始化)。
(3) 查询执行:执行处理节点(递归调用查询上下文、执行表达式,然后释放内存,重复操作)。
(4) 查询完成;执行未完成的表格修改节点。
(5) 查询结束:递归释放资源、释放查询及其子节点上下文。
(6) 释放查询描述。
总结
在本篇博客中我以自身学习的视角对openGauss SQL引擎做了简要的概括,新手上路,目光所及,短寸之间。如有失误之处,烦请不吝斧正。