语音特征提取: 梅尔频谱(Mel-spectrogram)与梅尔倒频系数(MFCCS)
1 核心概念
1.1 语音信号
语音信号是一个非平稳的时变信号,但语音信号是由声门的激励脉冲通过声道形成的,经过声道(人的三腔,咽口鼻)的调制,最后由口唇辐射而出。认为“短时间”(帧长/窗长:10~30ms)内语音信号是平稳时不变的。由此构成了语音信号的“短时分析技术”。帧移一般为帧长一半或1/4。
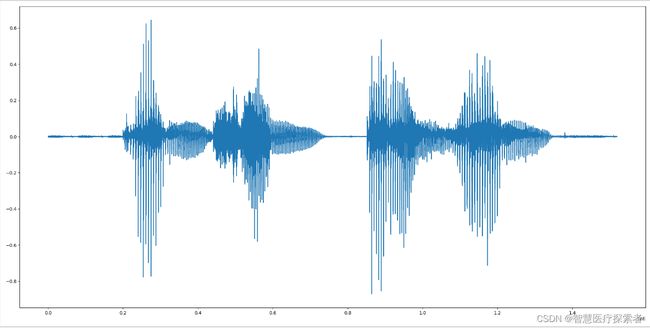
语音特征提取:声音信号本是一维的时域信号,直观上很难看出频率变化规律。傅里叶变换可把它变到频域上,虽然可看出信号的频率分布,但是丢失了时域信息,无法看出频率分布随时间的变化。为了解决这个问题,很多时频分析手段应运而生,如短时傅里叶,小波,Wigner分布等都是常用的时频域分析方法。
1.2 频谱
傅里叶变换的意义就是任意信号都可以分解为若干不同频率的正弦波的叠加。语音信号中,这些正弦波中,频率最低的称为信号的基波,其余称为信号的谐波。基波只有一个,可以称为一次谐波,谐波可以有很多个,每次谐波的频率是基波频率的整数倍。谐波的大小可能互不相同。以谐波的频率为横坐标,幅值(大小)为纵坐标,绘制的系列条形图,称为频谱。频谱能够准确反映信号的内部构造。

1.2 梅尔语谱图
语音的时域分析和频域分析是语音分析的两种重要方法,但是都存在着局限性。时域分析对语音信号的频率特性没有直观的了解,频域特性中又没有语音信号随时间的变化关系。
语谱图综合了时域和频域的特点,明显的显示出来了语音频率随时间的变化情况,语谱图的横轴为时间,纵轴为频率,颜色深表示能量大小,也就是|x|^2。语谱图上不同的黑白程度形成不同的纹路,称为声纹,不用讲话者的声纹是不一样的,可以用做声纹识别。
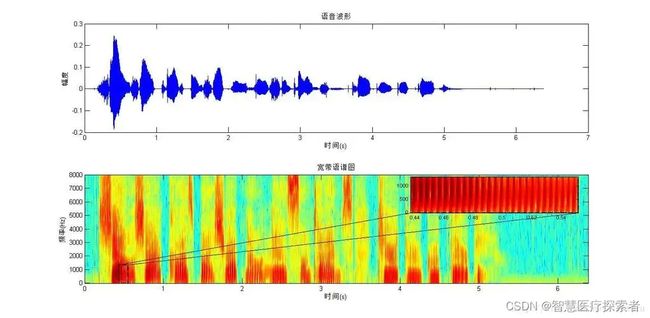
机器学习的第一步都是要提取出相应的特征(feature),如果输入数据是图片,例如28*28的图片,那么只需要把每个像素(pixel)作为特征,对应的像素值大小(代表颜色的强度)作为特征值即可。那么在音频、语音信号处理领域,我们需要将信号转换成对应的语谱图(spectrogram),将语谱图上的数据作为信号的特征。语谱图的横轴x为时间,纵轴y为频率,(x,y)对应的数值代表在时间x时频率y的幅值。通常的语谱图其频率是线性分布的,但是人耳对频率的感受是对数的(logarithmic),即对低频段的变化敏感,对高频段的变化迟钝,所以线性分布的语谱图显然在特征提取上会出现“特征不够有用的情况”,因此梅尔语谱图应运而生。梅尔语谱图的纵轴频率和原频率经过如下公式互换:
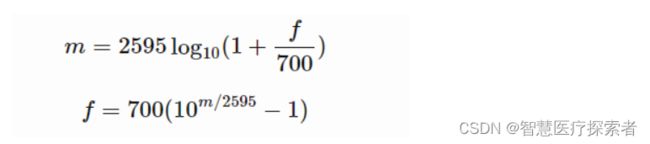
其中f代表原本的频率,m代表转换后的梅尔频率,显然,当f很大时,m的变化趋于平缓。
1.3 梅尔倒频系数(MFCCs)
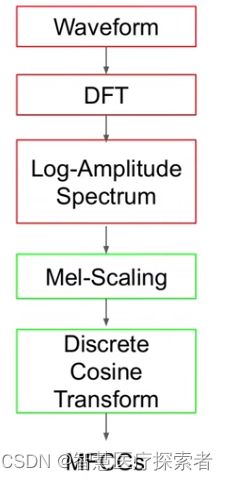
梅尔倒频系数(MFCCs)是在得到梅尔语谱图之后进行余弦变换(DCT,一种类似于傅里叶变换的线性变换),然后取其中一部分系数即可。提取流程总结如下:
通过librosa提取mfcc:
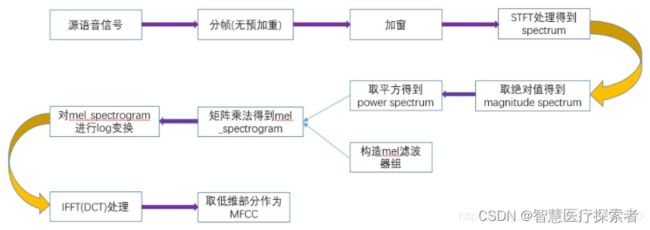
2 获取梅尔语谱图代码实现
2.1 获取音频信号
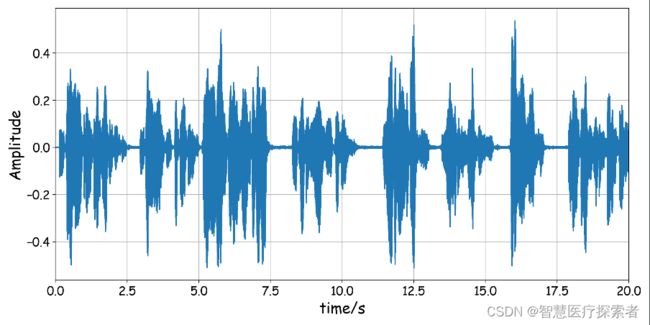
python可以用librosa库来读取音频文件,这里我们首先读取音频文件,并作出0-20秒的波形。现在的音乐文件采样率通常是44.1kHz。用y和sr分别表示信号和采样率。代码和图形如下:
import librosa
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
import matplotlib.ticker as ticker
# 图形绘制
def personal_plot(x, y):
plt.figure(dpi=200, figsize=(12, 6))
rcParams['font.family'] = 'Comic Sans MS'
plt.plot(x, y)
plt.xlim(x[0], x[-1])
plt.xlabel('time/s', fontsize=20)
plt.ylabel('Amplitude', fontsize=20)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.grid()
plt.show()
y, sr = librosa.load('../data/mel001.wav', sr=None, duration=30)
# 获取0-20秒的部分
tmax, tmin = 20, 0
t = np.linspace(tmin, tmax, (tmax - tmin) * sr)
personal_plot(t, y[tmin * sr:tmax * sr])注意:对于MP3文件,librosa会自动调用audio_read函数,所以如果是MP3文件,务必保证将ffmpeg的路径添加到系统环境变量中,不然audio_read函数会出错。
运行结果显示如下:
2.2 信号预加重(pre-emphasis)
通常来讲语音/音频信号的高频分量强度较小,低频分量强度较大,信号预加重就是让信号通过一个高通滤波器,让信号的高低频分量的强度不至于相差太多。在时域中,对信号x[n]作如下操作:
![]()
α通常取一个很接近1的值,typical value为0.97或0.95. 从时域公式来看,可能有部分人不懂为啥这是一个高通滤波器,我们从z变换的角度看一下滤波器的transfer function:
![]()
可以看出滤波器有一个极点0,和一个零点α。当频率为0时,z=1, 放大系数为(1-α)。当频率渐渐增大,放大系数不断变大,当频率到pi时,放大系数为(1+α)。离散域中,[0,pi]对应连续域中的[0, fs/2](单位Hz)。其中fs为采样率,在我们这里是44.1kHz。因此当频率到22000Hz时,放大系数为(1+α)。下面用两段代码和对应的图像给出一个直观感受:
# 未经过预加重的信号频谱
plt.figure(dpi=300, figsize=(7, 4))
freq = sr / n * np.linspace(0, n / 2, int(n / 2) + 1)
plt.plot(freq, np.absolute(np.fft.rfft(y[tmin * sr:tmax * sr], n) ** 2) / n)
plt.xlim(0, 5000)
plt.xlabel('Frequency/Hz', fontsize=14)
plt.show()
# 预加重之后的信号频谱
plt.figure(dpi=300, figsize=(7, 4))
plt.plot(freq,np.absolute(np.fft.rfft(emphasized_y,n)**2)/n)
plt.xlim(0, 5000)
plt.xlabel('Frequency/Hz', fontsize=14)
plt.show()运行结果显示如下:
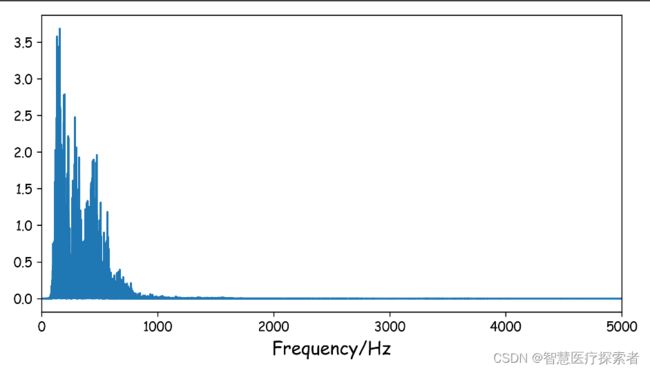
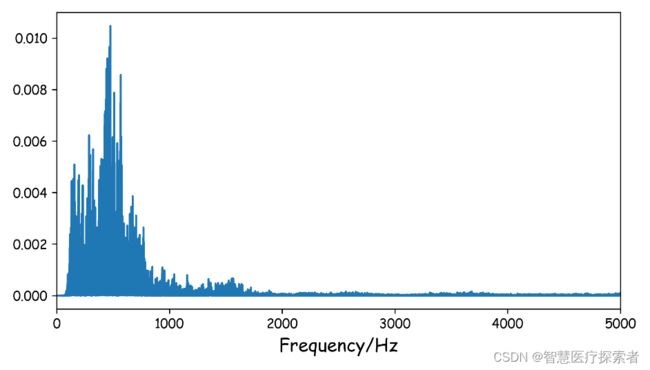
这两段代码里用了函数librosa.fft.rfft(y,n),rfft表示经过fft变换之后只取其中一半(因为另一半对应负频率,没有用处), y对应信号,n对应要做多少点的FFT。我们这里的信号有44.1k*20=882000个点,所以对应的FFT 也做882000点的FFT,每一个点所对应的实际频率是该点的索引值*fs/n,这是咋得出来的?因为第882000个点应该对应(约等于)fs(或者离散域中的2pi),所以前面的点根据线性关系一一对应即可。这里只展示0-5000Hz,可以看出,经过预加重之后的信号高频分量明显和低频分量的差距没那么大了。
这样预加重的好处有什么三点:
- 平衡高频和低频
- 避免FFT中的数值问题(也就是高频值太小出现在分母的时候可能会出问题)
- 或许可以提高SNR。
2.3 分帧(framing)
预处理完信号之后,要把原信号按时间分成若干个小块,一块就叫一帧(frame)。为啥要做这一步?因为原信号覆盖的时间太长,用它整个来做FFT,我们只能得到信号频率和强度的关系,而失去了时间信息。我们想要得到频率随时间变化的关系,所以将原信号分成若干帧,对每一帧作FFT(又称为短时FFT,因为我们只取了一小段时间),然后将得到的结果按照时间顺序拼接起来。这就是语谱图(spectrogram)的原理。
下面定义几个变量:
- frame_size: 每一帧的长度。通常取20-40ms。太长会使时间上的分辨率(time resolution)较小,太小会加重运算成本。这里取25ms.
- frame_length: 每一帧对应的sample数量。等于fs*frame_size。我们这里是44.1k*0.025=1102.
- frame_stride: 相邻两帧的间隔。通常间隔必须小于每一帧的长度,即两帧之间要有重叠,否则我们可能会实去两帧边界附近的信息。做特征提取的时候,我们是绝不希望实去有用信息的。 这里取10ms,即有60%的重叠。
- frame_step: 相邻两帧的sample数量。这里是441.
- frame_num: 整个信号所需要的帧数。一般希望所需要的帧数是个整数值,所以这里要对信号补0(zero padding)让信号的长度正好能分成整数帧。
具体代码如下:
frame_size, frame_stride = 0.025, 0.01
frame_length, frame_step = int(round(sr*frame_size)), int(round(sr*frame_stride))
signal_length = (tmax-tmin)*sr
# 向上舍入
frame_num = int(np.ceil((signal_length-frame_length)/frame_step))+1
# 不足的部分补零
pad_frame = (frame_num-1)*frame_step+frame_length-signal_length
pad_y = np.append(emphasized_y, np.zeros(pad_frame))
signal_len = signal_length+pad_frame2.4 加窗(window)
分帧完毕之后,对每一帧加一个窗函数,以获得较好的旁瓣下降幅度。通常使用hamming window。
为啥要加窗?要注意,即使我们什么都不加,在分帧的这个过程中也相当于给信号加了矩形窗,学过离散滤波器设计的人应该知道,矩形窗的频谱有很大的旁瓣,时域中将窗函数和原函数相乘,相当于频域的卷积,矩形窗函数和原函数卷积之后,由于旁瓣很大,会造成原信号和加窗之后的对应部分的频谱相差很大,这就是频谱泄露。hamming window有较小的旁瓣,造成的spectral leakage也就较小。代码实现如下:首先定义indices变量,这个变量生成每帧所对应的sample的索引。np.tile函数可以使得array从行或者列扩展。然后定义frames,对应信号在每一帧的值。frames共有1999行,1102列,分别对应一共有1999帧和每一帧有1102个sample。将得到的frames和hamming window直接相乘即可,注意这里不是矩阵乘法。
indices = np.tile(np.arange(0, frame_length), (frame_num, 1)) + np.tile(
np.arange(0, frame_num * frame_step, frame_step), (frame_length, 1)).T
# frame的每一行代表每一帧的sample值
frames = pad_y[indices]
# 加hamming window 注意这里不是矩阵乘法
frames *= np.hamming(frame_length)2.5 获取功率谱
我们在2.4中已经获得了frames变量,其每一行对应每一帧,所以我们分别对每一行做FFT。由于每一行是1102个点的信号,所以可以选择1024点FFT(FFT点数比原信号点数少会降低频率分辨率frequency resolution,但这里相差很小,所以可以忽略)。将得到的FFT变换取其magnitude,并进行平方再除以对应的FFT点数,即可得到功率谱。到这一步我们其实已经得到了spectrogram, 只需要用plt.imshow画出其dB值对应的热力图即可,代码和结果如下:
# frame_length=1102,所以用1024足够了
NFFT = 1024
mag_frames = np.absolute(np.fft.rfft(frames, NFFT))
pow_frames = mag_frames ** 2 / NFFT
plt.figure(dpi=300, figsize=(12, 6))
plt.imshow(20 * np.log10(pow_frames[40:].T), cmap=plt.cm.jet, aspect='auto')
plt.yticks([0, 128, 256, 384, 512], np.array([0, 128, 256, 384, 512]) * sr / NFFT)
plt.show()代码运行结果如下:
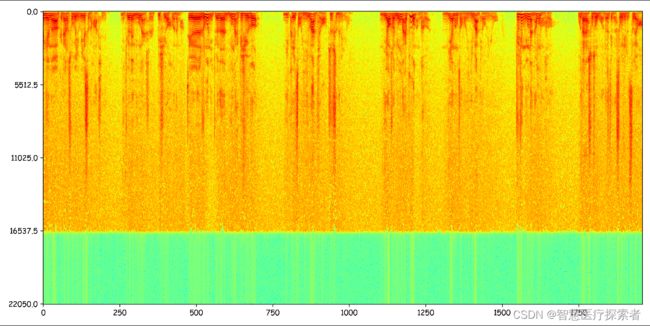
2.6 梅尔滤波器组(Mel-filter banks)
最后一步是将梅尔滤波器运用到上一步得到的pow_frames上。所谓梅尔滤波器组是一个等高的三角滤波器组,每个滤波器的起始点在上一个滤波器的中点处。其对应的频率在梅尔尺度上是线性的,因此称之为梅尔滤波器组。每个滤波器对应的频率可以将最大频率(下图中是4000,我们这里是22.05k)用上文中提到的公式转换成梅尔频率,在梅尔尺度上线性分成若干个频段,再转换回实际频率尺度即可。实际操作时,将每个滤波器分别和功率谱pow_frames进行点乘,获得的结果即为该频带上的能量(energy)。这里我们的pow_frames是一个(1999,513)的矩阵(这里可能有人疑问513咋来的?我们刚刚做的不是1024点FFT吗?这里注意因为我们用了rfft,只用了非负的那一半频率,所以是1024/2+1个点),梅尔滤波器fbank是一个(mel_N, 513)的矩阵,其中mel_N代表对应的梅尔滤波器个数,这个值不能太大,因为这里我们一共只有513个点,如果mel_N取得太大,会导致前面几个滤波器的长度都是0 (因为低频的梅尔滤波器特别窄)。我们只要将这两个矩阵相乘pow_frames*fbank.T即可得到mel-spectrogram,结果是一个(1999, 40)的矩阵,每一行是一帧,每一列代表对应的梅尔频带的能量。具体梅尔滤波器的图例和计算公式以及对应代码如下:
![]()
其中m代表滤波器的序号,f(m-1)和f(m)、f(m+1)分别对应第m个滤波器的起始点、中间点和结束点。大家一定要注意的一点是,这里的f(m)对应的值不是频率值,而是对应的sample的索引!比如,我们这里最大频率是22050 Hz, 所以22050Hz对应的是第513个sample,即频率f所对应的值是f/fs*NFFT。
代码中有一段np.where(condition,a,b),这个函数的功能是检索b中的元素,当condition满足的时候,输出a否则,输出b中的原元素。这一步的操作是为了将其中的全部0值以一个很小的非负值代替,否则在计算dB的时候,log中出现0会出错。
# frame_length=1102,所以用1024足够了
NFFT = 1024
mag_frames = np.absolute(np.fft.rfft(frames, NFFT))
pow_frames = mag_frames ** 2 / NFFT
plt.figure(dpi=300, figsize=(12, 6))
plt.imshow(20 * np.log10(pow_frames[40:].T), cmap=plt.cm.jet, aspect='auto')
plt.yticks([0, 128, 256, 384, 512], np.array([0, 128, 256, 384, 512]) * sr / NFFT)
plt.show()
# 下面定义mel filter
# 滤波器数量,这个数字若要提高,则NFFT也要相应提高
mel_N = 40
mel_low, mel_high = 0, (2595 * np.log10(1 + (sr / 2) / 700))
mel_freq = np.linspace(mel_low, mel_high, mel_N + 2)
hz_freq = (700 * (10 ** (mel_freq / 2595) - 1))
# 将频率转换成对应的sample位置
bins = np.floor((NFFT) * hz_freq / sr)
# 每一行储存一个梅尔滤波器的数据
fbank = np.zeros((mel_N, int(NFFT / 2 + 1)))
for m in range(1, mel_N + 1):
f_m_minus = int(bins[m - 1]) # left
f_m = int(bins[m]) # center
f_m_plus = int(bins[m + 1]) # right
for k in range(f_m_minus, f_m):
fbank[m - 1, k] = (k - bins[m - 1]) / (bins[m] - bins[m - 1])
for k in range(f_m, f_m_plus):
fbank[m - 1, k] = (bins[m + 1] - k) / (bins[m + 1] - bins[m])
filter_banks = np.matmul(pow_frames, fbank.T)
filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks) # np.finfo(float)是最小正值
filter_banks = 20 * np.log10(filter_banks)
# filter_banks -= np.mean(filter_banks,axis=1).reshape(-1,1)
plt.figure(dpi=300, figsize=(12, 6))
plt.imshow(filter_banks[40:].T, cmap=plt.cm.jet, aspect='auto')
plt.yticks([0, 10, 20, 30, 39], [0, 1200, 3800, 9900, 22000])
plt.show()最后,得到的mel-spectrogram如下:

2.7 Mel-spectogram feature
机器学习的时候,每一个音频段即可用对应的mel-spectogram表示,每一帧对应的某个频段即为一个feature。因此我们一共获得了1999*40个feature和对应的值。实际操作中,每个音频要采用同样的长度,这样我们的feature数量才是相同的。通常还要进行归一化,即每一帧的每个元素要减去该帧的平均值,以保证每一帧的均值均为0.
2.8 完整代码
import librosa
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
import matplotlib.ticker as ticker
# 图形绘制
def personal_plot(x, y):
plt.figure(dpi=200, figsize=(12, 6))
rcParams['font.family'] = 'Comic Sans MS'
plt.plot(x, y)
plt.xlim(x[0], x[-1])
plt.xlabel('time/s', fontsize=20)
plt.ylabel('Amplitude', fontsize=20)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.grid()
plt.show()
y, sr = librosa.load('../data/mel001.wav', sr=None, duration=30)
# 获取0-20秒的部分
tmax, tmin = 20, 0
t = np.linspace(tmin, tmax, (tmax - tmin) * sr)
personal_plot(t, y[tmin * sr:tmax * sr])
alpha = 0.97
emphasized_y = np.append(y[tmin * sr], y[tmin * sr + 1:tmax * sr] - alpha * y[tmin * sr:tmax * sr - 1])
n = int((tmax - tmin) * sr) # 信号一共的sample数量
# 未经过预加重的信号频谱
plt.figure(dpi=300, figsize=(7, 4))
freq = sr / n * np.linspace(0, n / 2, int(n / 2) + 1)
plt.plot(freq, np.absolute(np.fft.rfft(y[tmin * sr:tmax * sr], n) ** 2) / n)
plt.xlim(0, 5000)
plt.xlabel('Frequency/Hz', fontsize=14)
plt.show()
# 预加重之后的信号频谱
plt.figure(dpi=300, figsize=(7, 4))
plt.plot(freq,np.absolute(np.fft.rfft(emphasized_y,n)**2)/n)
plt.xlim(0, 5000)
plt.xlabel('Frequency/Hz', fontsize=14)
plt.show()
frame_size, frame_stride = 0.025, 0.01
frame_length, frame_step = int(round(sr*frame_size)), int(round(sr*frame_stride))
signal_length = (tmax-tmin)*sr
# 向上舍入
frame_num = int(np.ceil((signal_length-frame_length)/frame_step))+1
# 不足的部分补零
pad_frame = (frame_num-1)*frame_step+frame_length-signal_length
pad_y = np.append(emphasized_y, np.zeros(pad_frame))
signal_len = signal_length+pad_frame
indices = np.tile(np.arange(0, frame_length), (frame_num, 1)) + np.tile(
np.arange(0, frame_num * frame_step, frame_step), (frame_length, 1)).T
# frame的每一行代表每一帧的sample值
frames = pad_y[indices]
# 加hamming window 注意这里不是矩阵乘法
frames *= np.hamming(frame_length)
# frame_length=1102,所以用1024足够了
NFFT = 1024
mag_frames = np.absolute(np.fft.rfft(frames, NFFT))
pow_frames = mag_frames ** 2 / NFFT
plt.figure(dpi=300, figsize=(12, 6))
plt.imshow(20 * np.log10(pow_frames[40:].T), cmap=plt.cm.jet, aspect='auto')
plt.yticks([0, 128, 256, 384, 512], np.array([0, 128, 256, 384, 512]) * sr / NFFT)
plt.show()
# 下面定义mel filter
# 滤波器数量,这个数字若要提高,则NFFT也要相应提高
mel_N = 40
mel_low, mel_high = 0, (2595 * np.log10(1 + (sr / 2) / 700))
mel_freq = np.linspace(mel_low, mel_high, mel_N + 2)
hz_freq = (700 * (10 ** (mel_freq / 2595) - 1))
# 将频率转换成对应的sample位置
bins = np.floor((NFFT) * hz_freq / sr)
# 每一行储存一个梅尔滤波器的数据
fbank = np.zeros((mel_N, int(NFFT / 2 + 1)))
for m in range(1, mel_N + 1):
f_m_minus = int(bins[m - 1]) # left
f_m = int(bins[m]) # center
f_m_plus = int(bins[m + 1]) # right
for k in range(f_m_minus, f_m):
fbank[m - 1, k] = (k - bins[m - 1]) / (bins[m] - bins[m - 1])
for k in range(f_m, f_m_plus):
fbank[m - 1, k] = (bins[m + 1] - k) / (bins[m + 1] - bins[m])
filter_banks = np.matmul(pow_frames, fbank.T)
filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks) # np.finfo(float)是最小正值
filter_banks = 20 * np.log10(filter_banks)
# filter_banks -= np.mean(filter_banks,axis=1).reshape(-1,1)
plt.figure(dpi=300, figsize=(12, 6))
plt.imshow(filter_banks[40:].T, cmap=plt.cm.jet, aspect='auto')
plt.yticks([0, 10, 20, 30, 39], [0, 1200, 3800, 9900, 22000])
plt.show()
3 总结
在音频处理和语音识别领域,Mel频谱(Mel-spectrogram)和梅尔频率倒谱系数(MFCC)都是常用的特征表示方法。两者都广泛应用,但在不同的应用场景中各有优势。
Mel频谱(Mel-spectrogram)
-
定义:Mel频谱是一种频谱的视图,它展示了信号的能量在时间和Mel尺度频率上的分布。Mel尺度是一种基于人类听觉感知的非线性频率尺度。
-
用途:Mel频谱广泛用于现代的深度学习应用,特别是在使用卷积神经网络(CNN)进行音频分类、音乐生成、环境声音分析等领域。
-
优势:它提供了一种比较直观的频率和时间的表示,适用于需要利用信号局部的时频特征的深度学习模型。
MFCC(Mel Frequency Cepstral Coefficients)
-
定义:MFCC是一种在梅尔尺度上计算的倒谱系数,它从音频信号中提取的特征反映了人类听觉特性。
-
用途:MFCC传统上被广泛用于语音识别和说话人识别,尤其是在传统的机器学习方法中。
-
优势:MFCC特征对于表示语音信号的短时能量和频率分布非常有效,特别适合于处理和识别语音。
Mel频谱和MFCC都是重要的音频特征表示方法,但它们的应用依赖于特定的任务和所使用的技术。在深度学习特别是CNN的应用中,Mel频谱可能更常用;而在传统音频处理和基于传统机器学习的语音识别中,如HMM、GMM等模型中MFCC仍然占据重要地位。