基于YOLOv3算法的交通标志识别系统实现流程(个人学习笔记,仅当参考!!)
总流程
安装darknet
本文利用linux操作系统上安装的Darknet开源轻型深度学习框架,为了提高训练速度利用CUDA和OPENCV 进行编译,完成对YOLO v3算法LISA数据集中四类不同的交通标志的训练及测试,实现对视频中运动着的目标交通标志的实时检测识别。
官网: https://pjreddie.com/darknet/yolo/
1)克隆Darkent
git clone https://github.com/pjreddie/darknet
2)编译项目
cd darknet
make
3)下载预训练权重文件
wget https://pjreddie.com/media/files/yolov3.weights
4)测试CPU版本的Darknet
./darknet detect cfg/yolov3.cfg yolov3.weights data/horses.jpg
5)使用CUDA和OPENCV进行编译
修改darknet的makefile配置文件
GPU=1
CUDNN=1
OPENCV=1
6)然后执行
make clean
make
7)测试GPU版本的yolo
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
OPENCV编译
./darknet imtest data/eagle.jpg
 CPU与GPU版本yolo测试结果对比
CPU与GPU版本yolo测试结果对比
OPENCV测试结果图像
从以上对比可以看出,GPU版本的yolo要比CPU版本的yolo检测速度 快很多,对于大数据的数据集而言,经常使用GPU进行编译。
整理LISA数据集
LISA交通标志数据集是一组包含美国交通标志的视频和带注释的图像。它分为两个阶段发布,一个阶段只有图片,另一个阶段既有图片也有视频。整个数据集包括47种不同的交通标志,总共含有6610张图像可以用来交通标志的识别检测,具有不同的分辨率,低分辨率为640 480,高分辨率为1024 522,同样,图片上标注框的分辨率也不同,低分辨率为6 6,高分辨率为167 168。传统的图像处理必须经过图像二值化[15]操作,但LISA数据集中的图片既有彩色的又有灰度的,并且每个标志都标注了标志类型、位置、大小、堵塞(是/否)、侧道(是/否),所有注释都保存在纯文本的.csv文件中。数据集的完整版本包括所有带注释的符号的视频,本文便利用数据集中的测试视频进行测试。LISA数据集还有一个优点就是它提供了一组Python工具,用于处理注释和轻松地从数据集中提取相关符号,便于处理。本项目检测四种交通标志:“stop”,“pedestrianCrossing”,“signalAhead”,“speedLimit”。
因为原始的LISA数据集的每个标注都采用的以纯文本形式存储表格数据的csv格式,csv格式不具有通用标准,所以在后续的网络模型的训练及测试过程很容易出现错误,导致无法训练。为了避免这种错误的产生,需要预先将LISA数据集的.csv格式的标注转换成电子表格.xml的格式。xml相比于csv而言数据集中的图像均有标签注解,清楚明了不易出错,并用树形结构存储数据,灵活可扩展。
在linux操作系统上使用格式转换命令后将得到5373个.xml格式的新标注并建立了新的目录格式,将训练和测试使用的四类不同的交通标志图像保存在固定文件中,确定它的名称和路径并保存。
数据集格式转换
sudo pip install Jinja2-2.10.1-py2.py3-none-any.whl
python parse_lisa.py LISA_TS/allAnnotations.csv
执行该命令后将建立PACSAL VOC目录格式:
文件夹层次为 darknet / VOCdevkit / VOC2007
VOC2007下面建立两个文件夹:Annotations和JPEGImages
JPEGImages放所有的训练和测试图片,Annotations放所有的xml标记文件
在VOCdevkit / VOC2007目录下可以看到生成了文件夹labels ,同时在darknet下生成了两个文件2007_train.txt和2007_test.txt。2007_train.txt,2007_test.txt分别给出了训练图片文件和测试图片文件的列表,含有每个图片的路径和文件名。另外,在VOCdevkit / VOC2007/ImageSets/Main目录下生产了两个文件test.txt和train.txt,分别给出了训练图片文件和测试图片文件的列表,但只含有每个图片的文件名(不含路径和扩展名)。labels下的文件是images文件夹下每一个图像的yolo格式的标注文件,这是由annotations的xml标注文件转换来的。
修改网络配置文件
1)新建data/voc.names文件
可以复制data/voc.names再根据自己情况的修改;可以重新命名如:data/voc-lisa.names
2)新建 cfg/voc.data文件
可以复制cfg/voc.data再根据自己情况的修改;可以重新命名如:cfg/voc-lisa.data
3)新建cfg/yolov3-voc.cfg
可以复制cfg/yolov3-voc.cfg再根据自己情况的修改;可以重新命名cfg/yolov3-voc-lisa.cfg: 在cfg/yolov3-voc.cfg文件中,三个yolo层和各自前面的conv层的参数需要修改:
三个yolo层都要改:yolo层中的class为类别数,每一个yolo层前的conv层中的filters =(类别+5)* 3
yolo层 classes=4,conv层 filters=27
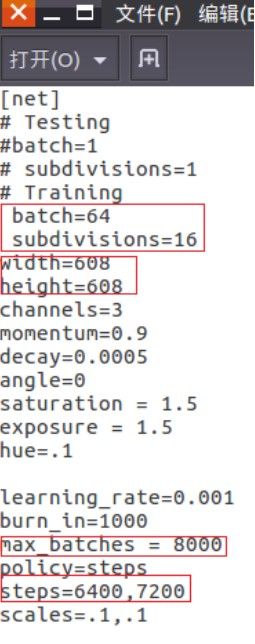
4) 训练建议
batch=64
subdivisions=16 (显存大时可用8) 把max_batches设置为 (classes*2000);例如如果训练4个目标类别,max_batches=8000
把steps改为max_batches的80% and 90%;例如steps=6400, 7200
为增加网络分辨率可增大height和width的值,但必须是32的倍数 .cfg-file (height=608, width=608 or any
value multiple of 32) 。这有助于提高检测精度。
因此训练时使用
sudo pip install Jinja2-2.10.1-py2.py3-none-any.whl python parse_lisa.py LISA_TS/allAnnotations.csv
batch=64
subdivisions=16
width=608
height=608
max_batches = 8000
policy=steps
steps=6400,7200

训练网络模型
1)在 darknet 目录下载权重文件:
wget https://pjreddie.com/media/files/darknet53.conv.74
2)训练
./darknet detector train cfg/voc-lisa.data cfg/yolov3-voc-lisa.cfg darknet53.conv.74
如需要存储训练日志,执行
./darknet detector train cfg/voc-lisa.data cfg/yolov3-voc-lisa.cfg darknet53.conv.74 2>1 | tee visualization/train_yolov3_lisa.log
输出消息为:
subdivisions输出:

Region 106 :网络层的索引为106
Region Avg IOU: 0.397296: 表示在当前l.batch(batch /= subdivs )内的图片的平均IOU
Class: 0.762366: 标注目标分类的正确率,期望该值趋近于1。
Obj: 0.337382: 检测目标的平均目标置信度,越接近1越好。
No Obj: 0.490547: 检测目标的平均目标性得分。
.5R: 0.333333:模型检测出的正样本(iou>0.5)与实际的正样本的比值。
.75R: 模型检测出的正样本(iou>0.75)与实际的正样本的比值。
count: 3:count后的值是当前l.batch(batch /= subdivs )内图片中包含正样本的图片的数量。
subdivisions输出显示了所有训练图片的一个批次,训练迭代包含16组,跟设定好的batch和subdivisions数值一致,这些样本分成16组送入网络参与训练,减轻内存占用的压力,82,94,106表示三个不同尺度上预测到的不同大小的参数。
batch输出:

5.迭代次数 2012.578125为总体的Loss值,2011.601318为平均Loss值。
3) 训练log文件分析
cd visualization
修改 extract_log.py文件,改动
extract_log(‘train_yolov3_lisa.log’,‘train_log_loss.txt’,‘images’)
extract_log(‘train_yolov3_lisa.log’,‘train_log_iou.txt’,‘IOU’)
python extract_log.py
得到两个文件: train_log_loss.txt, train_log_iou.txt
改变其中的lines的值。
然后,执行:
python train_loss_visualization.py
python train_iou_visualization.py
得到avg_loss.png和Region Avg IOU.png

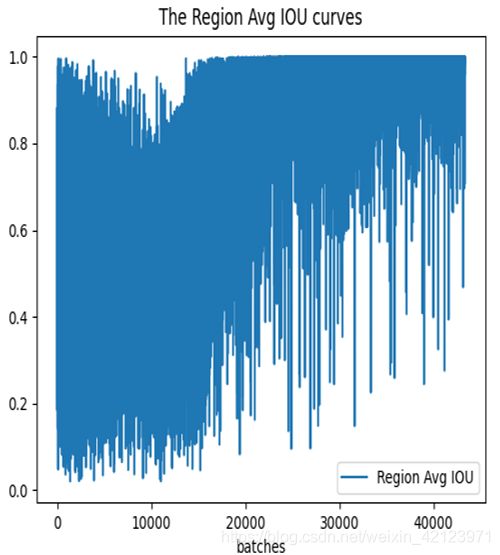
观察平均LOSS曲线和平均IOU曲线,发现平均LOSS曲线呈下降趋势并逐渐趋于0,平均IOU曲线呈上升趋势并逐渐趋于1,训练性能较好。
测试网络模型
挑选一张不属于训练集中的一张图进行测试:
./darknet detector test cfg/voc-lisa.data cfg/yolov3-voc-lisa-test.cfg backup/yolov3-voc- lisa_final.weights testfiles/img1.jpg
测试结果:

可以看到检测时间为28.065毫秒,图片中的‘stop’交通标志被100%识别出来。
测试视频:
./darknet detector demo cfg/voc-lisa.data cfg/yolov3-voc-lisa-test.cfg backup/yolov3-voc- lisa_final.weights testfiles/sd.mp4
计算mAP
./darknet detector valid cfg/voc-lisa.data cfg/yolov3-voc-lisa-test.cfg backup/yolov3- voc-lisa_final.weights
python reval_voc.py --voc_dir /home/bai/darknet/VOCdevkit --year 2007 --image_set test - -classes /home/bai/darknet/data/voc-lisa.names testLisa
画出PR曲线
python draw_pr.py
PR曲线也称为查全率查准率曲线,若该曲线越接近(1,1)坐标点,则越说明该分类器性能好。
根据白勇老师相关课程学习:链接: https://edu.51cto.com/course/18279.html.