LeetCode学习-分治算法思想
LeetCode学习-分治算法思想
- 分治算法思想,就是递归的思想。回忆一下数据结构的递归----简单来说就是函数自己调用自己本身,函数体需要一个终止条件,要不然就成死循环了。分治算法就是要求学会把一个问题向下分解成更小的问题一直分到边界(就是递归思想的终止条件),然后处理最小的分支,处理完后把结果返回给上一层作为输入继续参与运算,直到返回到最上层。如图:
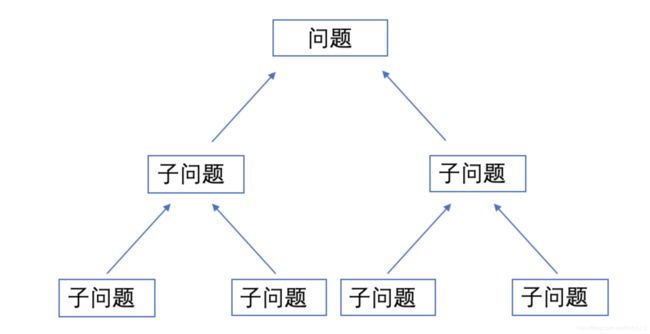
小Tips:递归对有些问题来说,处理速度是很快,比如快排。但是,递归降低时间复杂度是消耗更大内存的到的(就是占用更多的计算机的运行内存)。
- 分治算法代码的核心就是递归,那么首先复习一下递归算法
- 举个例子:6的阶乘=f(6),先看思路,也就是过程走一遍:

之前我们说了递归的重点就是一个终止条件(也叫边界条件);此处的边界条件就是f(n)中的n=1;当n=1时就表示递归进入了最低成,下一步就是要往上返回了。
- 再看代码:
# 算 n 的阶乘(假设n不为0)
def f(n):
if n==1:
return 1
else:
return n*f(n-1)
print(f(6)) #720
再来说这段简单的代码,由两部分组成。一个是终止条件n==1;当往深了走走到n=1了,开始往外返回计算的结果了;第二部分是 调用函数本身的部分了,就是处理问题的逻辑的方式了,阶乘,大家都知道一路乘下去直到1。一般的递归最难的部分就是这个逻辑的编写了,相当于什么呢?相当于,你要找到一个通用的办法,来结合一个数量级很大的运算;得多见识一些递归才好提高;
- 再来举个栗子:斐波那契数列=就是1,1,2,3,5,8,13…;现在让你求出第n个斐波那契数是多少?
想想思路;斐波那契数是前面连续两项相加得来的。那么递归逻辑部分就可以大致写成f(n) = f(n-2)+f(n-1);这个就是核心代码,是不是看起来很简单,那么还差一个终止条件是不是?观察斐波那契数列的前几个数据 f(1)=1 f(2)=1 f(3)=2前两项是固定的都是1,那么简单了,递归的终止条件就是往前推到第2项或者第1项的时候就返回1,即,终止条件是:n<=2时返回第一或者第二项的值1;
- 代码如下:(自己慢慢品)
def f(n):
if n<=2:
return 1
else:
return f(n-2)+f(n-1)
print(f(20)) # 6765
- 讲完递归,继续来分治算法思想,基本处理问题的思路如下伪代码:
def divide_conquer(problem, paraml, param2,...):
# 往里走的终止条件
if problem is None:
print_result
return
# 准备数据
data=prepare_data(problem)
# 将大问题拆分为小问题
subproblems=split_problem(problem, data)
# 处理小问题,得到子结果
subresult1=self.divide_conquer(subproblems[0],p1,..…)
subresult2=self.divide_conquer(subproblems[1],p1,...)
subresult3=self.divide_conquer(subproblems[2],p1,.…)
# 对子结果进行合并 得到最终结果
result=process_result(subresult1, subresult2, subresult3,...)
- 知道了分治思想,利用分治思想来处理一个计算x的n次幂的问题:
在不用递归思路的情况下,我们第一思路就是做一个n次的循环,每次循环都x乘上一次被复制的结果;
用分治思想来处理(从中间拆分成两部分:偶数次幂对半分,奇数次幂单独乘一个x后再分(n-1)/ 2 ):
1,终止条件:思路是n次方分成两个[n/2]次方相乘,最后n=0了表示不在拆分了;
2,准备数据,处理小问题:技术次幂先乘x再二分递归。偶数次幂直接二分递归;
def f(x, n):
# 【确定不断切分的终止条件】
if n == 0:
return 1
# 【准备数据,并将大问题拆分为小的问题】
# 奇数次幂先乘x,后剩下偶数次幂再对半递归
if n % 2 == 1:
# 【处理小问题,得到子结果】
p = x * f(x, n - 1)
return p
return f(x * x, n / 2)
print(f(3,5)) # 243
- 学到这儿,心里面大概有点印象,虽然分治思路写了那么多,总体分为两步,也就是递归思路的两个核心,一个终止条件,一个处理逻辑;再来举个例子:快速排序算法(好好感受下面代码的思想,争取自己能独立写出来,而不是看懂)
首先来说说快排的思路:每次都选择一个标志位,比标志小的放左边,比标志大的放右边。至于这个标志呢,就选定每边的第一个数字。好,选择思路有了,怎么实现,如果不考虑空间复杂度,我们的实现方式是添加新数组,每次拆分排序后,生成两个临时数组(一个放小于标志位的数,一个放大于标识位的数),下一层递归再生成两个新数组,这个实现起来岂不是增加极大的内存浪费么?有没有办法再不增加空间的情况下实现呢
在原先的数组的结构汇总进行移动数字。如何实现呢?通过用一个变量临时存放标识位,那么,标识为所在的数组中的位置不久空出来了么?只要数组中有空位,便可实现数字交换了呀;具体实现是:首位交替扫描
什么是首尾交替扫描呢?引用指针概念,left,right指针最开始分别指向数组的首尾,取第一个数字为标志位,那就是nums[left];那么left指向的位置空出来了,此时拿rigt位置的数跟标志位比较,小,就把right位置的数放到left的位置上,left++(left原来的数字已经被存到标识位变量pivot中了),若比标志位大,直接用right–比较(为什么呢?因为大的在右边啊,都最后一个了还不够右吗?)。交换后,right位置是不是空的呀?这个时候就比较left的位置啦(为啥是从left++开始,left被right覆盖后,left得++指向左数第二个元素了),继续重复上面步骤。代码如下:
# ---------------------------快速排序-------------
def quick_sort(nums: list, left: int, right: int) -> None:
#1,终止条件
if left < right:
i = left
j = right
# 取第一个元素为标志
pivot = nums[left]
while i != j:
# 交替扫描和交换
# 从右往左找到第一个比标志位小的元素,交换位置
while j > i and nums[j] > pivot:
j -= 1
if j > i:
# 如果找到了,进行元素交换
nums[i] = nums[j]
i += 1
# 从左往右找到第一个比标志位大的元素,交换位置
while i < j and nums[i] < pivot:
i += 1
if i < j:
nums[j] = nums[i]
j -= 1
# 至此完成一趟快速排序,标志位的位置已经确定好了,就在i位置上(i和j)值相等
nums[i] = pivot
# 以i为标志进行子序列元素交换
quick_sort(nums, left, i-1)
quick_sort(nums, i+1, right)
# 测试代码
import random
data = [random.randint(-100, 100) for _ in range(10)]
print(data)
quick_sort(data, 0, len(data) - 1)
print(data)
# [23, -77, 5, 26, -67, -41, -19, -89, 84, -56]
# [-89, -77, -67, -56, -41, -19, 5, 23, 26, 84]