飞桨领航团AI达人创造营----学习笔记【第二课:数据获取与处理(CV任务为主)】
AI Studio 链接
- 课程目的
- 数据的获取途径
- 数据处理与标注
- 数据预处理方法
- 模型训练评估
一、数据集的获取
通常,我们的数据来源于各个比赛平台。首先是AIStudio中的数据集,大部分经典数据集例如百度AI Studio ,Kaggle、天池、讯飞等平台(通过关键词搜索获取需要的数据集),或者是Github。还有一些小的平台,需要大家自己去看。通常来说,数据集用于学术目的,有些数据需要申请才能获得链接。
1.1 常用数据集获取方法
1.1.1 自拍自取
比如我们在比赛中需要识别官方发的几种图标,这时我们即可使用比赛时所采用的摄像头,拍取图片(或视频,在进行抽帧等处理)制作数据集。
1.1.2 爬虫
1.1.3 AI Studio 公开数据集
AI Studio 公开数据集
1.1.4 Kaggle有趣比较火热的数据集
House Prices-Advanced Regression Techniques 预测销售价格
Cat and Dog 猫狗分类
Machine Learning from Disaster 预测泰坦尼克号的生存情况并熟悉机器学习基础知识
1.1.5 天池
Barley Remote Sensing Dataset大麦遥感检测数据集 遥感影像分割
耶鲁人脸数据库 目标检测任务(人脸检测)
1.1.6 DataFountain
花卉分类数据集 图像分类
1.1.7 其他常用的数据集官网
科大讯飞官网
COCO数据集
1.2 完整流程概述
1.2.1 图像处理完整流程
-
- 图片数据获取
-
- 图片数据清洗
----初步了解数据,筛选掉不合适的图片
-
- 图片数据标注
-
- 图片数据预处理data preprocessing。
----标准化 standardlization
一 中心化 = 去均值 mean normallization
一 将各个维度中心化到0
一 目的是加快收敛速度,在某些激活函数上表现更好
一 归一化 = 除以标准差
一 将各个维度的方差标准化处于[-1,1]之间
一 目的是提高收敛效率,统一不同输入范围的数据对于模型学习的影响,映射到激活函数有效梯度的值域
-
- 图片数据准备data preparation(训练+测试阶段)
----划分训练集,验证集,以及测试集
-
- 图片数据增强data augjmentation(训练阶段 )
----CV常见的数据增强
· 随机旋转
· 随机水平或者重直翻转
· 缩放
· 剪裁
· 平移
· 调整亮度、对比度、饱和度、色差等等
· 注入噪声
· 基于生成对抗网络GAN做数搪增强AutoAugment等


ps: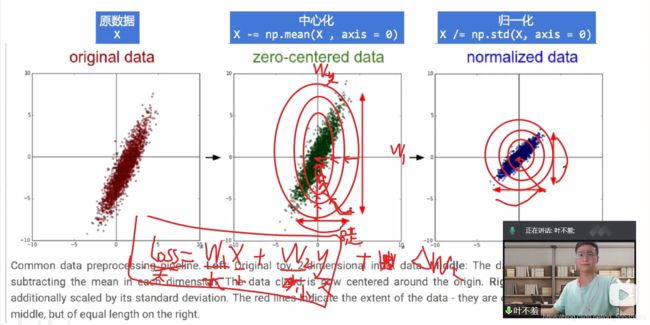
1.2.2 纯数据处理完整流程
-
数据预处理与特征工程
-
1.感知数据
----初步了解数据
----记录和特征的数量特征的名称
----抽样了解记录中的数值特点描述性统计结果
----特征类型
----与相关知识领域数据结合,特征融合
- 2.数据清理
----转换数据类型
----处理缺失数据
----处理离群数据
- 3.特征变换
----特征数值化
----特征二值化
----OneHot编码
----特征离散化特征
----规范化
区间变换
标准化
归一化
- 4.特征选择
----封装器法
循序特征选择
穷举特征选择
递归特征选择
----过滤器法
----嵌入法
- 5.特征抽取
----无监督特征抽取
主成分分析
因子分析
----有监督特征抽取
拓展小知识:
皮尔森相关系数是用来反应俩变量之间相似程度的统计量,在机器学习中可以用来计算特征与类别间的相似度,即可判断所提取到的特征和类别是正相关、负相关还是没有相关程度。 Pearson系数的取值范围为[-1,1],当值为负时,为负相关,当值为正时,为正相关,绝对值越大,则正/负相关的程度越大。若数据无重复值,且两个变量完全单调相关时,spearman相关系数为+1或-1。当两个变量独立时相关系统为0,但反之不成立。
用Corr()函数即可,(保证行相同)。
公式如下:
ρX,Y=cov(X,Y)σXσY=E((X−μX)(Y−μY))σXσY=E(XY)−E(X)E(Y)E(X2)−E2(X)E(Y2)−E2(Y)\rho_{X, Y}=\frac{\operatorname{cov}(X, Y)}{\sigma_{X} \sigma_{Y}}=\frac{E\left(\left(X-\mu_{X}\right)\left(Y-\mu_{Y}\right)\right)}{\sigma_{X} \sigma_{Y}}=\frac{E(X Y)-E(X) E(Y)}{\sqrt{E\left(X^{2}\right)-E^{2}(X)} \sqrt{E\left(Y^{2}\right)-E^{2}(Y)}}ρX,Y=σXσYcov(X,Y)=σXσYE((X−μX)(Y−μY))=E(X2)−E2(X)E(Y2)−E2(Y)E(XY)−E(X)E(Y)
当两个变量的标准差都不为零时,相关系数才有定义,Pearson相关系数适用于:
(1)、两个变量之间是线性关系,都是连续数据。
(2)、两个变量的总体是正态分布,或接近正态的单峰分布。
(3)、两个变量的观测值是成对的,每对观测值之间相互独立。
二、数据处理
2.1 官方数据处理成VOC或者COCO
2.1.1COCO2017数据集介绍
COCO数据集是Microsoft制作收集用于Detection + Segmentation + Localization + Captioning的数据集,作者收集了其2017年的版本,一共有25G左右的图片和600M左右的标签文件。 COCO数据集共有小类80个,分别为:
[‘person’, ‘bicycle’, ‘car’, ‘motorcycle’, ‘airplane’, ‘bus’, ‘train’, ‘truck’, ‘boat’, ‘traffic light’, ‘fire hydrant’, ‘stop sign’, ‘parking meter’, ‘bench’, ‘bird’, ‘cat’, ‘dog’, ‘horse’, ‘sheep’, ‘cow’, ‘elephant’, ‘bear’, ‘zebra’, ‘giraffe’, ‘backpack’, ‘umbrella’, ‘handbag’, ‘tie’, ‘suitcase’, ‘frisbee’, ‘skis’, ‘snowboard’, ‘sports ball’, ‘kite’, ‘baseball bat’, ‘baseball glove’, ‘skateboard’, ‘surfboard’, ‘tennis racket’, ‘bottle’, ‘wine glass’, ‘cup’, ‘fork’, ‘knife’, ‘spoon’, ‘bowl’, ‘banana’, ‘apple’, ‘sandwich’, ‘orange’, ‘broccoli’, ‘carrot’, ‘hot dog’, ‘pizza’, ‘donut’, ‘cake’, ‘chair’, ‘couch’, ‘potted plant’, ‘bed’, ‘dining table’, ‘toilet’, ‘tv’, ‘laptop’, ‘mouse’, ‘remote’, ‘keyboard’, ‘cell phone’, ‘microwave’, ‘oven’, ‘toaster’, ‘sink’, ‘refrigerator’, ‘book’, ‘clock’, ‘vase’, ‘scissors’, ‘teddy bear’, ‘hair drier’, ‘toothbrush’]
大类12个,分别为
[‘appliance’, ‘food’, ‘indoor’, ‘accessory’, ‘electronic’, ‘furniture’, ‘vehicle’, ‘sports’, ‘animal’, ‘kitchen’, ‘person’, ‘outdoor’]
VOC与COCO简介
Pascal 的全称是模式分析,静态建模和计算学习(Pattern Analysis, Statical Modeling and Computational Learning)。PASCAL VOC 挑战赛是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。从2005年至今,该组织每年都会提供一系列类别的、带标签的图片,挑战者通过设计各种精妙的算法,仅根据分析图片内容来将其分类,最终通过准确率、召回率、效率
MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
下面为大家演示一下标注的使用。
COCO格式,文件夹路径样式:
COCO_2017/
├── val2017 # 总的验证集
├── train2017 # 总的训练集
├── annotations # COCO标注
│ ├── instances_train2017.json # object instances(目标实例) ---目标实例的训练集标注
│ ├── instances_val2017.json # object instances(目标实例) ---目标实例的验证集标注
│ ├── person_keypoints_train2017.json # object keypoints(目标上的关键点) ---关键点检测的训练集标注
│ ├── person_keypoints_val2017.json # object keypoints(目标上的关键点) ---关键点检测的验证集标注
│ ├── captions_train2017.json # image captions(看图说话) ---看图说话的训练集标注
│ ├── captions_val2017.json # image captions(看图说话) ---看图说话的验证集标注
VOC格式,文件夹路径样式:
VOC_2017/
├── Annotations # 每张图片相关的标注信息,xml格式
├── ImageSets
│ ├── Main # 各个类别所在图片的文件名
├── JPEGImages # 包括训练验证测试用到的所有图片
├── label_list.txt # 标签的类别数
├── train_val.txt #训练集
├── val.txt # 验证集
2.1.2 Object Keypoint 类型的标注格式
{
"info": info,
"licenses": [license],
"images": [image],
"annotations": [annotation],
"categories": [category]
}
其中,info、licenses、images这三个结构体/类型,在不同的JSON文件中这三个类型是一样的,定义是共享的(object instances(目标实例), object keypoints(目标上的关键点), image captions(看图说话))。不共享的是annotation和category这两种结构体,他们在不同类型的JSON文件中是不一样的。 新增的keypoints是一个长度为3 X k的数组,其中k是category中keypoints的总数量。每一个keypoint是一个长度为3的数组,第一和第二个元素分别是x和y坐标值,第三个元素是个标志位v,v为0时表示这个关键点没有标注(这种情况下x=y=v=0),v为1时表示这个关键点标注了但是不可见(被遮挡了),v为2时表示这个关键点标注了同时也可见。 um_keypoints表示这个目标上被标注的关键点的数量(v>0),比较小的目标上可能就无法标注关键点。
annotation{
"keypoints": [x1,y1,v1,...],
"num_keypoints": int,
"id": int,
"image_id": int,
"category_id": int,
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
}
示例:
{
"segmentation": [[125.12,539.69,140.94,522.43,100.67,496.54,84.85,469.21,73.35,450.52,104.99,342.65,168.27,290.88,179.78,288,189.84,286.56,191.28,260.67,202.79,240.54,221.48,237.66,248.81,243.42,257.44,256.36,253.12,262.11,253.12,275.06,299.15,233.35,329.35,207.46,355.24,206.02,363.87,206.02,365.3,210.34,373.93,221.84,363.87,226.16,363.87,237.66,350.92,237.66,332.22,234.79,314.97,249.17,271.82,313.89,253.12,326.83,227.24,352.72,214.29,357.03,212.85,372.85,208.54,395.87,228.67,414.56,245.93,421.75,266.07,424.63,276.13,437.57,266.07,450.52,284.76,464.9,286.2,479.28,291.96,489.35,310.65,512.36,284.76,549.75,244.49,522.43,215.73,546.88,199.91,558.38,204.22,565.57,189.84,568.45,184.09,575.64,172.58,578.52,145.26,567.01,117.93,551.19,133.75,532.49]],
"num_keypoints": 10,
"area": 47803.27955,
"iscrowd": 0,
"keypoints": [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,142,309,1,177,320,2,191,398,2,237,317,2,233,426,2,306,233,2,92,452,2,123,468,2,0,0,0,251,469,2,0,0,0,162,551,2],
"image_id": 425226,"bbox": [73.35,206.02,300.58,372.5],"category_id": 1,
"id": 183126},
2.1.3 categories字段
最后,对于每一个category结构体,相比Object Instance中的category新增了2个额外的字段,keypoints是一个长度为k的数组,包含了每个关键点的名字;skeleton定义了各个关键点之间的连接性(比如人的左手腕和左肘就是连接的,但是左手腕和右手腕就不是)。 目前,COCO的keypoints只标注了person category (分类为人)。
{
"id": int,
"name": str,
"supercategory": str,
"keypoints": [str],
"skeleton": [edge]
}
示例:
{
"supercategory": "person",
"id": 1,
"name": "person",
"keypoints": ["nose","left_eye","right_eye","left_ear","right_ear","left_shoulder","right_shoulder","left_elbow","right_elbow","left_wrist","right_wrist","left_hip","right_hip","left_knee","right_knee","left_ankle","right_ankle"],
"skeleton": [[16,14],[14,12],[17,15],[15,13],[12,13],[6,12],[7,13],[6,7],[6,8],[7,9],[8,10],[9,11],[2,3],[1,2],[1,3],[2,4],[3,5],[4,6],[5,7]]
}
2.1.4 数据集统计信息
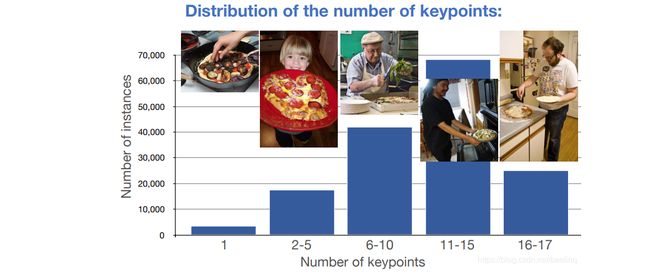
人体关键点标注,每个人体关键点个数的分布情况,其中11-15这个范围的人体是最多的,有接近70000人,6-10其次,超过40000人,后面依次为16-17,2-5,...
#拉取PaddleDetection
!git clone https://github.com.cnpmjs.org/PaddlePaddle/PaddleDetection#存入持久层中
!mv PaddleDetection/ work/#导入所需要的依赖
!pip install -r work/PaddleDetection/requirements.txt
#导入转格式所需要的包
!pip install pycocotools
!pip install scikit-image# COCO标注
!unzip -oq /home/aistudio/data/data97273/annotations_trainval2017.zip -d ./
# 总的验证集
!unzip -oq /home/aistudio/data/data97273/val2017.zip -d ./
# 总的训练集
!unzip -oq /home/aistudio/data/data97273/train2017.zip -d ./ #创建解析好的图片与xml文件的目录
!mkdir -p VOCData/images/
!mkdir -p VOCData/Annotations/
!mkdir COCOData/#处理目标检测的数据集
!python ProcessData.py#没有这个文件时创建一个空的label的txt文件
!touch VOCData/label_list.txt #移动到dataset文件夹
!mv VOCData work/PaddleDetection/dataset/%cd work/PaddleDetection/"""
按VOC格式划分数据集,train : val = 0.85 : 0.15
生成标签label_list.txt
"""
import os
import shutil
import skimage.io as io
from tqdm import tqdm
from random import shuffle
dataset = 'dataset/VOCData/'
train_txt = os.path.join(dataset, 'train_val.txt')
val_txt = os.path.join(dataset, 'val.txt')
lbl_txt = os.path.join(dataset, 'label_list.txt')
classes = [
"person"
]
with open(lbl_txt, 'w') as f:
for l in classes:
f.write(l+'\n')
xml_base = 'Annotations'
img_base = 'images'
xmls = [v for v in os.listdir(os.path.join(dataset, xml_base)) if v.endswith('.xml')]
shuffle(xmls)
split = int(0.85 * len(xmls)) #划分训练集与验证集
with open(train_txt, 'w') as f:
for x in tqdm(xmls[:split]):
m = x[:-4]+'.jpg'
xml_path = os.path.join(xml_base, x)
img_path = os.path.join(img_base, m)
f.write('{} {}\n'.format(img_path, xml_path))
with open(val_txt, 'w') as f:
for x in tqdm(xmls[split:]):
m = x[:-4]+'.jpg'
xml_path = os.path.join(xml_base, x)
img_path = os.path.join(img_base, m)
f.write('{} {}\n'.format(img_path, xml_path))%cd /home/aistudio/
!mv val2017/ COCOData/
!mv train2017/ COCOData/
!mv annotations/ COCOData/
!mv -f COCOData/ data/
!mv -f work/PaddleDetection/dataset/VOCData data/2.2 自定义数据集进行训练
2.2.1 常见标注工具
对于图像分类任务,我们只要将对应的图片是哪个类别划分好即可。对于检测任务和分割任务,目前比较流行的数据标注工具是labelimg、labelme,分别用于检测任务与分割任务的标注。
标注工具Github地址:
labelimg
labelme
PPOCRLabel
PS:利用Anaconda三步使用上述labelimg\labelme
下载及打开labelimg展示如下:
1.激活虚拟环境 :conda activate env_name
2.下载labelimg: pip install labelImg
3.打开labelimg: labelimg

2.2.2 制作VOC格式与COCO格式数据集并划分
#解压自制数据集
!unzip -oq /home/aistudio/data/data101583/facemask.zip -d work/PaddleDetection/dataset/MaskVOCData#导入paddlex
!pip install paddlex #划分VOC数据集
!paddlex --split_dataset --format VOC --dataset_dir work/PaddleDetection/dataset/MaskVOCData/ --val_value 0.15 --test_value 0.05%cd work/PaddleDetection/#制作COCO数据集
#提取文件下img目录所有照片名不要后缀
import pandas as pd
import os
filelist = os.listdir("dataset/MaskVOCData/JPEGImages")
train_name = []
for file_name in filelist:
name, point ,end =file_name.partition('.')
train_name.append(name)
df = pd.DataFrame(train_name)
df.head(8)
df.to_csv('./train_all.txt', sep='\t', index=None,header=None) !mkdir -p dataset/MaskVOCData/ImageSets/Main
!mv train_all.txt dataset/MaskVOCData/ImageSets
!mv dataset/MaskVOCData/labels.txt dataset/MaskVOCData/label_list.txt
!cp dataset/MaskVOCData/label_list.txt dataset/MaskVOCData/ImageSets/#备份VOC
!cp -r dataset/MaskVOCData /home/aistudio/!python tools/x2coco.py \
--dataset_type voc \
--voc_anno_dir dataset/MaskVOCData/Annotations \
--voc_anno_list dataset/MaskVOCData/ImageSets/train_all.txt \
--voc_label_list dataset/MaskVOCData/ImageSets/label_list.txt \
--voc_out_name ./dataset/annotations.json提示:AssertionError:label is not in label2id. 假如遇见这个问题,说明你的label对应不上标注文件里面的label,在打标签的时候不要有空格
!mv dataset/MaskVOCData dataset/MaskCOCOData
!mv ../../MaskVOCData dataset
!mkdir dataset/MaskCOCOData/annotations
!mv dataset/annotations.json dataset/MaskCOCOData/annotations
!rm dataset/MaskCOCOData/train_list.txt
!rm dataset/MaskCOCOData/val_list.txt
!rm dataset/MaskCOCOData/label_list.txt
!rm dataset/MaskCOCOData/test_list.txt
!rm -r dataset/MaskCOCOData/Annotations
!rm -r dataset/MaskCOCOData/ImageSets#划分COCO数据集
!paddlex --split_dataset --format COCO --dataset_dir dataset/MaskCOCOData/annotations --val_value 0.15 --test_value 0.05三、数据处理方法
3.1 图像的本质
我们常见的图片其实分为两种,一种叫位图,另一种叫做矢量图。如下图所示:

位图的特点:
-
由像素点定义一放大会糊
-
文件体积较大
-
色彩表现丰富逼真

矢量图的特点:
-
超矢量定义
-
放太不模糊
-
文件体积较小
-
表现力差
%cd /home/aistudio/work/PaddleDetectionimport paddle
import paddlex as pdx
import numpy as np
import paddle.nn as nn
import paddle.nn.functional as F
import PIL.Image as Image
import cv2
import os
from random import shuffle
from paddlex.det import transforms as T
from PIL import Image, ImageFilter, ImageEnhance
import matplotlib.pyplot as plt # plt 用于显示图片
path='dataset/MaskCOCOData/JPEGImages/maksssksksss195.png'
img = Image.open(path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
# 灰度图
img = np.array(Image.open(path).convert('L'), 'f')
plt.imshow(img,cmap="gray") #根据数组绘制图像
plt.show() #显示图像
#小Tips:jupyter notebook中plt显示灰度图异常,需要使用plt.imshow(gray,cmap="gray")方法正常显示灰度图。#原图
img = cv2.imread(path)
plt.subplot(221)
plt.imshow(img,cmap="gray")
# matplotlib 按照RGB顺序展示原图
plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
plt.subplot(222)
# cv2默认的GBR显示图
plt.imshow(img)
plt.subplot(223)
# 32*32的缩略图
plt.imshow(cv2.resize(img, (32, 32)))#图像处理示例 目标视野里比较多重叠,或者有点模糊的适用
path='dataset/MaskCOCOData/JPEGImages/maksssksksss443.png'
img = Image.open(path)
plt.imshow(img)
plt.show()
#锐化
img = img.filter(ImageFilter.SHARPEN)
img = img.filter(ImageFilter.SHARPEN)
plt.imshow(img)
plt.show()
#亮度变换
bright_enhancer = ImageEnhance.Brightness(img) # 传入调整系数亮度
img = bright_enhancer.enhance(1.6)
plt.imshow(img)
plt.show()
#提高对比度
contrast_enhancer = ImageEnhance.Contrast(img) # 传入调整系数对比度
img = contrast_enhancer.enhance(1.9)
plt.imshow(img)
plt.show() 3.2 为什么要做这些数据增强
是因为很多深度学习的模型复杂度太高了,且在数据量少的情况下,比较容易造成过拟合(通俗来说就是训练的这个模型它太沉浸在这个训练样本当中的一些特质上面了),表现为的这个模型呢受到了很多无关因素的影响。 所得出的结果就是在没有看到过的样本上对它做出预测呢就表现的不太好。

def preprocess(dataType="train"):
if dataType == "train":
transform = T.Compose([
T.MixupImage(mixup_epoch=10), #对图像进行mixup操作,模型训练时的数据增强操作,目前仅YOLOv3模型支持该transform
# T.RandomExpand(), #随机扩张图像
# T.RandomDistort(brightness_range=1.2, brightness_prob=0.3), #以一定的概率对图像进行随机像素内容变换
# T.RandomCrop(), #随机裁剪图像
# T.ResizeByShort(), #根据图像的短边调整图像大小
T.Resize(target_size=608, interp='RANDOM'), #调整图像大小,[’NEAREST’, ‘LINEAR’, ‘CUBIC’, ‘AREA’, ‘LANCZOS4’, ‘RANDOM’]
# T.RandomHorizontalFlip(), #以一定的概率对图像进行随机水平翻转
T.Normalize() #对图像进行标准化
])
return transform
else:
transform = T.Compose([
T.Resize(target_size=608, interp='CUBIC'),
T.Normalize()
])
return transform
train_transforms = preprocess(dataType="train")
eval_transforms = preprocess(dataType="eval")
# 定义训练和验证所用的数据集
# API地址:https://paddlex.readthedocs.io/zh_CN/develop/data/format/detection.html?highlight=paddlex.det
train_dataset = pdx.datasets.VOCDetection(
data_dir='./dataset/MaskVOCData',
file_list='./dataset/MaskVOCData/train_list.txt',
label_list='./dataset/MaskVOCData/label_list.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='./dataset/MaskVOCData',
file_list='./dataset/MaskVOCData/val_list.txt',
label_list='./dataset/MaskVOCData/label_list.txt',
transforms=eval_transforms)四、模型训练与评估
import matplotlib
matplotlib.use('Agg')
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
#num_classes有些模型需要加1 比如faster_rcnn
num_classes = len(train_dataset.labels)
model = pdx.det.PPYOLO(num_classes=num_classes, )
model.train(
num_epochs=70,
train_dataset=train_dataset,
train_batch_size=16,
eval_dataset=eval_dataset,
learning_rate=3e-5,
warmup_steps=90,
warmup_start_lr=0.0,
save_interval_epochs=7,
lr_decay_epochs=[42, 70],
save_dir='output/PPYOLO',
use_vdl=True)!mkdir ./output
!unzip -oq /home/aistudio/data/data101583/PPYOLO_YES.zip -d ./output
!unzip -oq /home/aistudio/data/data101583/PPYOLO_ALL.zip -d ./output
!unzip -oq /home/aistudio/data/data101583/PPYOLO_NO.zip -d ./output
!mv -f output/home/aistudio/PPYOLO_ALL output
!mv -f output/home/aistudio/PPYOLO_YES output
!rm -r output/home/注意:训练点中断后的必须重启环境,清除中断之前缓存的环境,点重启。重新运行代码块 7、20、31、32、37 即可继续往后执行 前面的加(39) 即可重新训练。
4.1 比对实验
在其他参数都相同的情况下,在没有加任何的数据增强时,mAP为38.06:

在其他参数都相同的情况下,在随机扩张,随机像素变换数据增强时,mAP为41.9:

在其他参数都相同的情况下,在加随机裁剪,随机水平翻转,短边调整,与Mixup的数据增强时,mAP为35.4:

以上对比实验说明,正确的增加数据增强时,可以小幅度提升mAP值。
(错误的数据增强会减小mAP值,玄学炼丹)

4.2 拓展介绍mAP:
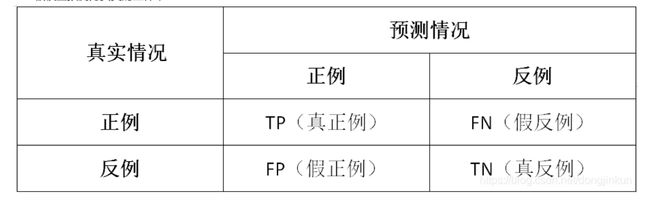
在机器学习领域中,用于评价一个模型的性能有多种指标,其中几项就是FP、FN、TP、TN、精确率(Precision)、召回率(Recall)、准确率(Accuracy)。
mean Average Precision, 即各类别AP的平均值,是AP:PR 曲线下面积。
此前先了解一下IOU评判标准:

TP、FP、FN、TN
常见的评判方式,第一位的T,F代表正确或者错误。第二位的P和N代表判断的正确或者错误
-
True Positive (TP): IoU>IOUthreshold \mathrm{IoU}>I O U_{\text {threshold }}IoU>IOUthreshold (IOU的阈值一般取0.5)的所有检测框数量(同一Ground Truth只计算一次),可以理解为真实框,或者标准答案
-
False Positive (FP): IoU
-
False Negative (FN): 没有检测到的 GT 的数量
-
True Negative (TN): mAP中无用到
查准率(Precision): Precision =TPTP+FP=TP all detections =\frac{T P}{T P+F P}=\frac{T P}{\text { all detections }}=TP+FPTP= all detections TP
查全率(Recall): Recall =TPTP+FN=TP all ground truths =\frac{T P}{T P+F N}=\frac{T P}{\text { all ground truths }}=TP+FNTP= all ground truths TP
二者绘制的曲线称为 P-R 曲线: 查准率:P 为纵轴y 查全率:R 为横轴x轴,如下图
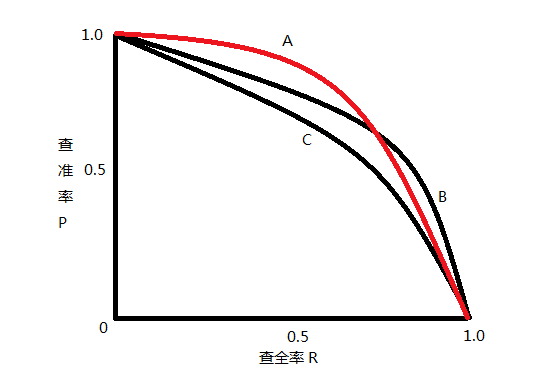
mAP值即为,PR曲线下的面积。
五、模型推理预测
使用模型进行预测,同时使用pdx.det.visualize将结果可视化,可视化结果将保存到work/PaddleDetection/output/PPYOLO/vdl_log下,载入模型推理保存图片至work/PaddleDetection/output/PPYOLO/img下。
#maksssksksss152.png maksssksksss105.png
model = pdx.load_model('output/PPYOLO_YES/best_model')
image_dir = '../../Test/'
images = os.listdir(image_dir)
for img in images:
image_name = image_dir + img
result = model.predict(image_name)
pdx.det.visualize(image_name, result, threshold=0.3, save_dir='./output/PPYOLO_YES/img')#展示模型推理结果
path = "../../Test/maksssksksss152.png"
img = Image.open(path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
path = 'output/PPYOLO_YES/img/visualize_maksssksksss152.png'
img = Image.open(path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像六、总结
本次课程主要为大家介绍了数据集获取,以及数据标注、数据划分、数据增强处理方法和简单的口罩检测实现,及其用数据增强和不用数据增强的对比实验,体现了数据增强在AI学习中的重要性,接下来有其他大佬的讲的更多更多干货的课程,也会更加深入,难度也会有所提升,想部署自己训练的模型吗,敬请关注后续更有意思的落地部署,大家加油!