基于像素特征的kmeas聚类的图像分割方案
kmeans聚类代码
将像素进行聚类,得到每个像素的聚类标签,默认聚类簇数为3
def seg_kmeans(img,clusters=3):
img_flat=img.reshape((-1,3))
# print(img_flat.shape)
img_flat=np.float32(img_flat)
criteria=(cv.TERM_CRITERIA_MAX_ITER+cv.TERM_CRITERIA_EPS,20,0.5)
flags=cv.KMEANS_RANDOM_CENTERS
ret,labels,centers=cv.kmeans(data=img_flat,K=clusters,bestLabels=None,criteria=criteria,attempts=10,flags=flags)
return labels为显示分割后的图像,将标签进行颜色映射,下述代码中,将第一类标签映射为绿色,第二类标签映射为蓝色,第三类标签映射为红色等:
def img_res(labels):
color = np.uint8([[255, 0, 0],
[0, 0, 255],
[0, 255, 0],
[255,255,0]])
res = color[labels.flatten()] # 像素映射
result = res.reshape((img.shape))
return result为探究不同聚类簇数的影响,分别采用聚类簇数clusters为2、3、4进行结果显示
RGB颜色模型下的聚类效果
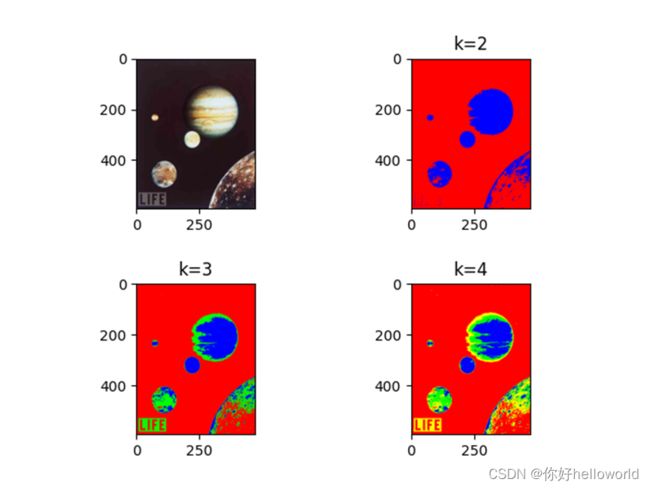

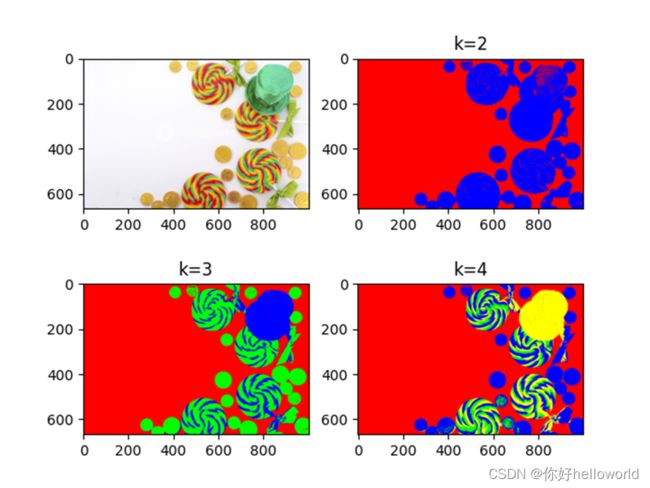
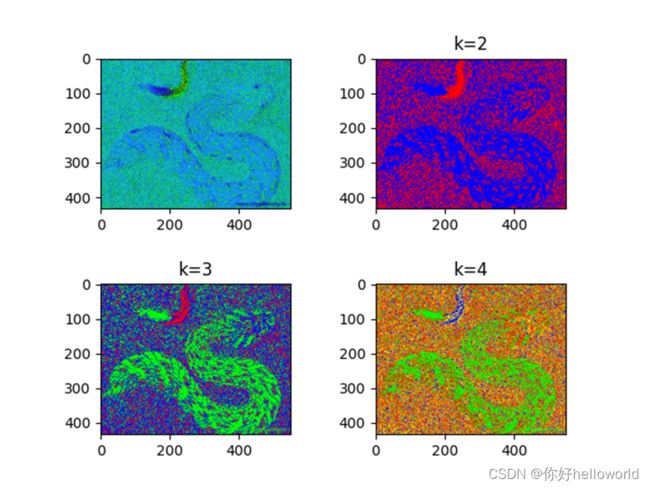
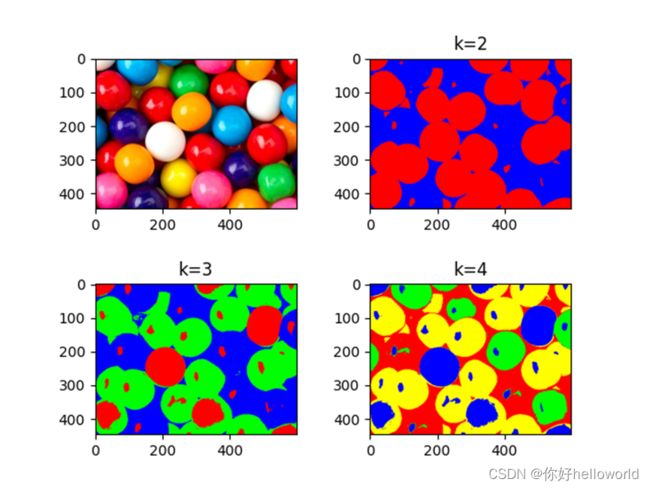
HSV颜色模型下的聚类效果

完整源码
import cv2 as cv
import matplotlib.pyplot as plt
import os
import numpy as np
def img_read(pattern=cv.IMREAD_GRAYSCALE):#默认显示灰度图
path=os.path.abspath(".")
img_path=path+r"\data\twins.jpg"
img=cv.imread(img_path,pattern)
return img
def seg_kmeans(img,clusters=3):
img_flat=img.reshape((-1,3))
# print(img_flat.shape)
img_flat=np.float32(img_flat)
criteria=(cv.TERM_CRITERIA_MAX_ITER+cv.TERM_CRITERIA_EPS,20,0.5)
flags=cv.KMEANS_RANDOM_CENTERS
ret,labels,centers=cv.kmeans(data=img_flat,K=clusters,bestLabels=None,criteria=criteria,attempts=10,flags=flags)
return labels
def img_res(labels):
color = np.uint8([[255, 0, 0],
[0, 0, 255],
[0, 255, 0],
[255,255,0]])
res = color[labels.flatten()] # 像素映射
result = res.reshape((img.shape))
return result
def plot_res(img):
clusters = [2, 3, 4] # 聚类簇数
img_list = [img] * len(clusters)
# 采取不同的聚类簇数进行聚类
labels = map(seg_kmeans, img_list, clusters)#map函数返回一个迭代器对象
labels = [np.array(label) for label in labels]
# 对结果进行颜色映射,便于输出
results = map(img_res, labels)
plt.subplot(2, 2, 1), plt.imshow(img)
for i, res in enumerate(results):
plt.subplot(2, 2, i + 2)
plt.imshow(res)
plt.title('k=' + str(i + 2))
plt.subplots_adjust(hspace=0.5)
plt.show()
if __name__=="__main__":
img=img_read(pattern=None)
img_RGB=cv.cvtColor(img,cv.COLOR_BGR2RGB)
img_HSV=cv.cvtColor(img,cv.COLOR_BGR2HSV)
plot_res(img_RGB)
plot_res(img_HSV)