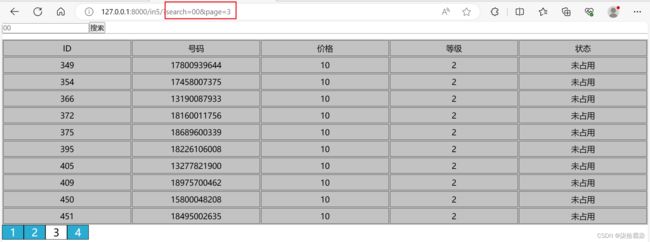
◢Django 分页+搜索
1、搜索数据
从数据库中获取数据,并进行筛选,xx__contains = q作为条件,查找的是xx列中有q的所有数据条
当有多个筛选条件时,将条件变成一个字典,传入 **字典 ,ORM会自行翻译并查找。
筛选电话号码这一列,若数据量过少,使用random库多次生成
{% load static %}
Title
ID
号码
价格
等级
状态
{% for i in data %}
{{ i.id }}
{{ i.phone }}
{{ i.price }}
{{ i.level }}
{{ i.get_status_display }}
{% endfor %}
def in4(request):
if request.method == 'GET':
data_dict = {}
search = request.GET.get('search')
print(search)
if search:
data_dict['phone__contains'] = search
# 获取数据库的数据
querset = models.User.objects.filter(**data_dict).order_by('level')
return render(request,'in4.html',{"data":querset})输入筛选条件, 点击搜索,会自动更新页面并清除输入框中的内容
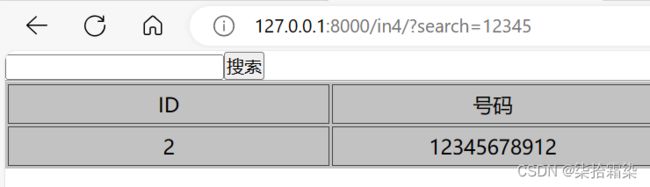
return 加入search,在input框中加入显示搜索的数据
placeholder="{{ search }}"
2、加入分页
按照上节直接加上,会导致搜索与分页不能同时存在,要对page与search进行url拼接【字典.urlencode()】
request请求传递过来的参数,不允许对其进行更改,先对其进行深拷贝,在拷贝出的数据上进行page与search两个参数的修改。
import copy
req = copy.deepcopy(request.GET)#深拷贝get请求
req._mutable = True
req.setlist(key,iter)#iter必须是可迭代对象
req.urlencode()设置一页显示的最大数据条数,获取page参数 ,对筛选后的数据进行分页截取,设置起始页与结束页至当前页的最大距离,循环设置分页的页码
import copy
req = copy.deepcopy(request.GET)#深拷贝get请求
req._mutable = True
page_size = 10
if request.GET.get('page'):
current_page = int(request.GET.get('page'))
else:
current_page = 1
page_count, count = divmod(data_count, page_size) # 共有多少页
if count:
page_count += 1
# 获取数据的起始位置与结束位置
start = int(current_page - 1) * page_size
if current_page == page_count: # 当前页是最后一页时,数据并不是page_size条数据
end = data_count
else:
end = int(current_page) * page_size
print(start, end)
data = querset[start:end]#从筛选后的数据中进行的分页数据
#设置分页最大显示
plus = 3
if current_page <= plus + 1:
start_page = 1
else:
start_page = current_page - plus
# 当前页大于等于最终点页 结束页始终为终点页 ;当前页小于终点页减plus 结束页为当前页+plus
if current_page >= page_count - plus:
end_page = page_count
else:
end_page = current_page + plus
#在筛选好的数据基础上,点击2页时不会使得search条件失去效果
page_string = ''
for i in range(start_page, end_page+1):
req.setlist('page',[i])
if i == current_page:#为活动页增加样式,突出显示当前页
page_string += f"{i}"
else:
page_string += f"{i}"
page_string = mark_safe("".join(page_string))
return render(request,'in4.html',{"data":data,"page_string":page_string})3、上一页与下一页
在点击页码的情况下增加上一页下一页的按钮,当前看到的最后页码变为第一个页码。
看见第一页不显示上一页按钮,同样最后一页也不带按钮。
处于看不见首页,但又不超过加减页时,点击上一页会跳出合适的页码,应当设置page=1,拉回跳转位置,放置page变为负数,尾页也一样。
页码满足加减页时,实行最后一个页码变第一个页码,在当前页的页码基础上 加上 或 减去 plus的2倍
def in4(request):
...
if current_page <= plus + 1:
pre = ''
else:
if current_page <= plus * 2: # 当前页处于大于1个plus,小于2个plus页时,点击上一页,跳转到第1页
req.setlist('page',[1])
pre = f'首页'
else:
req.setlist('page', [current_page - plus * 2])
pre = f'上一页'
# 下一页同上一页一致
if current_page >= page_count - plus:
next = ''
else:
if current_page >= page_count - plus * 2:
req.setlist('page',[page_count])
next = f'尾页'
else:
req.setlist('page',[current_page + plus * 2])
next = f'下一页'
4、封装
建立软件包,命名为utils
在utils中建立SplitPage.py,整合前面程序,该封装的封装,该方法体的方法体,page_size与plus进行内定义
from django.utils.safestring import mark_safe
import copy
class Splitpagenumber:
def __init__(self,request,queryset,page_size=10,plus=3):
#确实获取到page,若没有则默认为首页
if request.GET.get('page'):
self.current_page = int(request.GET.get('page'))
else:
self.current_page = 1
#拷贝get,为后续使用做准备
req = copy.deepcopy(request.GET)
req._mutable = True
self.req = req
#计算页码总数
self.page_count,count = divmod(queryset.count(),page_size)
if count:
self.page_count += 1
#为筛选好的数据进行分页
start = int(self.current_page - 1) * page_size
if self.current_page == self.page_count:
end = queryset.count()
else:
end = int(self.current_page) * page_size
self.page_data = queryset[start:end] # 从筛选后的数据中进行的分页数据
#
self.plus=plus
def html(self):
if self.current_page <= self.plus + 1:
start_page = 1
pre = ''
else:
start_page = self.current_page - self.plus
if self.current_page <= self.plus * 2:
self.req.setlist('page',[1])
pre = f'首页'
else:
self.req.setlist('page', [self.current_page - self.plus * 2])
pre = f'上一页'
if self.current_page >= self.page_count - self.plus:
end_page = self.page_count
behe=''
else:
end_page = self.current_page + self.plus
if self.current_page >= self.page_count - self.plus * 2:
self.req.setlist('page',[self.page_count])
behe = f'尾页'
else:
self.req.setlist('page',[self.current_page + self.plus * 2])
behe = f'下一页'
# 在筛选好的数据基础上,点击2页时不会使得search条件失去效果
page_string = ''
page_string += pre
for i in range(start_page, end_page + 1):
self.req.setlist('page', [i])
if i == self.current_page:
page_string += f"{i}"
else:
page_string += f"{i}"
page_string += behe
page_string = mark_safe("".join(page_string))
return page_string
5、使用封装好的分页搜索
from app02.utils.SplitPage import Splitpagenumber
def in5(request):
data_dict={}
search = request.GET.get('search')
if search:
data_dict['phone__contains'] = search
queryset = models.User.objects.filter(**data_dict)
page_obj = Splitpagenumber(request,queryset)#传递筛选好的数据
data = page_obj.page_data
page_string = page_obj.html()
context={
"search":search,
"data": data,
"page_string": page_string
}
return render(request,'in5.html',context)
{% load static %}
Title
ID
号码
价格
等级
状态
{# 插入数据条#}
{% for i in data %}
{{ i.id }}
{{ i.phone }}
{{ i.price }}
{{ i.level }}
{{ i.get_status_display }}
{% endfor %}
{{ page_string }}