爬虫项目-----拉勾网职位需求采集项目
文章目录
- 拉勾网职位需求采集项目
-
- 一、职位需求页面分析
- 二、PositionId 数据采集
- 三、项目代码
拉勾网职位需求采集项目
需求:
通过python抓取拉钩网的招聘详情,python岗位要求。
一、职位需求页面分析
- 拉钩网项目与前面爬虫项目的不同点:
之前项目是get请求,拉钩网项目是post请求。
get是要获取这个信息,post是获取这个信息的同时,在上传一部分参数。
在爬取三国演义小说时,我们是先爬取目录页内容,得到章节名和详情页链接;再通过分析去访问详情页链接获取详情页内容。
但在拉钩网项目中,原html代码中是找不到详情页链接的,此时我们需要通过分析XHR对象来获取需求。
- 页面分析:
进入拉钩网官网,输入python出现所有相关的职位,点击每一个职位进去分析每个职位详情页的网址特点。
通过观察可以发现,拉勾网的职位页面详情是由 http://www.lagou.com/jobs/ PositionId.html 组成。
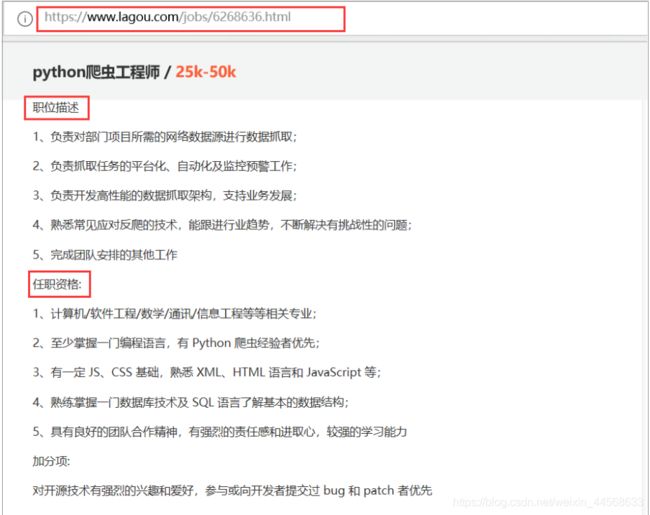
而 PositionId 可以通过分析 Json 的 XHR 获得。
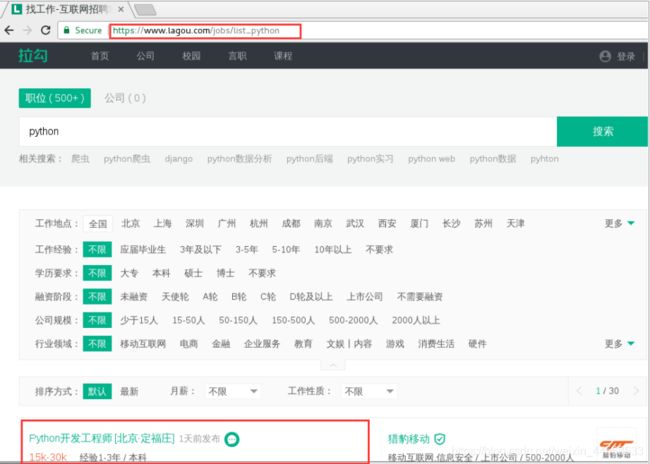
知道了数据的源头,接下来就按照常规步骤包装 Headers ,提交 FormData 来获取反馈数据。
二、PositionId 数据采集
注意:
- 拉勾网反爬虫做的比较严,请求头多添加几个参数才能不被网站识别。
- 我们找到真正的请求网址,发现返回的是一个 JSON 串,解析这个 JSON 串即可,而且注意是 POST传值,通过改变 Form Data 中 pn 的值来控制翻页。
XHR:XMLHttpRequest对象用于和服务器交换数据。
当我们进入开发者模式,点击网络,XHR获取响应后
这个请求里面包含了
真实的URL( 浏览器上的 URL 并没有职位数据,查看源代码就可以发现这一点)、
POST 请求的请求头Headers 、
POST 请求提交的表单 Form Data (这里面包含了页面信息 pn 、搜索的职位信息 kd )
真实的URL获取:

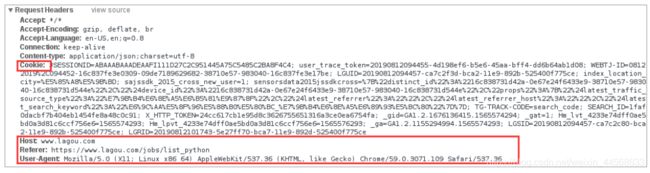
请求头信息
我们需要构造的请求头Headers信息,如果这里没有构造好的话,容易被网站识别为爬虫,从而拒绝访问请求。
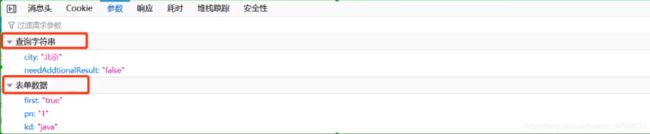
表单信息
发送POST请求时需要包含的表单信息 Form Data 。
返回的JSON数据
发现需要的职位信息在 content –> positionResult –> result 下,其中包含了工作地点、公司名、职位等信息。 我们只需要保存这个数据就可以了。
三、项目代码
1.先获取拉钩网所有岗位API接口的响应信息(response)
通过post并传入参数和数据访问url:https://www.lagou.com/jobs/positionAjax.json?=false
2.在获取的页面解析我们需要的所有岗位的ID号,yeild返回。
3.把ID传进解析岗位详情的函数里,先下载岗位详情页面,然后解析我们想要的岗位要求信息。
import time
import requests
from fake_useragent import UserAgent
from lxml import etree
ua = UserAgent()
def download_positions(kd="python", city="西安", page=1):
"""
获取拉勾网所有的岗位API接口的响应信息
:param kd: 岗位名称/关键字
:param city: 城市
:param page: 页码
:return: position_id
"""
# 拉勾网访问的网址,并不是Ajax的网址
# old_url = 'https://www.lagou.com/jobs/list_python'
# 真实的API接口的网址(通过F12开发者模式分析出来的)
url = 'https://www.lagou.com/jobs/positionAjax.json?=false'
# url提交的参数信息, http://xxxxx/?param1=value1¶m2=value2
params = {
'city': city,
# 'needAddtionalResult': 'false',
}
# url以POST方式提交的信息(参数分析出来的)
data = {
# 'first': 'true',
'pn': page,
'kd': kd
}
# 头部信息, 为了防止拉钩反爬策略的
headers = {
'UserAgent': ua.random,
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'TE': 'Trailers',
'X-Requested-With': 'XMLHttpRequest',
'Connection': 'keep-alive'
}
# 以POST方式请求网址并返回响应
response = requests.post(url=url, params=params, data=data)
data = response.json()
print(data)
if data.get('status') == False:
raise Exception("获取职位失败: %s" % (response.text))
else:
return response
def parse_position_ids(response):
"""
根据页面信息解析所有岗位的ID号
:param response:
:return: 字典
"""
# 响应的信息是json格式, 通过json方法自动化解析json字符串为python对象
ajax_data = response.json()
content = ajax_data.get('content')
positionResults = content.get('positionResult').get('result')
for position in positionResults:
yield {
'name': position.get('positionName'),
'positionId': position.get('positionId')
}
def download_detail(id):
"""下载详情页页面"""
url = 'https://www.lagou.com/jobs/%s.html' % (id)
headers = {
'UserAgent': ua.random,
'Origin': 'https://www.lagou.com',
}
try:
response = requests.get(url)
except Exception as e:
print("采集职位详情页失败: " % (str(e)))
else:
return response
def parse_position_detail(id):
"""解析详情页页面并提取岗位详情内容"""
response = download_detail(id)
# print(response.text)
# 使用解析器解析页面的岗位详情(正则、Xpath、BS4)
html = etree.HTML(response.text)
# 通过类名寻找class="job-detail"的节点, xpath('string(.)')获取节点所有的文本信息(标签自动删除)
job_detail = html.xpath('//div[@class="job-detail"]')
if job_detail:
return job_detail[0].xpath('string(.)')
# print(job_detail)
return ''
def position_ids():
response = download_positions()
position_ids = parse_position_ids(response)
for id in position_ids:
print(id)
# job_detail=parse_position_detail(id)
# print(job_detail)
def position_detail_id():
id = '7061310'
job_detail = parse_position_detail(id)
print(job_detail)
if __name__ == '__main__':
# position_ids()
# position_detail_id()
citys = ['上海', '北京', '西安']
pages = 10
# kds = ['Python', '产品经理', 'HR']
for city in citys:
# for kd in kds:
for page in range(pages):
page = page + 1
print("正在采集[%s]城市的第[%s]页岗位信息......" % (city, page))
response = download_positions(city=city, page=page)
time.sleep(3)
position_ids = parse_position_ids(response)
for item in position_ids:
# print(item)
id = item['positionId']
name = item['name']
job_detail = parse_position_detail(id)
print(job_detail)
因为网站反爬虫太严重,这里测试先打印每个职位的id,在打印一个岗位的详情。
运行结果:


下面是采集的前三页的岗位信息:
F:\python\Anaconda3\python.exe F:/ziliao/python_kaifa/my_code/14_Spider/SpiderProject/spider_file/26_拉勾网职位分析(职位画像).py
正在采集[上海]城市的第[1]页岗位信息......
1. 熟练掌握python基础语法2. 熟练使用django restframework框架3. 熟练使用pythton redis mysql MongoDB操作4. 熟练使用celery异步框架5. 熟练使用linux操作系统 6. 有运维工作经验优先7. 熟练使用vue框架,有前端html、JS等相关经验8. 至少使用DRF 和VUE 有一个完整的项目经验三年工作经验以上优先
https://www.lagou.com/jobs/7070888.html
https://www.lagou.com/jobs/5977096.html
https://www.lagou.com/jobs/4088383.html
https://www.lagou.com/jobs/6832150.html
https://www.lagou.com/jobs/6816417.html
https://www.lagou.com/jobs/7033381.html
https://www.lagou.com/jobs/6848831.html
https://www.lagou.com/jobs/6922468.html
职位描述:
1.负责内部系统的设计和开发;
2.积极了解业界相关新技术及发展趋势,有选择的引进来加强完善平台架构与功能;
3.配合前端开发人员进行应用及系统整合;
任职要求:
1.计算机相关专业全日制统招本科及以上学历;
2.精通Python,3年以上Python开发经验,熟悉基于Python代码的性能分析和优化;
3.熟悉zabbix/ganglia/Prometheus/grafana等监控的组合及使用,有zabbix监控插件开发经验;
4.具备优秀的编程习惯,具备较强的研发与设计能力;
5.具备缜密的逻辑思维,具备优秀的分析、解决问题的能力;有技术管理经验者优先;
6.具备良好的服务意识、责任心、较强的学习能力、优秀的团队沟通与协作能力、能承受一定的工作压力。
https://www.lagou.com/jobs/6689612.html
https://www.lagou.com/jobs/7034220.html
https://www.lagou.com/jobs/6656807.html
岗位职责:
1、负责公司用户端业务接口的功能开发和代码维护,能独立完成子系统和功能模块开发,编写完整的接口文档;
2、根据需求制定技术方案,项目计划以及开发,学习研究最新技术,并将之应用到工作当中;
3、根据产品需求,进行系统设计和编码, 持续对系统架构进行改造和优化;
4、具备良好的编码习惯,结构清晰,命名规范,逻辑性强,代码冗余率低。
岗位要求:
1、5年及以上Python开发经验,熟练Flask,Django, Sanic, Sqlalchemy,Celery等主流框架, 深入理解框架实现原理及特性, 熟练使用python的常用库, 熟悉网络爬虫;
2、熟悉Internet常用协议,如HTTP、TCP/IP、熟悉MySQL、Redis等,具备数据库应用、设计能力;
3、理解并能应用RESTFul规范,具备较强的编程能力和良好的编码风格;
4、熟练掌握Python语言及web相关技术栈;
5、善于团队合作与管理,对新技术有强烈的探索欲望,责任心强,能够承受工作压力,有强烈的责任心;
6、了解异步框架Async,集群与负载均衡,消息中间件等技术;
7、不了解异步框架的请慎投,谢谢!
https://www.lagou.com/jobs/6279719.html
职责描述:
本职位包含初级到tech lead级别, 参与公司各类(to B or to C)数据产品后台系统的研发
* 数据工程方向:
* 数据收集产品: 包括但不限于爬虫, 数据源对接
* 数据处理产品: 包括但不限于ETL, 任务调度
* 系统开发方向:
* 数据分析产品: 包括但不限于数据处理, 可视化以及协同操作
* 地图处理产品: 包括但不限于地图服务器的开发(静态瓦片, 矢量瓦片, 地理交互, 3d地图)
* 系统应用产品: 包括但不限于面向c端应用和内部效率工具
* 系统运维方向:
* 容器化部署(swarm or k8s), CI/CD
* 大规模私有化管理
* 系统监控 (promethues)
* 内部运营系统开发
* DBA(PostgreSQL, redis, promethues, elk, rabbitmq, kafka)
### 任职要求:
* 扎实的数据结构与基本算法基础
* 数学基础良好
* 熟悉 RESTFUL API, HTTP 以及 Linux 开发
* 熟悉 Python3 (或者精通某一门编程语言并有意向python发展)
* 英语阅读以及代码交流能力良好
* 熟悉 Git 代码管理
* 开源爱好者, 有解决方案搜索能力以及代码贡献热情
### 加分项:
精通以下一项以及熟练使用开源库
* 网络开发框架: Django, Flask, Tornado, etc
* 即时通讯开发: websocket (SocketIO), etc
* 数据处理: Pandas, Numpy, Scipy, etc
* 全栈开发经验 或 API开发经验
* 精通SQL, 有 OLAP 和 GIS 开发经验
* 地图(瓦片)服务器开发经验
* 熟悉多种数据库, 包括但不限于 Redis, PostgreSQL+Postgis, ELK stack, etc
* 熟练使用C++以及开发Python binding
* 任务(流)处理系统开发, Storm, OpenFaas, dramatiq, etc
### 技术面试内容
* 课堂项目/毕业论文介绍说明(应届)
* 过往工作经验/项目经验介绍说明
* 数据结构与基础算法
* 白板算法题
* 系统设计
* 时长30min~2hour, 2~3轮
https://www.lagou.com/jobs/6800450.html
职位职责:
1. 负责后台接口的设计和开发;
2. 设计数据接入的处理流程,以便从不同的数据源获取数据,并开发相关程序及服务;
3. 根据需求,完成数据可视化。
职位要求:
1. 有5年以上后台开发经验,本科及以上学历,211,985学校毕业优先;
2. 熟练使用Unix/Linux操作系统,熟悉常用的shell/python,必须不局限于某一项特定的开发技术,需要能够根据环境快速适应新技术;
3. 熟悉数据库技术,如MSSQL、Mysql,熟悉SQL查询的优化;
4. 有强烈的责任心,和良好的团队协作能力。
正在采集[上海]城市的第[2]页岗位信息......
任职资格:
-计算机本科及以上学历,两年以上开发经验;
-精通Python(ansible)或前端开发(Javascript / HTML / XML / JSON / HTML5 / JQuery)三者其一,熟悉其他语言可加分;
-拥有中大型项目、系统设计开发经验;
-有产品运维经验者、自动化运维开发经验者优先;
-熟悉Linux操作系统、网络原理;
-熟悉PASS、LaaS、DB管理系统、虚拟化技术等经验最佳;
-有良好的团队合作意识,工作态度认真、负责,能够承受一定的工作压力
岗位描述:
1.负责并持续优化算法和AI底层模块封装的研发(类型:图像提取、图像匹配、图像内容分析、图像设计质量等);
2.理解算法与应用之间的封装和整合,负责将模块进行产品化的架构设计、维护和研发。
3.搭建基于WEB内部机器学习训练平台,完成算法效率的提升和基础能力沉淀
岗位要求:
1.两年以上的Python开发经验,熟练使用python常用库,全日制本科以上学历,硕士优先;
2.掌握Django, Tornado, Flask等一种主流框架,深入理解框架实现原理及特性;
3.熟悉Python的高级特性,具备良好的编码习惯,深入理解各种设计模式和应用场景;
4.数学功底和建模能力强,熟悉机器学习领域的常见原理以及AI适用场景、优点、缺点以及弥补办法;
5.熟悉Internet常用协议,如HTTP、TCP/IP、熟悉RESTful规范;
6.掌握至少一种关系型数据库,了解Docker运维知识;
7.有一定外文文献的阅读能力,对计算机视觉、计算机图形学有极大兴趣者优先。
工作职责:
1. 基于Python的AI产品设计与开发;
2. AI产品持续优化;
3. 按照项目计划,按时提交高质量的代码,完成开发任务;
4. 积极参与工作相关技术的研究;
任职要求:
1. 计算机或相关专业本科或以上学历,4年以上相关工作经验,具备丰富的python实际项目开发经验
2. 熟悉并掌握Flask/Django等web框架,了解架构设计和实现原理
3. 熟悉数据库操作,拥有MySQL/MongoDB/Redis等使用经验
4. 了解JavaScript/HTML5/WebSocket等技术
5. 具有Linux/Unix下操作经验
6. 具备良好的团队协作精神,以及积极主动的学习和交流能力
7. 熟悉Git,有开源项目贡献者优先
8. 了解机器学习,有常见深度学习框架(如TensorFlow,PyTorch等)使用经验者优先
9. 了解虚拟化技术,熟悉docker者优先
岗位职责:
1.全日制本科及以上,计算机相关专业毕业;3年以上Python开发经验;
2.精通Python语言,熟练掌握PythonWeb服务搭建部署流程;
3.熟悉常见的Python服务框架,包括但不限于Django, Tornado,Flask等;
4.熟悉常见的中间件,包括但不限于RabbitMQ、Redis、Kafka、Nginx等;
5.熟悉常见的存储方案,包括但不限于MySQL、MongoDB、HBase、Ceph等;
6.熟悉常用的开发工具,如Git、SVN等;
7.有良好的代码风格和开发习惯,懂得单元测试原理;
其他要求:
1.良好的沟通能力;
2.性格积极乐观,诚信,有较强的语言表达能力,具备强烈的进取心、求知欲及团队合作精神。
补充:本岗位可接受远程面试,视频为主,电话为辅。**当前,足不出户,安心求职!
补充:本岗位可接受远程面试,视频为主,电话为辅。**当前,足不出户,安心求职!
https://www.lagou.com/jobs/7044379.html
1. 熟练掌握Python,有扎实的编程功底,熟悉面向对象和数据结构。同时了解Java或其他语言有加分。
2. 熟悉Numpy, Pandas, Flask/ FastAPI,熟悉Mysql,了解NoSQL类型数据库(MongoDB/Redis);
3. 微服务框架,消息中间件(Kafka, RabbitMQ)者为佳,
4. 了解Hadoop/Map-Reduce/Spark,有大数据处理经验者也有加分,但这些都不是必须的。
5. 执行力好,会合理排定个人工作计划,并控制风险,同时有良好的团队合作能力
https://www.lagou.com/jobs/7044065.html
正在采集[上海]城市的第[3]页岗位信息......
职责描述:
1、基于机器学习, 并结合自然语言处理技术,研发及优化智能聊天机器人等解决方案;
2、发布相关产品,不断迭代产品效果。
任职要求:
1、本科及以上学历,计算机科学,数学,统计学等相关专业;
2、3年以上相关工作经验,对面向对象编程、设计模式、软件工程等有较深入的理解,对产品交付和用户体验有高要求,热悉sanic框架者优先。
3、了解TCPIP、网络、多线程。多进程。协程编程、异步编程模型,了解线程安全和线程可见性,能编写正确且高效的并发代码;
4、熟悉计算机网络的基本知识及互联网上常见的通讯协议,熟悉常用数据结构与算法、Socket编程、多线程编程等;
5、熟练掌握mongodb数据库,了解一些非关系型数据库;
6、有较强的自学能力、分析及解决问题能力,良好的团队合作能力以及需求分析能力;
7、有很强的学习能力,有主动性和上进心,能承担压力;
https://www.lagou.com/jobs/6805881.html
岗位职责:
1. 开发大智慧App和PC客户端上推荐相关业务的接口
2. 开发个性化消息推送业务
3. 开发个性化信息流业务
岗位要求:
1. 熟悉Python的基本数据结构、能够开发多线程、多进程或异步的程序,了解装饰器、生成器等常用技巧
2. 能够熟练使用Falcon/Sanic/Flask/Django中任意一种框架开发Web服务
3. 熟悉MySQL/Mongo/Redis/Kafka的使用和基本的性能优化
4. 了解Etcd,了解docker容器技术
5. 熟悉Elasticsearch搜索技术的优先
https://www.lagou.com/jobs/7043456.html
https://www.lagou.com/jobs/6899512.html
加入 DaoCloud 会负责:
1.负责开发支撑Daocloud基于kubernetes的容器云平台的核心组件
2.负责基于 Python 的 web 快速开发、相关优化及产品部署
3. 搭建系统开发环境,完成系统框架和核心代码的实现,负责解决开发过程中的技术问题
4. 参与 Python 技术的相关产品规划、需求、设计、开发及测试等研发工作
5. 协助售前团队,服务客户,解决应用运行在容器平台的技术问题
DaoCloud 对你的期望:
1. 本科及以上学历,计算机相关专业
2.熟悉或精通 Python 语言,有两年以上后台开发经验
3.熟悉web开发框架(Django/Tornado/Flask),熟悉 Linux 操作系统及 shell 编程
4. 熟悉 MySQL、Redis、Mongo等常见数据库,具有数据库开发和设计能力
5. 了解异步框架、集群与负载均衡,消息中间件,容灾备份等技术
6. 熟悉代码构建打包流程,熟练使用 Jenkins 等常用 CI/CD 管理软件
优先条件:
1. 有全栈开发经验或大型在线服务开发经验者优先
2. 有从事过云平台、云计算方面开发经验者优先
3. 熟悉 Docker和 Kuberenetes 等容器相关技术者优先
https://www.lagou.com/jobs/4075805.html
职位描述
1. 负责小程序或公众号的后台开发;
2. 参与相关大数据产品的开发;
3. 根据新需求进行方案设计和技术文档的编写;
4. 相关软件模块的完善及性能调优工作。
任职要求
1. 本科及以上学历,3年以上互联网开发经验;
2. 精通基于python的web端的程序设计。 至少熟悉flask、tornado或django中的一种mvc框架;
3. 精通SQL编写,熟悉数据库技术,了解redis缓存技术;
4. 熟悉Linux开发环境;
5. 熟悉JavaScript、HTML、CSS;
6. 思维严密,执行力强, 能承受一定的工作压力,有团队合作精神,能够在工作中有效沟通交流。
https://www.lagou.com/jobs/7044517.html
https://www.lagou.com/jobs/7015992.html
https://www.lagou.com/jobs/6316569.html
岗位职责:
1、负责问卷网平台服务端设计和代码实现 ;
2、优化现有产品的功能和体验细节 ;
3、对现有平台进行性能优化 ;
4、积极调研新技术,随时准备用于产品 ;
岗位要求:
1、全日制统招本科及以上学历,计算机、软件工程、信息管理、计算机应用相关专业 ;
2、5年及以上Web服务器端开发经验,有Python经验佳,Java亦可;
3、有丰富的数据库建模经验,有丰富的性能优化经验 ;
4、有扎实的技术功底,做到知其然并知其所以然,能读懂python主流框架源码 ;
5、熟悉分布式系统的设计和应用,熟悉分布式、缓存、消息等机制;能对分布式常用技术进行合理应用,解决问题;
6、具有较深的技术架构思维,确保设计的技术方案、开发的代码有较高性能、质量保障、扩展性,前瞻性 。
https://www.lagou.com/jobs/6531220.html
https://www.lagou.com/jobs/4042218.html
https://www.lagou.com/jobs/7029947.html
职位描述:
1.自动化运维相关内容的开发,规范相关操作流程;
2.负责相关运维工具或脚本开发;
3.对Linux系统下相关应用进行监控工具的开发;
4.积累并规范化系统运维开发的最佳实践并文档化。
任职资格:
1.本科及以上学历,计算机相关专业优先;
2.诚实、正直,有责任心;
3.熟悉Linux系统,有1年以上系统运维开发工作经验优先;
4. 3年以上Python开发运维经验,熟练运用Python和相关框架进行开发进行自动化测试
5. 熟悉Linux操作系统,掌握Shell/PHP/Perl等至少一种脚本语言;
6. 参与或部分参与过自动化运维相关工作,对运维自动化有一定了解。
https://www.lagou.com/jobs/7073467.html
1.精通Python开发,3年以上Python开发经验,熟悉基于Python代码的性能分析和优化,必须会算法。
2.精通Flask/Django或者其他Python Web开发框架,熟悉MVC架构,熟悉常用设计模式
3.熟练使用mysql,熟悉mysql的各种存储引擎,熟悉索引工作原理;
4.熟悉 celery 等队列工具的开发使用;
5.有运维自动化、监控系统、应用发布系统、CMDB配置管理系统等运维开发或者维护经验优先;
6.熟悉开源监控软件Nagios/Zabbix/Cacti/Prometheus一种或以上的部署和应用经验优先
7.熟悉 Web 前端技能,有vue使用经验者优先;
7. 熟悉多种开源组件有的kafka、redis 、RabbitMq 使用经验优先
8. 熟悉Linux系统,具备编写shell脚本能力
9. 熟悉网络基础、TCP/IP、HTTP等协议,熟悉操作系统原理