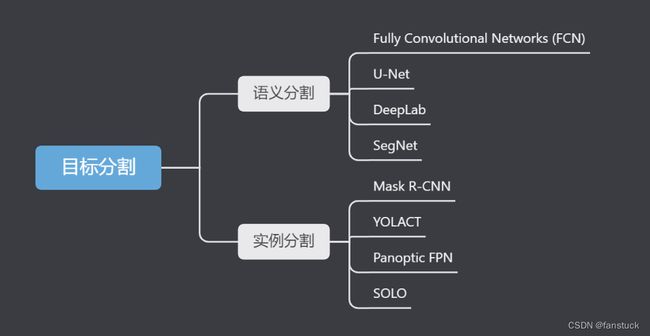
目标分割技术-语义分割总览
前言
博主现任高级人工智能工程师,曾发表多篇SCI且获得过多次国际竞赛奖项,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。目的就是为了让零基础快速使用各类代码模型,每一篇文章都包含实战项目以及可运行代码。欢迎大家订阅一文速学-深度学习项目实战
目标分割技术-语义分割总览
目标分割是计算机视觉领域的一个重要任务,旨在从图像或视频中准确地分割出特定的目标或对象。与目标检测关注物体位置和边界框不同,目标分割要求精确地识别并标记目标的每个像素,实现对目标的像素级别理解。
定义
我们可以把目标分割拆解为两个技术实现部分:一为语义分割、二为实例分割。对于图像分类、目标检测和图像分割而言:
- 图像分类旨在判断该图像所属类别。
- 目标检测是在图像分类的基础上,进一步判断图像中的目标具体在图像的什么位置,通常是以外包矩形(bounding box)的形式表示。
- 图像分割是目标检测更进阶的任务,目标检测只需要框出每个目标的包围盒,语义分割需要进一步判断图像中哪些像素属于哪个目标。但是,语义分割不区分属于相同类别的不同实例,也就是说如果存在目标物体重叠的情况,语义分割只会识别为一个共同的像素目标:
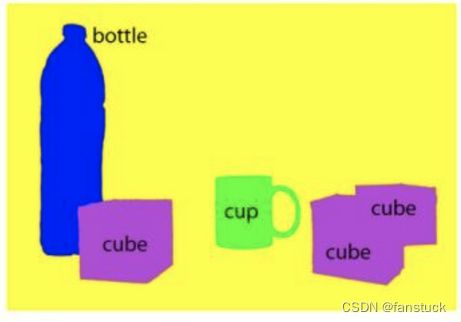
,而实例分割需要区分开来: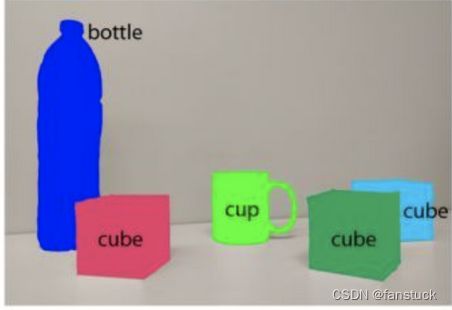
那么我们再对图像分割总体定义了解:在计算机视觉领域,图像分割(Object Segmentation)指的是将数字图像细分为多个图像子区域(像素的集合)的过程,并且同一个子区域内的特征具有一定相似性,不同子区域的特征呈现较为明显的差异: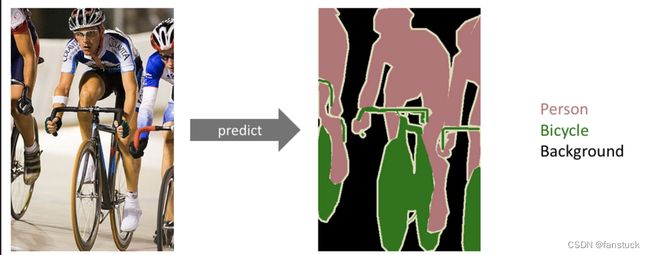
图像分割的目标就是为图像中的每个像素分类。应用领域非常的广泛:自动驾驶、医疗影像,图像美化、三维重建等等:

原理
简单来说,我们的目标是输入一个RGB彩色图片(height×width×3)或者一个灰度图(height×width×1),然后输出一个包含各个像素类别标签的分割图(height×width×1)。如下图所示:
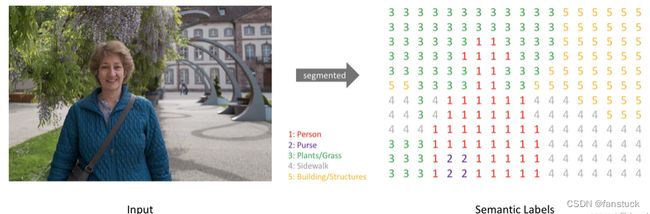
我们肉眼可以很明显区分目标物体,但是想让计算机实现目标切割,只能输出为图片数据形式我们再进行处。在图像处理部分,我们知道图片由三维数组RGB形式构成,不同像素块之间会存在些许差异,也就是说我们可以利用这些像素差异来实现区分不同的目标物体,但是如果存在像素之间颜色差异不大,那么久比较难区分不同的物体。预测目标可以采用one-hot编码,即为每一个可能的类创建一个输出通道。也就是把上述Semantic Labels的矩阵不同数字给割裂出来:
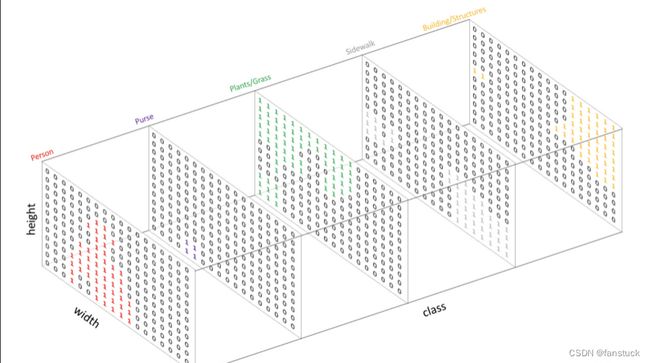
当将预测结果叠加到单个channel时,它可以给出一张图像中某个特定类的所在区域:

对于上述目标分割图像较为感兴趣的可以去看看PASCAL VOC数据集,PASCAL VOC(Visual Object Classes)数据集是一个广泛用于目标检测、图像分类和语义分割等计算机视觉任务的数据集。该数据集由英国牛津大学计算机视觉实验室于2005年至2012年发布,并由标准化的图像注释和评估协议定义: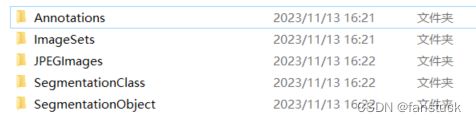
- JPEGImages中存放图片文件
- imagesets中的segmentation中记录了用于分割的图像信息
- SegmentationClass中是语义分割的标注信息
- SegmentationObject中是实例分割的标注信息

实现技术
了解以上基本概念之后,我们可以来了解一些实现目标分割的技术了,依然是分为两块:语义分割和实例分割来讲解。
语义分割(Semantic Segmentation)
定义: 语义分割旨在将图像中的每个像素分配到对应的语义类别,而不区分不同的实例。例如,在一张包含汽车、行人和道路的图像中,语义分割的目标是将图像中的每个像素标记为汽车、行人或道路。前面一段文章已经描述的比较具体了,不了解的再去看看前面的图片就好了。
算法: 一些常见的语义分割算法包括:
- Fully Convolutional Networks (FCN)
- U-Net
- DeepLab
- SegNet
这些算法挨个介绍,以后将陆续进行实现。传统的基于CNN的语义分割方法为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入,用于训练和预测。但是此类算法都通常有三个比较大的弊端:
- 计算存储效率低下,存储空间占用很高,比如对一个像素使用的图像块的大小为15×15,需要不断滑动窗口,每次滑动窗口之后再给CNN进行判别分类。因此,所需的存储空间根据滑动窗口的次数和大小需求很大。
- 计算效率低下,相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。
- 分类性能受限,像素块的大小限制了感受野的大小。通常像素块的大小比整幅图像的大小小很多,只能提取一些局部特征。
后续算法在CNN上进行不断修改优化后形成了现在的语义分割算法生态。
Fully Convolutional Networks (FCN)
Fully Convolutional Networks(FCN)是一种用于图像分割的深度学习架构,由Jonathan Long、Evan Shelhamer和Trevor Darrell于2015年提出。相较于传统的卷积神经网络(CNN)架构,FCN的创新之处在于它将全连接层替换为全卷积层,从而使网络能够接受任意大小的输入图像,并输出对应大小的分割结果。
通常,传统的CNN结构在经过卷积层提取图像特征之后,会通过若干全连接层将这些特征映射成一个固定长度的特征向量。这种结构适用于图像级的分类和回归任务。举例来说,AlexNet等经典的CNN模型,特别是在图像分类任务(如ImageNet分类)中,最终的目标是得到整个输入图像的一个数值描述,通常是一个概率分布向量。
以AlexNet为例,其结构包括卷积层、池化层和全连接层。在卷积和池化层中,图像的局部特征被提取并逐渐减小空间维度。而在全连接层中,这些特征会被压缩成一个固定长度的向量,最终输出分类的概率分布。这样的设计使得模型能够在高层次上理解整个图像,并输出关于整个输入图像的全局信息,这对于图像分类是合适的。然而,对于一些需要更细粒度的信息,比如目标的位置或者像素级的分割等任务,这样的结构可能显得不够灵活。
与此不同,全卷积网络(FCN)等结构则通过替代全连接层为全卷积层,使得模型能够处理变尺寸的输入图像,并且能够输出对应大小的分割结果。这种结构更适用于像素级的任务,如语义分割或实例分割。可以理解起来比较抽象,我们看图:
以传统的VGG卷积网络为例:
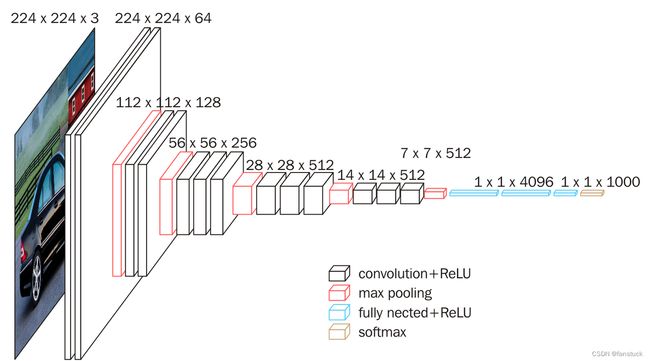
在经历了卷积和池化之后,最后经过全连接层将7x7x512的特征压缩成一个固定长度4096的一维向量。我们再来看看FCN网络结构:
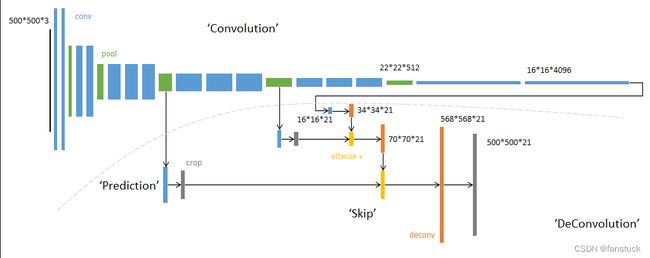
FCN网络结构主要分为两个部分:全卷积部分和反卷积部分,没有全连接层,也就是说不需要固定长度的特征向量,全卷积部分为一些经典的CNN网络(如VGG,ResNet等),用于提取特征,主要还是通过反卷积层来进行实现语义分割的,反卷积层(Deconvolutional Layer)通常用于上采样操作,将低分辨率的特征图映射到与输入图像相同的分辨率,以便生成像素级别的分割结果。然而,需要注意的是,术语“反卷积”在这里的含义与传统卷积的操作方向相反。
上采样 Upsampling:
在卷积过程的卷积操作和池化操作会使得特征图的尺寸变小,为得到原图像大小的稠密像素预测,需要对得到的特征图进行上采样操作。可通过双线性插值(Bilinear)实现上采样,且双线性插值易于通过固定卷积核的转置卷积(transposed convolution)实现,转置卷积即为反卷积(deconvolution)。在论文中,作者并没有固定卷积核,而是让卷积核变成可学习的参数。转置卷积操作过程如下,下图中蓝色是反卷积层的input,绿色是反卷积层的output,元素内和外圈都补0的转置卷积:
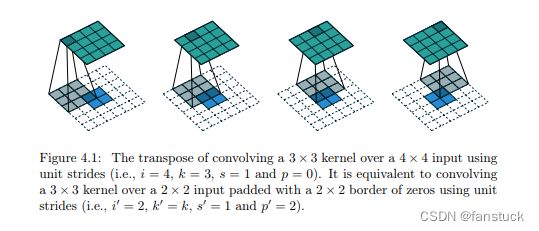
从上图可以看到卷积把2×2原图扩大了两圈,再通过3×3的卷积核,卷积结果图像被增大为4×4的大小。卷积后,结果图像比原图大:称之为full卷积,其实full卷积就是反卷积的过程,通过full卷积将原图扩大,增大原图的分辨率,所以对图像进行反卷积也称为对图像进行“上采样”。因此,也可以很直接地理解到,图像的卷积和反卷积并不是一个简单的变换、还原过程,也就是先把图片进行卷积,再用同样的卷积核进行反卷积,是不能还原成原图的,因为反卷积后只是单纯地对图片进行扩大处理,并不能还原成原图像。
反卷积层的目标是通过上采样将抽象的语义特征还原到更接近输入图像的原始分辨率。这有助于保留局部细节,提高分割的精度。在TensorFlow中,反卷积操作通常通过Conv2DTranspose层实现。这个层与正常的卷积层相似,但它执行的是转置卷积(transposed convolution),也被称为分数步长卷积(fractionally strided convolution)或反卷积。该操作通过在输入之间插入零元素(填充)来实现上采样:
from tensorflow.keras.layers import Conv2DTranspose
# 假设输入特征图大小为 (4, 4, 256)
input_feature_map = Input(shape=(4, 4, 256))
# 反卷积层
upsampled_feature_map = Conv2DTranspose(128, (3, 3), strides=(2, 2), padding='same')(input_feature_map)
strides=(2, 2)表示在高度和宽度方向上的步幅为2,实现了对输入特征图的上采样操作。
U-Net
U-Net是一种用于图像分割任务的深度学习架构,由Ronneberger等人于2015年提出。U-Net之所以得名,是因为其网络结构呈U形状。它在医学图像分割等领域取得了很大成功,特别适用于小样本、不平衡数据等情况。医务人员除了想要知道图像的类别以外,更想知道的是图像中各种组织的位置分布,而U-net就可以实现图片像素的定位,该网络对图像中的每一个像素点进行分类,最后输出的是根据像素点的类别而分割好的图像。
U-Net的网络结构分为两个主要部分:编码器(Encoder)和解码器(Decoder),中间是一个U形状的结构连接它们。该结构保留了图像分辨率的信息,有助于更好地捕获图像的局部和全局特征。
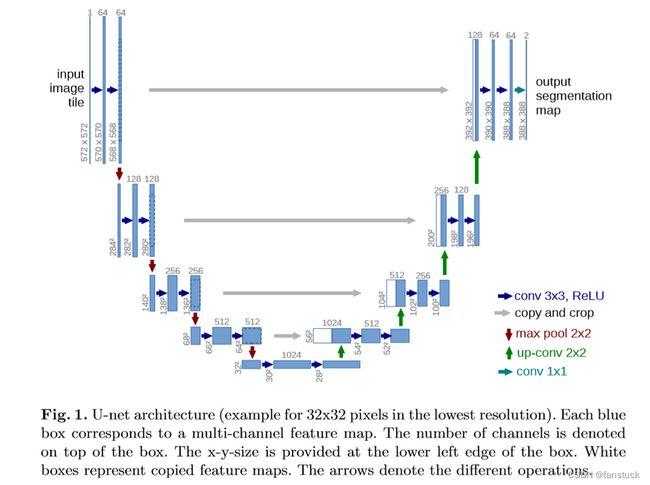
上图箭头分别代表一下转换操作:
- 蓝色箭头:利用3×3的卷积核对图片进行卷积后,通过ReLU激活函数输出特征通道;
- 灰色箭头:对左边下采样过程中的图片进行裁剪复制;
- 红色箭头:通过最大池化对图片进行下采样,池化核大小为2×2;
- 绿色箭头:反卷积,对图像进行上采样,卷积核大小为2×2;
- 青色箭头:使用1×1的卷积核对图片进行卷积。
具体网络架构和操作如上图展示。该U-net网络一共有四层,分别对图片进行了4次下采样和4次上采样。下章搭建语义分割将详细讲述每一层的网络操作,有代码更加具体。
DeepLab
DeepLab是由Google Research开发的一种用于图像分割任务的深度学习架构,其目标是实现高质量的语义分割。DeepLab的一系列版本不断引入新的技术和改进,其中最重要的是DeepLabV3和DeepLabV3+。
DeepLabV1:
- 空洞卷积(Atrous Convolution): DeepLabV1引入了空洞卷积,也称为膨胀卷积,用于扩大感受野,以更好地捕捉图像中的上下文信息。
- 多尺度处理: 在不同的空洞率下应用多个卷积核,以处理不同尺度的信息。
DeepLabV2:
- 条件随机场(Conditional Random Field,CRF): 引入了全连接CRF用于对分割结果进行精炼,以改善边界的细节。
DeepLabV3:
- 空洞卷积的变体: 使用了带有不同空洞率的空洞卷积模块,形成了深层空洞卷积网络(ASPP)结构。ASPP模块并行地运用多个不同的空洞率,以捕捉多尺度的上下文信息。
- 多尺度金字塔池化(ASPP): 用于有效地处理不同尺度的特征,提高分割性能。
- 全局平均池化: 使用全局平均池化层来处理不同尺寸的输入图像。
DeepLabV3+:
- 编码器-解码器结构: 引入了编码器-解码器结构,使用深度可分离卷积进行更高效的特征提取。
- Xception模型作为基础: 使用Xception模型作为编码器,提高了特征提取的效果。
- 解码器的空间上采样: 使用双线性插值和卷积来进行空间上采样,以将编码器的输出还原到原始分辨率。
SegNet
SegNet是一种用于图像分割任务的深度学习架构,由剑桥大学的研究团队于2015年提出。SegNet主要专注于语义分割,即将图像分割成不同的语义区域。其设计灵感来自于对深度学习在自动驾驶领域的应用,如道路分割。
SegNet包括编码器(Encoder)和解码器(Decoder)两个部分,其结构与自编码器有些相似。
编码器:
- 编码器由卷积层和池化层组成,用于提取输入图像的高级特征。这些特征在编码器中被下采样,降低了空间分辨率。
解码器:
- 解码器与编码器相反,由上采样层和反卷积层组成。解码器的任务是将编码器产生的低分辨率特征图还原到原始输入图像的分辨率。
(Decoder)两个部分,其结构与自编码器有些相似。
编码器:
- 编码器由卷积层和池化层组成,用于提取输入图像的高级特征。这些特征在编码器中被下采样,降低了空间分辨率。
解码器:
- 解码器与编码器相反,由上采样层和反卷积层组成。解码器的任务是将编码器产生的低分辨率特征图还原到原始输入图像的分辨率。
SegNet在编码器阶段使用最大池化,但与传统的最大池化不同,它会记录每个池化窗口中最大值的索引。这些池化索引将被传递到解码器,以在上采样阶段进行非线性上采样。SegNet主要用于图像分割任务,特别是在自动驾驶领域中的道路分割任务。它可以将图像中的每个像素分配到属于哪个语义类别,从而在自动驾驶系统中实现对道路、车辆、行人等的精确识别。