结合ENVI和PIE Hyp讲述高光谱遥感信息处理技术,包括光谱恢复、光谱库建立、光谱特征提取、混合像元分解、图像分类及精度检验
大气温室气体浓度不断增加,导致气候变暖加剧,随之会引发一系列气象、生态和环境灾害。如何降低温室气体浓度和应对气候变化已成为全球关注的焦点。海洋是地球上最大的“碳库”,“蓝碳”即海洋活动以及海洋生物(特别是红树林、盐沼和海草)能够吸收大气中的二氧化碳,并将其固定、储存在海洋中的过程、活动和机制。而维持与提升我国海岸带蓝碳潜力是缓解气候变化的低成本、高效益的方案,有利于充分发挥我国海洋和海岸带生态系统在缓解全球气候变化中的重要作用。红树林作为最主要的蓝碳植被,对其的监测与保护成为近年来的研究热点。从全球范围来看,红树林主要分布在热带与亚热带地区海岸带沿线,生境碎片化且分布不均匀,具有高度的空间异质性。
光谱和图像是人们观察世界的两种方式,高光谱遥感通过“图谱合一”的技术创新将两者结合起来,大大提高了人们对客观世界的认知能力,本来在宽波段遥感中不可探测的物质,在高光谱遥感中能被探测。以高光谱遥感为核心,构建大范围、快速、远程、定量探测技术,已在农业、林业、地质、生态、水质监测等领域取得了突出成果,而在药品、食物、环境等领域也显示了不可估量的应用潜力。
遥感云计算技术的发展和平台的出现为遥感大数据处理和分析提供了前所未有的机遇,表现在:(1)云端有海量数据资源,无需下载到本地处理,(2)云端提供批量和交互式的大数据计算服务,(3)云端提供应用程序接口API(Application Programming Interface),无需在本地安装软件,才可以进行处理分析。这彻底改变了传统遥感数据本地下载,处理和分析的模式,进一步降低了遥感数据使用的准入门槛,极大提高了运算效率,加速了算法测试的迭代过程,使得原本在台式机或服务器上难以实现的全球尺度地球系统科学快速分析和应用成为可能。
应广大科研工作者的要求,本次课程将聚焦目前遥感应用领域-碳储量估算,重点结合典型应用案例综合展示如何基于云计算与多源遥感技术,通过高光谱遥感对研究区域福建沿海的蓝碳植被进行精准探测,结合多光谱遥感技术监测并分析海岸带蓝碳植被的长时序分布变化与健康状态。本课程将结合ENVI和PIE Hyp讲述高光谱遥感信息处理技术,包括光谱恢复、光谱库建立、光谱特征提取、混合像元分解、图像分类及精度检验等内容;同时本课程以JavaScript版本GEE为主进行讲解长时序多尺度的遥感信息提取技术,包括GEE基本知识,遥感影像数据处理的关键知识进行串讲,最后结合海岸带应用典型案例进行综合讲解。
基于“遥感+”蓝碳储量估算、红树林信息提取实践技术应用与科研论文写作 (qq.com)
“遥感+”助推蓝碳生态系统碳储量调查简介
(1)蓝碳生态系统碳储量研究背景
红树林、海草床和盐沼是海岸带最具固碳效率的三大生态系统,统称为“蓝色碳汇”。虽然这三类生态系统的覆盖面积不到海床的0.5%,植物生物量只占陆地植物生物量的0.05%,但其碳储量却高达海洋碳储量的50%以上,甚至可能高达71%。尽管红树林面积有限,仅占陆地表面的0.1%,但它比陆地生态系统具有更高的碳储存和碳捕获的能力。作为蓝碳的重要组成部分,由于周期性的潮汐淹没、土壤厌氧和独特的复杂根系,红树林能有效捕获悬浮物质,埋藏有机物,并降低有机质分解速率进而达到固碳的效果。
(2)蓝碳生态系统碳储量研究方法
传统的碳库调查方式成本高、效率低,制约了长时间、大尺度区域开展红树林碳库分布的估算和监测,建立大尺度区域及时准确估算红树林碳储量的方法至关重要。从全球范围来看,红树林主要分布在热带与亚热带地区海岸带沿线,生境碎片化且分布不均匀,具有高度的空间异质性。
(3)遥感技术在蓝碳生态系统研究中的优势
结合高光谱遥感技术图谱合一的特点,利用高光谱遥感技术分析红树林光谱数据,实现物种进行精准识别或分类。针对桌面端软件处理遥感影像时效性低的问题,我们将结合遥感云计算平台实现对长时间、不同尺度区域的红树林碳库分布的估算和监测。
第一章
高光谱遥感数据介绍及预处理
1.1高光谱遥感数据的认识
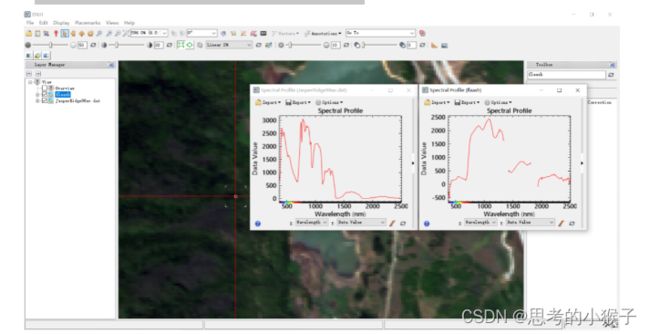
高光谱分辨率遥感是用很窄而连续的光谱通道对地物持续遥感成像的技术。在可见光到短波红外波段其光谱分辨率高达纳米数量级。高光谱图像数据可以被看作是由无数波段组合得到的一个立方体图像数据,并且具有光谱覆盖范围广,图谱合一、数据量大,光谱连续的特征。每一条光谱曲线都分别对应与代表着一个光谱像元。对地物特性而言,同一种地物应该存在相同的光谱曲线特征,因此在判断像元分类时往往依靠光谱特征属性来确定是否属于同一种地物。
示例:GF-5卫星是中国高分重大专项中唯一一颗高光谱卫星,其空间分辨率为30 m,幅宽为 60 km,共有330个波段(400-2500 nm),其中可见光和短波红外部分的光谱分辨率分别为5nm和10nm。
1.2高光谱数据预处理
高光谱图像预处理包括坏波段剔除、辐射定标和大气校正以及图像裁剪。
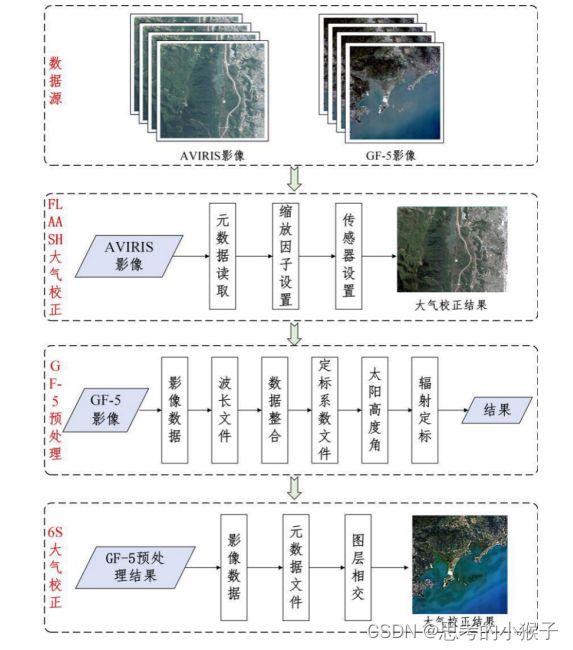
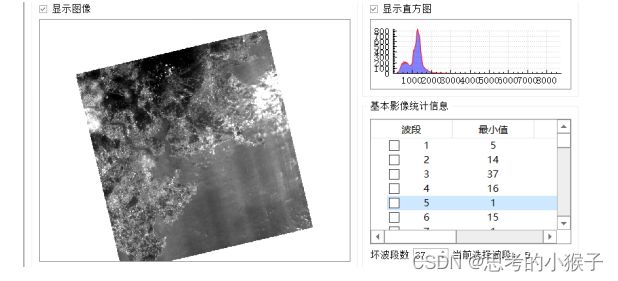
- 坏波段剔除
由于大气散射、水汽吸收、成像系统、传感器等因素的影响,高光谱影像中有部分波段影像质量较差,需要将这些波段剔除。
- 辐射定标
通过辐射定对数据采集和传输系统引起的系统、随机辐射失真或畸变进行的校正,去除或纠正因辐射误差而引起影像失真的过程。
- 大气校正
原理:大气反射、吸收、散射、折射和投射会不同程度的影响传感器记录地物反射的电磁波辐射,大气校正即消除大气影响所造成的误差,反演地物真实反射率的过程。
方法:目前遥感图像的大气校正方法主要有统计特征学模型、地面线性回归经验模型、大气辐射传输理论模型三类。
示例:6S辐射传输模型原理及实现。
第二章
光谱特征分析与参量提取
2.1光谱特征分析
红树林植被在可见光和近红外波段表现出典型绿色植物的主要光谱响应特征。在可见光波段,植物光谱主要受叶绿素含量的影响,470nm蓝光波段和670nm红光波段附近叶绿素吸收辐射能形成吸收谷,在550nm绿光波段附近吸收相对减少,形成绿色反射峰。受叶片内部细胞组织对近红外波段强反射的影响,670~780nm之间“红边”反射迅速增高。近红外波段受叶片内部的细胞结构和叶冠结构对光强烈反射的影响,780~950nm近红外波段内表现出高反射率特征。
2.2光谱特征变换分析
光谱二值编码,光谱微分,连续统去除
示例:连续统去除法
连续统去除法也叫包络线去除法。包络线去除法是一种有效增强吸收特征的光谱分析方法,经过包络线去除后,地物的光谱曲线的吸收特征更加明显,反射率归一化为0 ~ 1之间,有利于光谱吸收特征分析和光谱特征波段选择。并且,包络线去除法能够有效解决高光谱数据冗余的问题。
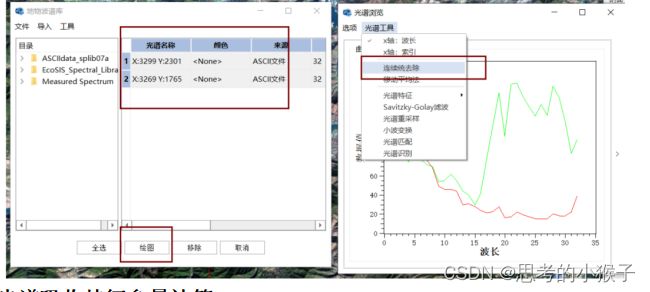
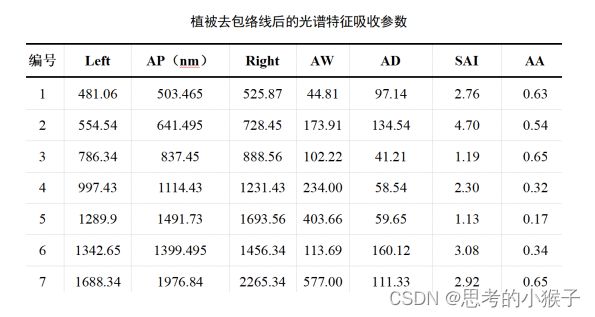
2.3光谱吸收特征参量计算
光谱吸收特征参量包括:吸收位置(absorption position,AP)、吸收深度(absorption depth,AD)、吸收宽度(absorption width,AW)、光谱吸收对称性(absorption asymmetry,AA)和光谱吸收指数(spectral absorption index,SAI)。
2.4 植被指数提取
(1)计算NDVI(归一化植被指数)
NDVI=(NIR-RED)/(NIR+RED)
(2)计算EMVI(增强型红树林指数)
EMVI=(GREEN-SWIR2)/(SWIR1-GREEN)
2.5红树林信息提取
结合矢量数据与影像计算的结果提取口红树林分布区域;
结合目视解译结果提取红树林信息。
第三章
高光谱遥感数据分类与制图
3.1混合像元分解
遥感图像中混合像元的存在,是像元级遥感分类和要素反演精度难以达到使用要求的主要原因。为了提高遥感应用的精度,必须解决混合像元分解
的问题,使遥感应用由像元级达到亚像元级。进入像元内部,将混合像元分解为不同的“基本组分单元”,或称“端元”,并求得这些基本组分所占的比例(即地物丰度),对混合像元对应地物的真实组成情况进行还原,即所谓的“光谱解混”过程。
混合像元分解包括端元数目估计、端元提取和丰度反演三部分

- 端元数目估计
HySime算法估计信号和噪声的相关系数矩阵后,在信号特征向量构成的空间中选择使得投影前后具有最小均方差的子空间,构成该子空间的特征向量个数即为端元估计数目。该
- 端元提取
端元波谱作为高光谱分类、地物识别和混合像元分解等过程中的参考波谱,直接影响波谱识别与混合像元分解结果的精度。端元提取的作用是从高光谱图像中提取“纯”地物,即端元的光谱。
端元提取包括顶点成分分析法、正交子空间投影、内部最大体积法
(N-FINDR)。
- 丰度反演
丰度反演主要是用来求混合像元中不同成分所占的比例。
丰度反演主要有三种方式,分别是最小二乘法、单形体体积和超平面距离。
3.2 高光谱遥感影像分类
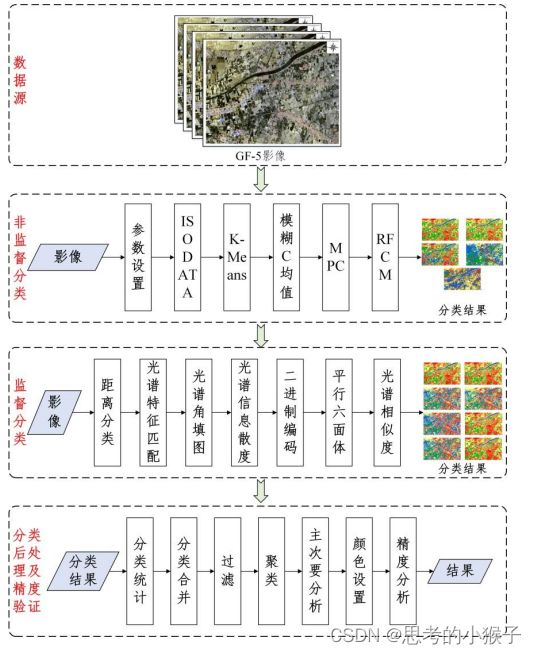
- 高光谱遥感影像分类方法
光谱角填图
光谱相似度
光谱特征匹配
光谱信息散度
ISODATA分类
K-Means分类
模糊 C 均值分类
MPC分类
RFCM分类
- 示例:基于光谱角填图的分类
波谱角分类(SAM)是一个基于自身的波谱分类,它是在n维空间将像元与参照波谱进行匹配。这一算法是通过计算波谱间的角度(将它们作为具有维数等于波段数特征的空间矢量进行处理),判定两个波谱间的相似度。较小的角度代表像元与参照波谱匹配紧密。大于指定的最大弧度阈值的像元不被分入该类。然后生成分类后的图像。
- 分类后处理
对分类后的图像进行分类统计、类别合并以及过滤,得到更加精确的分类结果。
- 精度评价
精度评价是用来计算分类后图像数据与真实地面数据的偏差。
使用地面实测红树林分布数据对红树林分类结果进行精度评价。
第四章
GEE数据处理介绍
4.1国外Earth Engine(GEE)平台简介
GEE(Google Earth Engine)是由谷歌、卡内基梅隆大学、美国地质调查局(USGS)共同开发的用以处理卫星遥感影像数据和其他地球观测数据的云端运算平台。GEE平台融合了谷歌服务器提供的强大计算能力或者以及大范围的云计算资源,平台数据集提供了对地观测卫星大量完整的影像数据如Sentinel, MODIS,Landsat等,也提供了植被、地表温度和社会经济等数据集,并能做到数据库每天更新。下图是GEE提供的Landsat Collection2数据
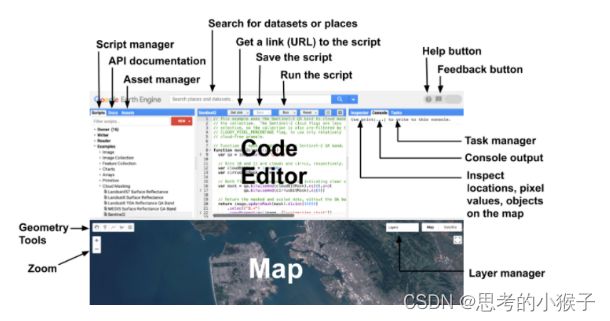
GEE提供了Python和JavaScript版的API,使用基于Web的代码编辑器(IDE)进行快速、交互式算法开发。用于地球引擎JavaScript API的IDE具有如下图的元素:
4.2 GEE主要数据类型与对象等
- 几何图形ee.Geometry()
GEE在Geometry下提供了一系列方法,如:LineString(线段)、
Point(点)、MultiPoint(复合点)、Polygon(多边形)等。在Geometry的创建,最快捷的方式是通过用户的点击创建所需的几何图形,如下图所示。在创建完成后会在代码编辑器中自动生成代码。

- 矢量数据ee.Feature()
在GEE中,Feature()类型的矢量数据是一种中间类型的数据,相比于Geometry多了一些需要存储的属性信息,类似于本地矢量数据的属性表。
- 矢量数据集合ee.FeatureCollection()
矢量数据集是GEE中常用的数据格式,在GEE中,矢量数据的操作大多数基于矢量数据集进行。
- 影像数据
-
Image的创建主要有GEE自带的数据集,用户上传和ee.image()/constant()及ee.Image.pixelLonLat()方法。
- 影像集合
-
影像集合与矢量集合数据处理方法类似,常用的有过滤方法、循环遍历方法等。
4.3 影像预处理
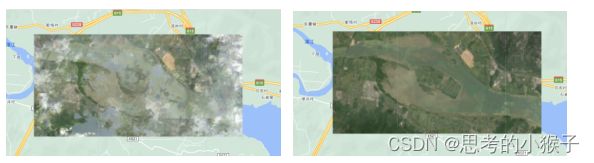
GEE上提供各种影像数据,大气、地形和几何校正的预处理工作已经完成。但在使用之前,需要对影像进行去云处理。以Landsat8数据为例,基本思路为获取数据的QA波段,设置QA波段的cloudShadowBitMask(云影位)和cloudsBitMaks(云位)均为0,再更新数据的该波段,即可得到去云后的影像。具体代码如下:
-

影像去云前后对比:
-
-
影像去云处理后,可直接利用ee.ImageCollection()下的filterBounds()、clip()方法和上传至平台的矢量数据,将影像裁剪至研究区范围,提高计算效率。
4.5机器学习分类提取红树林
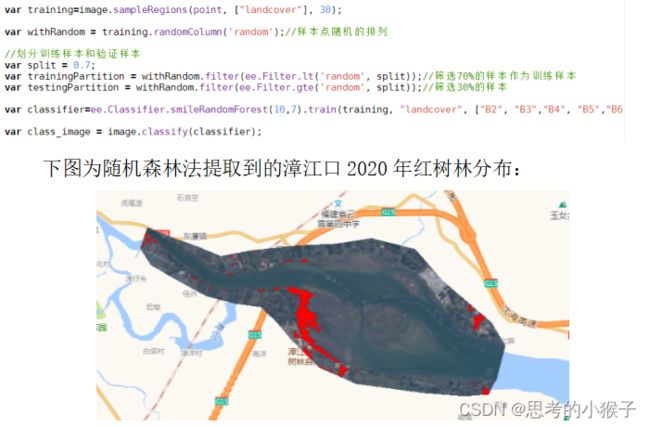
GEE提供了多种监督分类和非监督分类算法,本例展示使用随机森林法提取2020年漳江口自然保护区红树林分布。
首先需将样本点上上传,划分训练样本和验证样本后构建分类器,最后运用分类器得到结果,部分代码如下图所示:
-
4.6红树林植被指数计算及提取
为提高效率,使用植被指数阈值法进行红树林的提取。主要使用两种植被指数:增强型红树林植被指数EMVI和红树林植被指数MVI。
- 增强型红树林植被指数EMVI
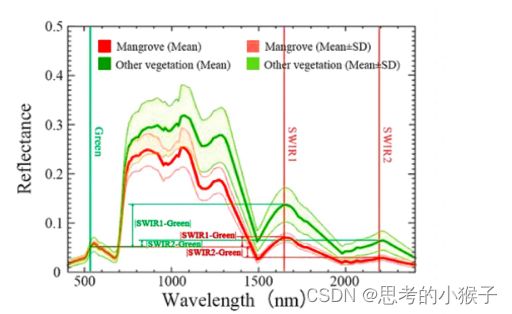
增强型红树林植被指数EMVI是Yang Gang等根据红树林与其他植被在绿光波段和中红外波段的光谱特征差异(如下图所示)构建的。
其计算公式为:
EMVI=(GREEN-SIWR2)\(SWIR1-GREEN)

利用该指数提取2020年漳江口国家级自然保护区红树林分布结果如下:

- 红树林植被指数MVI
红树林植被指数MVI是Alvin B.Baloloy等基于红树林与其他植被在绿光波段、近红外波段和中红外波段的差异构建的(如下图):
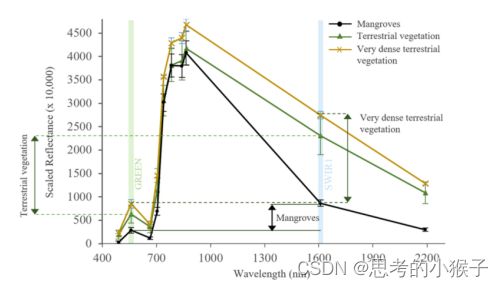


- 指数和阈值的选择
两种用于提取红树林的指数均有较好的效果(红树林纹理特征较明显,可目视解译判断提取效果)。指数及阈值的选择要根据影像数据源、研究区的时空条件而变化。
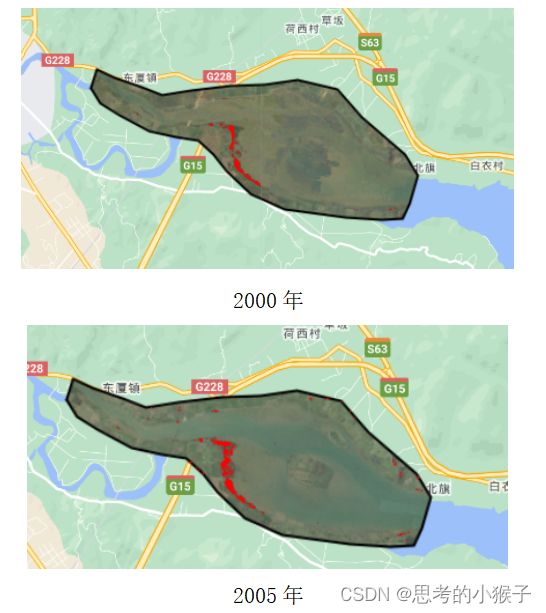
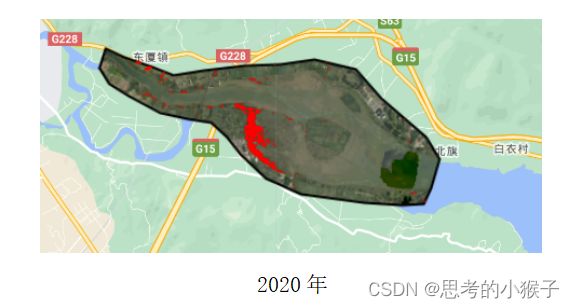
4.7红树林分布时序分析
利用植被指数阈值法提取红树林的优势在于无需选择样本点,结合GEE的云计算服务,可以高效实现红树林分布的时序分析。

4.8结果统计分析与绘图
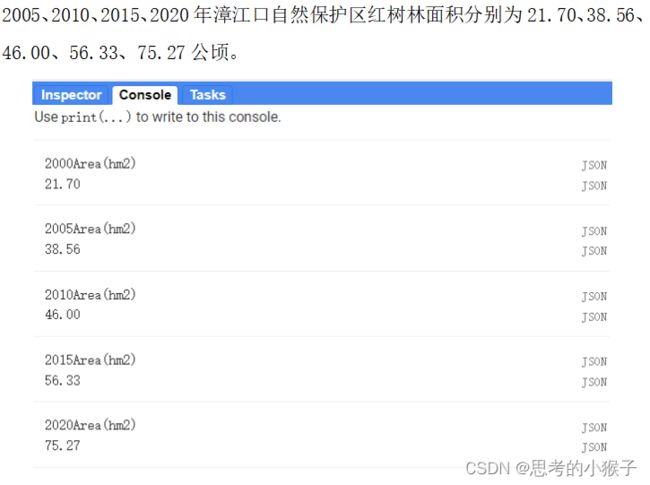
- 计算像素面积
通过pixelArea()和Reducer.sum()等方法,计算提取到的红树林的面积,并转化为公顷单位。

- 生成图表
利用图表可以更直观地展现红树林面积变化的趋势情况。GEE提供了多种图表形式,用户可根据自己的需求进行个性化设计。
4.9数据导出
GEE在Expot()下提供了导出影像到云盘的功能,用户设置需要导出的影像、影像描述、比例、区域以及最大像元数,运行后即可在右侧【Task】栏中运行任务,将影像导出,导出结果为Tiff格式。


第五章
碳储量时空变化与预测
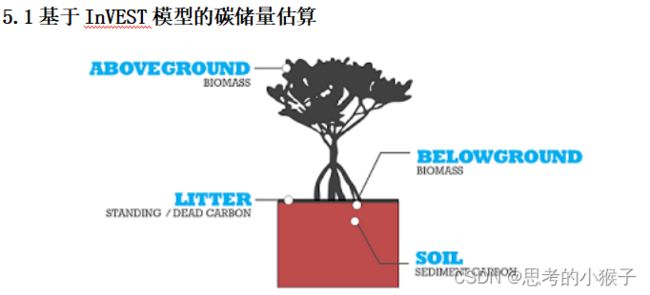

5.2基于InVEST模型的蓝碳储量估算
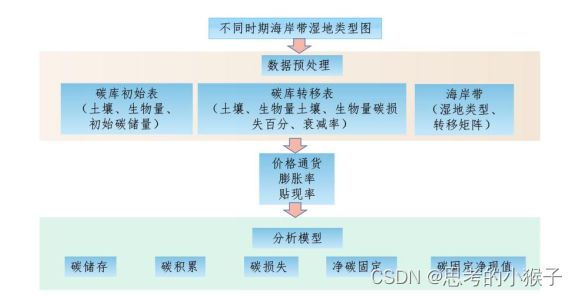
- 碳储存估算

2.碳积累估算
3.碳损失估算
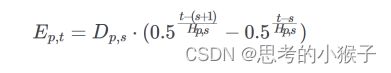
- 净碳固定估算

5.3 基于PLUS模型的碳储量的时空变化分析与预测
- 实现思路
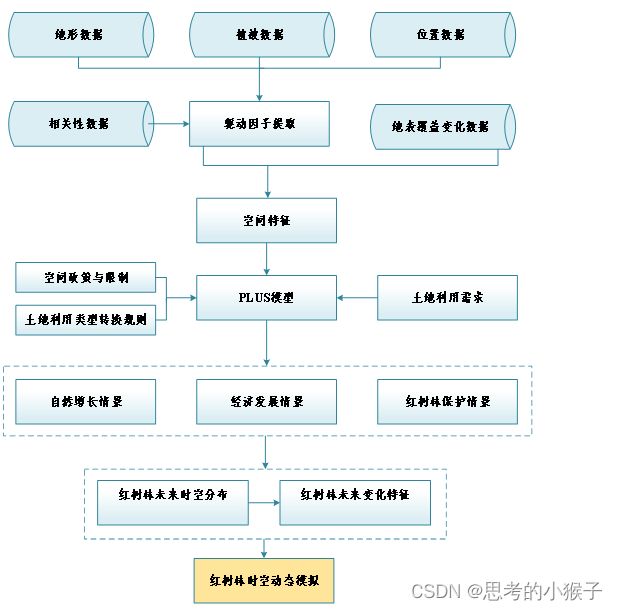
- PLUS模型数据准备
数据类型
数据格式转换
- 驱动因素选择和处理
驱动因子选择
驱动因子数据制备
驱动因子数据格式转换

- 土地扩张分析策略(LEAS)模块原理与实现
土地扩张分析策略(LEAS)模块原理介绍
用地扩张提取
RF算法提取土地利用类型的发展潜力
- 多类随机斑块种子的CA模型(CARS)模块原理与实现
(CARS)模块原理介绍
模块运行数据制备
Markov土地利用预测
未来土地利用分布模拟
模拟精度验证
场景多样性分析
- 碳储量的时空变化分析与预测
驱动因素影响分析
第六章
科技论文写作
与制图
- 科技论文结构分析
- 科技论文图表规范
- 图表优化技巧
- 论文投稿技巧分析
- SCI论文案例分析