seleninum 基础及简单实践
网页自动化
1 Selenium自动化基础
1.1 Selenium简介
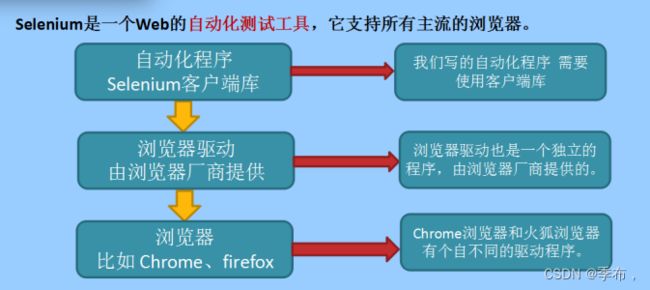
Selenium自动化流程如下:
- 自动化程序调用Selenium客户端库函数
- 客户端库会发送Selenium命令,给浏览器的驱动程序
- 浏览器驱动程序接收到命令后,驱动浏览器去执行命令
- 浏览器执行命令
- 浏览器驱动程序获取命令执行的结果,返回给我们自动化程序
- 自动化程序对返回结果进行处理
1.2 Selenium安装

1)谷歌浏览器驱动
(2)课件提供好的谷歌浏览器和谷歌浏览器驱动软件
注意:谷歌浏览器驱动,要放到python解释器的安装目录下(也就是跟python.exe同一个目录下)
1.3获取某个网页页面
# 导入 webdriver
from selenium import webdriver
#创建浏览器对象
driver = webdriver.Chrome(executable_path=r'C:\Users\nlp_1\Desktop\chromedriver\chromedriver-win32\chromedriver.exe')
# get方法会一直等到页面被完全加载,然后才会继续程序。
driver.get('https://www.baidu.com')
# 打印网页渲染后的源代码
print(driver.page_source)
------------------------------------------------------
# 打印页面标题“百度一下,你就知道”
print(Driver.title)
# 获取当前url
print(Driver.current_url)
# 关闭当前页面,如果只有一个页面,会关闭浏览器
Driver.close()
# 关闭浏览器
Driver.quit()
2、Selenium 数据解析提取
2.1 定位元素
Selenium提供了8种定位方式
- id
- name
- class name
- tag name
- link text
- xpath
- css selector
- partial link text
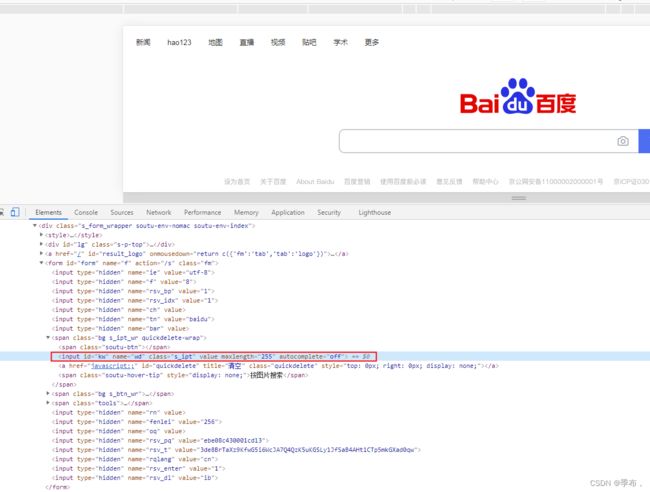
单属性查找:
**1.用 标签名 定位查找**
driver.find_element_by_css_selector("input")
**2.用 id 属性定位查找**
driver.find_element_by_css_selector("kw")
**3.用 class 属性定位查找**
driver.find_element_by_css_selector("s_ipt")
**4.其他属性定位**
driver.find_element_by_css_selector("[name='wd']")
组合属性查找:
# 1. 标签名及id属性值组合定位
driver.find_element_by_css_selector("input#kw")
# 2. 标签名及class属性值组合定位
driver.find_element_by_css_selector("input.s_ipt")
# 3. 标签名及属性(含属性值)组合定位
driver.find_element_by_css_selector("input[name='wd']")
# 4. 标签及属性名组合定位
driver.find_element_by_css_selector("input[name]")
# 5. 多个属性组合定位
driver.find_element_by_css_selector("[class='s_ipt'][name='wd']")

模糊匹配:
# 1. class拥有多个属性值,只匹配其中一个时
driver.find_element_by_css_selector("input[class ~= "bg"]")
# 2. 匹配以字符串开头的属性值
driver.find_element_by_css_selector("input[class ^= "bg"]")
# 3. 匹配以字符串结尾的属性值
driver.find_element_by_css_selector("input[class $= "s_btn"]")
# 4. 匹配被下划线分隔的属性值
driver.find_element_by_css_selector("input[class |= "s"]")
层级查找:
# 1.直接子元素层级关系,如上图的 百度一下 ,input为span的直接子元素(用 > 表示)
driver.find_element_by_css_selector(".bg.s_btn_wr > input")
# class为bg和s_btn_wr 的span标签的子元素input
# 2.只要元素包含在父元素里面,不一定是直接子元素,用空格隔开,如图一所示,form 下面的 span 里面的input
driver.find_element_by_css_selector("#form input")
# id是form的form标签里面的input标签
# 3.多级关系
driver.find_element_by_css_selector("#form > span > input")
# id是form的form标签下面的span标签的下面的input标签
2.1.2 多个元素查找
- find_elements_by_name 通过元素name定位
- find_elements_by_id 通过元素id定位
- find_elements_by_xpath 通过xpath表达式定位
- find_elements_by_link_text 通过完整超链接定位
- find_elements_by_partial_link_text 通过部分链接定位
- find_elements_by_tag_name 通过标签定位
- find_elements_by_class_name 通过类名进行定位
- find_elements_by_css_selector 通过css选择器进行定位
2.1.3 实例演示
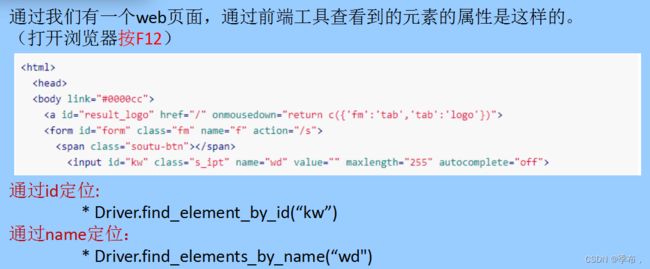


2.2 获取元素属性
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.baidu.com/'
browser.get(url)
input = browser.find_element_by_id('kw')
print(input)
print(input.get_attribute('name'))
print(input.get_attribute('class'))
print(input.get_attribute('id'))
print(input.get_attribute('maxlength'))
print(input.get_attribute('autocomplete'))
browser.close()
2.3 获取文本值
Selenium WebDriver 只会与可见元素交互,所以获取隐藏元素的文本总是会返回空字符串。
要获取隐藏元素的文本,这些内容可以使用
element.get_attribute(‘innerHTML’),会返回元素的内部HTML,包含所有的HTML标签。
element.get_attribute(‘textContent’),只会得到文本内容,而不会包含HTML。
element.get_attribute(‘innerText’),只会得到文本内容,而不会包含HTML标签。
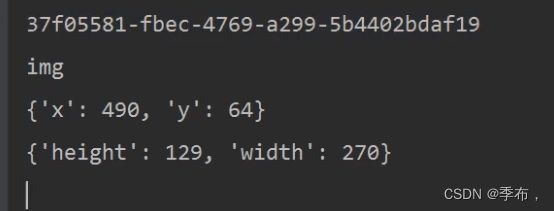
2.4 获取位置,ID,标签名
id
Location
Tag_name
Size
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.baidu.com/'
browser.get(url)
logo = browser.find_element_by_xpath('//div[@id="lg"]/img[@class="index-logo-src"]')
print(logo.id)
print(logo.tag_name)
print(logo.location)
print(logo.size)
2.5 执行JavaScript
这是一个非常有用的方法,这里就可以直接调用js方法来实现一些操作,
下面的例子是通过登录知乎然后通过js翻到页面底部,并弹框提示
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.zhihu.com/explore")
print(browser.page_source)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
2.6截屏
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window() #窗口最大化
driver.get(“https://blog.csdn.net/Kwoky/article/details/80285201”)
driver.save_screenshot(“./images/app2.png”) #截屏
3 、Selenium自动化交互
3.1 鼠标动作链
在页面上模拟一些鼠标操作,比如双击、右击、拖拽甚至按住不动等,可以通过导入ActionChains类实现。
ActionChains执行原理
(1)当调用ActionChains的方法时不会立即执行,而是会将所有的操作按顺序存放在一个队列里,
(2)当你调用perform()方法时,队列中的时间会依次执行。
有两种写法本质上是一样的,ActionChains会按照顺序执行所有的操作。
#ActionChains方法列表
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
3.2 案例:百度自动化搜索
# 导入 webdriver
from selenium import webdriver
# 调用环境变量指定的 Chrome 浏览器创建浏览器对象
driver = webdriver. Chrome ()
# get 方法会一直等到页面被完全加载,然后才会继续程序,通常测试会在这里选择
time.sleep(2)
driver.get("http://www.baidu.com/")
# id=“kw”是百度搜索输入框,输入字符串“python”
driver.find_element_by_id(“kw”).send_keys(“python")
# id=“su”是百度搜索按钮, click() 是模拟点击
driver.find_element_by_id(“su”).click()
# 获取新的页面快照
driver.save_screenshot(“python1.png”)
# 清除输入框内容
driver.find_element_by_id(“kw”).clear()
print(‘访问成功')
3.3 等待页面加载
Python内置的time库,time.sleep()方法可以强制等待。
Selenium 提供了两种等待方式:
一种是隐式等待,一种是显式等待,隐式等待是等待特定的时间,显式等待是指某一条件直到这个条件成立时继续执行。
显示等待:指定某个条件,然后设置最长等待时间。如果这个时间还没有找到元素,那么便会抛出异常了。如果不写参数,程序默认会0.5s调用一次来查看元素是否已经生成,如果本来元素就是存在的,那么会立即返回。
隐式等待:比较简单,就是简单地设置一个等待时间,单位为秒。如果不设置,默认等待时间为0。通过设定的时长等待页面元素加载完成,再执行下面的代码,如果超过设定时间还未加载完成,则继续执行下面的代码(注意:在设定时间内加载完成则立即执行下面的代码)。
下面是一些内置的等待条件,可以直接调用这些条件,而不用自己写某些等待条件了。 expected_conditions类提供的预期条件判断方法如下。
title_is 标题是某内容
title_contains 标题包含某内容
presence_of_element_located 元素加载出,传入定位元组,如(By.ID, 'p')
visibility_of_element_located 元素可见,传入定位元组
visibility_of 可见,传入元素对象
presence_of_all_elements_located 所有元素加载出
text_to_be_present_in_element 某个元素文本包含某文字
text_to_be_present_in_element_value 某个元素值包含某文字
frame_to_be_available_and_switch_to_it frame 加载并切换
invisibility_of_element_located 元素不可见
element_to_be_clickable 元素可点击
staleness_of 判断一个元素是否仍在 DOM,可判断页面是否已经刷新
element_to_be_selected 元素可选择,传元素对象
element_located_to_be_selected 元素可选择,传入定位元组
element_selection_state_to_be 传入元素对象以及状态,相等返回 True,否则返回 False
element_located_selection_state_to_be 传入定位元组以及状态,相等返回 True,否则返回False
alert_is_present 是否出现 Alert
显示等待

隐式等待
