AIGC实战 - 使用变分自编码器生成面部图像
AIGC实战 - 使用变分自编码器生成面部图像
-
- 0. 前言
- 1. 数据集分析
- 2. 训练变分自编码器
-
- 2.1 变分自编码器架构
- 2.2 变分自编码器分析
- 3. 生成新的面部图像
- 4. 潜空间算术
- 5. 人脸变换
- 小结
- 系列链接
0. 前言
在自编码器和变分自编码器上,我们都仅使用具有两个维度的潜空间。这有助于我们可视化自编码器和变分自编码器的内部工作原理,并理解自编码器和变分自编码潜空间分布的区别。在本节中,我们将使用更复杂的数据集,并了解增加潜空间的维度时,变分自编码器的图像生成效果。
1. 数据集分析
接下来,我们将使用 CelebFaces Attributes (CelebA) 数据集训练一个新的变分自编码器 (Variational Autoencoder, VAE)。CelebA 数据集包含了 200,000 多张人脸部彩色图像,每张图像都标注了各种标签(例如戴帽子、微笑等):

当然,训练 VAE 时并不需要这些标签,但当我们探索如何在多维潜空间中捕获这些特征时,这些标签将会派上用场。VAE 训练完成后,我们就可以从潜空间中采样,生成新的面部图像。
CelebA 数据集可以在 Kaggle 网站中获取,下载完成后,将图像和相关元数据保存到本地的 ./data 文件夹中。
# 加载数据
train_data = image_dataset_from_directory(
"data/img_align_celeba",
label_mode=None,
color_mode="rgb",
image_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
shuffle=True,
seed=42,
interpolation="bilinear",
)
使用 Keras 函数 image_dataset_from_directory 能够创建一个指向存储图像目录的 TensorFlow 数据集。用于在需要时(例如在训练期间)将图像批量读入内存,以便处理大型数据集,而不必担心要将整个数据集装入内存中导致内存不足的情况。同时还将图像调整为 64 × 64 大小,并在像素值之间进行插值处理。
原始数据值范围在 [0, 255] 之间,表示像素强度,我们需要将其重新缩放到范围 [0, 1]:
# 数据预处理
def preprocess(img):
img = tf.cast(img, "float32") / 255.0
return img
2. 训练变分自编码器
2.1 变分自编码器架构
面部生成变分自编码模型的网络架构与 Fashion-MNIST 架构类似,仅有以下细微区别:
- 输入数据为三通道 (
RGB) 图像,而不是仅有一个通道的灰度图像灰度,因此需要将解码器的最后一个转置卷积层的通道数更改为3 - 使用一个具有
200个维度的潜空间,而不是仅仅只有2个,由于面部图像比Fashion-MNIST图像复杂得多,因此需要增加潜空间的维度,以便网络可以从图像中编码出丰富的细节 - 在每个卷积层之后都使用批归一化层,以稳定训练,尽管每批数据的运行时间较长,但达到相同损失所需的批大小大幅减少
- 将
KL 散度的权重因子增加到2,000,权重因子是一个可调整的超参数,我们可以使用不同值以获得最佳效果
编码器和解码器的完整架构如下图所示:
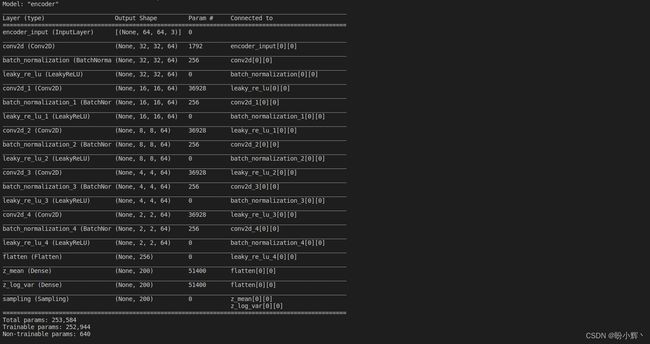
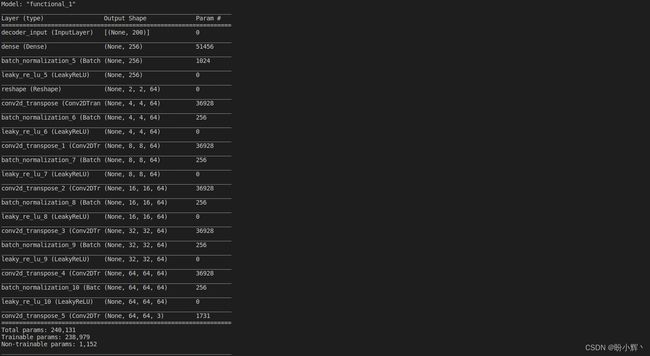
在经过大约五个 epoch 的训练之后,变分自编码器已经能够生成新的面部图像。
2.2 变分自编码器分析
接下来,我们查看重建的脸部样本。下图中顶行展示了原始图像,底行显示了它们通过编码器和解码器处理后的重建图像。

可以看到,VAE 成功地捕捉到了每张脸的关键特征,例如头部的角度、发型、表情等等。虽然仍然缺少一些细节,但是构建变分自编码器的目标并不是实现完美的重建损失,我们的目标是从潜空间中采样,生成新的面部图像。
为此,我们必须检查潜空间中的点的分布是否与多元标准正态分布大致相同。由于我们无法同时查看所有维度,因此只能分别检查隐空间的每个维度的分布。如果我们发现有任何维度与标准正态分布显著不同,那么我们可能需要减小重建损失权重系数,以增加 KL 散度对损失值的影响。
下图展示了潜空间中的前 50 个维度,可以看到,没有任何分布明显不同于标准正态分布,所以我们可以继续进行下一步,生成新的面部图像。
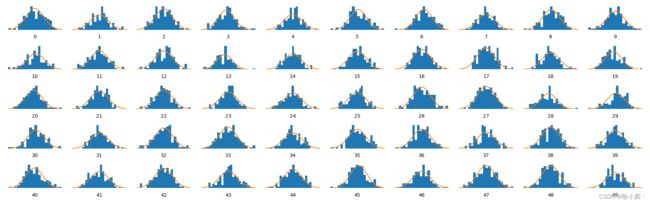
3. 生成新的面部图像
使用以下代码生成新的面部图像:
grid_width, grid_height = (10, 3)
# 从一个具有 200 个维度的标准多元正态分布中随机采样 30 个点
z_sample = np.random.normal(size=(grid_width * grid_height, Z_DIM))
# 解码采样点
reconstructions = decoder.predict(z_sample)
# 绘制解码后得到的图像
fig = plt.figure(figsize=(18, 5))
fig.subplots_adjust(hspace=0.4, wspace=0.4)
for i in range(grid_width * grid_height):
ax = fig.add_subplot(grid_height, grid_width, i + 1)
ax.axis("off")
ax.imshow(reconstructions[i, :, :])
plt.show()
输出结果如下图所示:

可以看到,VAE 能够将我们从标准正态分布中采样的一组点转化为逼真的人脸图像。尽管这些图像并不完美,但这是我们首次尝试生成模型的真正潜力。接下来,我们学习如何利用潜空间对生成的图像执行操作。
4. 潜空间算术
将图像映射到低维潜空间的一个好处在于,我们可以针对潜空间中对向量执行算术运算,当这个向量解码回原始图像域时,就能观察到其对应的视觉效果。
例如,假设我们想给一个看起来很悲伤的人物图像添加一个微笑表情。为此,我们首先需要找到潜空间中指向增加微笑表情方向的向量。将这个向量与原始图像在潜空间中的编码相加,将会得到一个新的点,解码后就能够得到一个在原始图像基础上带有微笑表情的新图像。
因此,关键是找到微笑向量。CelebA 数据集中的每个图像都带有属性标签,其中就包括微小 (Smiling)。如果我们计算具有 “Smiling” 属性的编码图像在潜在空间中的平均位置,并减去没有 “Smiling” 属性的编码图像的平均位置,就可以得到指向 “Smiling” 方向的向量。
从概念上讲,可以通过以下方式在潜在空间中执行向量算术运算,其中 alpha 是一个确定要添加或减去多少特征向量的因子:
z _ n e w = z + a l p h a ∗ f e a t u r e _ v e c t o r z\_new = z + alpha * feature\_vector z_new=z+alpha∗feature_vector
下图展示了几个编码到潜空间中的图像。接下来,通过添加或减去某个向量(例如 “Smiling”,“Black_Hair”,“Eyeglasses”,“Young”,“Male”,“Blond_Hair”),就可以获得不同版本的图像,而且这些图像只改变了相关的特征。
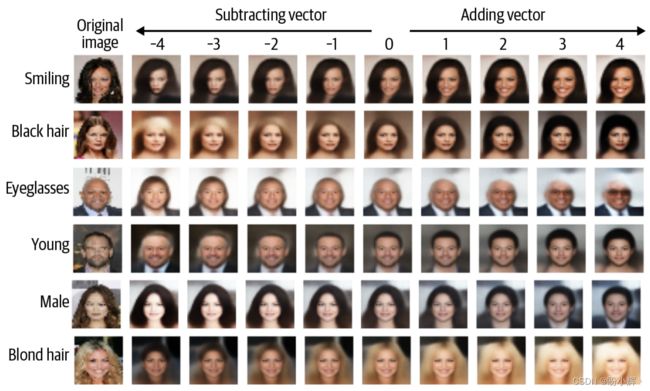
需要注意的是,尽管我们在潜空间中将点移动了相当大的距离,但图像的核心特征仍然基本保持不变,只有我们想要操控的那个特征发生了变化。这说明了变分自编码器具备捕捉和调整图像的高级特征的能力。
5. 人脸变换
类似的,我们可以在两张人脸之间进行形态变换,将一张面孔图像变成另一张。假设潜空间中有两个代表两张图像的点 A 和 B,如果从点 A 开始沿着直线走向点 B,在解码过程中遇到每个点,都可以看作是从起始面孔逐渐变换到结束面孔的过渡。从数学上讲,可以通过以下方程描述这一直线的遍历过程:
z _ n e w = z _ A ∗ ( 1 − a l p h a ) + z _ B ∗ a l p h a z\_new = z\_A * (1- alpha) + z\_B * alpha z_new=z_A∗(1−alpha)+z_B∗alpha
其中,alpha 是介于 0 到 1 之间的值,用于确定我们从点 A 沿着直线前进的距离。
下图展示了实际的变换过程。我们选择两个图像,将它们编码到潜空间,然后在它们之间的直线上,以固定间隔对两点之间的所有点进行解码。

可以看到,即使同时需要改变多个特征(例如去掉眼镜、改变发色、性别),变分自编码器也能够平滑地实现这种过渡。这表明变分自编码器的潜空间的确是一个连续的空间,遍历和探索该空间可以生成各种不同的人脸图像。
小结
在本节中,我们将变分自编码器应用于人脸生成问题,并了解如何解码来自标准正态分布的样本点以生成新的人脸。此外,通过在潜空间内执行向量运算,我们可以实现一些新奇的效果,如人脸形态变换和特征操作。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)