ECCV2020最佳论文RAFT:Recurrent All-Pairs Field Transforms for Optical Flow
最近做光流相关,看了一些监督和无监督自监督的光流估计。今天介绍一下RAFT(监督学习,目前sota)。
官方代码
背景
在RAFT之前,一些有名的光流估计方法,大都遵循金字塔结构+coarse to fine的预测flow的方式。在多个尺度上预测flow,flow层层迭代,逐步细化,分辨率越来越大。作者任务这种范式存在以下问题:
- 粗level预测错了,在后面的更细节的level不好修正
- 对小目标快速移动的情况,很难正确预测
- 训练迭代时间长
- 某些迭代优化的模型,没有把权重复用。
RAFT的特点:
- 始终保持一个高分辨率(1/8)
- 迭代过程,重复使用一个gru blcok。(不同迭代中参数共享),所以模型参数小很多,且能一直迭代没有发散
- 提出一种look up(查询)操作,在每一个迭代中都使用了 all pair attention,但查询操作可以只做一次attention,节省了很多计算量
- 不同于之前方法使用的cost valume。作者使用4D correlation valume。4D是指多个尺度,correlation valume是attention map。
方法
RAFT整个结构,异常简洁。
整个pipeline可以分成3个部分。
- feature encoder
- correlation valume的构建
- 迭代式update(含有查询look up操作)
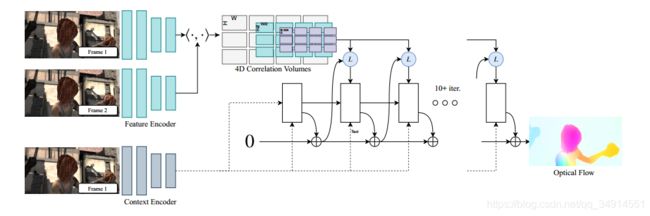
总体pipeline:
- 目标是求第一帧到第二帧的前向光流。首先用feature encoder提出两帧的特征,然后计算attention map,构建4D Correlation Volumes。然后用context encoder提出第一帧的特征。
- context 特征用于在correlation valume上查询,得到每个位置对应邻域(含多尺度)的相似值,记作corr。corr和flow和context feature送入更新模块,不断得到更正确的光流位置。迭代次数大,光流位置会逐渐收敛到固定点,不会发散。
第一部分的输出是1/8的特征。我们就直接开始讲述第二部分和第三部分。
Correlation Valume
第一帧和第二帧对应的feature encoder的输出是 F 1 , F 2 F_1, F_2 F1,F2。然后计算attention map。
c o r r 1 = F 1 T × F 2 , ∈ R h w ∗ h w corr_1 = F_1 ^T \times F_2 , \in R^{hw*hw} corr1=F1T×F2,∈Rhw∗hw
然后用三次池化,kernel size和stride分别为2 4 8,得到一个4d 的correlation volume: { c o r r 1 , c o r r 2 , c o r r 4 , c o r r 8 } \{corr_1, corr_2, corr_4, corr_8 \} {corr1,corr2,corr4,corr8}
update step
这个整个过程最复杂的地方,是一个迭代过程。每一次迭代都会输出一个HW2的flow预测,用来计算loss。测试的时候,只要最后一次迭代的输出就行了。
假设最大迭代次数为T,每一次输出的flow就是 O i , i ∈ 1 , 2 , 3... T O_i, i \in {1,2,3...T} Oi,i∈1,2,3...T。更新的模块输出的是基于当前flow预测的修正项 Δ i \Delta_i Δi,则当前迭代下预测的光流就是 O i = O i − 1 + Δ i O_i = O_{i-1} + \Delta_i Oi=Oi−1+Δi.
我们之前说过,更新操作是一直在高分辨率下完成的,就没有上采样环节了。
接下来就详细说说。
在初始状态, O 0 O_0 O0就是全0的张量,生成的坐标张量加上 O 0 O_0 O0,得到每个在第一帧上的坐标(u,v)对应到第二帧上的坐标(u’,v’)。接下来,就开始查询操作了。在correlation volume中,对每个level(一共4个),都在(u’,v’)上考虑一个邻域(范围为r),将这个范围的相似值拿出来(grid sample操作),组成一个HW((2r*+1)**2)的张量。一共4个level,就得到 H*W*((2r*+1)**2 * 4)作为cost valume。
多尺度可以在计算cost valume的时候,考虑更大范围,仅通过计算邻域的方式,所以代码没有复杂的环境配置,仅仅依赖pytorch内部的张量操作。
接下来作者使用了一个不带bn的ConvGRU,更新状态,输入cost valume, contenxt 特征,当前迭代预测的flow。输出 Δ i \Delta_i Δi, 新的context feature。 Δ i \Delta_i Δi用来修正当前状态下的预测的光流,是光流的残差。所以(u’,v’) + Δ i \Delta_i Δi,就是修正之后的两帧对应点关系。那么(u’,v’) + Δ i \Delta_i Δi -(u,v)就是当前状态下的光流,也就是等于 O i − 1 + Δ i O_{i-1} + \Delta_i Oi−1+Δi
至于ConvGRU的结构,比较简单,就不多说。
还有一个细节。是如何将1/8的flow上采样到原图。一般的做法直接用bilinear + 8乘就可以了。作者使用了一个mask。预测的flow是1/8,每33个patch,对应了33*(88)个系数。前两个33就是patch大小。后2个数字,就是一个patch对应了8个点,用这64个9维向量,加权patch,得到了64个向量,reshape成8*8的区域,这样就能把预测结果上采到原图大小了。
loss
用的是L1。对每个迭代产生的输出,采用加权的方式。加权系数来自于指数计算。 γ = 0.8 \gamma =0.8 γ=0.8。