#gStore-weekly | gAnswer源码分析:基于通用数据集的NE、RE服务开发

PART1
简 介
目前基于知识图谱的问答模式有两种,一种是基于信息检索的方式,一种是基于语义分析的方式。前者较之于后者,没有真正关心语义,主要是ranker算法,擅于处理简单问题,后者则是从语义的角度将用户的自然语言问题转化为逻辑形式,再在KG中执行查询。gAnswer 就是基于语义分析的方法,区别于传统的语义解析的方法,它是一种新颖的面向知识图谱的自然语言问答系统,以图数据驱动的视角回答RDF知识库上的自然语言问题。
采用基于语法分析的方法,大致分为两个阶段:其一为问题理解,即将问题转换为 SPARQL 类型的结构化查询;其二为查询评分,即对产生的结构化查询进行置信度评分。在问答系统中,重点是解决第一阶段中的歧义性问题,即解决:第一,短语链接问题,即如何将自然语言问句中的短语链接到正确的实体/类/关系/属性上;第二,复合问题,即一个自然语言问题可能转换为多个知识图谱三元组,而这多个三元组如何组合,才正确表达了问题的意图,并由此得到正确答案。
因此,为了解决第一阶段的两个问题,gAnswer基于图匹配的方法,建立一个与自然语言问句意图充分匹配的查询图Qs,这个查询图中可以存在具有歧义性的实体(以节点表示)或关系(以边表示)。当这个查询图被确定下来时,对应的结构化查询也被唯一确定。算法将解决歧义问题与查询评分这两个阶段融合在一起,即当得到自然语言问题的一个正确匹配的查询子图时,歧义问题也已经同时解决了。
图谱学苑社区weekly分别在:
-
70期,介绍了句法依存树、句法依存分析工具以及它们在gAnswer中的使用;
-
73期,介绍了NE即节点提取模块;
-
76期,介绍了RE即关系提取模块;
-
79期中,介绍了查询图生成。
这四期是gAnswer几个重要的基础模块。
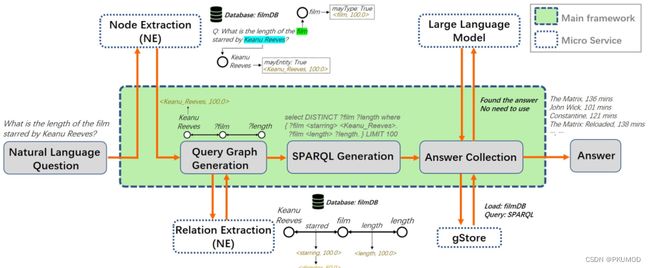
大多数现有项目主要集中于提高模型在单一基准数据集上的效果,忽视了在现实场景(如多用户平台)中重新训练、重新部署和调整系统适应不同数据集所带来的高成本。因此,我们的团队在gAnswer中加入了ADMUS,一个渐进式知识库问答框架,旨在适应各种各样的数据集,包括多种语言、多样的基础知识库和不同的问答数据集。为了提高ADMUS的易用性,我们设计了一个渐进式框架,包括三个阶段,从执行精确查询、生成近似查询到检索大型语言模型引用的开放领域知识。我们的框架支持轻松集成新数据集,只需付出极小的努力和成本,通过添加NE和RE服务来支持新的数据集,创建一个与数据集相关的微服务。下面就解析在birdDB添加的NE和RE服务。
PART2
bird数据集
NE:
首先使用模型分词和词性标注,提取出四种类型节点Entity、Type、Literal、Variable(bird数据集只需要提取Entity和Type),并将结果存储在相应的数据结构中。源码通过调用Extract(question)函数,可以提取给定问题中的相关信息。
def Extract(question):
word_list = model(question)
word_list = word_list[0]
print("parsing result: ", word_list)
ret = {}
ret["mergedQuestionList"] = [question]
mWordList = []
length = len(word_list)
vis = np.zeros(length, dtype=bool)
for sta in range(0, length):
for l in range(length - sta, 0, -1):
flg1 = False
for j in range(sta, sta + l):
if vis[j] == True:
flg1 = True
if flg1 == True:
break
word = ""
flg = False
for j in range(sta, sta + l):
word += word_list[j]
mWord = Word(word)
pred = check_predicate(word)
if pred != None:
continue
emList = check_entity(word)
if emList != None and len(emList) > 0:
for x in emList:
addEntity(mWord, Entity_candidate(x[0], x[1], x[2]))
flg = True
if check_type(word) != None:
addType(mWord, Type_candidate(word, -1, 100.0, -1))
flg = True
if flg == True: # 如果有候选,就加入mWodList
mWordList.append(mWord)
for j in range(sta, sta + l):
vis[j] = True
主函数Extract(question):
-
使用
model即使用FastHan模型对传入的问题进行分词和词性标注,得到一个词语列表。 -
创建一个结果返回字典
ret,包含一个合并的问题列表和一个空的单词列表。 -
遍历词语列表,对每个词语进行处理:
构建一个表示词语的字典
mWord。mWord的结构如下:def Word(name): mWord = {} name = name.replace("_", " ") mWord["name"] = name mWord["mayCategory"] = False mWord["mayEnt"] = False mWord["mayType"] = False mWord["mayLiteral"] = False return mWord检查词语是否是谓词,如果是则跳过。
检查词语是否是实体,如果是则将实体候选项添加到
mWord的emList中,并将mayEnt标记为True。检查词语是否是类型,如果是则将类型候选项添加到
mWord的tmList中,并将mayType标记为True。将被标记词语的
mWord添加到单词列表mWordList中,后续不再重复访问。 -
将单词列表
mWordList添加到字典ret中。并将字典ret转换为JSON字符串并返回。
对于如何检验是否是实体或者类型,NE模块的方法是提取输入问题中的mentions,然后通过实体链接将其和特定数据集匹配,将其映射到知识图谱中的一组实体(类型)名称。这个方法的复杂性取决于知识库的规模和复杂性。诸如DBpedia等大型知识库,通常采用离线基于词典的链接器或利用第三方实体链接服务。在相对较小的知识库中,所有实体可以加载到内存缓存中,通过精确匹配、子串匹配或神经链接器方法来实现实体的链接。此处使用的是基于最长公共子序列(Longest Common Subsequence)匹配算法。
for i, s in enumerate(entities):
score = SequenceMatcher(None, s, word).ratio()
temp.append((s, -1, score * 100))
temp.sort(key=lambda x: x[2], reverse=True)
res = []
for i, x in enumerate(temp):
if i == candidate_num or x[2] < sqMatcher_thrs:
break
res.append(x)
RE:
关系提取服务的目标是识别连接查询图中每对节点的谓词。给定查询图作为输入,与数据集相关的RE服务将为节点对生成与知识库中谓词对齐的关系以及相应的分数。
主函数RE_explicit用于解析文本数据中的语义关系。下面是对该函数的解析:
def RE_explicit(data):
posResult = data["posResult"]
dependencyResult = data["dependencyResult"]
SemanticUnitList = data["simplifiedSemanticUnitList"]
print("posResult", posResult)
nodes.clear()
temp = ["_", "_", "_"]
nodes.append(Node(temp))
for i, u in enumerate(dependencyResult):
nodes.append(Node(u))
if u[2] == "root": root = i + 1
for i, u in enumerate(nodes):
if i == 0: continue
u.token = posResult[u.position - 1]
if u.fa_position != 0:
u.fa = get_idx(nodes, u.fa_position)
nodes[u.fa].vertices.append(i)
u.vertices.append(u.fa)
print("=====nodes=====")
for i, u in enumerate(nodes):
if i == 0: continue
print("i: ", i, end="\t")
print("token: ", u.token, end="\t")
print("father: ", u.fa, end="\t")
print("head label: ", u.head_label, end="\t")
print("vertices: ", u.vertices)
simplifiedSemanticRelations = {}
simplifiedSemanticUnitList = []
cnt = 2333
for i, SemanticUnit in enumerate(SemanticUnitList):
u = SemanticUnit["centerWordIndex"]
simplifiedSemanticUnit = {}
simplifiedSemanticUnit["centerWordIndex"] = u
new_neighborUnitList = []
neighborUnitList = SemanticUnit["neighborUnitList"]
for j, neighborUnit in enumerate(neighborUnitList):
ret = calc_relations(u, neighborUnit)
if ret != None:
simplifiedSemanticRelations[str(cnt)] = ret
cnt += 1
new_neighborUnitList.append(neighborUnit)
simplifiedSemanticUnit["neighborUnitList"] = new_neighborUnitList
simplifiedSemanticUnitList.append(simplifiedSemanticUnit)
ret = {}
ret["simplifiedSemanticUnitList"] = simplifiedSemanticUnitList
ret["simplifiedSemanticRelations"] = simplifiedSemanticRelations
solve_steadyEdge(ret)
json_ret = json.dumps(ret)
print("return result(json): ", json_ret)
return json_ret
-
遍历
dependencyResult,对于每个依存结果u,创建一个节点对象,并将其添加到nodes列表中。如果该节点是根节点,则记录其索引。 -
遍历所有节点,为每个节点设置词性标记
token,并处理节点间的连接关系。如果节点有父节点,则将节点与父节点之间建立连接。 -
遍历简化的语义单元列表
SemanticUnitList,对每个语义单元进行处理。提取其中的中心词索引u,以及邻居单元列表neighborUnitList。 -
遍历邻居单元列表,对每个邻居单元计算语义关系,并将结果存储到
simplifiedSemanticRelations中。同时更新计数器cnt。 -
将新的邻居单元列表更新到当前语义单元中,并将当前语义单元添加到
simplifiedSemanticUnitList中。 -
构建返回结果
ret,将简化语义单元列表和语义关系添加到其中。调用solve_steadyEdge函数处理稳定边的情况。solve_steadyEdge函数如下:def solve_steadyEdge(ret): vis = {} num_nodes = 0 simplifiedSemanticUnitList = ret["simplifiedSemanticUnitList"] for semanticUnit in simplifiedSemanticUnitList: x = semanticUnit["centerWordIndex"] if x not in vis: num_nodes += 1 vis[x] = 1 xs = semanticUnit["neighborUnitList"] for x in xs: if x not in vis: num_nodes += 1 vis[x] = 1 num_edges = len(ret["simplifiedSemanticRelations"].keys()) print("steadyEdge check:num_edges ", num_edges, "num_nodes:", num_nodes) if num_edges > num_nodes - 1: relations = ret["simplifiedSemanticRelations"] for key in relations: rel = relations[key] rel["isSteadyEdge"] = False
与NE服务类似,RE服务的选择取决于目标知识库的属性。对于结构简单、谓词数量较少的知识库,可以采用直接的策略。两个节点之间的谓词通过确定它们的语义结构(如依存树)中的共同祖先节点来确定。对于像DBpedia这样更复杂的知识库,仅依赖上述简单策略可能会导致较大的错误。
在经过NE、QGG和RE处理后,我们获得了一个粗粒度匹配的查询图的超集,其中包含必要的查询结构和节点。ADUMS将通过近似匹配和在目标知识库上搜索子图来处理这样的查询图,然后交互地生成预期的SPARQL查询。

gAnswer在DBpedia,bird,film三个数据集的demo演示可以公开访问:https://answer.gstore.cn/pc/index.html
[1] Sen Hu, Lei Zou, Jeffrey Xu Yu, Haixun Wang, DongyanZhao: “Answering Natural Language Questions by Subgraph Matching over KnowledgeGraphs”. IEEE Trans. Knowl. Data Eng (TKDE) 2018: 824-837
[2] ADMUS: A Progressive Question Answering Framework Adaptable to Multiple Knowledge Sources