爬虫---》selenium4.0+使用
获取页面源码
page_text = bro.get(request.url).page_source属性定位
id
在最开始需要将 selenium 的 webdriver与By 导入
在输入路径语句中查询元素方法find_element里参数一By.ID表示定位属性是id,参数二表示属性值为kw
#导入库
from selenium import webdriver
from selenium.webdriver.common.by import By
#初始化浏览器
dr = webdriver.Chrome()
#打开百度
dr.get('https://www.baidu.com')
#输入路飞
dr.find_element(By.ID, 'kw').send_keys('路飞')
#点击百度一下
dr.find_element(By.ID, 'su').click()name
dr = webdriver.Chrome()
dr.get('https://www.baidu.com')
dr.find_element(By.NAME, 'wd').send_keys('诸葛亮')
dr.find_element(By.ID, 'su').click()Class
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
#点击第一个分类
dr.find_elements(By.CLASS_NAME, 'navigation-right')[0].click()
#等待3秒
time.sleep(3)
#点击第一个分类
dr.find_elements(By.CLASS_NAME, 'navigation-right')[1].click()tag
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.find_elements(By.TAG_NAME, 'dl')[0].click()Link
Link表示包含有属性href = “https://www.xxxxxxx.com”元素,可以通过linktext定位,linktext是页面上展示的文字。它还可以部分linktext定位。
网上很多文章将linktext通过全linktext与部分linktext区分为两种定位方式,没有本文最后的JS定位方式,也是对的。
参数一By.LINK_TEXT表示全部匹配linktext定位找到元素,参数二值是页面这个链接的全部文案‘Java’
参数一By.PARTIAL_LINK_TEXT表示模糊匹配linktext定位找到元素 ,参数二值是页面这个链接部分文案‘人工智’
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
#通过linetext点击‘Java’分类
dr.find_element(By.LINK_TEXT, 'Java').click()
time.sleep(3)
#通过部分linktext点击‘人工智能’分类
dr.find_element(By.PARTIAL_LINK_TEXT, '人工智').click()xpath
| 表达式 |
描述 |
| nodename |
选取此节点的所有子节点 |
| / |
从当前节点选取直接子节点 |
| // |
从当前节点选取子孙节点 |
| . |
选取当前节点 |
| . . |
选取当前节点的父节点 |
| @ |
选取属性 |
| * |
任何元素 |
css选择器
css是前端样式,这里说的css定位是用css样式里定位元素用的方法叫做css选择器。
符号.代表class, 符号 # 代表id, 路径空格写tag名
它与xpath一样,可以定位到任何元素,也可以直接通过F12的copy selector来取 得元素的css选择器
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.find_element(By.CSS_SELECTOR, '#www-home-right > div.www-home-silde > div.ContentBlock > div:nth-child(2) > div > span').click()js执行
js不是定位器
js不是定位器
js不是定位器
js是javascript,是可以独以运行的脚本;不使用selenium的方法,进行页面元素的点击、输入、拖拽等等操作,像如果对js使用很熟练,那么也就完全不需要管上面的定位方式。全部可以使用js来实现页面元素的各种操作。
像滚动条拖拽是没法用元素定位操作的,只能使用js
进入CSDN,拖拽滚动条
滚动条拖拽的js为document.documentElement.scrollTop=10000
使用exeute_script执行JS
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.execute_script('document.documentElement.scrollTop=10000')selenium封装
介绍
上面讲了selenium八大元素定位方式,但做自动化肯定不是一直写这样的python代码,因为时间与空间上都浪费人力,不如功能测试,所以我们需要学会去二次封装selenium。将其制定成规则化的自然代码来让自动化变得简单易懂。
设计规则
一、做自动化是模拟人的操作,所以有操作字段:点击、输入等
二、定位元素需要定位方式,所以有定位器字段:id、name、class、tag、link、plink、xpath、css、js
三、定位器有了,定位器的对象字段也要有
四、页面相同属性的元素有多个,所以需要一个下标字段
五、输入、下拉、检查需要值,所以值字段也需要一个
基本上暂时可以先确定这些字段:
operation、type、locatuion、index、value
确认入口函数
设计好五个参数后,基本上操作就只需要这五个参数了,所以需要一个统一入口函数,将这五个参数均带入其实。
def web_autotest_opr(operation, type, locatuion, index, value)
设计逻辑
一、封装浏览器打开功能,返回浏览器对象
二、封装入口函数
三、封装定位元素方式
四、封装元素操作方式
代码封装
from selenium import webdriver
from selenium.webdriver.common.by import By
def open_url(url):
'''
打开浏览顺访问url,并返回浏器操作句柄
:param url: 要测试的网站url
:return: webdriver对像
'''
opr = webdriver.Chrome()
opr.get(url)
return opr
def get_element(opr:webdriver.Chrome, type, locatuion, index):
'''
获取元素并返回
:param opr: 浏览器句柄
:param type: 定位器类型
:param locatuion: 定位器
:param index: 下标
:return: 元素对象
'''
if str.lower(type) == 'id':
return opr.find_elements(By.ID, locatuion)[index]
elif str.lower(type) == 'name':
return opr.find_elements(By.NAME, locatuion)[index]
elif str.lower(type) == 'class':
return opr.find_elements(By.CLASS_NAME, locatuion)[index]
elif str.lower(type) == 'tag':
return opr.find_elements(By.TAG_NAME, locatuion)[index]
elif str.lower(type) == 'link':
return opr.find_elements(By.LINK_TEXT, locatuion)[index]
elif str.lower(type) == 'plink':
return opr.find_elements(By.PARTIAL_LINK_TEXT, locatuion)[index]
elif str.lower(type) == 'xpath':
return opr.find_elements(By.XPATH, locatuion)[index]
elif str.lower(type) == 'css':
return opr.find_elements(By.CSS_SELECTOR, locatuion)[index]
def element_opr(el:webdriver.Chrome.find_element, operation, value):
'''
元素操作
:param el: 元素对象
:param operation: 操作类型
:param value: 值
:return: 成功(True)or失败(False)
'''
if operation == '点击':
el.click()
return True
elif operation == '输入':
el.send_keys(value)
return True
def web_autotest_opr(opr:webdriver.Chrome ,operation, type, locatuion, index=0, value=''):
'''
元素操作统一入口
:param opr: 浏览器句柄
:param operation: 操作类型
:param type: 定位器类型
:param locatuion: 定位器
:param index: 下标
:param value: 值
:return: 成功(True)or失败(False)
'''
if str.lower(type) != 'js':
el = get_element(opr, type, locatuion, index)
result = element_opr(el, operation, value)
else:
result = opr.execute_script(locatuion)
return result其他操作
添加等待
如果不添加等待可能会出现上一个操作还没有完成就进行下一个操作的情况,或者出现看不到效果的情况。
(1)固定等待
import time
time.sleep(3)(2)智能等待
等待的操作3秒已经完成了,就可以进行下一步了,不用等到规定的10秒。
implicitly_wait()
driver.implicitly_wait(10)
打印信息
print()
#打印title星黛露百度搜索
#打印url当前界面的url
title=driver.title
url=driver.current_url
print(title)
print(url)
浏览器的操作
(1)浏览器最大化
maximize_window()
driver.maximize_window()
(2)设置浏览器宽、高
set_window_size(宽,高)
driver.set_window_size(600,600)
(3)操作浏览器的前进、后退
#后退
back()
driver.back()
#前进
forward()
driver.forward()
(4)控制浏览器滚动条
用js语言,数值为0滚动条往顶端拉,数值越大滚动条往下端拉。
js1="var q=documentElement.Scro1lTop=数值"
#滚动条往顶端拉
js1="var q=documentElement.Scro1lTop=0"
#滚动条往下拉
js1="var q=documentElement.Scro1lTop=10000"
#执行操作
driver.execute_script(js1)
键盘事件
(1)enter键
from selenium.webdriver import Keys
send_keys(Keys.ENTER)
以禅道的登录为例
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
#导入键盘包
from selenium.webdriver import Keysdriver = webdriver.Chrome()
time.sleep(3)
url = "复制禅道登录界面的地址"
driver.get(url)
#浏览器最大化
driver.maximize_window()#输入自己的用户名和密码,输完密码后在密码框中点击enter键登录
driver.find_element(By.ID, "account").send_keys("用户名")
driver.find_element(By.NAME, "password").send_keys("密码")
driver.find_element(By.NAME, "password").send_keys(Keys.ENTER)
time.sleep(6)
driver.quit()
Tab键
切换焦点
from selenium.webdriver import Keys
send_keys(Keys.TAB)
from selenium import webdriver
import time
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
time.sleep(3)
url = "输入自己的禅道登录的地址"
driver.get(url)
driver.maximize_window()
#把光标从登录框切换到密码框
driver.find_element(By.ID, "account").send_keys("admin")
driver.find_element(By.ID, "account").send_keys(Keys.TAB)
time.sleep(6)
driver.quit()
键盘组合用法
#ctrl+a 全选输入框内容
send_keys(Keys.CONTROL,'a')
#ctrl+x 剪切输入框内容
send_keys(Keys.CONTROL,'x')
鼠标事件
模拟鼠标
(1)常用鼠标事件
from selenium.webdriver import Keys, ActionChains
#右击
.context_click()
# 双击
double_click()
#拖动
drag_and_drop()
#移动,把鼠标移动到相应位置
move_to_element()
(2)举例
#导包
from selenium.webdriver import Keys, ActionChains
#假设已经处于禅道登录界面,输入用户名
su=driver.find_element(By.ID, "account").send_keys("admin")
#ActionChains首先要知道要操作的是哪个浏览器
#右击登录输入框
#perform执行
ActionChains(driver).context_click(su).perform()
定位一组元素
定位一组具有相同属性元素,如给一列表格打钩。
from selenium import webdriver
import time
#导包
import os
driver = webdriver.Chrome()
#本地文件绝对路径
file="file:///"+os.path.abspath("路径地址具体到文件名")
#打开文件
driver.get(file)
driver.maximize_window()
#对文件进行操作
#定位文件中所有tagname为input中type=checkbox的元素
inputs=driver.find_elements(By.TAG_NAME, "input")
for input in inputs:
if input.get_attribute('type')=='checkbox':
input.click()
time.sleep(6)
driver.quit()
多层框架/窗口定位
有多个框架或者窗口。
import switch as switch
#定位到哪个框架
switch_to.frame("框架id")
#转换到默认界面
switch_to.default_content()
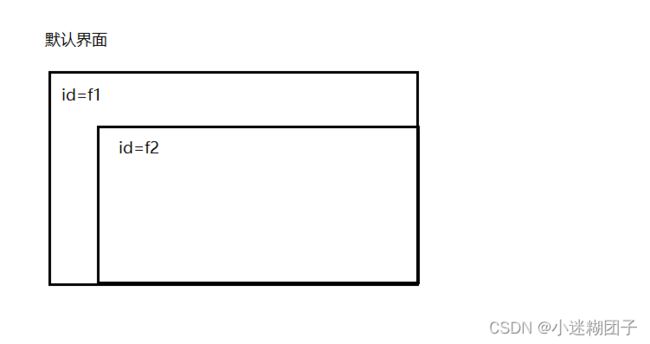
例:默认界面中嵌套两个框架,iframe框架的id分别为f1、f2
from selenium import webdriver
import time
import os
driver = webdriver.Chrome()
file="file:///"+os.path.abspath("")
driver.get(file)
driver.maximize_window()
time.sleep(3)
#转换层级
driver.switch_to.frame("f1")
driver.switch_to.frame("f2")
#f2上进行操作
driver.find_element(By.ID, "c1").click()
time.sleep(2)
#要想从f2回到f1,要先回到默认界面
driver.switch_to.default_content()
driver.switch_to.frame("f1")
driver.find_element(By.ID, "c1").click()
time.sleep(6)
driver.quit()
层级定位
有时候我们需要定位的元素没有直接在页面展示,而是需要对页面的元素经过一系列操作之后才展示出来,这个时候我们就需要一层层去定位.
例:类似于这样的情况
from selenium import webdriver
import time
import os
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
file="file:///"+os.path.abspath("")
driver.get(file)
driver.maximize_window()
time.sleep(3)
#先定位到界面的选项
driver.find_element(By.LINK_TEXT, "link1").click()
#定位下拉列表特定的元素
ele=driver.find_element(By.ID, "dropdown1").find_element(By.LINK_TEXT, "settings")
#把鼠标放到元素上(用鼠标事件中的拖动),让元素高亮
ActionChains(driver).move_to_element(ele).perform()
time.sleep(6)
driver.quit()
下拉框处理
这里的下拉框类似于,每次调查问卷中选择地区或者性别的框,或者是星座输年份的。
from selenium import webdriver
import time
import os
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
file = "file:///"+os.path.abspath("")
driver.get(file)
driver.maximize_window()
time.sleep(3)
#定位到下拉框,注意elements的复数形式
options = driver.find_element(By.CLASS_NAME,"qA").find_elements(By.TAG_NAME, "option")
for option in options:
if option.get_attribute('value') == '10':
option.click()
# 第二种方法option[10].click
time.sleep(6)
driver.quit()
alert的处理
alert就是每次界面上的弹出框,只有关闭弹出框才能进行下一步操作,类似于下图。
没有对话框不能用send_keys 输入值,不然会报错
text 返回alert/confirm/prompt 中的文字信息
#分两步得到操作弹框的句柄
#accept 点击确认按钮,关闭弹窗
#dismiss 点击取消,关闭弹窗
switch_to.alert
accept()
dismiss()
#例如得到句柄关闭弹框
alert=driver.switch_to.alert
#在弹出框中输入信息
alert.send_keys("mxz")
#点击确定
alert.accept()
DIV对话框的处理
#例如:先定位到DIV这个模块,在对模块上的元素进行操作
div1=driver.find_element(By.CLASS_NAME, "class名")
div1.find_element(By.ID, "名称").click()
#如果这个模块上多个button,还可以使用这样的方法
div1=driver.find_element(By.CLASS_NAME, "class名")
buttons=div1.find_element(By.ID, "名称")
button[0].click()
上传文件操作
先定位上传按键,再send_keys 添加本地文件路径就可以了
#例
driver.find_element(By.CLASS_NAME, "class名").send_keys("路径")